Sejak ClusterControl 1.2.11 dirilis pada tahun 2015, MariaDB MaxScale telah didukung sebagai penyeimbang beban basis data. Selama bertahun-tahun MaxScale telah tumbuh dan matang, menambahkan beberapa fitur yang kaya. Baru-baru ini MariaDB MaxScale 2.2 dirilis dan memperkenalkan beberapa fitur baru termasuk manajemen failover cluster replikasi.
MariaDB MaxScale memungkinkan penerapan master/slave dengan ketersediaan tinggi, failover otomatis, peralihan manual, dan penggabungan ulang otomatis. Jika master gagal, MariaDB MaxScale dapat secara otomatis mempromosikan slave terbaru ke master. Jika master yang gagal dipulihkan, MariaDB MaxScale dapat secara otomatis mengkonfigurasi ulang sebagai budak dari master baru. Selain itu, administrator dapat melakukan peralihan manual untuk mengubah master sesuai permintaan.
Di blog kami sebelumnya, kami membahas cara Menyebarkan MaxScale Menggunakan ClusterControl serta Menyebarkan MariaDB MaxScale di Docker. Bagi mereka yang belum terbiasa dengan MariaDB MaxScale, ini adalah proxy database plug-in canggih untuk server database MariaDB. Maxscale berada di antara aplikasi klien dan server database, merutekan kueri klien dan respons server. Itu juga memantau server, dengan cepat memperhatikan setiap perubahan dalam status server atau topologi replikasi.
Meskipun Maxscale berbagi beberapa karakteristik dari teknologi penyeimbangan beban lainnya seperti ProxySQL, fitur failover baru ini (yang merupakan bagian dari mekanisme pemantauan dan deteksi otomatisnya) menonjol. Di blog ini kita akan membahas fungsi baru Maxscale yang menarik ini.
Ikhtisar Mekanisme Failover MariaDB MaxScale
Deteksi Utama
Monitor sekarang cenderung tidak mengubah server master secara tiba-tiba, bahkan jika server lain memiliki lebih banyak budak daripada master saat ini. DBA dapat memaksa pemilihan ulang master dengan menyetel master saat ini hanya-baca, atau dengan menghapus semua budaknya jika master tidak aktif.
Hanya satu server yang dapat memiliki bendera status Master pada satu waktu, bahkan dalam pengaturan multimaster. Server lain dalam grup multimaster diberi tanda status Relay Master dan Slave.
Switchover Pemilihan Otomatis Master Baru
Perintah switchover sekarang dapat dipanggil hanya dengan nama instance monitor sebagai parameter. Dalam hal ini monitor akan secara otomatis memilih server untuk promosi.
Deteksi Jeda Replikasi
Pengukuran jeda replikasi sekarang hanya membaca Seconds_Behind_Master -bidang output status budak dari budak. Budak menghitung nilai ini dengan membandingkan cap waktu dalam peristiwa binlog yang sedang diproses oleh budak dengan jam milik budak itu sendiri. Jika seorang budak memiliki beberapa koneksi budak, lag terkecil digunakan.
Peralihan Otomatis Setelah Deteksi Ruang Disk Rendah
Dengan versi Server MariaDB terbaru, monitor sekarang dapat memeriksa ruang disk di backend dan mendeteksi jika server hampir habis. Ketika ini terjadi, monitor dapat diatur untuk secara otomatis beralih dari ruang disk master yang rendah. Budak juga dapat diatur ke mode pemeliharaan. Ruang disk juga merupakan faktor yang dipertimbangkan saat memilih master baru yang akan dipromosikan.
Lihat switchover_on_low_disk_space dan maintenance_on_low_disk_space untuk informasi lebih lanjut.
Fitur Reset Replikasi
replikasi ulang perintah monitor menghapus semua koneksi budak dan log biner, dan kemudian mengatur replikasi. Berguna saat data sinkron tetapi gtid tidak.
Penanganan Acara Terjadwal di Failover/Switchover/Rejoin
Peristiwa server yang diluncurkan oleh utas penjadwal peristiwa sekarang ditangani selama operasi modifikasi klaster. Lihat handle_server_events untuk informasi lebih lanjut.
Dukungan Master Eksternal
Monitor dapat mendeteksi jika server di cluster mereplikasi dari master eksternal (server yang tidak dipantau oleh monitor MaxScale). Jika server yang mereplikasi adalah server master cluster, maka cluster itu sendiri dianggap memiliki master eksternal.
