Jika Anda ingin tahu segalanya tentang Hadoop MapReduce, Anda telah mendarat di tempat yang tepat. Tutorial MapReduce ini memberi Anda panduan lengkap tentang setiap dan semua yang ada di Hadoop MapReduce.
Dalam Pengenalan MapReduce ini, Anda akan menjelajahi apa itu Hadoop MapReduce, Bagaimana kerangka kerja MapReduce. Artikel ini juga membahas MapReduce DataFlow, Fase berbeda dalam MapReduce, Mapper, Reducer, Partitioner, Cominer, Shuffle, Sorting, Data Locality, dan banyak lagi.
Kami juga telah mendapatkan keuntungan dari kerangka kerja MapReduce.
Mari kita jelajahi terlebih dahulu mengapa kita membutuhkan Hadoop MapReduce.
Mengapa MapReduce?
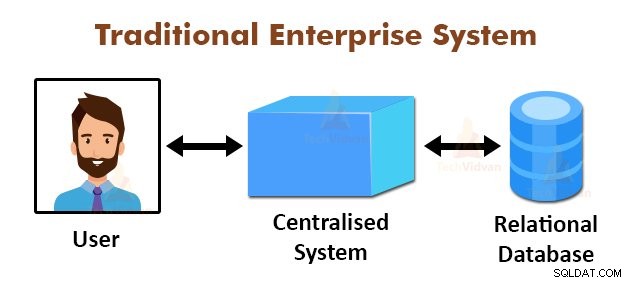
Gambar di atas menggambarkan tampilan skema dari sistem perusahaan tradisional. Sistem tradisional biasanya memiliki server terpusat untuk menyimpan dan memproses data. Model ini tidak cocok untuk memproses data skalabel dalam jumlah besar.
Juga, model ini tidak dapat diakomodasi oleh server database standar. Selain itu, sistem terpusat menciptakan terlalu banyak hambatan saat memproses banyak file secara bersamaan.
Dengan menggunakan algoritma MapReduce, Google memecahkan masalah kemacetan ini. Kerangka kerja MapReduce membagi tugas menjadi bagian-bagian kecil dan memberikan tugas ke banyak komputer.
Kemudian, hasilnya dikumpulkan di tempat yang biasa dan kemudian diintegrasikan untuk membentuk kumpulan data hasil.
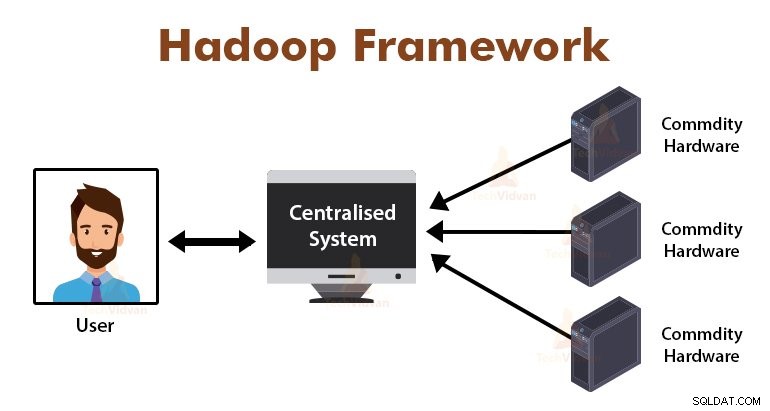
Pengantar Kerangka MapReduce
MapReduce adalah lapisan pemrosesan di Hadoop. Ini adalah kerangka kerja perangkat lunak yang dirancang untuk memproses sejumlah besar data secara paralel dengan membagi tugas ke dalam kumpulan tugas independen.
Kita hanya perlu menempatkan logika bisnis dalam cara kerja MapReduce, dan kerangka kerja akan mengurus sisanya. Kerangka kerja MapReduce bekerja dengan membagi pekerjaan menjadi tugas-tugas kecil dan memberikan tugas-tugas ini ke budak.
Program MapReduce ditulis dalam gaya tertentu yang dipengaruhi oleh konstruksi pemrograman fungsional, idiom khusus untuk memproses daftar data.
Pada MapReduce, input berupa list dan output dari framework juga berupa list. MapReduce adalah jantung dari Hadoop. Efisiensi dan kekuatan Hadoop disebabkan oleh pemrosesan paralel framework MapReduce.
Sekarang mari kita jelajahi cara kerja Hadoop MapReduce.
Bagaimana Hadoop MapReduce Bekerja?
Kerangka kerja Hadoop MapReduce bekerja dengan membagi pekerjaan menjadi tugas-tugas independen dan menjalankan tugas-tugas ini pada mesin budak. Pekerjaan MapReduce dijalankan dalam dua tahap yaitu fase peta dan fase pengurangan.
Input ke dan output dari kedua fase adalah pasangan kunci, nilai. Kerangka kerja MapReduce didasarkan pada prinsip lokalitas data (dibahas nanti) yang berarti mengirimkan komputasi ke node tempat data berada.
