Tolok ukur adalah salah satu aktivitas yang dilakukan oleh administrator basis data. Anda menjalankannya untuk melihat bagaimana perilaku perangkat keras Anda, Anda menjalankannya untuk melihat bagaimana aplikasi dan database Anda bekerja bersama di bawah tekanan. Anda menjalankannya dalam banyak situasi berbeda. Mari kita bahas sedikit tentang mereka, tantangan apa yang akan Anda hadapi, masalah apa yang harus Anda hindari.
Jenis benchmark
Setiap tolok ukur berbeda. Mereka melayani tujuan yang berbeda dan itu harus diperhitungkan ketika Anda berencana untuk menjalankannya. Secara umum, Anda dapat menentukan dua jenis tolok ukur utama:tolok ukur sintetis dan, sebut saja, tolok ukur "dunia nyata".
Tolok ukur sintetis biasanya merupakan alat yang mensimulasikan semacam beban kerja. Ini bisa menjadi beban kerja OLTP seperti dalam kasus Sysbench, itu bisa menjadi tolok ukur "standar" seperti di TPC-C atau TPC-H. Biasanya idenya adalah bahwa tolok ukur semacam itu mensimulasikan semacam beban kerja dan mungkin berguna jika beban kerja dunia nyata Anda akan mengikuti pola yang sama. Ini juga dapat digunakan untuk menentukan bagaimana kombinasi perangkat keras dan konfigurasi database Anda bekerja bersama di bawah jenis beban kerja tertentu. Kelebihan dari benchmark sintetis cukup jelas. Anda dapat menjalankannya di mana saja, mereka tidak bergantung pada beberapa pengaturan atau desain skema tertentu. Ya, mereka melakukannya tetapi mereka datang dengan alat untuk mengatur semuanya dari server database kosong. Kelemahan utama adalah bahwa ini bukan beban kerja Anda. Jika Anda akan menjalankan tes OLTP menggunakan Sysbench maka Anda harus ingat bahwa aplikasi Anda tidak akan pernah menjadi Sysbench. Ini juga dapat menjalankan beban kerja OLTP tetapi campuran kueri akan berbeda. Tidak pernah, dalam situasi apa pun, benchmark sintetis akan memberi tahu Anda dengan tepat bagaimana aplikasi Anda akan berperilaku pada campuran perangkat keras/konfigurasi tertentu.
Di ujung lain spektrum yang kami miliki, apa yang kami sebut, tolok ukur "dunia nyata". Yang kami maksud di sini adalah tolok ukur yang menggunakan kumpulan data dan kueri yang terkait dengan aplikasi Anda. Itu tidak selalu memiliki kumpulan data lengkap dan campuran kueri lengkap. Anda mungkin ingin fokus pada beberapa bagian dari aplikasi Anda, tetapi ide utama di baliknya adalah Anda ingin memahami interaksi yang tepat antara aplikasi, perangkat keras dan konfigurasi database, baik secara umum atau dalam beberapa aspek tertentu.
Seperti yang kami sebutkan di atas, kami memiliki dua jenis tolok ukur utama yang berbeda tetapi, tetap saja, mereka memiliki beberapa hal umum yang harus Anda pertimbangkan saat mencoba menjalankan tolok ukur.
-
Tentukan apa yang ingin Anda uji
Pertama-tama, benchmarking demi menjalankan benchmark tidak ada gunanya. Itu harus dirancang untuk benar-benar mencapai sesuatu. Apa yang ingin Anda dapatkan dari benchmark run? Apakah Anda ingin menyesuaikan kueri? Apakah Anda ingin mengubah konfigurasi? Apakah Anda ingin menilai skalabilitas tumpukan Anda? Apakah Anda ingin mempersiapkan tumpukan Anda untuk beban yang lebih tinggi? Apakah Anda ingin melakukan konfigurasi umum untuk proyek baru? Apakah Anda ingin menentukan pengaturan terbaik untuk perangkat keras Anda? Itu adalah contoh tujuan yang mungkin ingin Anda capai. Masing-masing akan memerlukan pendekatan yang berbeda dan penyiapan tolok ukur yang berbeda.
