Presto adalah mesin SQL open-source, terdistribusi paralel untuk pemrosesan data besar. Ini dikembangkan dari bawah ke atas oleh Facebook. Rilis internal pertama terjadi pada tahun 2013 dan merupakan solusi yang cukup revolusioner untuk masalah data besar mereka.
Dengan ratusan server geo-located dan petabyte data, Facebook mulai mencari platform alternatif untuk cluster Hadoop mereka. Tim infrastruktur mereka ingin mengurangi waktu yang dibutuhkan untuk menjalankan tugas batch analitik dan menyederhanakan pengembangan pipeline dengan menggunakan bahasa pemrograman yang dikenal luas di organisasi - SQL.
Menurut yayasan Presto, “Facebook menggunakan Presto untuk kueri interaktif terhadap beberapa penyimpanan data internal, termasuk gudang data 300PB mereka. Lebih dari 1.000 karyawan Facebook menggunakan Presto setiap hari untuk menjalankan lebih dari 30.000 kueri yang secara total memindai lebih dari satu petabyte setiap hari.”
Meskipun Facebook memiliki lingkungan gudang data yang luar biasa, tantangan yang sama juga terjadi di banyak organisasi yang berurusan dengan data besar.
Di blog ini, kita akan melihat cara mengatur lingkungan presto dasar menggunakan server Docker dari file tar. Sebagai sumber data, kami akan fokus pada sumber data MySQL, tetapi bisa juga RDBMS populer lainnya.
Menjalankan Presto di Lingkungan Big Data
Sebelum kita mulai, mari kita lihat sekilas prinsip arsitektur utamanya. Presto adalah alternatif untuk alat yang meminta HDFS menggunakan saluran pekerjaan MapReduce - seperti Hive. Tidak seperti Hive Presto tidak menggunakan MapReduce. Presto berjalan dengan mesin eksekusi kueri tujuan khusus dengan operator tingkat tinggi dan pemrosesan dalam memori.
Berbeda dengan Hive Presto yang dapat mengalirkan data melalui semua tahapan sekaligus menjalankan bongkahan data secara bersamaan. Ini dirancang untuk menjalankan kueri analitik ad-hoc terhadap sumber data heterogen tunggal atau terdistribusi. Itu dapat menjangkau dari platform Hadoop untuk menanyakan database relasional atau penyimpanan data lainnya seperti file datar.
Presto menggunakan ANSI SQL standar termasuk agregasi, gabungan, atau fungsi jendela analitik. SQL terkenal dan lebih mudah digunakan dibandingkan dengan MapReduce yang ditulis dalam Java.
Menerapkan Presto ke Docker
Konfigurasi Presto dasar dapat diterapkan dengan image Docker yang telah dikonfigurasi sebelumnya atau tarball server presto.
Server buruh pelabuhan dan wadah Presto CLI dapat dengan mudah digunakan dengan:
docker run -d -p 127.0.0.1:8080:8080 --name presto starburstdata/presto
docker exec -it presto presto-cliAnda dapat memilih antara dua versi server Presto. Versi komunitas dan versi Perusahaan dari Starburst. Karena kami akan menjalankannya di lingkungan kotak pasir non-produksi, kami akan menggunakan versi Apache dalam artikel ini.
Persyaratan sebelumnya
Presto diimplementasikan seluruhnya di Java dan membutuhkan JVM untuk diinstal pada sistem Anda. Ini berjalan di OpenJDK dan Oracle Java. Versi minimum adalah Java 8u151 atau Java 11.
Untuk mengunduh JAVA JDK, kunjungi https://openjdk.java.net/ atau https://www.Oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
Anda dapat memeriksa versi Java Anda dengan
$ java -version
openjdk version "1.8.0_222"
OpenJDK Runtime Environment (AdoptOpenJDK)(build 1.8.0_222-b10)
OpenJDK 64-Bit Server VM (AdoptOpenJDK)(build 25.222-b10, mixed mode)Instalasi Presto
Untuk menginstal Presto kita akan mendownload server tar dan Presto CLI jar yang dapat dieksekusi.
Tarball akan berisi satu direktori tingkat atas, presto-server-0.223, yang akan kita sebut sebagai direktori instalasi.