- Fase peta Pada fase Peta, fungsi peta yang ditentukan pengguna memproses data input. Dalam fungsi peta, pengguna menempatkan logika bisnis. Keluaran dari fase Peta adalah keluaran antara dan disimpan di disk lokal.
- Mengurangi fase – Fase ini merupakan kombinasi dari fase shuffle dan fase reduksi. Pada fase Reduce, output dari tahap peta diteruskan ke Reducer di mana mereka dikumpulkan. Output dari fase Reduce adalah output akhir. Pada fase Reduce, fungsi pengurangan yang ditentukan pengguna memproses output Mappers dan menghasilkan hasil akhir.
Selama pekerjaan MapReduce, framework Hadoop mengirimkan tugas Map dan tugas Reduce ke mesin yang sesuai di cluster.
Kerangka kerja itu sendiri mengelola semua detail pengiriman data seperti menerbitkan tugas, memverifikasi penyelesaian tugas, dan menyalin data antara node di sekitar cluster. Tugas berlangsung di node tempat data berada untuk mengurangi lalu lintas jaringan.
Alur Data MapReduce
Anda semua mungkin ingin tahu bagaimana pasangan nilai kunci ini dihasilkan dan bagaimana MapReduce memproses data input. Bagian ini menjawab semua pertanyaan ini.
Mari kita lihat Bagaimana data harus mengalir dari berbagai fase di Hadoop MapReduce untuk menangani data yang akan datang secara paralel dan terdistribusi.
1. File Masukan
Dataset input, yang akan diproses oleh program MapReduce disimpan di InputFile. InputFile disimpan di Sistem File Terdistribusi Hadoop.
2. Pemisahan Masukan
Catatan di InputFiles dibagi menjadi model logis. Ukuran split umumnya sama dengan ukuran blok HDFS. Setiap pemisahan diproses oleh masing-masing Mapper.
3. Format Masukan
InputFormat menentukan spesifikasi input file. Ini mendefinisikan cara ke RecordReader di mana catatan dari InputFile diubah menjadi kunci, pasangan nilai.
4. Pembaca Rekam
RecordReader membaca data dari InputSplit dan mengubah catatan menjadi kunci, pasangan nilai, dan menyajikannya ke Pemeta.
5. Pemeta
Pemeta mengambil kunci, pasangan nilai sebagai input dari RecordReader dan memprosesnya dengan menerapkan fungsi peta yang ditentukan pengguna. Di setiap Mapper, pada satu waktu, satu pemisahan diproses.
Pengembang menempatkan logika bisnis dalam fungsi peta. Keluaran dari semua pembuat peta adalah keluaran antara, yang juga berupa kunci, pasangan nilai.
6. Acak dan Urutkan
Output antara yang dihasilkan oleh Pemeta diurutkan sebelum diteruskan ke Peredam untuk mengurangi kemacetan jaringan. Output perantara yang diurutkan kemudian diacak ke Peredam melalui jaringan.
7. Peredam
Proses Reducer dan menggabungkan output Mapper dengan menerapkan fungsi pengurangan yang ditentukan pengguna. Output Reducers adalah output akhir dan disimpan di Hadoop Distributed File System (HDFS).
Sekarang mari kita mempelajari beberapa terminologi dan konsep lanjutan dari kerangka Hadoop MapReduce.
Pasangan Key-Value di MapReduce
Kerangka kerja MapReduce bekerja pada pasangan kunci, nilai karena berhubungan dengan skema non-statis. Dibutuhkan data berupa kunci, pasangan nilai, dan output yang dihasilkan juga berupa kunci, pasangan nilai.
Pasangan nilai kunci MapReduce adalah entitas rekaman yang diterima oleh pekerjaan MapReduce untuk eksekusi. Dalam pasangan nilai kunci:
- Kunci adalah offset baris dari awal baris di dalam file.
- Nilai adalah konten baris, tidak termasuk terminator baris.
Pembagi MapReduce
Hadoop MapReduce Partitioner mempartisi ruang kunci. Partisi keyspace di MapReduce menetapkan bahwa semua nilai dari setiap kunci dikelompokkan bersama, dan memastikan bahwa semua nilai dari satu kunci harus masuk ke Reducer yang sama.
Partisi ini memungkinkan pemerataan output mapper melalui Reducer dengan memastikan bahwa kunci yang tepat menuju ke Reducer yang tepat.
Partisi MapReducer default adalah Hash Partitioner, yang mempartisi ruang kunci berdasarkan nilai hash.
Penggabung MapReduce
Penggabung MapReduce juga dikenal sebagai "Semi-Reducer." Ini memainkan peran utama dalam mengurangi kemacetan jaringan. Kerangka kerja MapReduce menyediakan fungsionalitas untuk mendefinisikan Penggabung, yang menggabungkan keluaran antara dari Pemeta sebelum meneruskannya ke Peredam.
Agregasi keluaran Mapper sebelum diteruskan ke Reducer membantu kerangka kerja mengacak sejumlah kecil data, yang mengarah ke kemacetan jaringan yang rendah.
