Pengantar
Mencari tahu jenis infrastruktur database yang Anda perlukan agar sesuai dengan kinerja, keandalan, dan persyaratan penskalaan aplikasi Anda bisa menjadi tugas yang sulit. Pilihan yang Anda buat untuk topologi database Anda dapat memengaruhi bagaimana seluruh tumpukan aplikasi Anda merespons berbagai jenis penggunaan dan skenario kegagalan apa yang dapat diperhitungkan. Karena itu, penting untuk memahami opsi Anda dan membuat keputusan yang tepat yang selaras dengan tujuan Anda.
Ada banyak cara berbeda untuk beralih dari satu database yang menangani semua kebutuhan infrastruktur Anda ke sistem yang lebih kompleks. Bersamaan dengan ini, ada banyak kompromi yang perlu dipertimbangkan.
Dalam panduan ini, kami akan memperkenalkan beberapa pola paling umum untuk infrastruktur database relasional dan bagaimana pola tersebut selaras dengan pola penggunaan yang berbeda. Kami akan membahas kelebihan yang ditawarkan setiap konfigurasi serta beberapa kekurangan yang perlu Anda perhitungkan. Kami juga akan berbicara tentang dampak dari keputusan yang berbeda pada kompleksitas operasi Anda secara keseluruhan. Setelah selesai, Anda akan dapat membuat keputusan yang lebih baik tentang desain apa yang paling cocok untuk kebutuhan Anda saat ini dan opsi mana yang mungkin ingin Anda coba saat kebutuhan Anda berubah.
Menskalakan secara vertikal
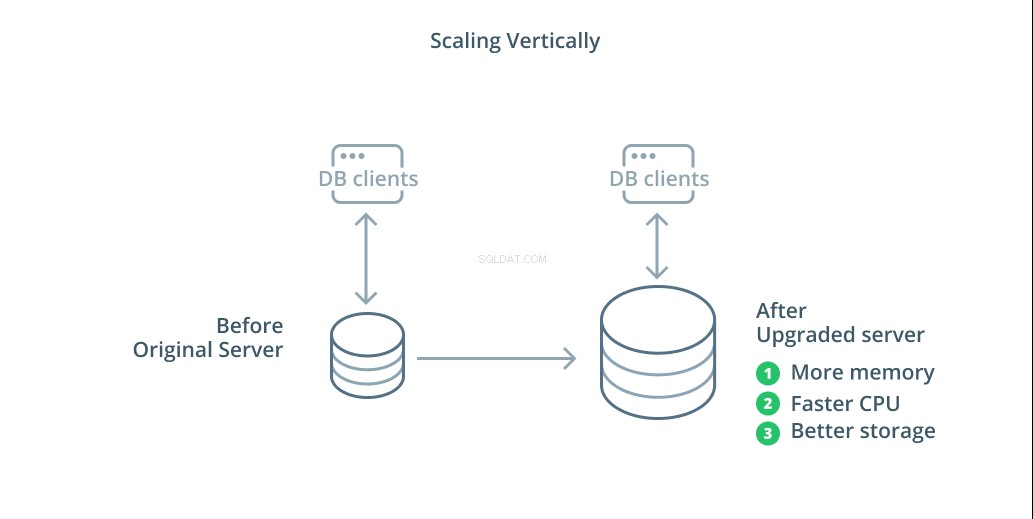
Cara paling sederhana untuk menskalakan sistem basis data adalah penskalaan vertikal. Menskalakan secara vertikal , juga disebut meningkatkan , berarti menambah kapasitas ke server yang mengelola database Anda. Dengan meningkatkan daya pemrosesan, alokasi memori, atau kapasitas penyimpanan, Anda dapat meningkatkan kinerja dan volume yang dapat ditangani oleh sistem database tanpa meningkatkan kompleksitas sistem secara keseluruhan.