$ wget https://repo1.maven.org/maven2/com/facebook/presto/presto-server/0.223/presto-server-0.223.tar.gz
$ tar -xzvf presto-server-0.223.tar.gz
$ cd presto-server-0.223/
$ wget https://repo1.maven.org/maven2/com/facebook/presto/presto-cli/0.223/presto-cli-0.223-executable.jar
$ mv presto-cli-0.223-executable.jar presto
$ chmod +x prestoSelain itu, Presto memerlukan direktori data untuk menyimpan log, dll.
Direkomendasikan untuk membuat direktori data di luar direktori instalasi.
$ mkdir -p ~/data/presto/Lokasi ini adalah tempat kami memulai pemecahan masalah.
Mengonfigurasi Presto
Sebelum kita memulai instance pertama kita, kita perlu membuat banyak file konfigurasi. Mulailah dengan membuat direktori etc/ di dalam direktori instalasi. Lokasi ini akan menyimpan file konfigurasi berikut:
dll/
- Properti Node - konfigurasi lingkungan node
- Konfigurasi JVM (jvm.config) - Konfigurasi Mesin Virtual Java
- Properti Konfigurasi(config.properties) -konfigurasi untuk server Presto
- Properti Katalog - konfigurasi untuk Konektor (sumber data)
- Properti Log - Konfigurasi logger
Di bawah ini Anda dapat menemukan beberapa konfigurasi dasar untuk menjalankan kotak pasir Presto. Untuk lebih jelasnya kunjungi dokumentasi.
vi etc/config.properties
Config.properties
coordinator = true
node-scheduler.include-coordinator = true
http-server.http.port = 8080
