Dalam posting sebelumnya, kami membahas bagaimana Anda dapat mengendalikan proses failover di ClusterControl dengan memanfaatkan daftar putih dan daftar hitam. Dalam posting ini, kita akan membahas konsep serupa. Namun kali ini kita akan fokus pada integrasi dengan skrip dan aplikasi eksternal melalui berbagai pengait yang disediakan oleh ClusterControl.
Lingkungan infrastruktur dapat dibangun dengan cara yang berbeda, karena seringkali ada banyak pilihan untuk dipilih untuk bagian tertentu dari teka-teki. Bagaimana kita mendefinisikan node database mana yang akan kita tulis? Apakah Anda menggunakan IP virtual? Apakah Anda menggunakan semacam penemuan layanan? Mungkin Anda menggunakan entri DNS dan mengubah catatan A saat diperlukan? Bagaimana dengan lapisan proxy? Apakah Anda mengandalkan nilai 'read_only' untuk proxy Anda untuk memutuskan penulis, atau mungkin Anda membuat perubahan yang diperlukan secara langsung dalam konfigurasi proxy? Bagaimana lingkungan Anda menangani peralihan? Bisakah Anda melanjutkan dan menjalankannya, atau mungkin Anda harus mengambil beberapa tindakan awal sebelumnya? Misalnya, menghentikan beberapa proses lain sebelum Anda benar-benar dapat melakukan peralihan?
Perangkat lunak failover tidak mungkin dikonfigurasikan sebelumnya untuk mencakup semua pengaturan berbeda yang dapat dibuat orang. Ini adalah alasan utama untuk menyediakan cara yang berbeda untuk menghubungkan ke dalam proses failover. Dengan cara ini Anda dapat menyesuaikannya dan memungkinkan untuk menangani semua seluk-beluk pengaturan Anda. Dalam posting blog ini, kita akan melihat bagaimana proses failover ClusterControl dapat dikustomisasi menggunakan skrip sebelum dan sesudah failover yang berbeda. Kami juga akan membahas beberapa contoh tentang apa yang dapat dicapai dengan penyesuaian tersebut.
Mengintegrasikan ClusterControl
ClusterControl menyediakan beberapa kait yang dapat digunakan untuk memasang skrip eksternal. Di bawah ini Anda akan menemukan daftar mereka dengan beberapa penjelasan.
- Replication_onfail_failover_script - skrip ini dijalankan segera setelah diketahui bahwa failover diperlukan. Jika skrip mengembalikan bukan nol, itu akan memaksa failover untuk dibatalkan. Jika skrip ditentukan tetapi tidak ditemukan, failover akan dibatalkan. Empat argumen diberikan ke skrip:arg1='all server' arg2='oldmaster' arg3='candidate', arg4='slaves of oldmaster' dan diteruskan seperti ini:'scripname arg1 arg2 arg3 arg4'. Skrip harus dapat diakses di pengontrol dan dapat dieksekusi.
- Replication_pre_failover_script - skrip ini dijalankan sebelum failover terjadi, tetapi setelah kandidat dipilih dan dimungkinkan untuk melanjutkan proses failover. Jika skrip mengembalikan bukan nol, itu akan memaksa failover untuk dibatalkan. Jika skrip ditentukan tetapi tidak ditemukan, failover akan dibatalkan. Skrip harus dapat diakses di pengontrol dan dapat dieksekusi.
- Replication_post_failover_script - skrip ini dijalankan setelah kegagalan terjadi. Jika skrip mengembalikan bukan nol, Peringatan akan ditulis di log pekerjaan. Skrip harus dapat diakses di pengontrol dan dapat dieksekusi.
- Replication_post_unsuccessful_failover_script - Skrip ini dijalankan setelah upaya failover gagal. Jika skrip mengembalikan bukan nol, Peringatan akan ditulis di log pekerjaan. Skrip harus dapat diakses di pengontrol dan dapat dieksekusi.
- Replication_failed_reslave_failover_script - skrip ini dijalankan setelah master baru dipromosikan dan jika reslaving budak ke master baru gagal. Jika skrip mengembalikan bukan nol, Peringatan akan ditulis di log pekerjaan. Skrip harus dapat diakses di pengontrol dan dapat dieksekusi.
- Replication_pre_switchover_script - skrip ini dijalankan sebelum peralihan terjadi. Jika skrip mengembalikan bukan nol, itu akan memaksa peralihan gagal. Jika skrip ditentukan tetapi tidak ditemukan, peralihan akan dibatalkan. Skrip harus dapat diakses di pengontrol dan dapat dieksekusi.