Sebagai aturan umum, meningkatkan skala database Anda adalah langkah pertama yang baik karena meningkatkan kemampuan database Anda tanpa mempengaruhi topologi infrastruktur Anda. Peningkatan skala biasanya juga cukup sederhana, karena mesin berkapasitas lebih besar dapat dikonfigurasi sebagai pengikut replikasi hingga disinkronkan dan kemudian failover dapat dipicu untuk menjadikannya server utama baru.
Namun, scaling up memiliki keterbatasan karena jumlah sumber daya yang dapat dialokasikan secara wajar ke satu mesin terbatas. Ini juga mewakili satu titik kegagalan jika tidak ada pengikut replikasi yang dikonfigurasi untuk mengambil alih saat terjadi masalah. Masalah ini diatasi dengan beberapa opsi penskalaan lainnya.
Pemisahan tanggung jawab kueri perintah (CQRS) dan replika hanya-baca
Cara utama lainnya untuk menskalakan infrastruktur database Anda adalah dengan menskalakan. Meningkatkan berarti bahwa alih-alih meningkatkan kapasitas satu server, Anda meningkatkan jumlah server yang didedikasikan untuk melayani kebutuhan tertentu. Jadi, Anda menambah kapasitas dengan menambahkan mesin tambahan ke infrastruktur Anda.
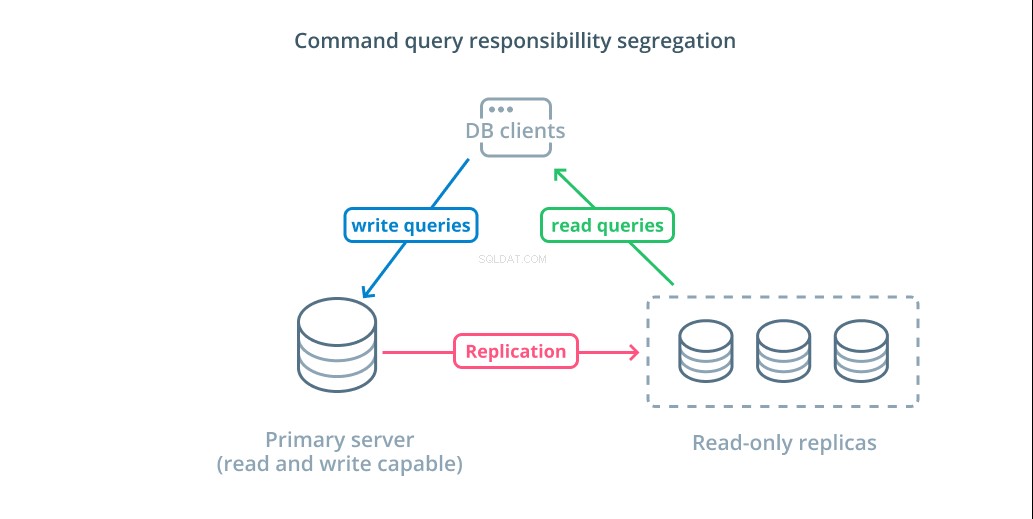
Pemisahan tanggung jawab kueri perintah (CQRS) adalah istilah yang digunakan untuk menjelaskan penambahan logika untuk memisahkan kueri yang mengubah data (menulis kueri) dari yang tidak (membaca kueri). Ini memungkinkan Anda merutekan kategori permintaan yang berbeda ini ke host yang berbeda untuk membantu mendistribusikan beban.
Infrastruktur paling dasar untuk memanfaatkan desain ini adalah server utama yang dapat menerima kueri baca dan tulis yang digabungkan dengan satu atau lebih server replika mengikuti server utama yang dapat menerima kueri baca. Desain ini sesuai untuk pola penggunaan aplikasi yang banyak membaca, karena operasi baca dapat ditangani oleh server database mana pun.