Jika terjadi failover/switchover, server master baru diatur untuk mereplikasi dari server master eksternal cluster. Nama pengguna dan kata sandi untuk replikasi ditentukan dalam replica_user dan replica_password. Alamat dan port yang digunakan adalah yang ditunjukkan oleh SHOW ALL SLAVES STATUS di server master cluster lama. Dalam kasus peralihan, master lama juga berhenti mereplikasi dari server eksternal untuk mempertahankan topologi.
Setelah failover master baru mereplikasi dari master eksternal. Jika master lama yang gagal kembali online, master tersebut juga mereplikasi dari server eksternal. Untuk menormalkan situasi, aktifkan auto_rejoin atau jalankan rejoin secara manual. Ini akan mengarahkan master lama ke master cluster saat ini.
Bagaimana Failover Berguna dan Berlaku?
Failover membantu Anda meminimalkan waktu henti, melakukan perawatan harian, atau menangani perawatan yang berbahaya dan tidak diinginkan yang terkadang dapat terjadi pada saat yang tidak menguntungkan. Dengan kemampuan MaxScale untuk mengisolasi aplikasi klien dari server database backend, ia menambahkan fungsionalitas berharga yang membantu meminimalkan waktu henti.
Plugin pemantauan MaxScale terus memantau status server database backend. Plugin perutean MaxScale kemudian menggunakan informasi status ini untuk selalu merutekan kueri ke server basis data backend yang ada dalam layanan. Ia kemudian dapat mengirim kueri ke cluster database backend, bahkan jika beberapa server cluster sedang menjalani pemeliharaan atau mengalami kegagalan.
Konfigurasi tinggi MaxScale memungkinkan perubahan dalam konfigurasi cluster tetap transparan untuk aplikasi klien. Misalnya, jika server baru perlu ditambahkan atau dihapus secara administratif dari cluster master-slave, Anda cukup menambahkan konfigurasi MaxScale ke daftar server plugin monitor dan router melalui konsol maxadmin CLI. Aplikasi klien akan sama sekali tidak menyadari perubahan ini dan akan terus mengirimkan kueri database ke port mendengarkan MaxScale.
Mengatur server database dalam pemeliharaan sederhana dan mudah. Cukup lakukan perintah berikut menggunakan maxctrl dan MaxScale akan berhenti mengirim pertanyaan apa pun ke server ini. Misalnya,
maxctrl: set server DB_785 maintenance
OKKemudian periksa status server sebagai berikut,
maxctrl: list servers
┌────────┬───────────────┬──────┬─────────────┬──────────────────────┬────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼───────────────┼──────┼─────────────┼──────────────────────┼────────────┤
│ DB_783 │ 192.168.10.10 │ 3306 │ 0 │ Master, Running │ 0-43001-70 │
├────────┼───────────────┼──────┼─────────────┼──────────────────────┼────────────┤
│ DB_784 │ 192.168.10.20 │ 3306 │ 0 │ Slave, Running │ 0-43001-70 │
├────────┼───────────────┼──────┼─────────────┼──────────────────────┼────────────┤
│ DB_785 │ 192.168.10.30 │ 3306 │ 0 │ Maintenance, Running │ 0-43001-70 │
└────────┴───────────────┴──────┴─────────────┴──────────────────────┴────────────┘Setelah dalam mode pemeliharaan, MaxScale akan berhenti merutekan permintaan baru ke server. Untuk permintaan saat ini, MaxScale tidak akan menghentikan sesi ini, melainkan akan memungkinkannya untuk menyelesaikan eksekusinya dan tidak akan mengganggu kueri yang sedang berjalan saat dalam mode pemeliharaan. Juga, perhatikan bahwa mode pemeliharaan tidak persisten. Jika MaxScale dimulai ulang saat sebuah node dalam mode pemeliharaan, instance baru MariaDB MaxScale tidak akan mengikuti mode ini. Jika beberapa instans MariaDB MaxScale dikonfigurasikan untuk menggunakan node, mode pemeliharaannya harus diatur dalam setiap instans MariaDB MaxScale. Namun, jika beberapa layanan dalam satu instans MariaDB MaxScale menggunakan server, maka Anda hanya perlu mengatur mode pemeliharaan sekali di server agar semua layanan memperhatikan perubahan mode.
