Ketersediaan Tinggi adalah persyaratan untuk hampir setiap perusahaan di seluruh dunia yang menggunakan PostgreSQL Sudah diketahui bahwa PostgreSQL menggunakan Replikasi Streaming sebagai metode replikasi. Replikasi Streaming PostgreSQL tidak sinkron secara default, sehingga beberapa transaksi dapat dilakukan di node utama yang belum direplikasi ke server siaga. Ini berarti ada kemungkinan beberapa potensi kehilangan data.
Penundaan dalam proses komit ini seharusnya sangat kecil... jika server siaga cukup kuat untuk mengimbangi beban. Jika risiko kehilangan data kecil ini tidak dapat diterima di perusahaan, Anda juga dapat menggunakan replikasi sinkron alih-alih default.
Dalam replikasi sinkron, setiap komit dari transaksi tulis akan menunggu hingga konfirmasi bahwa komit telah ditulis ke log tulis-depan pada disk dari server utama dan server siaga.
Metode ini meminimalkan kemungkinan kehilangan data. Agar kehilangan data terjadi, Anda memerlukan primer dan siaga agar gagal pada saat yang bersamaan.
Kerugian metode ini sama untuk semua metode sinkron karena dengan metode ini waktu respons untuk setiap transaksi tulis meningkat. Ini karena kebutuhan untuk menunggu sampai semua konfirmasi bahwa transaksi telah dilakukan. Untungnya, transaksi read-only tidak akan terpengaruh oleh hal ini, tetapi; hanya transaksi tulis.
Di blog ini, Anda menunjukkan cara menginstal Cluster PostgreSQL dari awal, mengubah replikasi asinkron (default) menjadi yang sinkron. Saya juga akan menunjukkan cara mengembalikan jika waktu respons tidak dapat diterima karena Anda dapat dengan mudah kembali ke keadaan sebelumnya. Anda akan melihat cara menerapkan, mengonfigurasi, dan memantau replikasi sinkron PostgreSQL dengan mudah menggunakan ClusterControl hanya menggunakan satu alat untuk seluruh proses.
Memasang Cluster PostgreSQL
Mari kita mulai menginstal dan mengonfigurasi replikasi PostgreSQL asinkron, yaitu mode replikasi yang biasa digunakan dalam cluster PostgreSQL. Kami akan menggunakan PostgreSQL 11 pada CentOS 7.
Instalasi PostgreSQL
Mengikuti panduan instalasi resmi PostgreSQL, tugas ini cukup sederhana.
Pertama, instal repositori:
$ yum install https://download.postgresql.org/pub/repos/yum/reporpms/EL-7-x86_64/pgdg-redhat-repo-latest.noarch.rpmInstal paket klien dan server PostgreSQL:
$ yum install postgresql11 postgresql11-serverInisialisasi database:
$ /usr/pgsql-11/bin/postgresql-11-setup initdb
$ systemctl enable postgresql-11
$ systemctl start postgresql-11Pada node siaga, Anda dapat menghindari perintah terakhir (memulai layanan database) karena Anda akan memulihkan cadangan biner untuk membuat replikasi streaming.
Sekarang, mari kita lihat konfigurasi yang diperlukan oleh replikasi PostgreSQL asinkron.
Mengonfigurasi Replikasi PostgreSQL Asinkron
Pengaturan Node Utama
Di node utama PostgreSQL, Anda harus menggunakan konfigurasi dasar berikut untuk membuat replikasi Async. File yang akan dimodifikasi adalah postgresql.conf dan pg_hba.conf. Secara umum, mereka berada di direktori data (/var/lib/pgsql/11/data/) tetapi Anda dapat mengonfirmasinya di sisi database:
postgres=# SELECT setting FROM pg_settings WHERE name = 'data_directory';
setting
------------------------
/var/lib/pgsql/11/data
(1 row)Postgresql.conf
Ubah atau tambahkan parameter berikut di file konfigurasi postgresql.conf.
Di sini Anda perlu menambahkan alamat IP untuk mendengarkan. Nilai defaultnya adalah 'localhost', dan untuk contoh ini, kami akan menggunakan '*' untuk semua alamat IP di server.
listen_addresses = '*' Setel port server tempat mendengarkan. Secara default 5432.
port = 5432 Tentukan berapa banyak informasi yang ditulis ke WAL. Nilai yang mungkin minimal, replika, atau logis. Nilai hot_standby dipetakan ke replika dan digunakan untuk menjaga kompatibilitas dengan versi sebelumnya.
wal_level = hot_standby Setel jumlah maksimum proses walsender, yang mengelola koneksi dengan server siaga.
max_wal_senders = 16Setel jumlah minimum file WAL untuk disimpan di direktori pg_wal.
wal_keep_segments = 32Mengubah parameter ini memerlukan restart layanan database.