Selain itu, sistem ini menyediakan beberapa redundansi untuk arsitektur Anda karena sistem akan tetap berfungsi jika salah satu server mati. Jika pengikut turun, permintaan baca dapat dialihkan ke server lain. Jika server utama mati, salah satu pengikut replika dapat dipromosikan untuk menerima kueri tulis.
Replikasi multi-primer
Meskipun menggunakan CQRS dengan replika baca-saja membantu Anda menangani jumlah permintaan baca yang lebih tinggi, hal itu tidak secara signifikan memengaruhi kinerja tulis infrastruktur Anda. Untuk meningkatkan jumlah penulisan yang dapat ditangani oleh arsitektur Anda, Anda perlu mempertimbangkan apakah Anda dapat mengadopsi desain replikasi multi-primer.
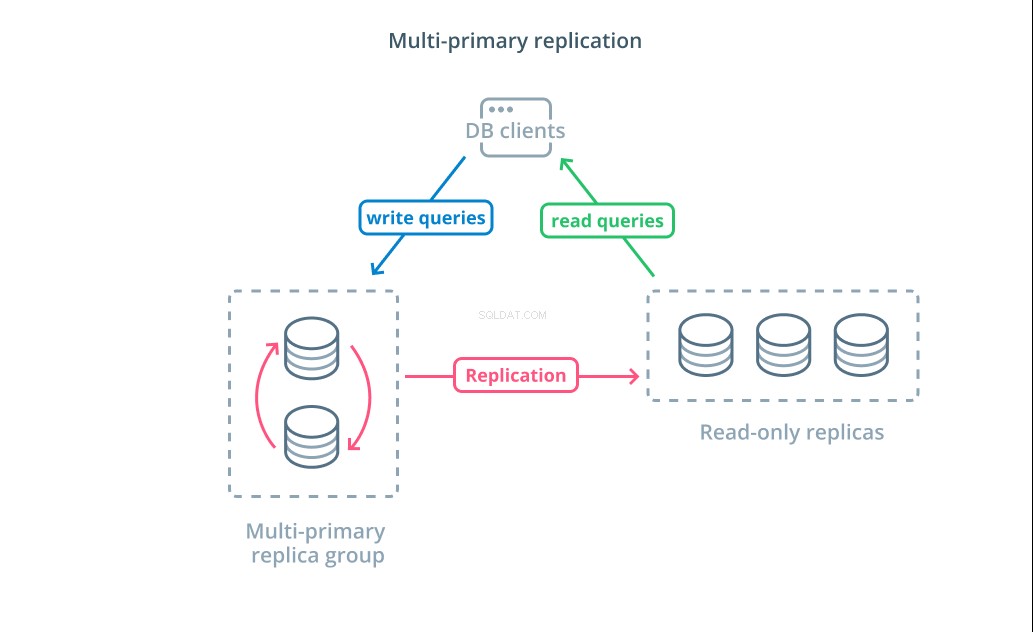
Replikasi multi-primer adalah bentuk replikasi di mana beberapa server dapat menerima permintaan tulis. Beberapa sistem dikonfigurasi sehingga server mana pun dapat memproses permintaan penulisan, sementara yang lain dirancang agar grup inti server utama menangani penulisan dengan jumlah pengikut hanya baca yang lebih besar. Terlepas dari implementasinya, replikasi multi-primer meningkatkan jumlah server yang bertanggung jawab untuk menulis kueri.
Meskipun desain ini terdengar ideal pada awalnya, ada beberapa tantangan utama yang mencegah hal ini menjadi pola yang diadopsi secara luas. Meskipun beberapa server dapat menangani permintaan tulis, mereka masih harus berkoordinasi untuk mereplikasi perubahan di antara server mereka dan untuk menyelesaikan konflik dalam perubahan data. Hal ini dapat menyebabkan waktu respons yang lama karena konflik dinegosiasikan atau kemungkinan data yang tidak konsisten.