Setelah selesai dengan pemeliharaan Anda, cukup bersihkan server dengan perintah berikut. Misalnya,
maxctrl: clear server DB_785 maintenance
OKMemeriksa apakah sudah kembali normal, jalankan saja perintah daftar server .
Anda juga dapat menerapkan tindakan administratif tertentu melalui ClusterControl UI. Lihat contoh tangkapan layar di bawah ini:
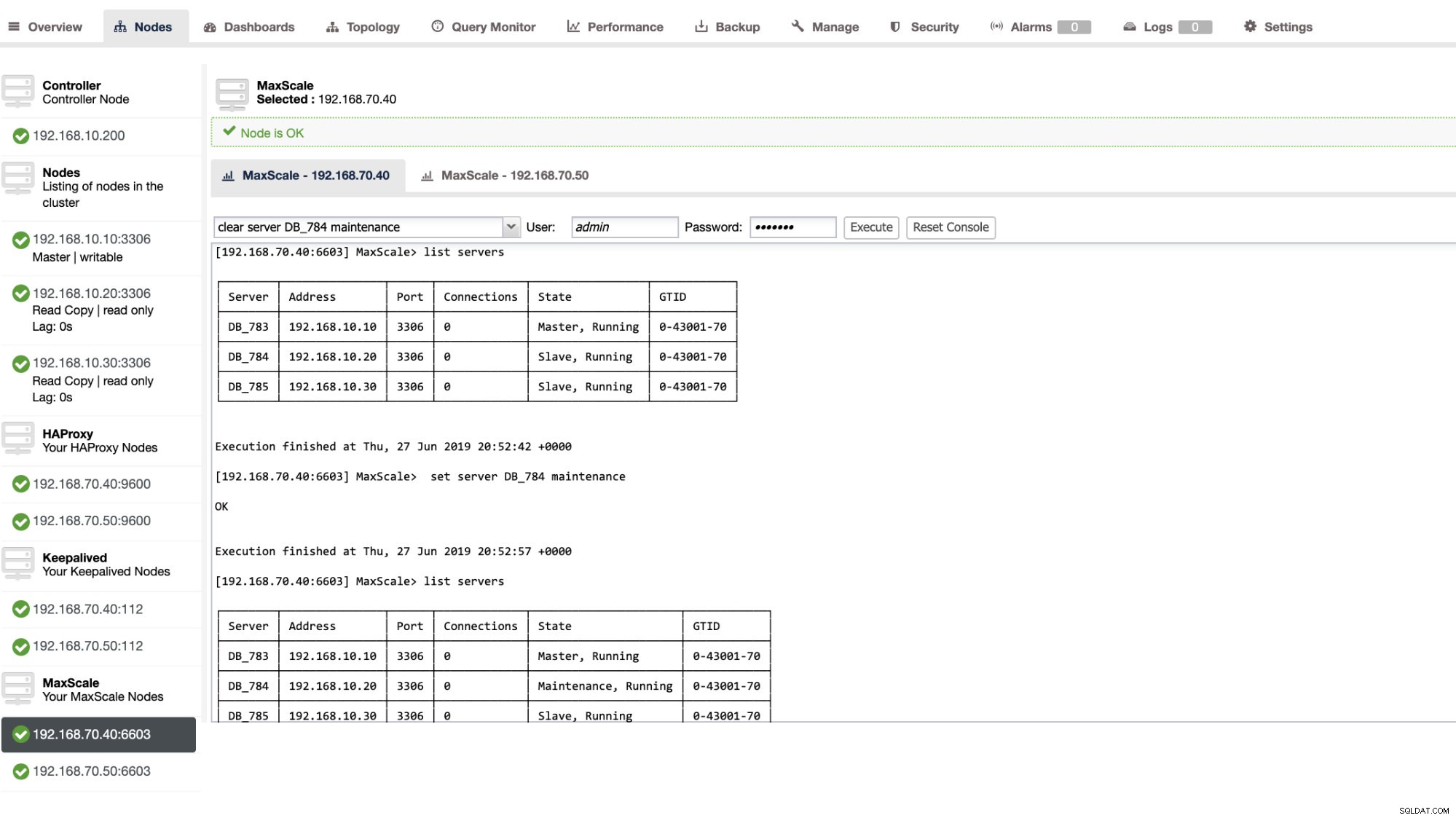
In-Action Failover MaxScale
Kegagalan Otomatis
Failover MaxScale MariaDB bekerja dengan sangat efisien dan mengonfigurasi ulang slave sesuai dengan yang diharapkan. Dalam pengujian ini, kami memiliki kumpulan file konfigurasi berikut yang dibuat dan dikelola oleh ClusterControl. Lihat di bawah:
[replication_monitor]
type=monitor
servers=DB_783,DB_784,DB_785
disk_space_check_interval=1000
disk_space_threshold=/:85
detect_replication_lag=true
enforce_read_only_slaves=true
failcount=3
auto_failover=1
auto_rejoin=true
monitor_interval=300
password=725DE70F196694B277117DC825994D44
user=maxscalecc
replication_password=5349E1268CC4AF42B919A42C8E52D185
replication_user=rpl_user
module=mariadbmonPerhatikan bahwa, hanya auto_failover dan auto_rejoin adalah variabel yang telah saya tambahkan karena ClusterControl tidak akan menambahkan ini secara default setelah Anda mengatur penyeimbang beban MaxScale (lihat blog ini tentang cara mengatur MaxScale menggunakan ClusterControl). Jangan lupa bahwa Anda perlu memulai ulang MariaDB MaxScale setelah Anda menerapkan perubahan dalam file konfigurasi Anda. Jalankan saja,
systemctl restart maxscaledan Anda siap melakukannya.
Sebelum melanjutkan uji failover, mari kita periksa dulu kesehatan cluster:
maxctrl: list servers
┌────────┬───────────────┬──────┬─────────────┬─────────────────┬────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_783 │ 192.168.10.10 │ 3306 │ 0 │ Master, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_784 │ 192.168.10.20 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_785 │ 192.168.10.30 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
