Sudah lama berlalu ketika database digunakan sebagai node atau instance tunggal - server mandiri yang kuat yang ditugaskan untuk menangani semua permintaan ke database. Penskalaan vertikal adalah cara yang harus dilakukan - ganti server dengan yang lain, bahkan yang lebih kuat. Selama waktu ini, seseorang tidak perlu diganggu oleh kinerja jaringan. Selama permintaan masuk, semuanya baik-baik saja.
Namun saat ini, database dibangun sebagai cluster dengan node yang saling berhubungan melalui jaringan. Ini tidak selalu merupakan jaringan lokal yang cepat. Dengan bisnis yang mencapai skala global, infrastruktur database juga harus menjangkau seluruh dunia, untuk tetap dekat dengan pelanggan dan untuk mengurangi latensi. Muncul dengan tantangan tambahan yang harus kita hadapi ketika merancang lingkungan database yang sangat tersedia. Dalam posting blog ini, kami akan melihat masalah jaringan yang mungkin Anda hadapi dan memberikan beberapa saran tentang cara mengatasinya.
Dua Opsi Utama untuk MySQL atau MariaDB HA
Kami membahas topik khusus ini cukup luas di salah satu buku putih, tetapi mari kita lihat dua cara utama untuk membangun ketersediaan tinggi untuk MySQL dan MariaDB.
Kluster Galera
Galera Cluster adalah teknologi cluster yang hampir sinkron untuk MySQL. Ini memungkinkan untuk membangun pengaturan multi-penulis yang dapat menjangkau seluruh dunia. Galera berkembang pesat di lingkungan latensi rendah tetapi juga dapat dikonfigurasi untuk bekerja dengan koneksi WAN yang panjang. Galera memiliki mekanisme kuorum bawaan yang memastikan bahwa data tidak akan dikompromikan jika terjadi partisi jaringan pada beberapa node.
Replikasi MySQL
Replikasi MySQL dapat berupa asinkron atau semi-sinkron. Keduanya dirancang untuk membangun kluster replikasi skala besar. Seperti dalam pengaturan replikasi master-slave atau primary-secondary lainnya, hanya ada satu penulis, master. Node lain, slave, digunakan untuk tujuan failover karena berisi salinan kumpulan data dari maser. Slave juga dapat digunakan untuk membaca data dan membongkar sebagian beban kerja dari master.
Kedua solusi memiliki batasan dan fiturnya sendiri, keduanya mengalami masalah yang berbeda. Keduanya dapat dipengaruhi oleh koneksi jaringan yang tidak stabil. Mari kita lihat batasan tersebut dan bagaimana kita dapat merancang lingkungan untuk meminimalkan dampak infrastruktur jaringan yang tidak stabil.
Cluster Galera - Masalah Jaringan
Pertama, mari kita lihat Galera Cluster. Seperti yang telah kita diskusikan, ini bekerja paling baik di lingkungan latensi rendah. Salah satu masalah utama terkait latensi di Galera adalah cara Galera menangani penulisan. Kami tidak akan membahas semua detail di blog ini, tetapi membaca lebih lanjut di Cluster Galera kami untuk tutorial MySQL. Intinya adalah, karena proses sertifikasi untuk penulisan, di mana semua node dalam cluster harus menyetujui apakah penulisan dapat diterapkan atau tidak, kinerja penulisan Anda untuk satu baris sangat dibatasi oleh waktu bolak-balik jaringan antara penulis node dan node yang paling jauh. Selama latensi dapat diterima dan selama Anda tidak memiliki terlalu banyak hot spot dalam data Anda, pengaturan WAN dapat bekerja dengan baik. Masalahnya dimulai ketika latensi jaringan melonjak dari waktu ke waktu. Penulisan akan memakan waktu 3 atau 4 kali lebih lama dari biasanya dan, akibatnya, database mungkin mulai kelebihan beban dengan penulisan yang berjalan lama.
Salah satu fitur hebat dari Galera Cluster adalah kemampuannya untuk mendeteksi status cluster dan bereaksi terhadap partisi jaringan. Jika node cluster tidak dapat dijangkau, node tersebut akan dikeluarkan dari cluster dan tidak akan dapat melakukan penulisan apa pun. Hal ini penting dalam menjaga integritas data selama cluster dipecah - hanya sebagian besar cluster yang akan menerima penulisan. Minoritas akan mengeluh. Untuk menangani ini, Galera memperkenalkan serangkaian pemeriksaan dan batas waktu yang dapat dikonfigurasi untuk menghindari peringatan palsu pada masalah jaringan yang sangat sementara. Sayangnya, jika jaringan tidak dapat diandalkan, Galera Cluster tidak akan dapat bekerja dengan benar - node akan mulai meninggalkan cluster, bergabunglah nanti. Ini akan menjadi masalah khususnya jika kita memiliki Galera Cluster yang menjangkau seluruh WAN - bagian cluster yang terpisah dapat hilang secara acak jika jaringan interkoneksi tidak berfungsi dengan baik.