Setiap sistem memilih pendekatan mereka sendiri untuk menangani tantangan ini. Ini adalah demonstrasi Teorema CAP — pernyataan yang menjelaskan interaksi antara konsistensi, ketersediaan, dan toleransi partisi dalam sistem terdistribusi — dalam tindakan. Beberapa sistem menawarkan jaminan konsistensi yang lebih lemah untuk menjaga ketersediaan, sementara database lain menolak untuk menerima perubahan jika rekan-rekan mereka tidak dapat mengoordinasikan transaksi pada saat penulisan. Memilih pendekatan yang paling sesuai dengan kebutuhan Anda merupakan faktor penting saat memutuskan di antara berbagai implementasi.
Baca cache kueri
Meskipun menggunakan replika baca-saja adalah cara untuk meningkatkan database yang tersedia yang dapat merespons permintaan baca, hal itu tidak meningkatkan kinerja kueri dasar dari operasi baca yang kompleks. Salah satu server masih diharapkan untuk menjalankan operasi baca setiap kali permintaan dibuat, meskipun hasilnya identik dengan pencarian sebelumnya.
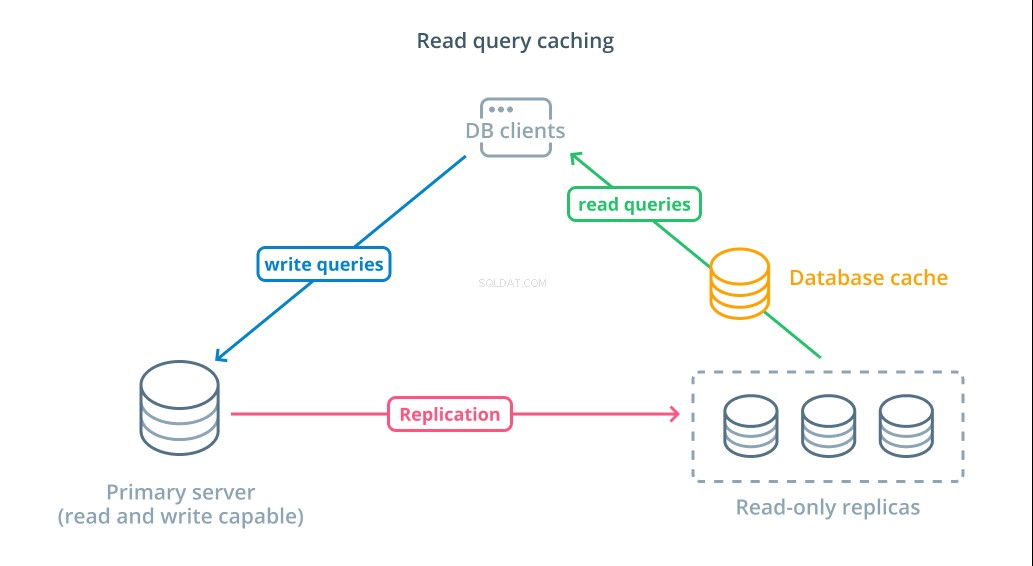
Untuk mengurangi waktu respons, baca cache kueri lapisan dapat diperkenalkan. Menambahkan cache antara klien database Anda dan database itu sendiri dapat mengurangi waktu kueri untuk permintaan umum secara signifikan. Aplikasi dapat meminta hasil baca dari cache dan menerimanya segera jika tersedia. Untuk kasus di mana hasilnya tidak ditemukan dalam cache, hasilnya diambil dari database itu sendiri dan ditambahkan ke cache untuk waktu berikutnya.
Mengonfigurasi caching dengan cara ini sangat efisien untuk skenario di mana data tidak mungkin berubah setiap kali permintaan dibuat. Ini sangat membantu untuk kueri baca yang mahal yang berkonsultasi dengan banyak tabel dan menyertakan operasi gabungan yang kompleks. Hasil ini dapat dieksekusi sekali dan kemudian disimpan untuk kueri di masa mendatang.