└────────┴───────────────┴──────┴─────────────┴─────────────────┴────────────┘Tampak hebat!
Saya membunuh master hanya dengan perintah pembunuh murni KILL -9 $(pidof mysqld) di master node saya dan melihat, tidak mengherankan, monitor dengan cepat memperhatikan ini dan memicu failover. Lihat lognya sebagai berikut:
2019-06-28 06:39:14.306 error : (mon_log_connect_error): Monitor was unable to connect to server DB_783[192.168.10.10:3306] : 'Can't connect to MySQL server on '192.168.10.10' (115)'
2019-06-28 06:39:14.329 notice : (mon_log_state_change): Server changed state: DB_783[192.168.10.10:3306]: master_down. [Master, Running] -> [Down]
2019-06-28 06:39:14.329 warning: (handle_auto_failover): Master has failed. If master status does not change in 2 monitor passes, failover begins.
2019-06-28 06:39:15.011 notice : (select_promotion_target): Selecting a server to promote and replace 'DB_783'. Candidates are: 'DB_784', 'DB_785'.
2019-06-28 06:39:15.011 warning: (warn_replication_settings): Slave 'DB_784' has gtid_strict_mode disabled. Enabling this setting is recommended. For more information, see https://mariadb.com/kb/en/library/gtid/#gtid_strict_mode
2019-06-28 06:39:15.012 warning: (warn_replication_settings): Slave 'DB_785' has gtid_strict_mode disabled. Enabling this setting is recommended. For more information, see https://mariadb.com/kb/en/library/gtid/#gtid_strict_mode
2019-06-28 06:39:15.012 notice : (select_promotion_target): Selected 'DB_784'.
2019-06-28 06:39:15.012 notice : (handle_auto_failover): Performing automatic failover to replace failed master 'DB_783'.
2019-06-28 06:39:15.017 notice : (redirect_slaves_ex): Redirecting 'DB_785' to replicate from 'DB_784' instead of 'DB_783'.
2019-06-28 06:39:15.024 notice : (redirect_slaves_ex): All redirects successful.
2019-06-28 06:39:15.527 notice : (wait_cluster_stabilization): All redirected slaves successfully started replication from 'DB_784'.
2019-06-28 06:39:15.527 notice : (handle_auto_failover): Failover 'DB_783' -> 'DB_784' performed.