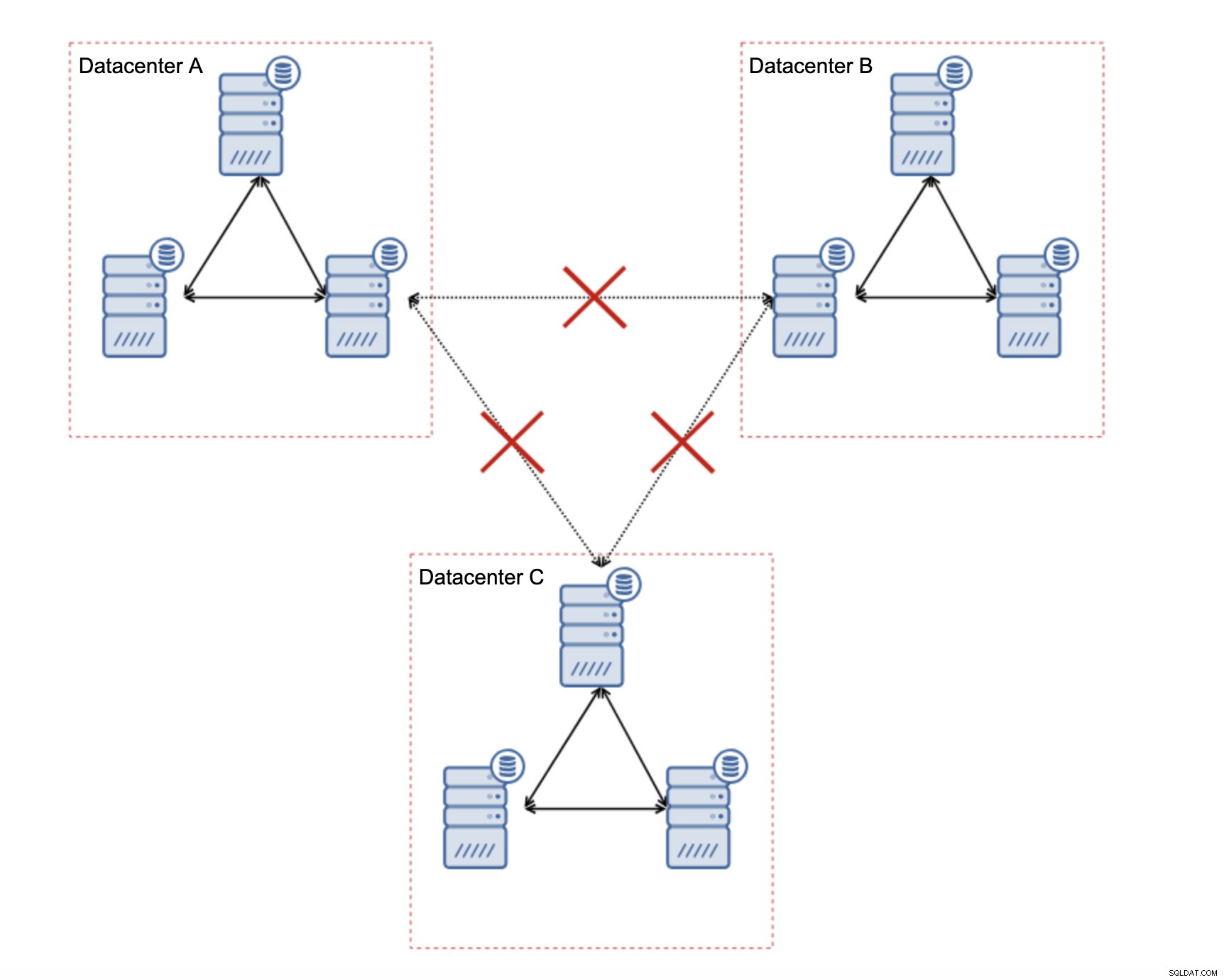
Bagaimana Mendesain Cluster Galera untuk Jaringan yang Tidak Stabil?
Hal pertama yang pertama, jika Anda memiliki masalah jaringan di dalam pusat data tunggal, tidak banyak yang dapat Anda lakukan kecuali jika Anda dapat menyelesaikan masalah tersebut. Jaringan lokal yang tidak dapat diandalkan tidak cocok untuk Galera Cluster, Anda harus mempertimbangkan kembali untuk menggunakan beberapa solusi lain (meskipun, sejujurnya, jaringan yang tidak dapat diandalkan akan selalu menjadi masalah). Di sisi lain, jika masalah hanya terkait dengan koneksi WAN (dan ini adalah salah satu kasus yang paling umum), mungkin saja untuk mengganti tautan WAN Galera dengan replikasi asinkron biasa (jika penyetelan Galera WAN tidak membantu).