Fungsi utama dari Combiner adalah untuk meringkas output dari Pemeta dengan kunci yang sama dan meneruskannya ke Peredam. Kelas Combiner digunakan antara kelas Mapper dan kelas Reducer.
Lokalitas Data di MapReduce
Lokalitas data mengacu pada “Memindahkan komputasi lebih dekat ke data daripada memindahkan data ke komputasi.” Jauh lebih efisien jika komputasi yang diminta oleh aplikasi dijalankan pada mesin tempat data yang diminta berada.
Ini sangat benar dalam kasus di mana ukuran data sangat besar. Ini karena meminimalkan kemacetan jaringan dan meningkatkan throughput sistem secara keseluruhan.
Satu-satunya asumsi di balik ini adalah lebih baik memindahkan komputasi lebih dekat ke mesin tempat data ada daripada memindahkan data ke mesin tempat aplikasi berjalan.
Apache Hadoop bekerja pada volume data yang sangat besar, sehingga tidak efisien untuk memindahkan data sebesar itu melalui jaringan. Oleh karena itu kerangka kerja muncul dengan prinsip paling inovatif yaitu lokalitas data, yang memindahkan logika komputasi ke data alih-alih memindahkan data ke algoritme komputasi. Ini disebut lokalitas data.
Kelebihan MapReduce
1. Skalabilitas: Kerangka kerja MapReduce sangat skalabel. Ini memungkinkan organisasi untuk menjalankan aplikasi dari set mesin yang besar, yang dapat melibatkan penggunaan ribuan terabyte data.
2. Fleksibilitas: Kerangka kerja MapReduce memberikan fleksibilitas kepada organisasi untuk memproses data dalam berbagai ukuran dan format apa pun, baik terstruktur, semi-terstruktur, atau tidak terstruktur.
3. Keamanan dan Otentikasi: Model pemrograman MapReduce memberikan keamanan yang tinggi. Ini melindungi akses tidak sah ke data dan meningkatkan keamanan cluster.
4. Hemat biaya: Kerangka kerja ini memproses data di seluruh kelompok perangkat keras komoditas, yang merupakan mesin murah. Dengan demikian, sangat hemat biaya.
5. Cepat: MapReduce memproses data secara paralel karena sangat cepat. Hanya butuh beberapa menit untuk memproses terabyte data.
6. Model sederhana untuk pemrograman: Program MapReduce dapat ditulis dalam bahasa apa pun seperti Java, Python, Perl, R, dll. Jadi, siapa pun dapat dengan mudah mempelajari dan menulis program MapReduce dan memenuhi kebutuhan pemrosesan data mereka.
Penggunaan MapReduce
1. Analisis log: MapReduce pada dasarnya digunakan untuk menganalisis file log. Kerangka kerja memecah file log besar menjadi beberapa bagian dan pencarian mapper untuk halaman web berbeda yang diakses.
Setiap kali halaman web ditemukan di log, maka kunci, pasangan nilai diteruskan ke peredam di mana kuncinya adalah halaman web, dan nilainya adalah "1". Setelah memancarkan kunci, pasangan nilai ke Reducer, Reducer menggabungkan jumlah untuk halaman web tertentu.
Hasil akhirnya adalah jumlah total klik untuk setiap halaman web.
2. Pengindeksan teks lengkap: MapReduce juga digunakan untuk melakukan pengindeksan teks lengkap. Pemeta di MapReduce akan memetakan setiap frase atau kata dalam satu dokumen ke dokumen. Peredam akan menulis pemetaan ini ke indeks.
3. Google menggunakan MapReduce untuk menghitung Pagerank mereka.
4. Grafik Tautan Web Terbalik: MapReduce juga digunakan dalam Reverse Web-Link GRAF. Fungsi Peta menampilkan target dan sumber URL, mengambil input dari halaman web (sumber).
Fungsi pengurangan kemudian menggabungkan daftar semua URL sumber yang terkait dengan URL target yang diberikan dan mengembalikan target dan daftar sumber.
5. Jumlah kata dalam dokumen: Kerangka kerja MapReduce dapat digunakan untuk menghitung berapa kali kata tersebut muncul dalam dokumen.
Ringkasan
Ini semua tentang Tutorial Hadoop MapReduce. Kerangka kerja ini memproses sejumlah besar data secara paralel di seluruh klaster perangkat keras komoditas. Ini membagi pekerjaan menjadi tugas-tugas independen dan menjalankannya secara paralel pada node yang berbeda dalam cluster.
MapReduce mengatasi kemacetan sistem perusahaan tradisional. Kerangka kerja bekerja pada kunci, pasangan nilai. Pengguna mendefinisikan dua fungsi yaitu fungsi peta dan fungsi pengurangan.
Logika bisnis dimasukkan ke dalam fungsi peta. Artikel tersebut telah menjelaskan berbagai konsep lanjutan dari framework MapReduce.