$ systemctl restart postgresql-11Pg_hba.conf
Ubah atau tambahkan parameter berikut di file konfigurasi pg_hba.conf.
# TYPE DATABASE USER ADDRESS METHOD
host replication replication_user IP_STANDBY_NODE/32 md5
host replication replication_user IP_PRIMARY_NODE/32 md5Seperti yang Anda lihat, di sini Anda perlu menambahkan izin akses pengguna. Kolom pertama adalah jenis koneksi, yang dapat berupa host atau lokal. Kemudian, Anda perlu menentukan database (replikasi), pengguna, alamat IP sumber dan metode otentikasi. Mengubah file ini memerlukan pemuatan ulang layanan database.
$ systemctl reload postgresql-11Anda harus menambahkan konfigurasi ini di node primer dan standby, karena Anda akan membutuhkannya jika node standby dipromosikan menjadi master jika terjadi kegagalan.
Sekarang, Anda harus membuat pengguna replikasi.
Peran Replikasi
ROLE (pengguna) harus memiliki hak REPLICATION untuk menggunakannya dalam replikasi streaming.
postgres=# CREATE ROLE replication_user WITH LOGIN PASSWORD 'PASSWORD' REPLICATION;
CREATE ROLESetelah mengonfigurasi file yang sesuai dan pembuatan pengguna, Anda perlu membuat cadangan yang konsisten dari node utama dan memulihkannya di node siaga.
Pengaturan Node Siaga
Pada node standby, buka direktori /var/lib/pgsql/11/ dan pindahkan atau hapus datadir saat ini:
$ cd /var/lib/pgsql/11/
$ mv data data.bkKemudian, jalankan perintah pg_basebackup untuk mendapatkan datadir utama saat ini dan tetapkan pemilik yang benar (postgres):
$ pg_basebackup -h 192.168.100.145 -D /var/lib/pgsql/11/data/ -P -U replication_user --wal-method=stream
$ chown -R postgres.postgres dataSekarang, Anda harus menggunakan konfigurasi dasar berikut untuk membuat replikasi Async. File yang akan dimodifikasi adalah postgresql.conf, dan Anda perlu membuat file recovery.conf baru. Keduanya akan ditempatkan di /var/lib/pgsql/11/.
Pemulihan.conf
Tentukan bahwa server ini akan menjadi server siaga. Jika aktif, server akan terus memulihkan dengan mengambil segmen WAL baru saat akhir WAL yang diarsipkan tercapai.
standby_mode = 'on'Tentukan string koneksi yang akan digunakan server siaga untuk terhubung ke node utama.
primary_conninfo = 'host=IP_PRIMARY_NODE port=5432 user=replication_user password=PASSWORD'Tentukan pemulihan ke dalam timeline tertentu. Standarnya adalah memulihkan di sepanjang garis waktu yang sama dengan saat pencadangan dasar dilakukan. Menyetel ini ke "terbaru" akan memulihkan ke garis waktu terbaru yang ditemukan di arsip.
recovery_target_timeline = 'latest'Tentukan file pemicu yang kehadirannya mengakhiri pemulihan di standby.
trigger_file = '/tmp/failover_5432.trigger'Postgresql.conf
Ubah atau tambahkan parameter berikut di file konfigurasi postgresql.conf.
Tentukan berapa banyak informasi yang ditulis ke WAL. Nilai yang mungkin minimal, replika, atau logis. Nilai hot_standby dipetakan ke replika dan digunakan untuk menjaga kompatibilitas dengan versi sebelumnya. Mengubah nilai ini memerlukan restart layanan.
wal_level = hot_standbyIzinkan kueri selama pemulihan. Mengubah nilai ini memerlukan restart layanan.
hot_standby = onMemulai Node Siaga
Sekarang Anda memiliki semua konfigurasi yang diperlukan, Anda hanya perlu memulai layanan database pada node siaga.