- Replication_post_switchover_script - skrip ini dijalankan setelah peralihan terjadi. Jika skrip mengembalikan bukan nol, Peringatan akan ditulis di log pekerjaan. Skrip harus dapat diakses di pengontrol dan dapat dieksekusi.
Seperti yang Anda lihat, kait mencakup sebagian besar kasus di mana Anda mungkin ingin mengambil beberapa tindakan - sebelum dan sesudah peralihan, sebelum dan sesudah failover, ketika reslave gagal atau ketika failover gagal. Semua skrip dipanggil dengan empat argumen (yang mungkin atau mungkin tidak ditangani dalam skrip, skrip tidak diharuskan untuk menggunakan semuanya):semua server, nama host (atau IP - seperti yang didefinisikan dalam ClusterControl) master lama, nama host (atau IP - seperti yang didefinisikan dalam ClusterControl) calon master dan yang keempat, semua replika master lama. Opsi tersebut harus memungkinkan untuk menangani sebagian besar kasus.
Semua kait tersebut harus didefinisikan dalam file konfigurasi untuk cluster tertentu (/etc/cmon.d/cmon_X.cnf di mana X adalah id cluster). Contohnya mungkin terlihat seperti ini:
replication_pre_failover_script=/usr/bin/stonith.py
replication_post_failover_script=/usr/bin/vipmove.shTentu saja, skrip yang dipanggil harus dapat dieksekusi, jika tidak cmon tidak akan dapat mengeksekusinya. Sekarang mari kita luangkan waktu sejenak dan melalui proses failover di ClusterControl dan melihat kapan skrip eksternal dijalankan.
Proses Kegagalan di ClusterControl
Kami mendefinisikan semua kait yang tersedia:
replication_onfail_failover_script=/tmp/1.sh
replication_pre_failover_script=/tmp/2.sh
replication_post_failover_script=/tmp/3.sh
replication_post_unsuccessful_failover_script=/tmp/4.sh
replication_failed_reslave_failover_script=/tmp/5.sh
replication_pre_switchover_script=/tmp/6.sh