Dalam kasus di mana data berubah lebih cepat, cache baca mungkin tidak banyak membantu. Bergantung pada perilaku yang dikonfigurasi, cache berisiko mengembalikan data basi dalam situasi ini dan strategi pembatalan cache yang bijaksana harus diterapkan untuk mengeluarkan data basi dari cache saat diubah.
Sharding data
Sejauh ini, desain yang telah kita diskusikan memiliki komponen basis data yang tersegmentasi berdasarkan apakah mereka merespons permintaan tulis atau tidak. Namun, cara lain untuk membagi tanggung jawab adalah dengan membagi kumpulan data aktual menjadi beberapa bagian.
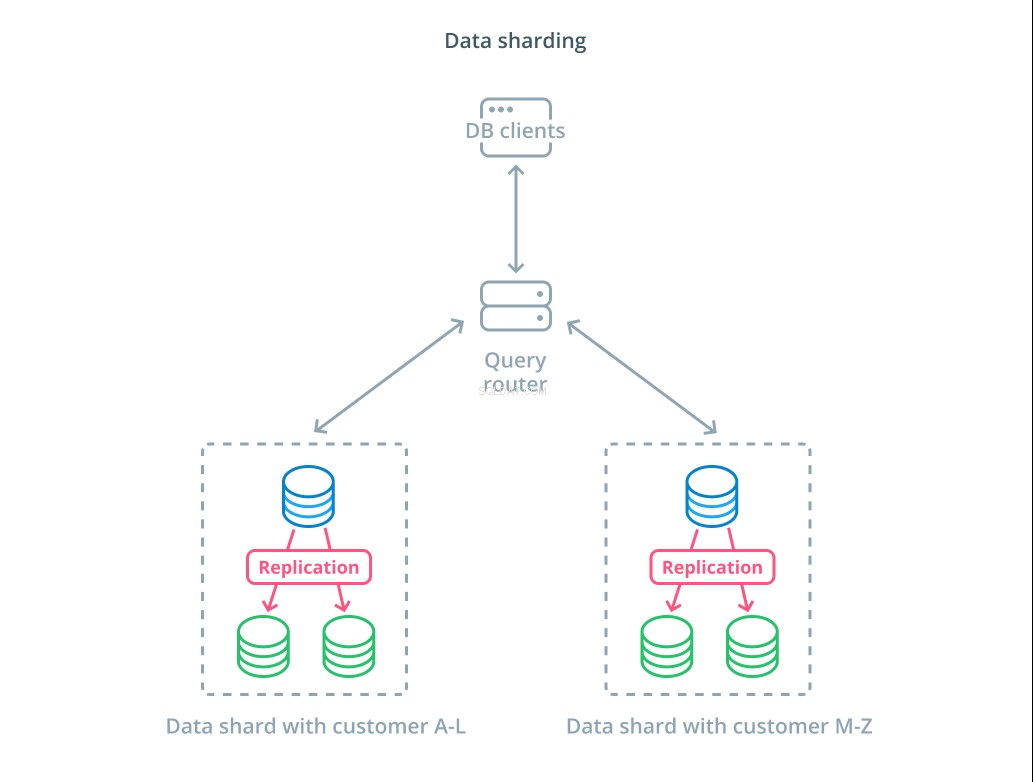
Berbagi adalah proses memecah kumpulan data logis menjadi himpunan bagian yang lebih kecil untuk mendistribusikan manajemennya ke mesin yang berbeda. Setiap server database hanya menangani sebagian data dan mekanik perutean diperkenalkan yang memahami mesin mana yang bertanggung jawab atas bagian data apa.