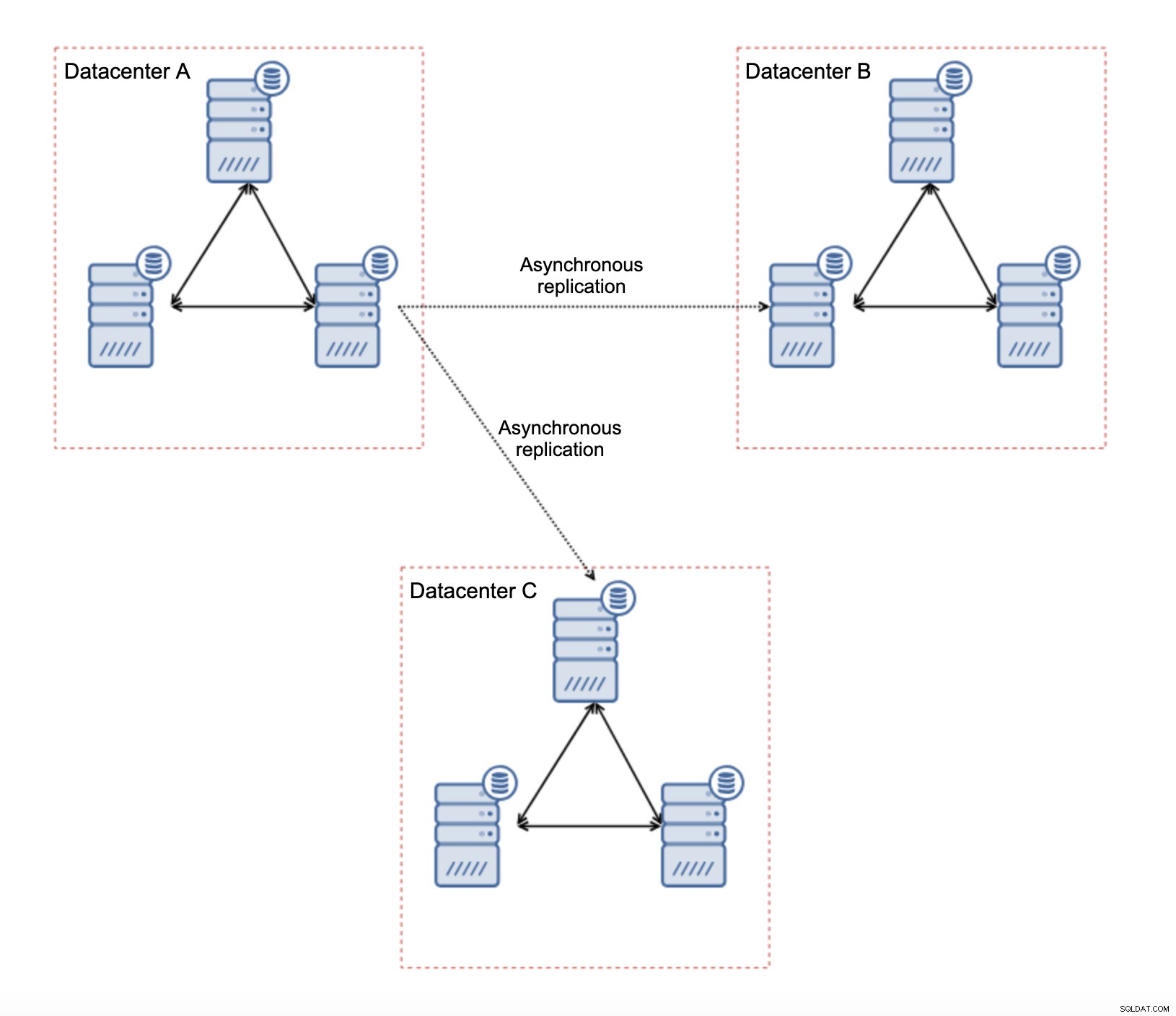
Ada beberapa batasan bawaan dalam penyiapan ini - masalah utamanya adalah penulisan biasanya dilakukan secara lokal. Sekarang, semua penulisan harus menuju ke pusat data "master" (DC A dalam kasus kami). Ini tidak seburuk kedengarannya. Harap diingat bahwa dalam lingkungan all-Galera, penulisan akan diperlambat oleh latensi antara node yang terletak di pusat data yang berbeda. Bahkan penulisan lokal akan terpengaruh. Ini akan menjadi perlambatan yang kurang lebih sama dengan penyiapan asinkron di mana Anda akan mengirim penulisan melalui WAN ke pusat data “master”.