replication_post_switchover_script=/tmp/7.shSetelah ini, Anda harus memulai kembali proses cmon. Setelah selesai, kami siap untuk menguji failover. Topologi aslinya terlihat seperti ini:
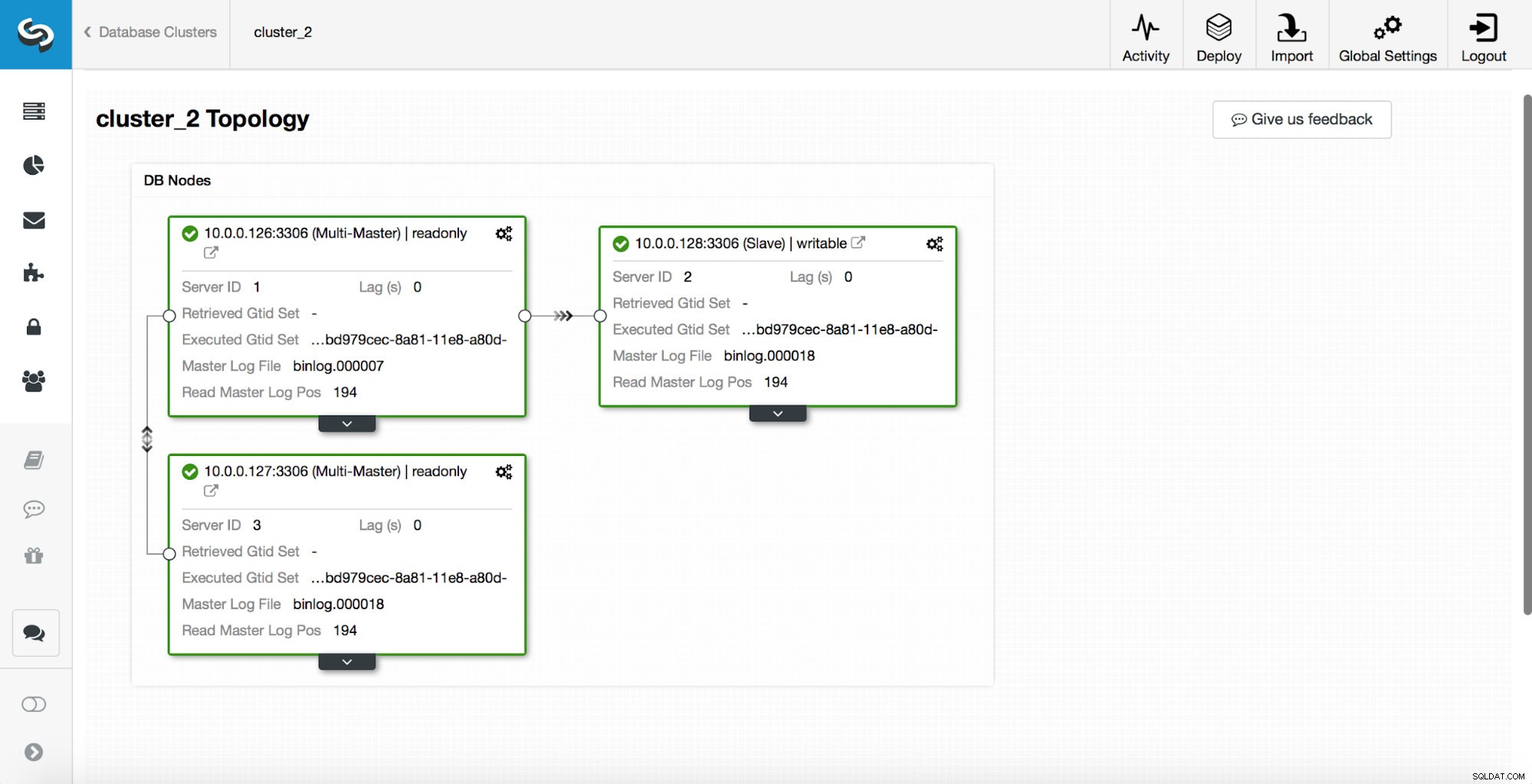
Seorang master telah terbunuh dan proses failover dimulai. Harap dicatat, entri log yang lebih baru ada di bagian atas sehingga Anda ingin mengikuti failover dari bawah ke atas.
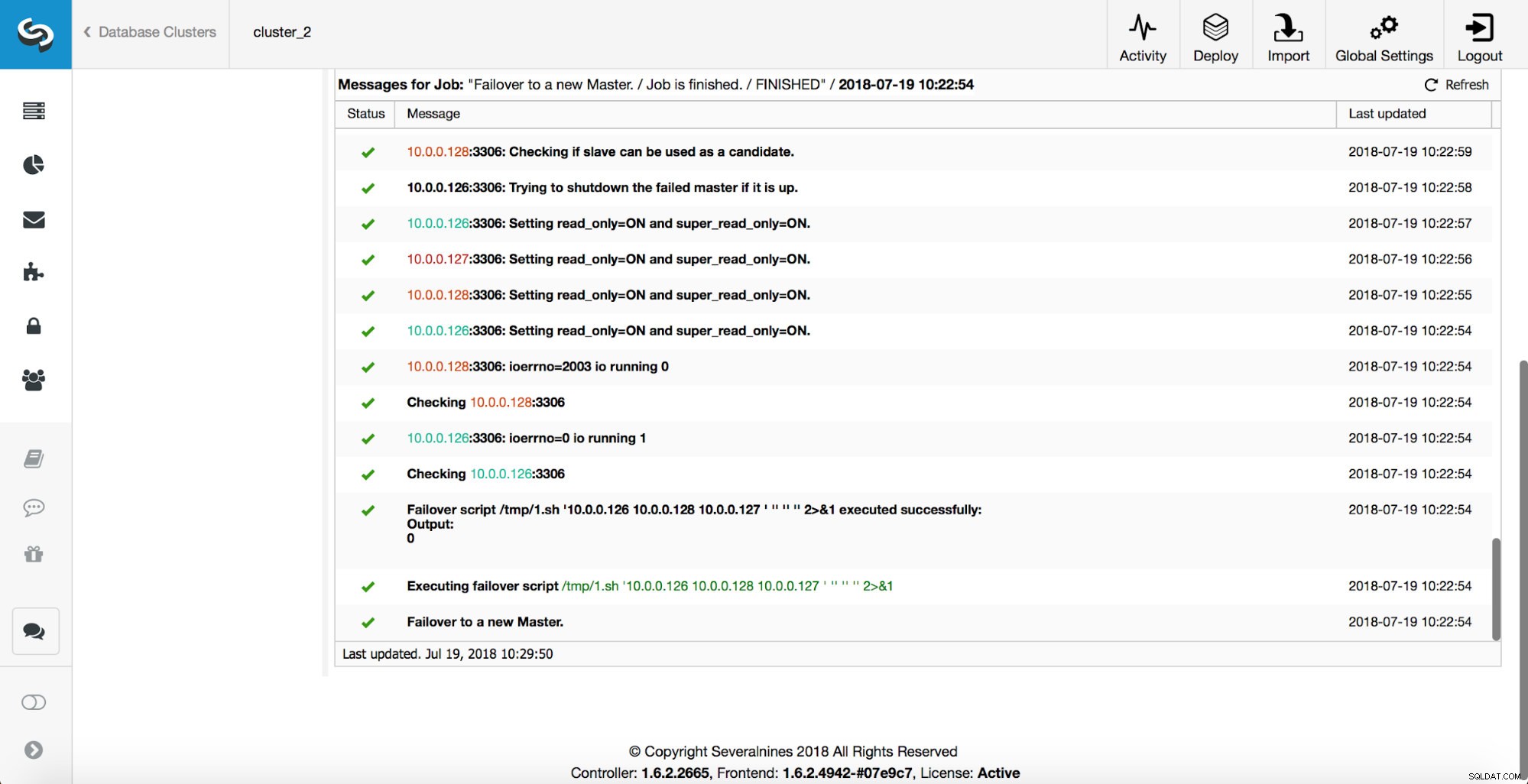
Seperti yang Anda lihat, segera setelah pekerjaan failover dimulai, itu memicu kait 'replication_onfail_failover_script'. Kemudian, semua host yang dapat dijangkau ditandai sebagai read_only dan ClusterControl mencoba untuk mencegah master lama berjalan.
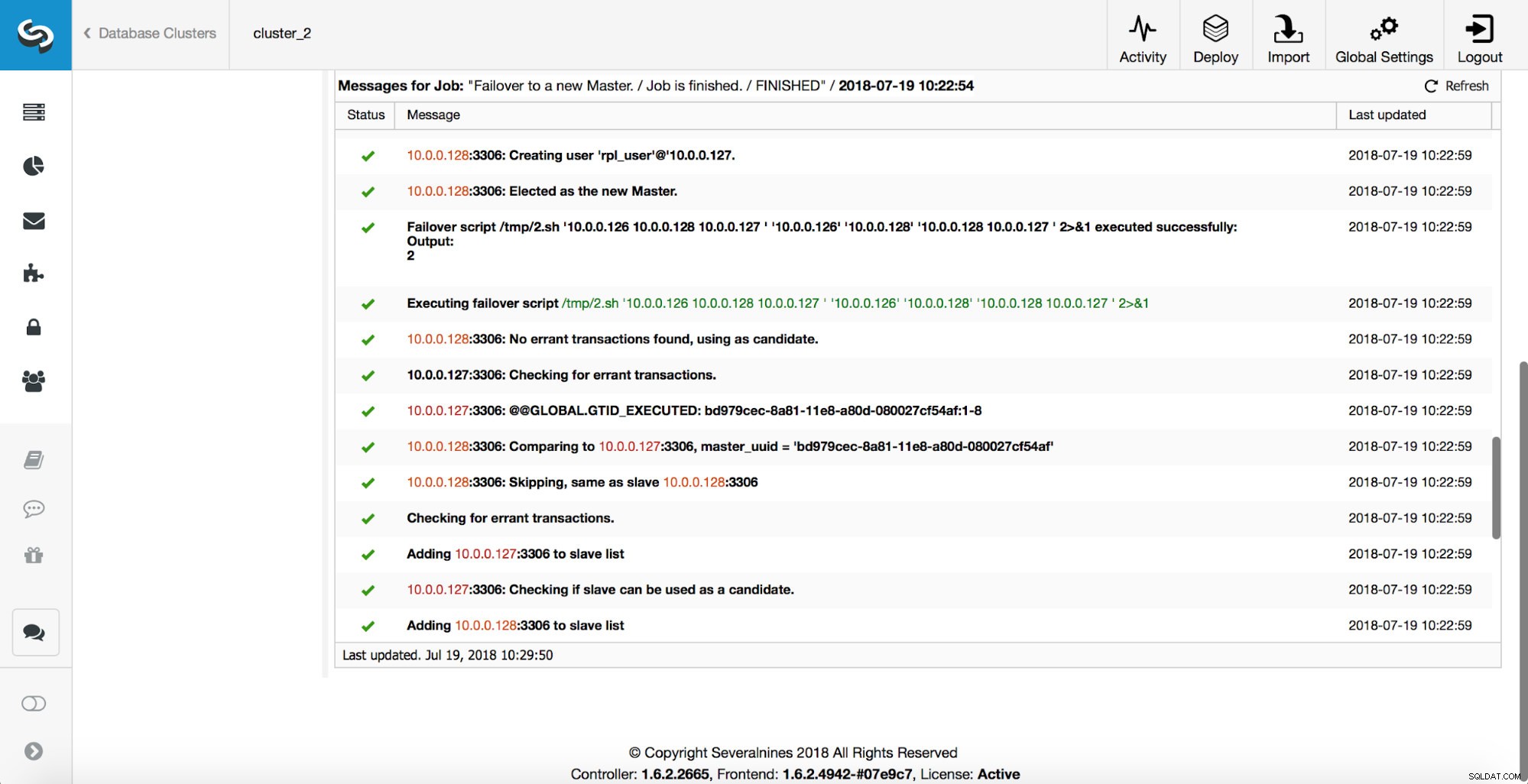
Selanjutnya, kandidat master dipilih, pemeriksaan kewarasan dijalankan. Setelah dikonfirmasi, kandidat master dapat digunakan sebagai master baru, 'replication_pre_failover_script' dijalankan.