2019-06-28 06:39:15.634 notice : (mon_log_state_change): Server changed state: DB_784[192.168.10.20:3306]: new_master. [Slave, Running] -> [Master, Running]
2019-06-28 06:39:20.165 notice : (mon_log_state_change): Server changed state: DB_783[192.168.10.10:3306]: slave_up. [Down] -> [Slave, Running]Sekarang mari kita lihat kesehatan clusternya,
maxctrl: list servers
┌────────┬───────────────┬──────┬─────────────┬─────────────────┬────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_783 │ 192.168.10.10 │ 3306 │ 0 │ Down │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_784 │ 192.168.10.20 │ 3306 │ 0 │ Master, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_785 │ 192.168.10.30 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
└────────┴───────────────┴──────┴─────────────┴─────────────────┴────────────┘Node 192.168.10.10 yang sebelumnya master telah down. Saya mencoba memulai ulang dan melihat apakah bergabung kembali secara otomatis akan terpicu, dan seperti yang Anda perhatikan di log pada waktu 28-06-2019 06:39:20.165, begitu cepat untuk menangkap status node dan kemudian mengatur konfigurasi secara otomatis tanpa kerumitan bagi DBA untuk mengaktifkannya.
Sekarang, terakhir memeriksa statusnya, tampaknya berfungsi sempurna seperti yang diharapkan. Lihat di bawah:
maxctrl: list servers
┌────────┬───────────────┬──────┬─────────────┬─────────────────┬────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_783 │ 192.168.10.10 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_784 │ 192.168.10.20 │ 3306 │ 0 │ Master, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_785 │ 192.168.10.30 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
└────────┴───────────────┴──────┴─────────────┴─────────────────┴────────────┘Mantan Master Saya Telah Diperbaiki dan Dipulihkan dan Saya Ingin Beralih
Beralih ke master sebelumnya juga tidak merepotkan. Anda dapat mengoperasikan ini dengan maxctrl (atau maxadmin di versi MaxScale sebelumnya) atau melalui ClusterControl UI (seperti yang ditunjukkan sebelumnya).
Mari kita lihat keadaan sebelumnya dari kesehatan cluster replikasi sebelumnya, dan ingin mengganti 192.168.10.10 (saat ini budak), kembali ke keadaan masternya. Sebelum melanjutkan, Anda mungkin perlu mengidentifikasi terlebih dahulu monitor yang akan Anda gunakan. Anda dapat memverifikasi ini dengan perintah berikut di bawah ini:
maxctrl: list monitors
┌─────────────────────┬─────────┬────────────────────────┐
│ Monitor │ State │ Servers │
├─────────────────────┼─────────┼────────────────────────┤
│ replication_monitor │ Running │ DB_783, DB_784, DB_785 │
└─────────────────────┴─────────┴────────────────────────┘Setelah Anda memilikinya, Anda dapat melakukan perintah berikut untuk beralih:
maxctrl: call command mariadbmon switchover replication_monitor DB_783 DB_784
OKKemudian periksa kembali status cluster,
maxctrl: list servers
┌────────┬───────────────┬──────┬─────────────┬─────────────────┬────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_783 │ 192.168.10.10 │ 3306 │ 0 │ Master, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_784 │ 192.168.10.20 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_785 │ 192.168.10.30 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
└────────┴───────────────┴──────┴─────────────┴─────────────────┴────────────┘Terlihat sempurna!
Log akan dengan jelas menunjukkan kepada Anda bagaimana kelanjutannya dan rangkaian tindakannya selama peralihan. Lihat detailnya di bawah ini:
2019-06-28 07:03:48.064 error : (switchover_prepare): 'DB_784' is not a valid promotion target for switchover because it is already the master.
2019-06-28 07:03:48.064 error : (manual_switchover): Switchover cancelled.
2019-06-28 07:04:30.700 notice : (create_start_slave): Slave connection from DB_784 to [192.168.10.10]:3306 created and started.
2019-06-28 07:04:30.700 notice : (redirect_slaves_ex): Redirecting 'DB_785' to replicate from 'DB_783' instead of 'DB_784'.
2019-06-28 07:04:30.708 notice : (redirect_slaves_ex): All redirects successful.
2019-06-28 07:04:31.209 notice : (wait_cluster_stabilization): All redirected slaves successfully started replication from 'DB_783'.
2019-06-28 07:04:31.209 notice : (manual_switchover): Switchover 'DB_784' -> 'DB_783' performed.