Menggunakan replikasi asinkron datang dengan semua masalah khas untuk replikasi asinkron. Keterlambatan replikasi dapat menjadi masalah - bukan karena Galera akan lebih berperforma, hanya saja Galera akan memperlambat lalu lintas melalui kontrol aliran sementara replikasi tidak memiliki mekanisme apa pun untuk membatasi lalu lintas di master.
Masalah lainnya adalah failover:jika node Galera “master” (yang bertindak sebagai master untuk slave di pusat data lain) akan gagal, beberapa mekanisme harus dibuat untuk mengarahkan kembali slave ke node master lain yang berfungsi. Ini mungkin semacam skrip, juga memungkinkan untuk mencoba sesuatu dengan VIP di mana cluster Galera “slave” menggunakan IP Virtual yang selalu ditetapkan ke node Galera yang hidup di cluster “master”.
Keuntungan utama dari pengaturan tersebut adalah bahwa kami menghapus tautan WAN Galera yang berarti bahwa cluster "master" kami tidak akan diperlambat oleh fakta bahwa beberapa node terpisah secara geografis. Seperti yang kami sebutkan, kami kehilangan kemampuan untuk menulis di semua pusat data, tetapi penulisan berdasarkan latensi di seluruh WAN sama dengan menulis secara lokal ke kluster Galera yang membentang di seluruh WAN. Akibatnya, latensi keseluruhan harus meningkat. Replikasi asinkron juga kurang rentan terhadap jaringan yang tidak stabil. Skenario terburuk, link replikasi akan rusak dan akan dibuat ulang saat jaringan bertemu.
Bagaimana Mendesain Replikasi MySQL untuk Jaringan yang Tidak Stabil?
Di bagian sebelumnya, kami membahas kluster Galera dan salah satu solusinya adalah menggunakan replikasi asinkron. Bagaimana tampilannya dalam pengaturan replikasi asinkron biasa? Mari kita lihat bagaimana jaringan yang tidak stabil dapat menyebabkan gangguan terbesar dalam penyiapan replikasi.
Pertama-tama, latensi - salah satu masalah utama untuk Galera Cluster. Dalam hal replikasi, itu hampir tidak menjadi masalah. Kecuali Anda menggunakan replikasi semi-sinkron yaitu - dalam kasus seperti itu, peningkatan latensi akan memperlambat penulisan. Dalam replikasi asinkron, latensi tidak berdampak pada kinerja penulisan. Namun, ini mungkin berdampak pada jeda replikasi. Ini tidak sepenting untuk Galera tetapi Anda mungkin mengharapkan lebih banyak lonjakan lag dan kinerja replikasi yang kurang stabil secara keseluruhan jika jaringan antar node mengalami latensi tinggi. Hal ini sebagian besar disebabkan oleh fakta bahwa master mungkin juga melayani beberapa penulisan sebelum transfer data ke slave dapat dimulai pada jaringan latensi tinggi.
Ketidakstabilan jaringan pasti dapat memengaruhi tautan replikasi tetapi, sekali lagi, tidak terlalu kritis. Budak MySQL akan mencoba menyambung kembali ke masternya dan replikasi akan dimulai.
Masalah utama dengan replikasi MySQL sebenarnya adalah sesuatu yang diselesaikan Galera Cluster secara internal - partisi jaringan. Kita berbicara tentang partisi jaringan sebagai kondisi di mana segmen jaringan dipisahkan satu sama lain. Replikasi MySQL menggunakan satu node penulis tunggal - master. Tidak peduli bagaimana Anda mendesain lingkungan Anda, Anda harus mengirim tulisan Anda ke master. Jika master tidak tersedia (untuk alasan apa pun), aplikasi tidak dapat melakukan tugasnya kecuali jika dijalankan dalam semacam mode read-only. Oleh karena itu ada kebutuhan untuk memilih master baru sesegera mungkin. Di sinilah masalah muncul.
Pertama, bagaimana membedakan host mana yang master dan mana yang bukan. Salah satu cara yang biasa digunakan adalah dengan menggunakan variabel “read_only” untuk membedakan slave dari master. Jika node telah read_only diaktifkan (set read_only=1), node tersebut adalah slave (karena slave tidak boleh menangani penulisan langsung apa pun). Jika node memiliki read_only dinonaktifkan (set read_only=0), itu adalah master. Untuk membuat segalanya lebih aman, pendekatan umum adalah mengatur read_only=1 dalam konfigurasi MySQL - jika dimulai ulang, lebih aman jika node muncul sebagai budak. “Bahasa” seperti itu dapat dipahami oleh proxy seperti ProxySQL atau MaxScale.
Mari kita lihat contohnya.
