Replikasi master-slave MySQL cukup mudah dan mudah diatur. Inilah alasan utama mengapa orang memilih teknologi ini sebagai langkah awal untuk mencapai ketersediaan database yang lebih baik. Namun, itu datang dengan harga kompleksitas dalam manajemen dan pemeliharaan; terserah admin untuk menjaga integritas data, terutama saat failover, failback, maintenance, upgrade dan sebagainya.
Ada banyak artikel di luar sana yang menjelaskan tentang cara melakukan operasi failover untuk pengaturan replikasi. Kami juga telah membahas topik ini dalam posting blog ini, Pengantar Failover untuk Replikasi MySQL - Blog 101. Dalam posting blog ini, kita akan membahas tugas pascabencana saat mengembalikan ke topologi asli - melakukan operasi failback.
Mengapa Kita Membutuhkan Failback?
Pemimpin replikasi (master) adalah node paling kritis dalam pengaturan replikasi. Ini membutuhkan spesifikasi perangkat keras yang baik untuk memastikannya dapat memproses penulisan, menghasilkan peristiwa replikasi, memproses pembacaan kritis, dan sebagainya dengan cara yang stabil. Ketika failover diperlukan selama pemulihan bencana atau pemeliharaan, mungkin tidak jarang menemukan kami mempromosikan pemimpin baru dengan perangkat keras yang lebih rendah. Situasi ini mungkin baik-baik saja untuk sementara, namun untuk jangka panjang, master yang ditunjuk harus dibawa kembali untuk memimpin replikasi setelah dianggap sehat.
Berlawanan dengan failover, operasi failback biasanya terjadi di lingkungan yang terkendali melalui peralihan, jarang terjadi dalam mode panik. Ini memberi tim operasi waktu untuk merencanakan dengan hati-hati dan melatih latihan untuk transisi yang mulus. Tujuan utamanya adalah mengembalikan master lama yang baik ke status terbaru dan mengembalikan pengaturan replikasi ke topologi aslinya. Namun, ada beberapa kasus di mana failback sangat penting, misalnya ketika master yang baru dipromosikan tidak bekerja seperti yang diharapkan dan mempengaruhi layanan database secara keseluruhan.
Bagaimana Melakukan Failback dengan Aman?
Setelah failover terjadi, master lama akan keluar dari rantai replikasi untuk pemeliharaan atau pemulihan. Untuk melakukan peralihan, seseorang harus melakukan hal berikut:
- Sediakan master lama ke status yang benar, dengan menjadikannya slave paling mutakhir.
- Hentikan aplikasi.
- Pastikan semua budak ditangkap.
- Promosikan master lama sebagai pemimpin baru.
- Tunjukkan kembali semua budak ke master baru.
- Mulai aplikasi dengan menulis ke master baru.
Pertimbangkan pengaturan replikasi berikut:
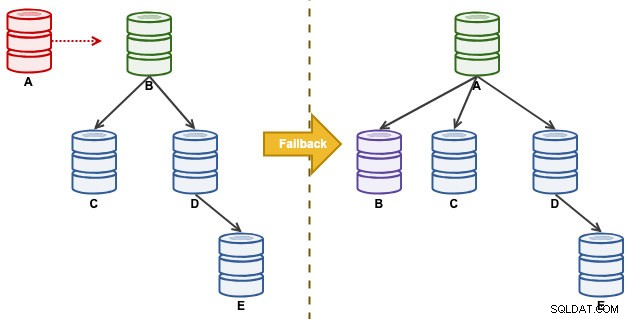
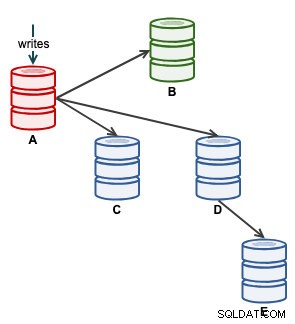
"A" adalah master sampai peristiwa penuh disk yang menyebabkan kekacauan pada rantai replikasi. Setelah kejadian failover, topologi replikasi kami dipimpin oleh B dan direplikasi ke C hingga E. Latihan failback akan mengembalikan A sebagai pemimpin dan mengembalikan topologi asli sebelum bencana. Perhatikan bahwa semua node berjalan di MySQL 8.0.15 dengan GTID diaktifkan. Versi utama yang berbeda mungkin menggunakan perintah dan langkah yang berbeda.