query.max-memory = 5GB
query.max-memory-per-node = 1GB
discovery-server.enabled = true
discovery.uri = https://localhost:8080
vi etc/jvm.config
-server
-Xmx8G
-XX:+UseG1GC
-XX:G1HeapRegionSize=32M
-XX:+UseGCOverheadLimit
-XX:+ExplicitGCInvokesConcurrent
-XX:+HeapDumpOnOutOfMemoryError
-XX:+ExitOnOutOfMemoryError
vi etc/log.properties
com.facebook.presto = INFOvi etc/node.properties
node.environment = production
node.id = ffffffff-ffff-ffff-ffff-ffffffffffff
node.data-dir = /Users/bartez/data/prestoStruktur dasar etc/ mungkin terlihat sebagai berikut:

Langkah selanjutnya adalah menyiapkan konektor MySQL.
Kita akan menghubungkan ke salah satu dari 3 node MariaDB Cluster.
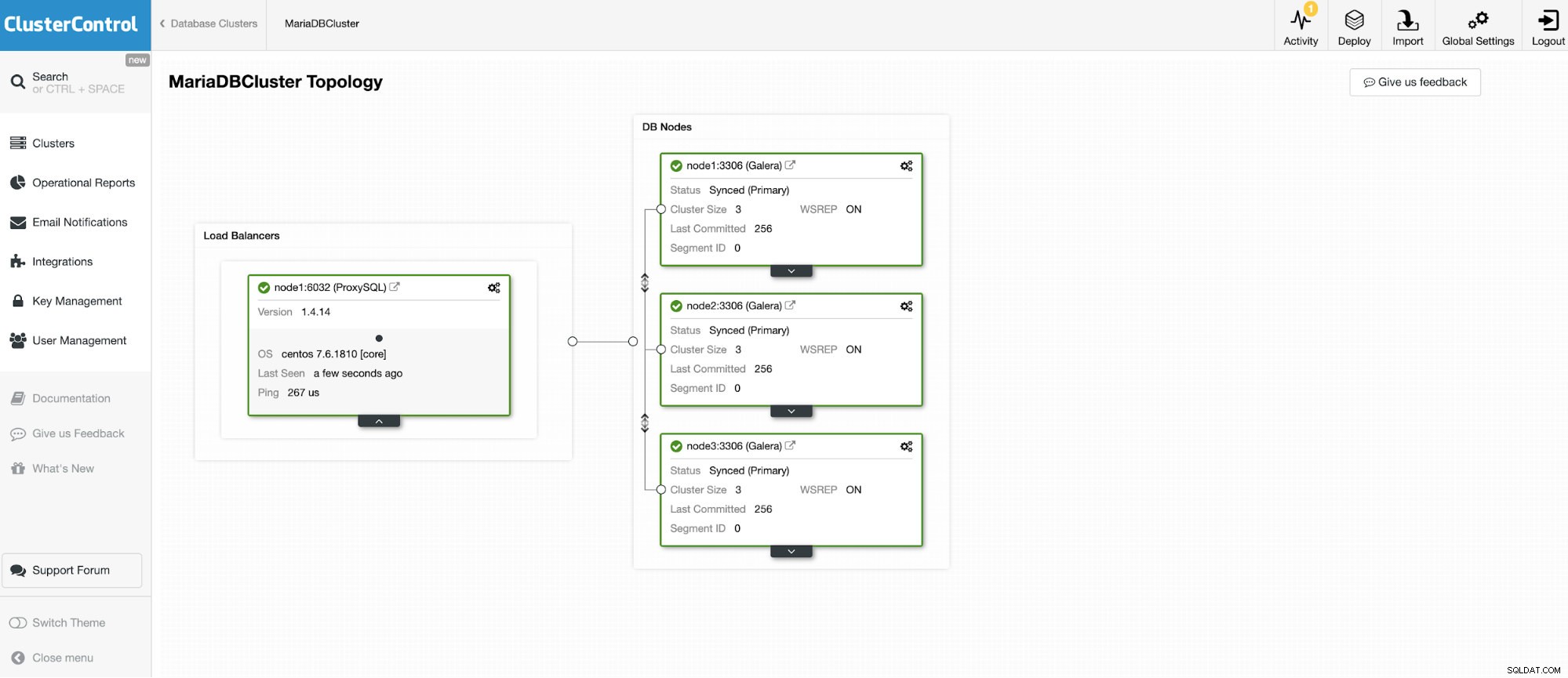
Dan instance mandiri lainnya yang menjalankan Oracle MySQL 5.7.
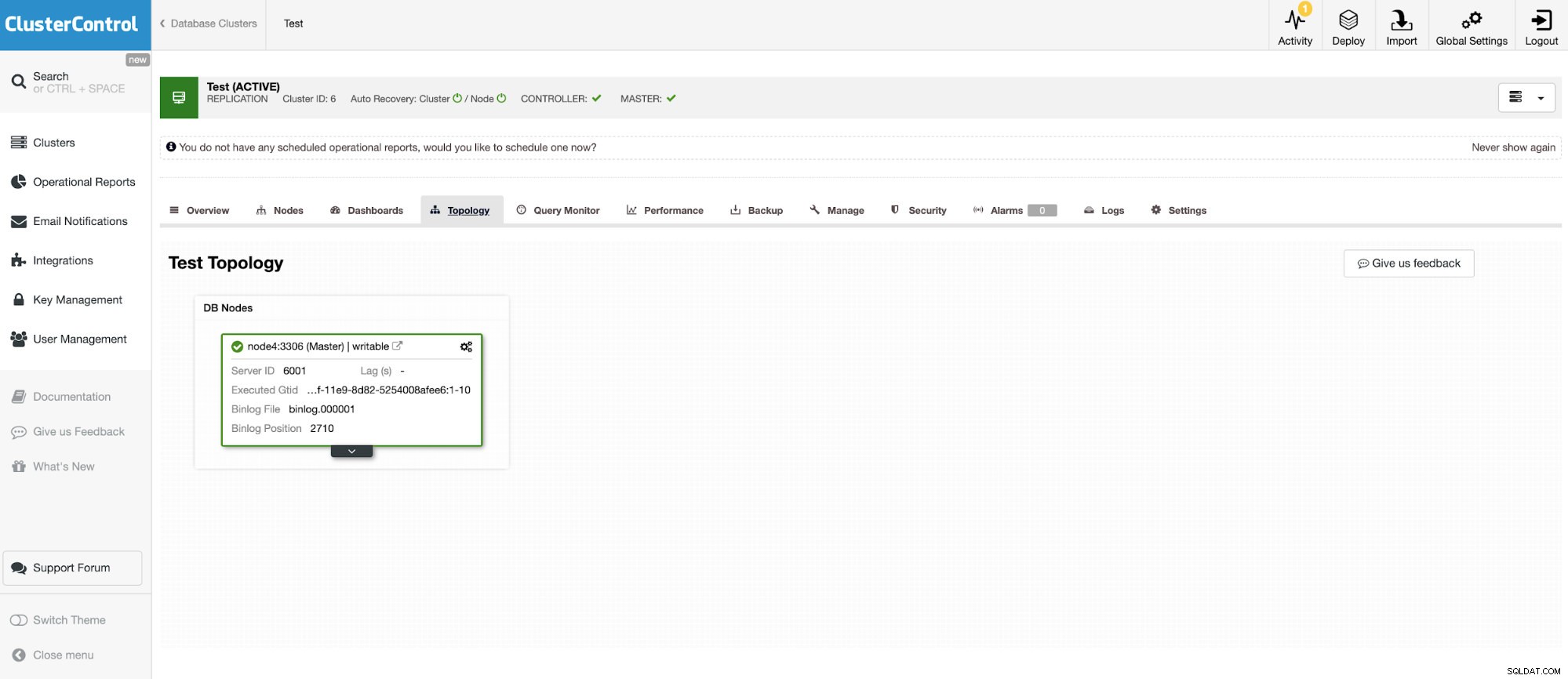
Konektor MySQL memungkinkan query dan membuat tabel dalam database MySQL eksternal. Ini dapat digunakan untuk menggabungkan data antara sistem yang berbeda seperti MariaDB dan MySQL dari Oracle.
Presto menggunakan konektor yang dapat dicolokkan dan konfigurasinya sangat mudah. Untuk mengkonfigurasi konektor MySQL, buat file properti katalog di etc/catalog bernama, misalnya, mysql.properties, untuk memasang konektor MySQL sebagai katalog mysql. Setiap file mewakili koneksi ke server lain. Dalam hal ini, kami memiliki dua file:
vi etc/catalog/mysq.properties:
connector.name=mysql
connection-url=jdbc:mysql://node1.net:3306
connection-user=bart
connection-password=secretvi etc/catalog/mysq2.properties
connector.name=mysql
connection-url=jdbc:mysql://node4.net:3306
connection-user=bart2
connection-password=secretMenjalankan Presto
Ketika semuanya sudah diatur, saatnya untuk memulai instance Presto. Untuk memulai presto, buka direktori bin di bawah instalasi preso dan jalankan perintah berikut:
$ bin/launcher start
Started as 18363Untuk menghentikan Presto jalankan
$ bin/launcher stopSekarang ketika server aktif dan berjalan, kita dapat terhubung ke Presto dengan CLI dan meminta database MySQL.
Untuk memulai menjalankan konsol Presto:
./presto --server localhost:8080 --catalog mysql --schema employeesSekarang kita dapat melakukan query database kita melalui CLI.
presto:mysql> select * from mysql.employees.departments;
dept_no | dept_name
---------+--------------------
d009 | Customer Service
d005 | Development
d002 | Finance
d003 | Human Resources
d001 | Marketing
d004 | Production
d006 | Quality Management
d008 | Research
d007 | Sales
(9 rows)
Query 20190730_232304_00019_uq3iu, FINISHED, 1 node
Splits: 17 total, 17 done (100,00%)
0:00 [9 rows, 0B] [81 rows/s, 0B/s]
Baik database MariaDB cluster maupun MySQL telah dilengkapi dengan database karyawan.