Biasanya, sharding dilakukan dalam skenario di mana operasi pada seluruh dataset sekaligus tidak diperlukan atau tidak biasa. Kumpulan data tersegmentasi berdasarkan nilai setiap record untuk kunci tertentu, yang dikenal sebagai kunci sharding . Misalnya, Anda dapat melakukan sharding data secara manual berdasarkan lokasi pelanggan. Anda juga dapat melakukan sharding secara otomatis menggunakan algoritme hashing untuk menentukan node mana yang harus menangani kunci mana. Ini dapat membantu sistem Anda menghindari distribusi yang tidak seimbang jika ruang kunci shard terdistribusi secara tidak merata.
Sharding memperkenalkan sedikit kerumitan ke dalam sistem data dan tidak sesuai untuk semua skenario. Operasi yang berinteraksi dengan banyak pecahan akan mengalami penalti kinerja yang signifikan saat mereka mengambil hasil dari setiap anggota. Ini bisa terjadi untuk kueri agregat atau jika kunci shard tertentu tidak diketahui sebelumnya. Selain itu, alokasi shard yang tidak merata juga dapat menyebabkan inefisiensi dan kemacetan yang perlu diperbaiki dengan menyeimbangkan kembali distribusi seluruh kumpulan data.
Pengelolaan data fungsional terdesentralisasi
Daripada membagi nilai dataset menjadi beberapa segmen, dalam banyak kasus, lebih masuk akal untuk menggunakan database yang berbeda untuk tujuan fungsional yang berbeda. Misalnya, jika Anda memiliki layanan akun dan layanan produk, memiliki database khusus yang sesuai dengan setiap masalah dapat membantu Anda menskalakan komponen yang berbeda secara mandiri.
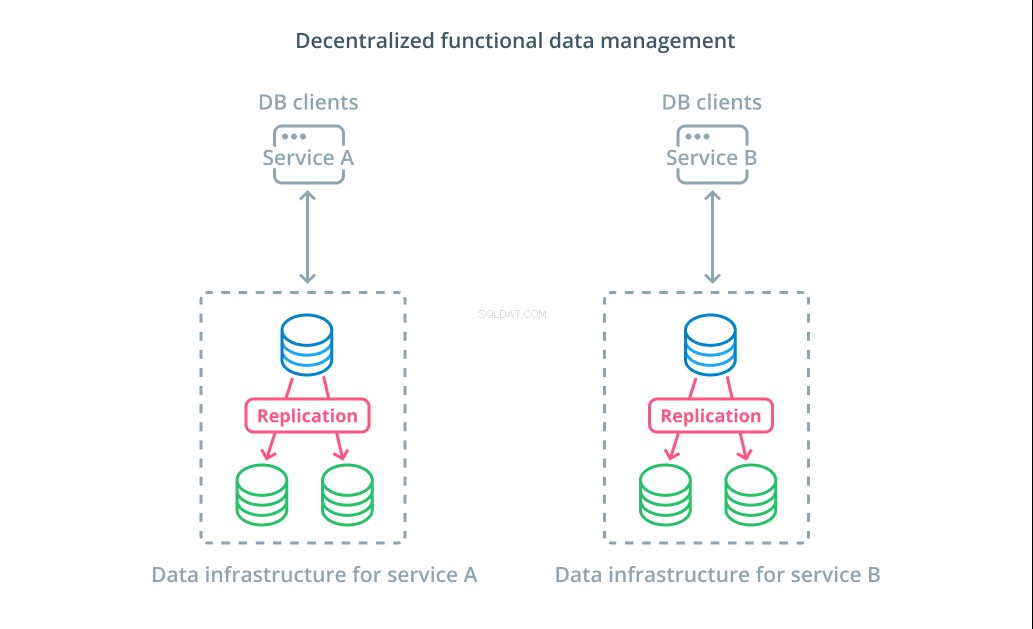
Manajemen data fungsional memungkinkan Anda untuk memecah infrastruktur database Anda dan mengelola setiap bagian sesuai dengan kebutuhan kliennya. Setiap bagian fungsional dapat diskalakan menggunakan strategi apa pun yang paling masuk akal. Ini memungkinkan Anda mendesain skema database dan menerapkannya ke lokasi yang paling cocok dengan pola kasus penggunaan tertentu daripada mengharuskannya untuk melayani seluruh organisasi.