Seperti inilah arsitektur kita sekarang setelah failover (diambil dari tampilan Topologi ClusterControl):
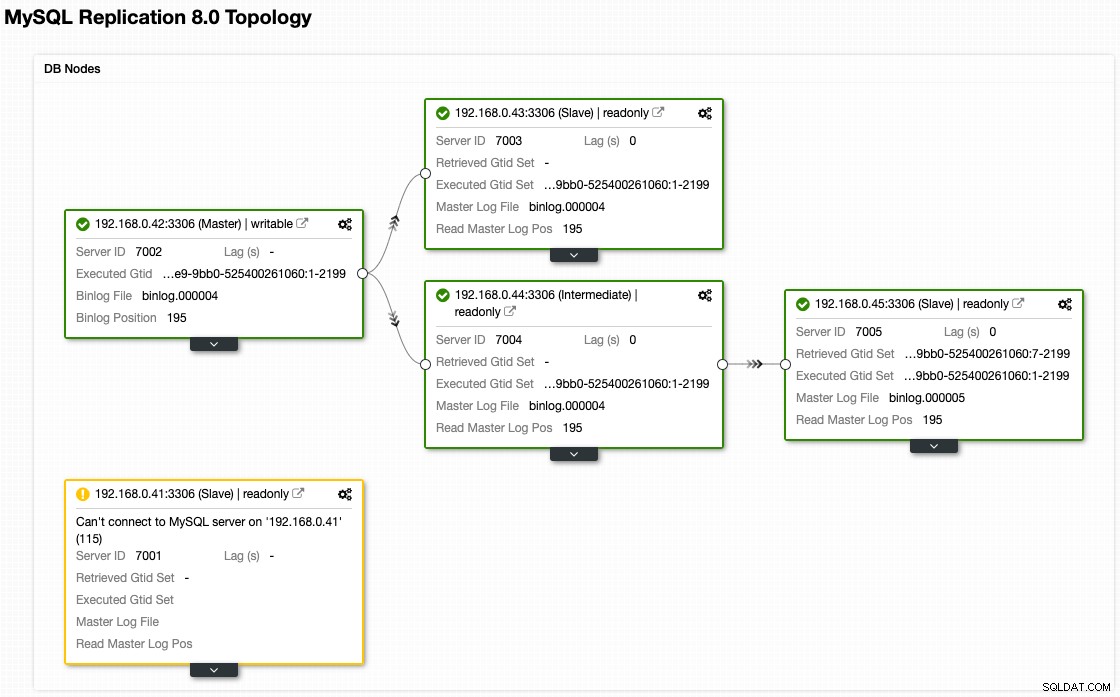
Penyediaan Node
Sebelum A dapat menjadi master, A harus diperbarui dengan status database saat ini. Cara terbaik untuk melakukannya adalah dengan mengubah A sebagai slave ke master aktif, B. Karena semua node dikonfigurasi dengan log_slave_updates=ON (artinya slave juga menghasilkan log biner), kita sebenarnya dapat memilih slave lain seperti C dan D sebagai sumber kebenaran untuk sinkronisasi awal. Namun, semakin dekat dengan master aktif, semakin baik. Ingatlah beban tambahan yang mungkin ditimbulkannya saat mengambil cadangan. Bagian ini mengambil sebagian besar dari jam failback. Bergantung pada status node dan ukuran set data, menyinkronkan master lama dapat memakan waktu (bisa berjam-jam dan berhari-hari).