wget https://github.com/datacharmer/test_db/archive/master.zip
mysql -uroot -psecret < employees.sqlStatus kueri juga terlihat di konsol web Presto:https://localhost:8080/ui/#
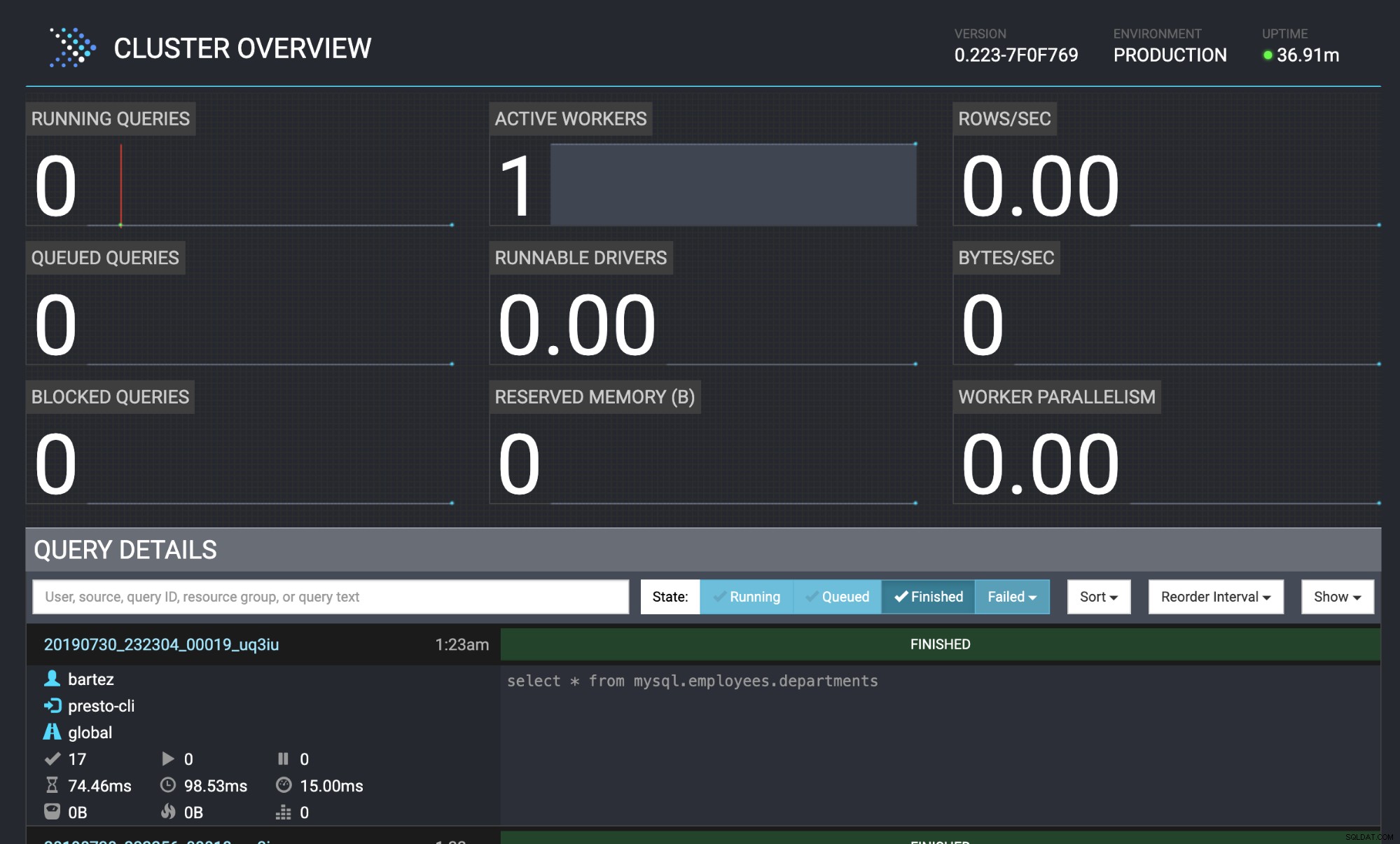 Ikhtisar Klaster Presto
Ikhtisar Klaster Presto Kesimpulan
Banyak perusahaan terkenal (seperti Airbnb, Netflix, Twitter) mengadopsi Presto untuk kinerja latensi rendah. Tidak diragukan lagi, ini adalah perangkat lunak yang sangat menarik yang dapat menghilangkan kebutuhan untuk menjalankan proses gudang data ETL yang berat. Di blog ini, kami hanya melihat sekilas konektor MySQL tetapi Anda dapat menggunakannya untuk menganalisis data dari HDFS, penyimpanan objek, RDBMS (SQL Server, Oracle, PostgreSQL), Kafka, Cassandra, MongoDB, dan banyak lainnya.