Bagi banyak organisasi, strategi ini memiliki keunggulan penting yang melampaui sifat sistem yang sebenarnya. Desentralisasi manajemen data dapat memungkinkan tim yang lebih kecil untuk memiliki data mereka sendiri tanpa mengoordinasikan perubahan dengan pihak lain. Hal ini selaras dengan pemisahan fokus perhatian yang dipromosikan oleh arsitektur aplikasi berorientasi layanan mikro.
Database tanpa server
Pertukaran yang berbeda yang harus Anda evaluasi dan jumlah infrastruktur yang mungkin diharapkan untuk Anda kelola untuk penskalaan yang tepat dapat membuat banyak orang kewalahan. Salah satu opsi untuk mengurangi kompleksitas ini adalah dengan memanfaatkan layanan database yang mengelola infrastruktur dan skala untuk Anda.
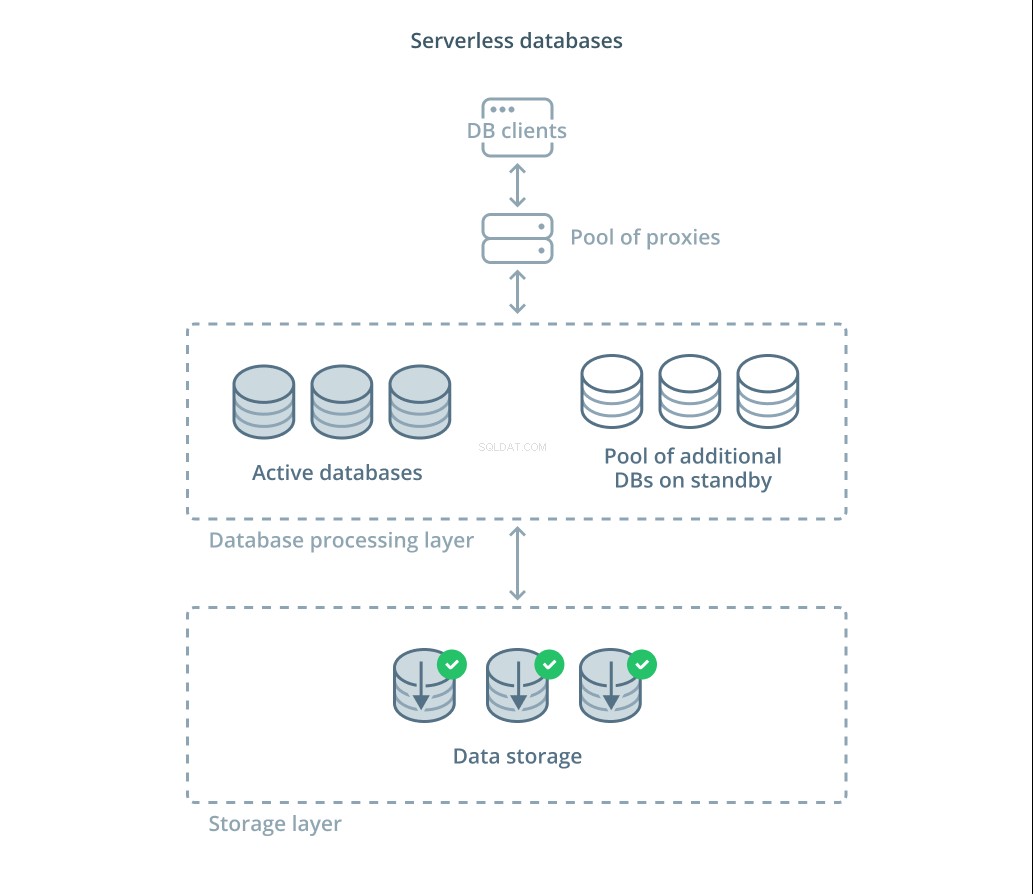
Database tanpa server adalah kategori layanan yang memisahkan penyimpanan data dari pemrosesan data untuk menskalakan sumber daya dengan mudah sebagai respons terhadap perubahan permintaan.