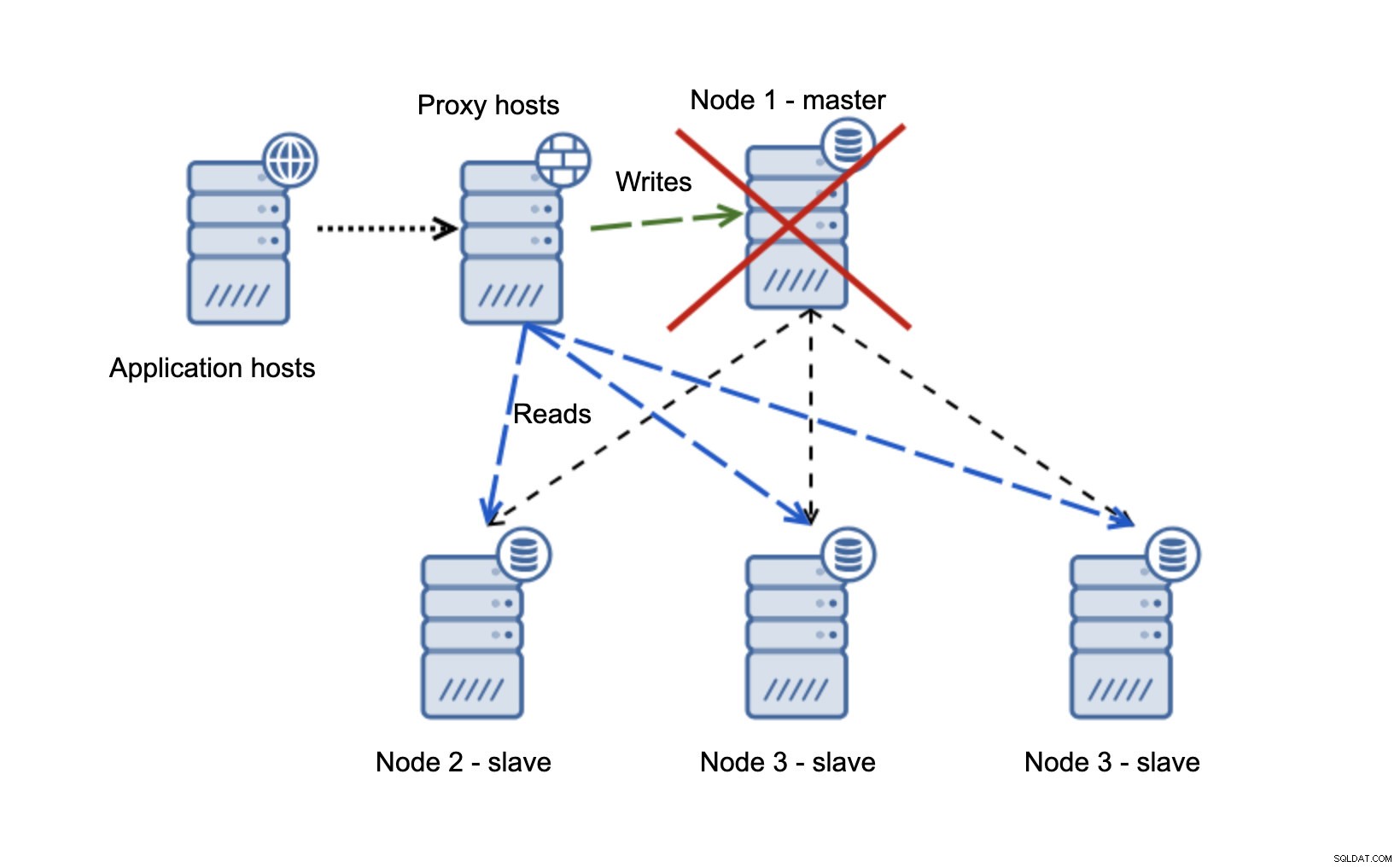
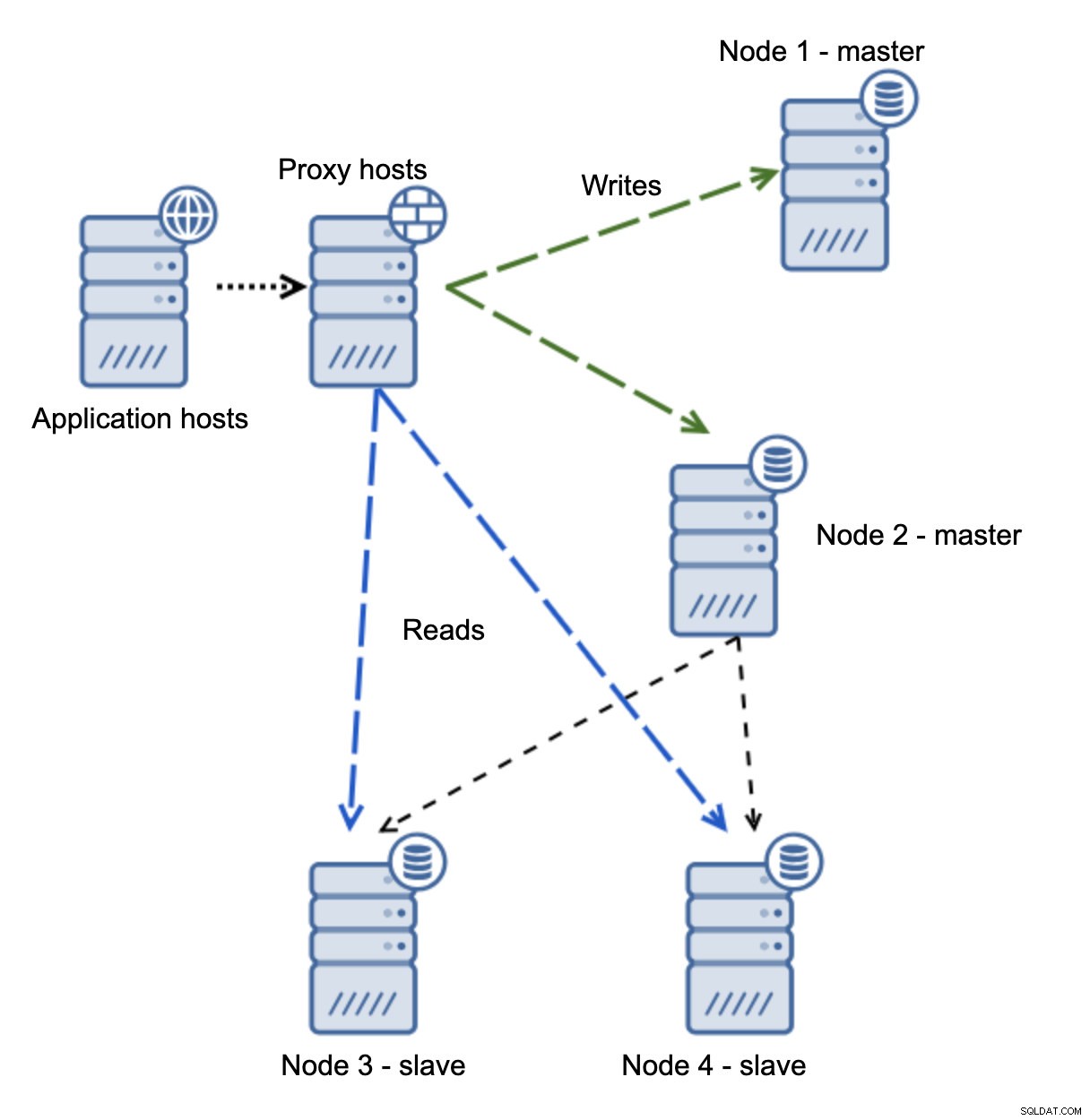
Kami memiliki host aplikasi yang terhubung ke lapisan proxy. Proxy melakukan pemisahan baca/tulis mengirim SELECT ke slave dan menulis ke master. Jika master down, failover dilakukan, master baru dipromosikan, lapisan proxy mendeteksinya dan mulai mengirim penulisan ke node lain.
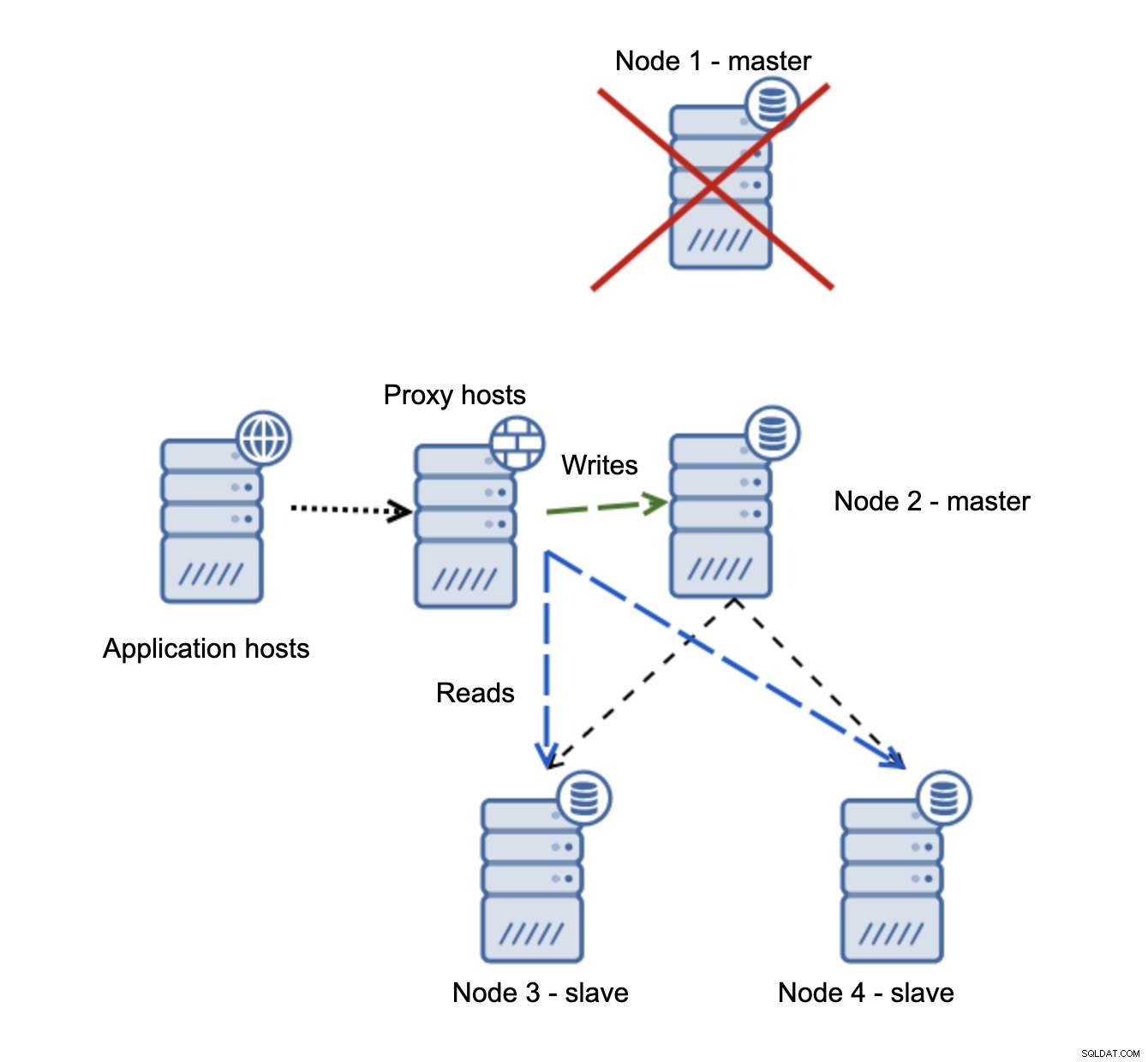
Jika node1 restart, itu akan muncul dengan read_only=1 dan akan terdeteksi sebagai budak. Ini tidak ideal karena tidak mereplikasi tetapi dapat diterima. Idealnya, master lama tidak akan muncul sama sekali sampai master tersebut dibangun kembali dan digantikan oleh master baru.
Situasi yang jauh lebih bermasalah adalah jika kita harus berurusan dengan partisi jaringan. Mari kita pertimbangkan penyiapan yang sama:tingkat aplikasi, tingkat proxy, dan database.
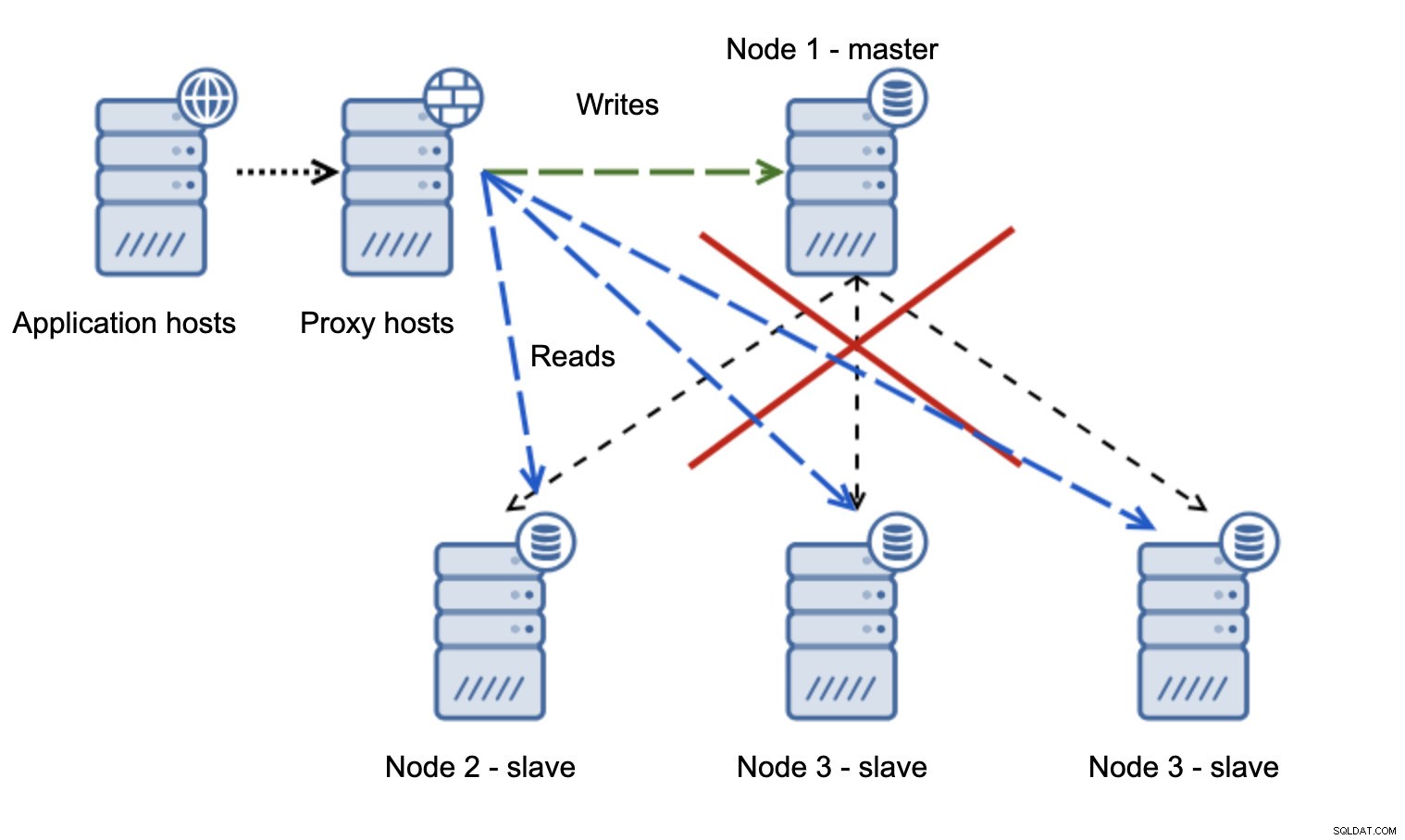