Setelah masalah pada "A" diselesaikan dan siap untuk bergabung dengan rantai replikasi, langkah pertama yang terbaik adalah mencoba mereplikasi dari "B" (192.168.0.42) dengan pernyataan CHANGE MASTER:
mysql> SET GLOBAL read_only = 1; /* enable read-only */
mysql> CHANGE MASTER TO MASTER_HOST = '192.168.0.42', MASTER_USER = 'rpl_user', MASTER_PASSWORD = 'p4ss', MASTER_AUTO_POSITION = 1; /* master information to connect */
mysql> START SLAVE; /* start replication */
mysql> SHOW SLAVE STATUS\G /* check replication status */Jika replikasi berhasil, Anda akan melihat berikut ini dalam status replikasi:
Slave_IO_Running: Yes
Slave_SQL_Running: YesJika replikasi gagal, lihat Last_IO_Error atau Last_SQL_Error dari output status budak. Misalnya, jika Anda melihat kesalahan berikut:
Last_IO_Error: error connecting to master 'example@sqldat.com:3306' - retry-time: 60 retries: 2Kemudian, kita harus membuat pengguna replikasi pada master aktif saat ini, B:
mysql> CREATE USER example@sqldat.com IDENTIFIED BY 'p4ss';
mysql> GRANT REPLICATION SLAVE ON *.* TO example@sqldat.com;Kemudian, restart slave di A untuk mulai mereplikasi lagi:
mysql> STOP SLAVE;
mysql> START SLAVE;Kesalahan umum lainnya yang akan Anda lihat adalah baris ini:
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: ...Itu mungkin berarti budak mengalami masalah membaca file log biner dari master saat ini. Dalam beberapa kesempatan, budak mungkin jauh di belakang di mana peristiwa biner yang diperlukan untuk memulai replikasi telah hilang dari master saat ini, atau biner pada master telah dibersihkan selama failover dan seterusnya. Dalam hal ini, cara terbaik adalah melakukan sinkronisasi penuh dengan mengambil cadangan penuh di B dan memulihkannya di A. Di B, Anda dapat menggunakan mysqldump atau Percona Xtrabackup untuk mengambil cadangan penuh:
$ mysqldump -uroot -p --all-databases --single-transaction --triggers --routines > dump.sql # for mysqldump
$ xtrabackup --defaults-file=/etc/my.cnf --backup --parallel 1 --stream=xbstream --no-timestamp | gzip -6 - > backup-full-2019-04-16_071649.xbstream.gz # for xtrabackupTransfer file cadangan ke A, inisialisasi ulang instalasi MySQL yang ada untuk pembersihan yang tepat dan lakukan pemulihan database:
$ systemctl stop mysqld # if mysql is still running
$ rm -Rf /var/lib/mysql # wipe out old data
$ mysqld --initialize --user=mysql # initialize database
$ systemctl start mysqld # start mysql
$ grep -i 'temporary password' /var/log/mysql/mysqld.log # retrieve the temporary root password
$ mysql -uroot -p -e 'ALTER USER example@sqldat.com IDENTIFIED BY "p455word"' # mandatory root password update
$ mysql -uroot -p < dump.sql # restore the backup using the new root passwordSetelah dipulihkan, atur tautan replikasi ke master B aktif (192.168.0.42) dan aktifkan hanya-baca. Di A, jalankan pernyataan berikut:
mysql> SET GLOBAL read_only = 1; /* enable read-only */
mysql> CHANGE MASTER TO MASTER_HOST = '192.168.0.42', MASTER_USER = 'rpl_user', MASTER_PASSWORD = 'p4ss', MASTER_AUTO_POSITION = 1; /* master information to connect */
mysql> START SLAVE; /* start replication */
mysql> SHOW SLAVE STATUS\G /* check replication status */Untuk Percona Xtrabackup, silakan merujuk ke halaman dokumentasi tentang cara mengembalikan ke A. Ini melibatkan langkah prasyarat untuk menyiapkan cadangan terlebih dahulu sebelum mengganti direktori data MySQL.
Setelah A mulai mereplikasi dengan benar, pantau Seconds_Behind_Master dalam status budak. Ini akan memberi Anda gambaran tentang seberapa jauh budak telah tertinggal dan berapa lama Anda harus menunggu sebelum mengejarnya. Pada titik ini, arsitektur kita terlihat seperti ini:
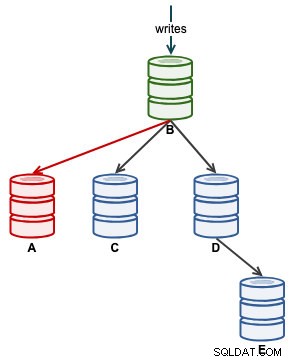
Setelah Seconds_Behind_Master kembali ke 0, saat itulah A berhasil menjadi budak terbaru.