-
Buat satu per satu
Apa pun yang Anda uji dan ubah, yang terpenting adalah Anda hanya membuat satu perubahan konfigurasi pada satu waktu. Ini benar-benar kritis. Tolok ukur ini dimaksudkan untuk memberi Anda gambaran tentang kinerjanya. Kueri per detik, latensi, 99 persentil, semua ini memberi tahu Anda seberapa cepat Anda dapat menjalankan kueri dan seberapa stabil dan dapat diprediksi beban kerjanya. Sangat mudah untuk mengetahui apakah perubahan yang Anda buat dalam konfigurasi, perangkat keras, atau campuran kueri mengubah apa pun:metrik dari tolok ukur akan terlihat berbeda. Masalahnya, jika Anda membuat beberapa perubahan pada saat yang sama, tidak ada cara untuk mengetahui mana yang bertanggung jawab atas hasil keseluruhan. Bahkan bisa lebih jauh dari itu. Katakanlah Anda telah mengubah dua nilai dalam konfigurasi database. Nilai A dan B. Peningkatan keseluruhan adalah 20%, yang cukup bagus hanya untuk perubahan konfigurasi. Namun, di bawah tenda, perubahan ke nilai A membawa peningkatan 30% sementara perubahan tambahan pada nilai B mengembalikannya ke 20%. Dengan beberapa perubahan pada saat yang sama, Anda hanya dapat mengamati dampak umumnya, ini bukan cara untuk menentukan dengan tepat hasil dari setiap perubahan yang Anda buat. Tentu, ini secara signifikan meningkatkan waktu yang Anda habiskan untuk menjalankan tolok ukur, tetapi begitulah adanya.
-
Lakukan beberapa benchmark berjalan
Komputer sendiri merupakan sistem yang kompleks. Mereka memiliki beberapa komponen yang berinteraksi satu sama lain:memori, CPU, disk, jaringan. Lalu mari kita tambahkan ke virtualisasi ini, containerization. Kemudian perangkat lunak - sistem operasi, aplikasi, database. Lapisan di atas lapisan di atas lapisan di atas lapisan elemen yang berinteraksi entah bagaimana. Tidak mudah untuk memprediksi perilakunya. Anda dapat mengatakan bahwa hampir tidak mungkin untuk secara tepat memprediksi perilaku sistem yang kompleks seperti itu. Inilah alasan mengapa menjalankan satu benchmark saja tidak cukup untuk menarik kesimpulan. Bagaimana jika, tanpa Anda sadari, beberapa elemen, yang sama sekali tidak terkait dengan apa yang ingin Anda uji, memengaruhi kinerja secara keseluruhan? Beban tinggi pada VM lain yang terletak di host yang sama. Beberapa server lain mengalirkan cadangan melalui jaringan. Hal ini dapat berdampak sementara pada kinerja dan hasil benchmark miring. Jika Anda hanya menjalankan satu benchmark, Anda akan mendapatkan hasil yang salah. Inilah sebabnya mengapa praktik terbaik adalah mengeksekusi beberapa lintasan benchmark dan kemudian menghapus yang paling lambat dan tercepat, dengan merata-ratakan yang lainnya.