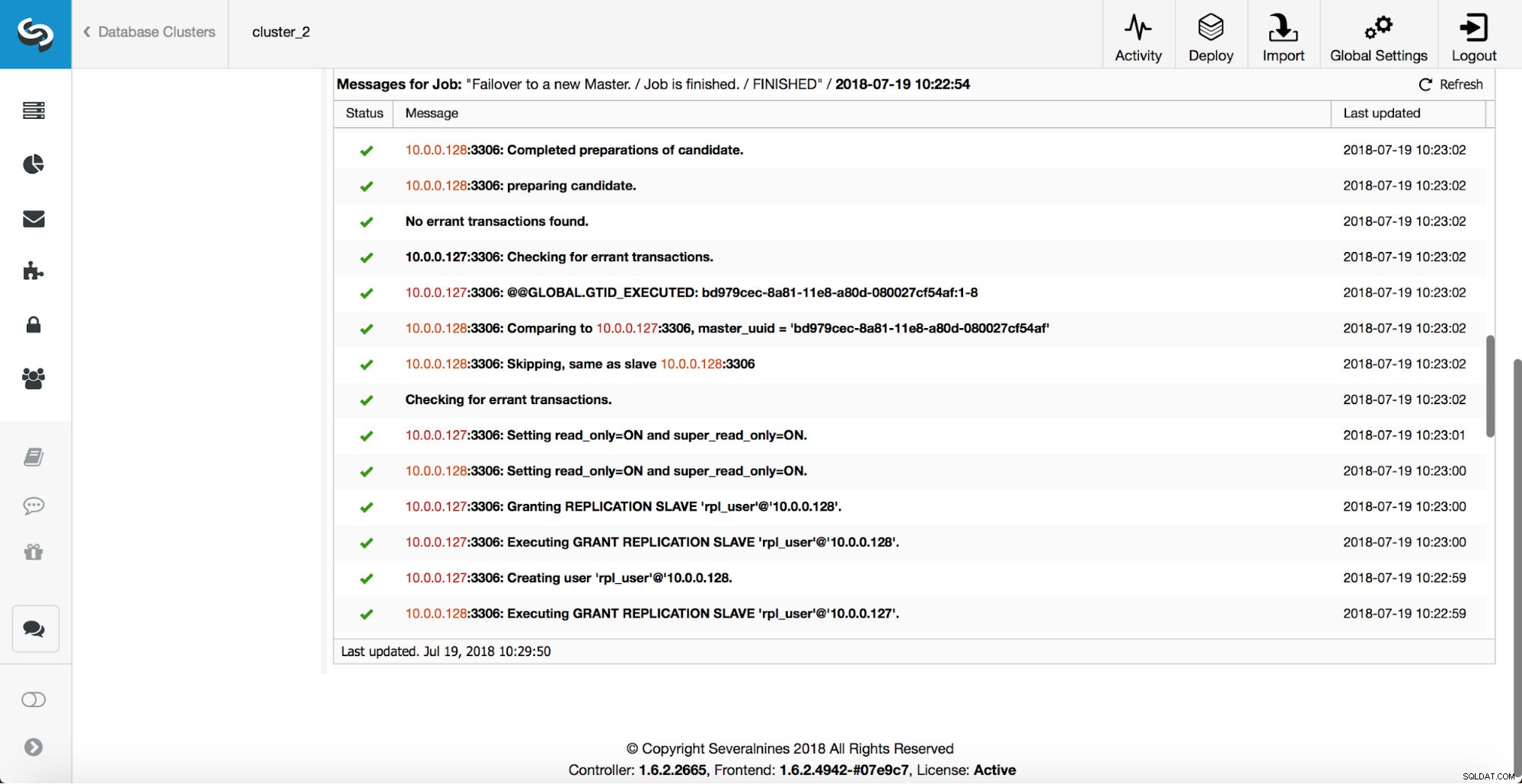
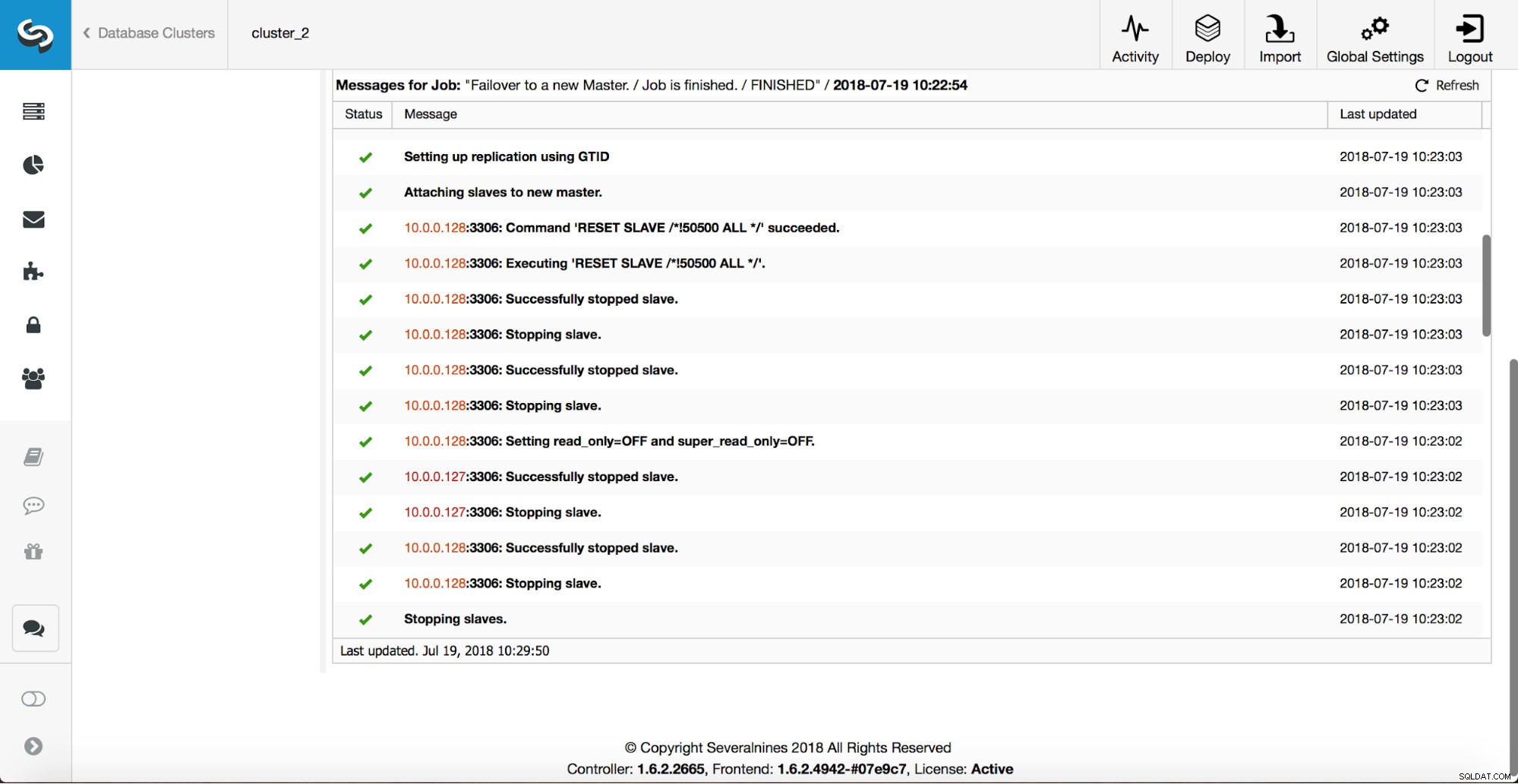
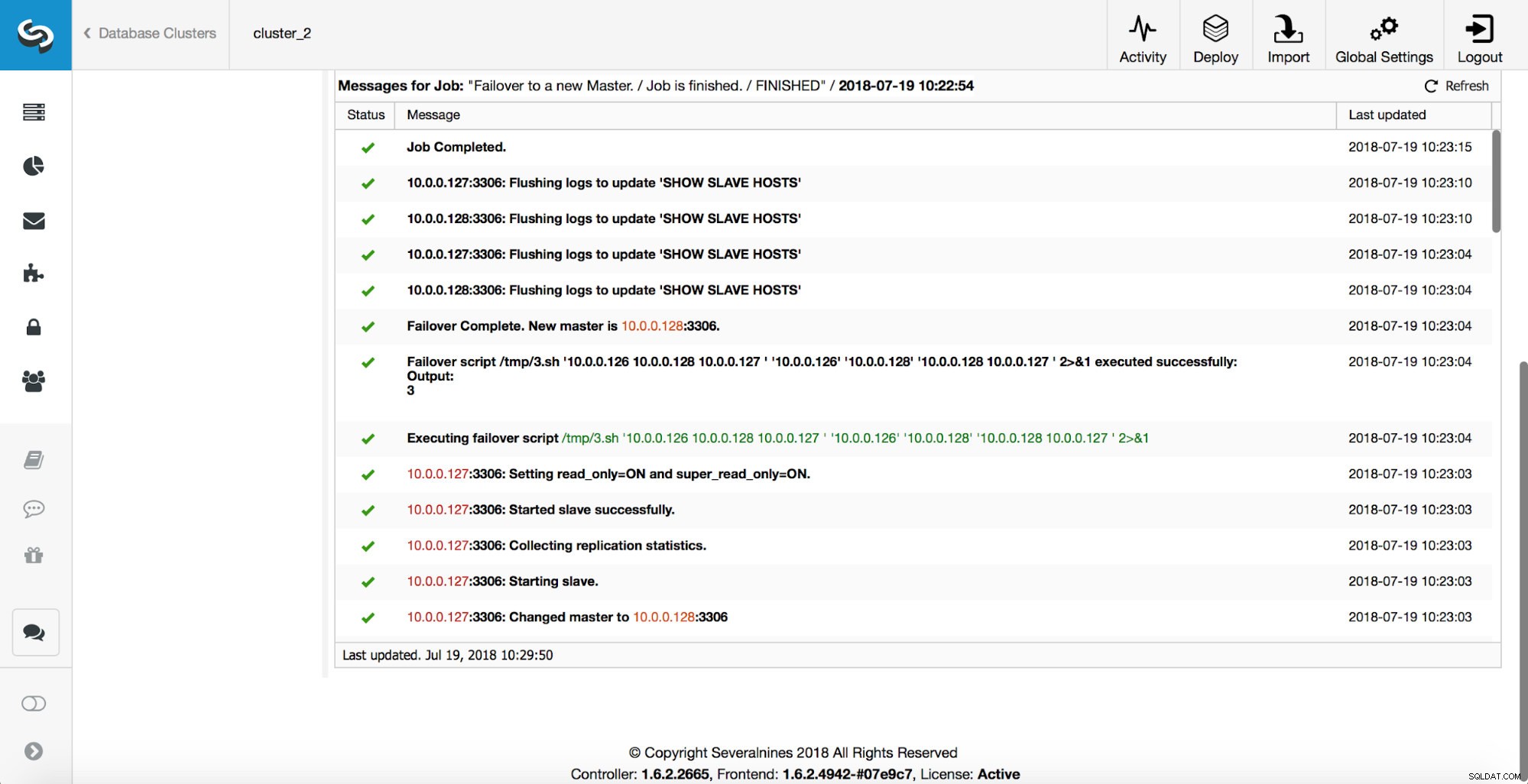
Lebih banyak pemeriksaan dilakukan, replika dihentikan dan dikeluarkan dari master baru. Akhirnya, setelah failover selesai, hook terakhir, 'replication_post_failover_script', dipicu.
Kapan Hooks Bisa Berguna?