Jika Anda menggunakan ClusterControl, Anda memiliki opsi untuk menyinkronkan ulang node dengan memulihkan dari cadangan yang ada atau membuat dan mengalirkan cadangan langsung dari node master aktif:
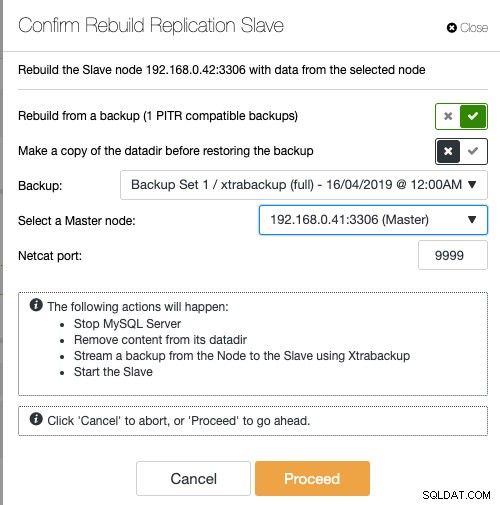
Staging slave dengan backup yang ada adalah cara yang disarankan untuk dilakukan untuk membangun slave, karena hal ini tidak akan mempengaruhi server master aktif saat menyiapkan node.
Promosikan Tuan Tua
Sebelum mempromosikan A sebagai master baru, cara teraman adalah menghentikan semua operasi penulisan pada B. Jika ini tidak memungkinkan, cukup paksa B untuk beroperasi dalam mode hanya-baca:
mysql> SET GLOBAL read_only = 'ON';
mysql> SET GLOBAL super_read_only = 'ON';Kemudian, di A, jalankan SHOW SLAVE STATUS dan periksa status replikasi berikut:
Read_Master_Log_Pos: 45889974
Exec_Master_Log_Pos: 45889974
Seconds_Behind_Master: 0
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updatesNilai Read_Master_Log_Pos dan Exec_Master_Log_Pos harus sama, sedangkan Seconds_Behind_Master adalah 0 dan statusnya harus 'Slave has read all relay log'. Pastikan bahwa semua slave telah memproses pernyataan apa pun di log relai mereka, jika tidak, Anda akan mengambil risiko bahwa kueri baru akan memengaruhi transaksi dari log relai, memicu segala macam masalah (misalnya, aplikasi dapat menghapus beberapa baris yang diakses oleh transaksi dari log relai).
Pada A, hentikan replikasi dan gunakan pernyataan RESET SLAVE ALL untuk menghapus semua konfigurasi terkait replikasi dan menonaktifkan hanya baca:
mysql> STOP SLAVE;
mysql> RESET SLAVE ALL;
mysql> SET GLOBAL read_only = 'OFF';
mysql> SET GLOBAL super_read_only = 'OFF';Pada titik ini, A siap menerima penulisan (read_only=OFF), namun slave tidak terhubung dengannya, seperti yang diilustrasikan di bawah ini:
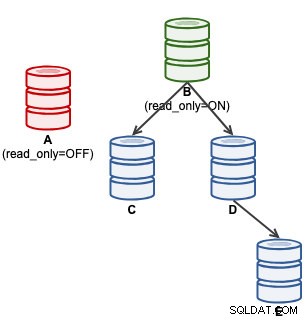
Untuk pengguna ClusterControl, mempromosikan A dapat dilakukan dengan menggunakan fitur "Promote Slave" di bawah Node Actions. ClusterControl akan secara otomatis menurunkan master B yang aktif, mempromosikan slave A sebagai master dan menunjuk kembali C dan D untuk mereplikasi dari A. B akan dikesampingkan dan pengguna harus secara eksplisit memilih "Ubah Master Replikasi" untuk bergabung kembali dengan B yang mereplikasi dari A di tahap selanjutnya .