2019-06-28 07:04:31.318 notice : (mon_log_state_change): Server changed state: DB_783[192.168.10.10:3306]: new_master. [Slave, Running] -> [Master, Running]
2019-06-28 07:04:31.318 notice : (mon_log_state_change): Server changed state: DB_784[192.168.10.20:3306]: new_slave. [Master, Running] -> [Slave, Running]Dalam kasus peralihan yang salah, itu tidak akan dilanjutkan dan karenanya akan menghasilkan kesalahan seperti yang ditunjukkan pada log di atas. Jadi Anda akan aman dan tidak ada kejutan menakutkan sama sekali.
Menjadikan MaxScale Anda Sangat Tersedia
Meskipun agak di luar topik terkait failover, saya ingin menambahkan beberapa poin berharga di sini sehubungan dengan ketersediaan tinggi dan bagaimana hal itu terkait dengan failover MariaDB MaxScale.
Membuat MaxScale Anda sangat tersedia adalah bagian penting jika sistem Anda mogok, mengalami kerusakan disk, atau kerusakan mesin virtual. Situasi ini tidak dapat dihindari dan dapat memengaruhi status penyiapan failover otomatis Anda saat siklus pemeliharaan tak terduga ini terjadi.
Untuk lingkungan tipe kluster replikasi, ini sangat bermanfaat dan sangat disarankan untuk pengaturan MaxScale tertentu. Tujuannya adalah, hanya satu instance MaxScale yang diizinkan untuk memodifikasi cluster pada waktu tertentu. Jika Anda memiliki setup dengan Keepalive, ini adalah tempat instance dengan status MASTER. MaxScale sendiri tidak mengetahui statusnya, tetapi dengan maxctrl (atau maxadmin di versi sebelumnya) dapat mengatur instance MaxScale ke mode pasif. Pada versi 2.2.2, MaxScale pasif berperilaku mirip dengan yang aktif dengan perbedaan bahwa ia tidak akan melakukan failover, switchover, atau bergabung kembali. Bahkan versi manual dari perintah ini akan berakhir dengan kesalahan. Perbedaan mode pasif/aktif dapat diperluas di masa mendatang, jadi pantau terus perubahan tersebut di MaxScale. Untuk melakukannya, cukup lakukan hal berikut:
maxctrl: alter maxscale passive true
OKAnda dapat memverifikasi ini setelahnya dengan menjalankan perintah di bawah ini:
[example@sqldat.com vagrant]# maxctrl -u admin -p mariadb -h 127.0.0.1:8989 show maxscale|grep 'passive'
│ │ "passive": true, │Jika Anda ingin melihat cara menyiapkan sangat tersedia dengan Keepalive, silakan periksa posting ini dari MariaDB.
Penanganan VIP
Selain itu, karena MaxScale tidak memiliki penanganan VIP bawaan, Anda dapat menggunakan Keepalive untuk menanganinya untuk Anda. Anda bisa menggunakan virtual_ipaddress yang ditetapkan ke node status MASTER. Ini kemungkinan akan muncul dengan manajemen IP virtual seperti yang dilakukan MHA dengan variabel master_failover_script. Seperti yang disebutkan sebelumnya, lihat entri blog penyiapan Keepalive dengan MaxScale ini oleh MariaDB.
Kesimpulan
MariaDB MaxScale kaya fitur dan memiliki banyak kemampuan, tidak hanya terbatas sebagai proxy dan penyeimbang beban, tetapi juga menawarkan mekanisme failover yang dicari oleh organisasi besar. Ini hampir merupakan perangkat lunak satu ukuran untuk semua, tetapi tentu saja dilengkapi dengan keterbatasan yang mungkin diperlukan oleh aplikasi tertentu dibandingkan dengan penyeimbang beban lainnya seperti ProxySQL.
ClusterControl juga menawarkan mekanisme auto-failover dan master deteksi otomatis, ditambah pemulihan cluster dan node dengan kemampuan untuk menerapkan Maxscale dan teknologi penyeimbangan beban lainnya.
Masing-masing alat ini memiliki beragam fitur dan fungsinya, tetapi MariaDB MaxScale didukung dengan baik dalam ClusterControl dan dapat digunakan dengan layak bersama dengan Keepalive, HAProxy untuk membantu Anda mempercepat tugas rutin harian Anda.