-
Sebuah gambar bernilai ribuan kata
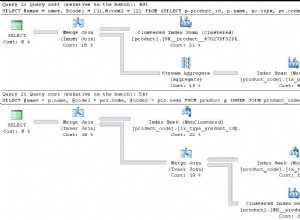
Nah, ini adalah deskripsi pembandingan yang cukup akurat. Jika memungkinkan, selalu buat grafik. Idealnya, lacak metrik selama benchmark sesering mungkin. Perincian satu detik seharusnya cukup untuk sebagian besar kasus. Untuk menghindari penulisan ribuan kata, kami akan menyertakan contoh ini. Menurut Anda apa yang lebih bermanfaat? Kumpulan keluaran tolok ukur ini yang mewakili QPS rata-rata untuk setiap 10 lintasan, setiap lintasan membutuhkan waktu 600 detik
11650.52
11237,97
11550.16
11247.08
11177,78
11163,76
11131,47
11235.06
11235.59
11277,25
Atau plot ini:
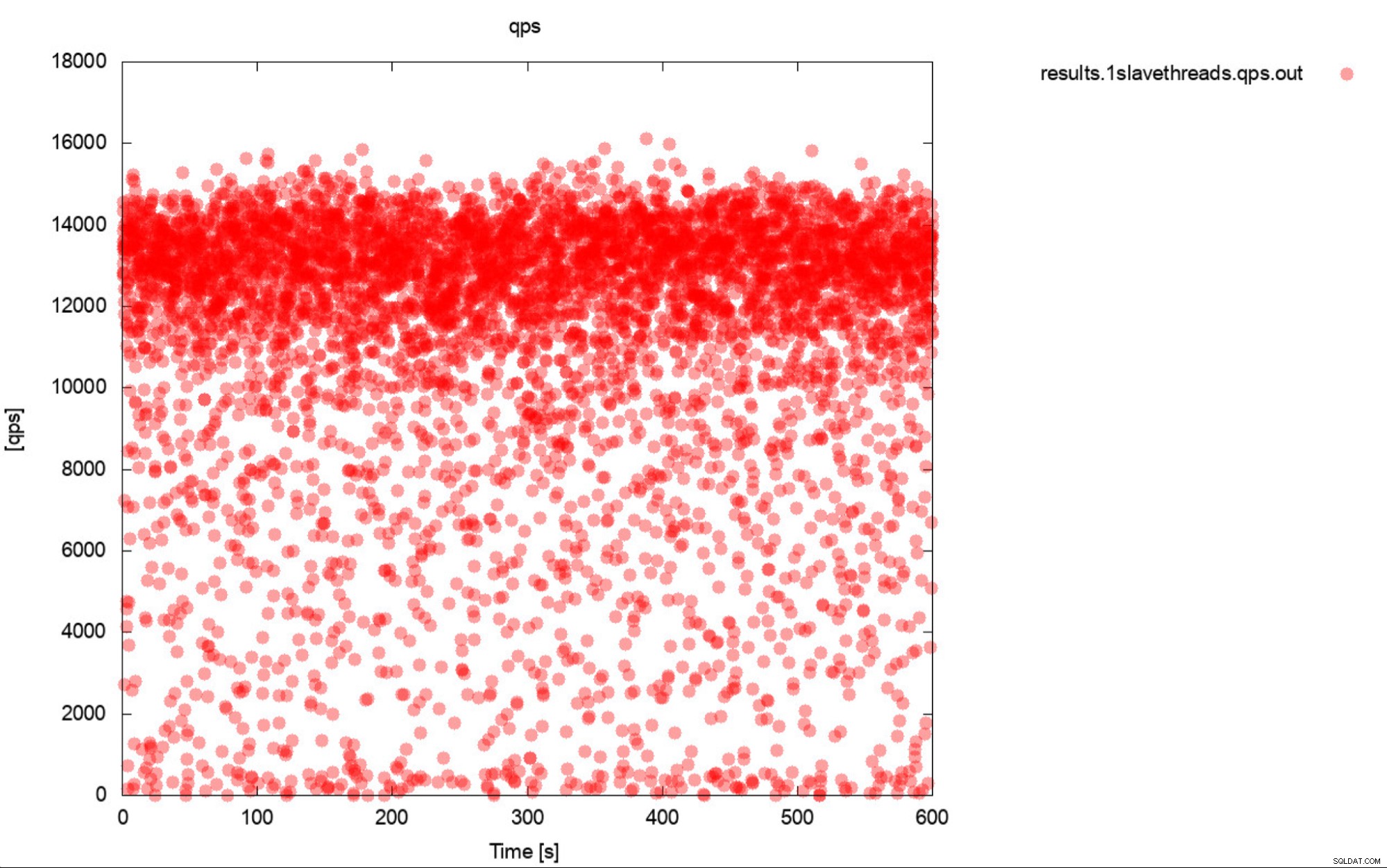
Rata-rata QPS adalah 11k tetapi kenyataannya adalah kinerja di seluruh tempat, termasuk penurunan ke 0 kueri yang dieksekusi dalam satu detik, dan ini pasti sesuatu yang ingin Anda kerjakan dan tingkatkan pada sistem produksi.