Penunjukan Kembali Budak
Sekarang aman untuk mengubah master pada slave terkait untuk direplikasi dari A (192.168.0.41). Pada semua slave kecuali E, konfigurasikan berikut ini:
mysql> STOP SLAVE;
mysql> CHANGE MASTER TO MASTER_HOST = '192.168.0.41', MASTER_USER = 'rpl_user', MASTER_PASSWORD = 'p4ss', MASTER_AUTO_POSITION = 1;
mysql> START SLAVE;Jika Anda adalah pengguna ClusterControl, Anda dapat melewati langkah ini karena penunjukan ulang dilakukan secara otomatis saat Anda memutuskan untuk mempromosikan A sebelumnya.
Kami kemudian dapat memulai aplikasi kami untuk menulis di A. Pada titik ini, arsitektur kami terlihat seperti ini:
Dari tampilan topologi ClusterControl, kami telah memulihkan cluster replikasi kami ke arsitektur aslinya yang terlihat seperti ini:
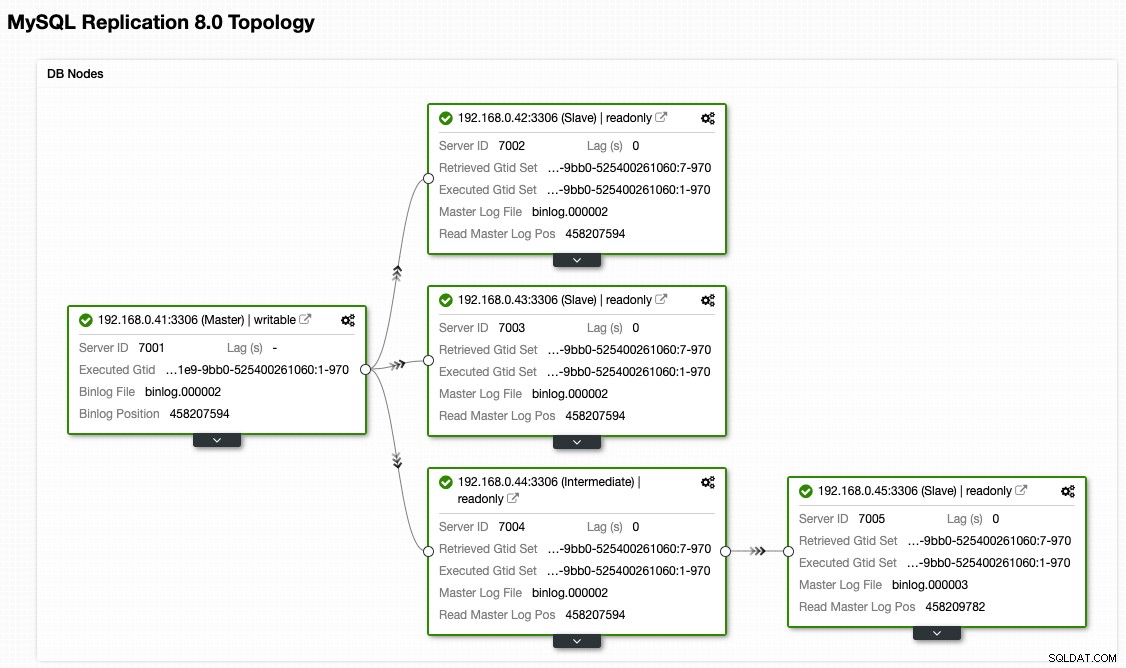
Perhatikan bahwa latihan failback jauh lebih kecil risikonya jika dibandingkan dengan failover. Penting untuk menjadwalkan latihan ini selama jam tidak sibuk untuk meminimalkan dampaknya terhadap bisnis Anda.
Pemikiran Akhir
Operasi failover dan failback harus dilakukan dengan hati-hati. Operasi ini cukup sederhana jika Anda memiliki sejumlah kecil node tetapi untuk beberapa node dengan rantai replikasi yang kompleks, ini bisa menjadi latihan yang berisiko dan rawan kesalahan. Kami juga menunjukkan bagaimana ClusterControl dapat digunakan untuk menyederhanakan operasi kompleks dengan menjalankannya melalui UI, ditambah tampilan topologi divisualisasikan secara real-time sehingga Anda memiliki pemahaman tentang topologi replikasi yang ingin Anda buat.