Lapisan penyimpanan data bertanggung jawab untuk memelihara data aktual yang dikelola oleh sistem. Di depan lapisan ini, tingkat unit pemrosesan basis data yang dapat diskalakan dikerahkan untuk menangani pemrosesan kueri aktual terhadap kumpulan data. Jumlah unit yang aktif pada waktu tertentu terkait langsung dengan penggunaan saat ini, sehingga lebih banyak sumber daya dialokasikan sebagai puncak permintaan dan unit pemrosesan dikembalikan ke standby jika keadaan tenang.
Kueri diteruskan ke pemroses database melalui proxy perutean yang mengetahui cara meneruskan permintaan ke node aktif dan kapan meminta sumber daya tambahan.
Basis data tanpa server memiliki banyak properti yang sama dengan layanan basis data tradisional yang mengimplementasikan fitur penskalaan otomatis. Keduanya dapat mengalokasikan kapasitas berdasarkan permintaan. Namun, database tanpa server memungkinkan Anda untuk memisahkan biaya penyimpanan dari biaya pemrosesan dan dapat menurunkan skala pemrosesan hingga nol saat tidak diperlukan. Selain itu, solusi tanpa server cenderung dapat ditingkatkan lebih cepat untuk memenuhi permintaan dibandingkan dengan penskalaan otomatis yang ditawarkan oleh penawaran tradisional.
Meskipun database tanpa server mungkin cocok untuk beberapa orang, mereka bukan peluru perak. Dalam kasus di mana pemroses basis data adalah diperkecil ke nol, mungkin ada penundaan dalam pemrosesan lagi karena mulai dingin. Selain itu, churn through koneksi antara berbagai komponen dalam tumpukan database tanpa server dapat menyebabkan latensi tambahan.
Platform database tanpa server juga bisa sulit dari sudut pandang operasi. Penerapan dan perubahan basis data bisa lebih sulit untuk dipikirkan dan dipantau. Lingkungan pengembangan lokal mungkin juga berbeda secara signifikan dari lingkungan produksi karena keadaan dinamis dari sistem database. Dan akhirnya, seperti halnya layanan cloud lainnya, menggunakan database tanpa server berpotensi menempatkan Anda dalam bahaya penguncian vendor. Penting untuk mengingat kompromi ini saat mendesain platform tanpa server.
Kesimpulan
Ada banyak cara untuk merancang, menyebarkan, dan mengelola infrastruktur database Anda karena persyaratan aplikasi Anda menjadi lebih serius. Setiap solusi memiliki kekuatan dan keterbatasannya sendiri yang penting untuk dipahami saat mencoba menemukan kecocokan untuk lingkungan Anda.
Mempelajari tentang bagaimana infrastruktur database memengaruhi ketersediaan, kinerja, dan integritas data Anda memungkinkan Anda menghindari kesalahan dan implementasi yang mahal yang tidak memberikan jaminan yang Anda butuhkan. Jika salah satu desain di atas tidak memenuhi kebutuhan Anda, Anda mungkin dapat menggabungkan beberapa elemen pendekatan yang berbeda untuk mendapatkan keuntungan tambahan.
Jika Anda ingin mempelajari lebih lanjut tentang pola umum yang tercakup di atas, berikut adalah beberapa sumber daya tambahan yang mungkin ingin Anda lihat:
- Meningkatkan versus memperkecil
- Pemisahan tanggung jawab kueri perintah
- Replikasi multi-primer
- Menyimpan kueri yang telah dibaca ke dalam cache
- Pembagian data
- Pengelolaan data terdesentralisasi
- Database tanpa server