-
Kueri Per Detik bukanlah metrik yang paling penting
Anda mungkin berpikir bahwa kueri per detik adalah cawan suci kinerja karena mewakili berapa banyak kueri yang dapat dijalankan oleh database dalam satu detik. Sebenarnya, ini bukan metrik yang paling penting, terutama jika kita berbicara tentang output rata-rata dari sebuah benchmark. QPS mewakili throughput tetapi mengabaikan latency. Anda dapat mencoba mendorong sejumlah besar kueri tetapi kemudian Anda akhirnya menunggu mereka mengembalikan hasil. Ini bukan yang diharapkan pengguna dari aplikasi. Pengguna mengharapkan kinerja yang stabil. Itu tidak harus sangat cepat tetapi ketika beberapa tindakan membutuhkan waktu satu detik untuk diselesaikan, kita cenderung berharap bahwa melakukan tindakan itu akan selalu memakan waktu 1 detik itu. Jika, karena alasan tertentu, mulai memakan waktu lebih lama, manusia cenderung menjadi cemas. Inilah alasan utama mengapa kami cenderung memilih latensi, terutama P99 (persentil ke-99) sebagai metrik yang lebih andal. Latensi memberi tahu kita berapa lama aplikasi harus menunggu hasil dari database. P99 memberi tahu kami latensi bahwa 99% kueri memiliki lebih rendah dari. Katakanlah kita memiliki P99 100 md, artinya 99% kueri mengembalikan hasil tidak lebih lambat dari 100 md. Jika kami melihat latensi P99 rendah, artinya hampir semua kueri kembali dengan cepat dan berkinerja stabil dan dapat diprediksi. Ini adalah sesuatu yang ingin dilihat pengguna kami.
-
Pahami apa yang terjadi sebelum menarik kesimpulan
Poin terakhir yang kami miliki di blog singkat ini, tetapi kami akan mengatakan itu yang paling penting. Anda akan melihat hasil dan perilaku aneh dan tak terduga yang berbeda selama benchmark. Lebih buruk lagi, Anda mungkin melihat hasil yang cukup standar, berulang tetapi masih cacat. Sebagian besar dari mereka dapat dilacak ke perilaku database atau perangkat keras. Ini sangat penting - sebelum Anda menerima begitu saja hasilnya, Anda harus dapat menjelaskan perilaku dan menjelaskan apa yang terjadi. Kami tahu itu tidak mudah dan kami tahu itu benar-benar membutuhkan pengetahuan khusus basis data, terutama pengetahuan yang terkait dengan internal basis data. Kami tahu bahwa di dunia nyata orang biasanya tidak peduli dengan hal ini, mereka hanya ingin mendapatkan hasil. Masalahnya, terutama untuk kasus di mana Anda mencoba meningkatkan kinerja melalui konfigurasi atau penyesuaian perangkat keras, memahami apa yang terjadi di balik kap mesin memungkinkan Anda memilih cara yang tepat untuk melanjutkan penyetelan. Ini juga memungkinkan untuk mengetahui apakah tolok ukur yang telah dieksekusi mungkin masuk akal. Apakah kita benar-benar menguji elemen yang benar? Contohnya adalah tes yang dijalankan melalui jaringan (karena Anda tidak ingin menggunakan inti CPU lokal dari node database untuk alat benchmark). Sangat mungkin bahwa jaringan itu sendiri dan beban CPU yang lembut akan menjadi faktor pembatas, jauh lebih awal daripada Anda akan mencapai kemacetan "yang diharapkan" seperti saturasi CPU. Jika Anda tidak mengetahui lingkungan Anda dan perilakunya, Anda akan mengukur kinerja jaringan Anda untuk mentransfer data dalam jumlah besar, bukan kinerja CPU.
Seperti yang Anda lihat, benchmarking bukanlah hal termudah untuk dilakukan, Anda harus memiliki tingkat kesadaran tentang apa yang sedang terjadi, Anda harus memiliki rencana yang tepat untuk apa yang akan Anda lakukan dan apa yang ingin kamu uji? Di bagian selanjutnya dari blog ini kita akan membahas beberapa kasus uji dunia nyata. Apa yang bisa salah, masalah apa yang akan kita hadapi dan bagaimana mengatasinya.