Ketika jaringan membuat master tidak dapat dijangkau, aplikasi tidak dapat digunakan karena tidak ada penulisan yang sampai ke tujuan. Master baru dipromosikan, penulisan dialihkan ke sana. Lalu apa yang akan terjadi jika masalah jaringan berhenti dan master lama dapat dijangkau? Itu belum dihentikan, oleh karena itu masih menggunakan read_only=0:
Anda sekarang telah berakhir di otak yang terbelah, ketika penulisan diarahkan ke dua node. Situasi ini sangat buruk karena untuk menggabungkan kumpulan data yang berbeda mungkin memerlukan waktu dan proses yang cukup rumit.
Apa yang bisa dilakukan untuk menghindari masalah ini? Tidak ada peluru perak tetapi beberapa tindakan dapat diambil untuk meminimalkan kemungkinan terjadinya perpecahan otak.
Pertama-tama, Anda bisa lebih pintar dalam mendeteksi keadaan master. Bagaimana para budak melihatnya? Bisakah mereka menirunya? Mungkin beberapa budak masih dapat terhubung ke master, artinya master sedang aktif dan berjalan atau, setidaknya, memungkinkan untuk menghentikannya jika diperlukan. Bagaimana dengan lapisan proxy? Apakah semua node proxy melihat master sebagai tidak tersedia? Jika beberapa masih dapat terhubung, maka Anda dapat mencoba menggunakan node tersebut untuk ssh ke master dan menghentikannya sebelum failover?
Perangkat lunak manajemen failover juga dapat lebih pintar dalam mendeteksi keadaan jaringan. Mungkin menggunakan RAFT atau protokol pengelompokan lainnya untuk membangun cluster yang sadar kuorum. Jika perangkat lunak manajemen failover dapat mendeteksi otak yang terbelah, ia juga dapat mengambil beberapa tindakan berdasarkan ini seperti, misalnya, menyetel semua node di segmen yang dipartisi ke read_only memastikan bahwa master lama tidak akan muncul sebagai dapat ditulisi saat jaringan bertemu.
Anda juga dapat menyertakan alat seperti Consul atau Dll untuk menyimpan status cluster. Lapisan proxy dapat dikonfigurasi untuk menggunakan data dari Konsul, bukan status variabel read_only. Selanjutnya terserah pada perangkat lunak manajemen failover untuk membuat perubahan yang diperlukan di Konsul sehingga semua proxy akan mengirimkan lalu lintas ke master baru yang benar.
Beberapa dari petunjuk tersebut bahkan dapat digabungkan bersama untuk membuat deteksi kegagalan menjadi lebih andal. Secara keseluruhan, adalah mungkin untuk meminimalkan kemungkinan bahwa cluster replikasi akan menderita dari jaringan yang tidak dapat diandalkan.
Seperti yang Anda lihat, tidak peduli apakah kita berbicara tentang Galera atau Replikasi MySQL, jaringan yang tidak stabil dapat menjadi masalah serius. Di sisi lain, jika Anda mendesain lingkungan dengan benar, Anda masih bisa membuatnya bekerja. Kami berharap posting blog ini akan membantu Anda menciptakan lingkungan yang akan bekerja dengan stabil meskipun jaringan tidak.