Di bagian ini, kita akan membahas beberapa contoh kasus yang mungkin merupakan ide bagus untuk mengimplementasikan skrip eksternal. Kami tidak akan membahas detail apa pun karena terlalu terkait erat dengan lingkungan tertentu. Ini akan lebih merupakan daftar saran yang mungkin berguna untuk diterapkan.
skrip STONITH
Shoot The Other Node In The Head (STONITH) adalah proses memastikan bahwa master lama, yang sudah mati, akan tetap mati (dan ya.. kami tidak suka zombie berkeliaran di infrastruktur kami). Hal terakhir yang mungkin Anda inginkan adalah memiliki master lama yang tidak responsif yang kemudian kembali online dan, sebagai hasilnya, Anda berakhir dengan dua master yang dapat ditulis. Ada tindakan pencegahan yang dapat Anda ambil untuk memastikan master lama tidak akan digunakan bahkan jika muncul lagi, dan lebih aman untuk tetap offline. Cara bagaimana memastikannya akan berbeda dari lingkungan ke lingkungan. Oleh karena itu, kemungkinan besar, tidak akan ada dukungan bawaan untuk STONITH di alat failover. Bergantung pada lingkungannya, Anda mungkin ingin menjalankan perintah CLI yang akan menghentikan (dan bahkan menghapus) VM yang menjalankan master lama. Jika Anda memiliki pengaturan lokal, Anda mungkin memiliki kontrol lebih besar atas perangkat keras. Dimungkinkan untuk menggunakan semacam manajemen jarak jauh (Lampu mati terintegrasi atau akses jarak jauh lainnya ke server). Anda mungkin juga memiliki akses ke soket daya yang dapat diatur dan mematikan daya di salah satunya untuk memastikan server tidak akan pernah memulai lagi tanpa campur tangan manusia.
Penemuan Layanan
Kami telah menyebutkan sedikit tentang penemuan layanan. Ada banyak cara untuk menyimpan informasi tentang topologi replikasi dan mendeteksi host mana yang merupakan master. Jelas, salah satu opsi yang lebih populer adalah menggunakan etc.d atau Consul untuk menyimpan data tentang topologi saat ini. Dengan itu, aplikasi atau proxy dapat mengandalkan data ini untuk mengirim lalu lintas ke node yang benar. ClusterControl (seperti kebanyakan alat yang mendukung penanganan failover) tidak memiliki integrasi langsung dengan etc.d atau Consul. Tugas memperbarui data topologi ada pada pengguna. Dia dapat menggunakan kait seperti Replication_post_failover_script atau Replication_post_switchover_script untuk menjalankan beberapa skrip dan melakukan perubahan yang diperlukan. Solusi lain yang cukup umum adalah menggunakan DNS untuk mengarahkan lalu lintas ke instance yang benar. Jika Anda akan menjaga Time-To-Live dari catatan DNS rendah, Anda harus dapat menentukan domain, yang akan menunjuk ke master Anda (yaitu writes.cluster1.example.com). Ini memerlukan perubahan pada catatan DNS dan, sekali lagi, kait seperti Replication_post_failover_script atau Replication_post_switchover_script dapat sangat membantu untuk membuat modifikasi yang diperlukan setelah terjadi failover.
Konfigurasi Ulang Proksi
Setiap server proxy yang digunakan harus mengirimkan lalu lintas ke instance yang benar. Bergantung pada proxy itu sendiri, bagaimana pendeteksian master dilakukan dapat (sebagian) di-hardcode atau dapat terserah pengguna untuk menentukan apa pun yang dia suka. Mekanisme failover ClusterControl dirancang sedemikian rupa sehingga terintegrasi dengan baik dengan proxy yang disebarkan dan dikonfigurasi. Masih mungkin terjadi bahwa ada proxy di tempat, yang tidak diinstal oleh ClusterControl dan mereka memerlukan beberapa tindakan manual untuk dilakukan saat failover sedang dijalankan. Proksi tersebut juga dapat diintegrasikan dengan proses failover ClusterControl melalui skrip dan kait eksternal seperti replica_post_failover_script atau replica_post_switchover_script.
Pencatatan Tambahan
Mungkin saja Anda ingin mengumpulkan data dari proses failover untuk tujuan debugging. ClusterControl memiliki cetakan ekstensif untuk memastikan mungkin untuk mengikuti proses dan mencari tahu apa yang terjadi dan mengapa. Mungkin saja Anda ingin mengumpulkan beberapa informasi khusus tambahan. Pada dasarnya semua hook dapat digunakan di sini - Anda dapat mengumpulkan status awal, sebelum failover, Anda dapat melacak status lingkungan di semua tahap failover.