$ systemctl start postgresql-11Dan periksa log database di /var/lib/pgsql/11/data/log/. Anda harus memiliki sesuatu seperti ini:
2019-11-18 20:23:57.440 UTC [1131] LOG: entering standby mode
2019-11-18 20:23:57.447 UTC [1131] LOG: redo starts at 0/3000028
2019-11-18 20:23:57.449 UTC [1131] LOG: consistent recovery state reached at 0/30000F8
2019-11-18 20:23:57.449 UTC [1129] LOG: database system is ready to accept read only connections
2019-11-18 20:23:57.457 UTC [1135] LOG: started streaming WAL from primary at 0/4000000 on timeline 1Anda juga dapat memeriksa status replikasi di node utama dengan menjalankan kueri berikut:
postgres=# SELECT pid,usename,application_name,state,sync_state FROM pg_stat_replication;
pid | usename | application_name | state | sync_state
------+------------------+------------------+-----------+------------
1467 | replication_user | walreceiver | streaming | async
(1 row)Seperti yang Anda lihat, kami menggunakan replikasi asinkron.
Mengonversi Replikasi PostgreSQL Asinkron menjadi Replikasi Sinkron
Sekarang, saatnya untuk mengubah replikasi asinkron ini menjadi replikasi yang sinkron, dan untuk ini, Anda perlu mengonfigurasi node utama dan node siaga.
Node Utama
Di node utama PostgreSQL, Anda harus menggunakan konfigurasi dasar ini selain konfigurasi async sebelumnya.
Postgresql.conf
Tentukan daftar server siaga yang dapat mendukung replikasi sinkron. Nama server standby ini adalah pengaturan application_name di file recovery.conf standby.
synchronous_standby_names = 'pgsql_0_node_0'synchronous_standby_names = 'pgsql_0_node_0'Menentukan apakah komit transaksi akan menunggu catatan WAL ditulis ke disk sebelum perintah mengembalikan indikasi "berhasil" ke klien. Nilai yang valid adalah aktif, remote_apply, remote_write, lokal, dan nonaktif. Nilai default aktif.
synchronous_commit = onPenyiapan Node Siaga
Di node siaga PostgreSQL, Anda perlu mengubah file recovery.conf dengan menambahkan 'nilai nama_aplikasi dalam parameter primary_conninfo.
Pemulihan.conf
standby_mode = 'on'
primary_conninfo = 'application_name=pgsql_0_node_0 host=IP_PRIMARY_NODE port=5432 user=replication_user password=PASSWORD'
recovery_target_timeline = 'latest'
trigger_file = '/tmp/failover_5432.trigger'Mulai ulang layanan database di node utama dan node siaga:
$ service postgresql-11 restartSekarang, Anda seharusnya sudah mengaktifkan dan menjalankan replikasi streaming streaming:
postgres=# SELECT pid,usename,application_name,state,sync_state FROM pg_stat_replication;
pid | usename | application_name | state | sync_state
------+------------------+------------------+-----------+------------
1561 | replication_user | pgsql_0_node_0 | streaming | sync
(1 row)Rollback dari Replikasi PostgreSQL Sinkron ke Asinkron
Jika Anda perlu kembali ke replikasi PostgreSQL asinkron, Anda hanya perlu mengembalikan perubahan yang dilakukan di file postgresql.conf pada node utama:
Postgresql.conf
#synchronous_standby_names = 'pgsql_0_node_0'
#synchronous_commit = onDan restart layanan database.
$ service postgresql-11 restartJadi sekarang, Anda seharusnya memiliki replikasi asinkron lagi.
postgres=# SELECT pid,usename,application_name,state,sync_state FROM pg_stat_replication;
pid | usename | application_name | state | sync_state
------+------------------+------------------+-----------+------------
1625 | replication_user | pgsql_0_node_0 | streaming | async
(1 row)Cara Menyebarkan Replikasi Sinkron PostgreSQL Menggunakan ClusterControl
Dengan ClusterControl Anda dapat melakukan tugas penerapan, konfigurasi, dan pemantauan all-in-one dari pekerjaan yang sama dan Anda akan dapat mengelolanya dari UI yang sama.
Kami akan berasumsi bahwa Anda telah menginstal ClusterControl dan dapat mengakses node database melalui SSH. Untuk informasi lebih lanjut tentang cara mengonfigurasi akses ClusterControl, silakan merujuk ke dokumentasi resmi kami.
Buka ClusterControl dan gunakan opsi “Deploy” untuk membuat cluster PostgreSQL baru.
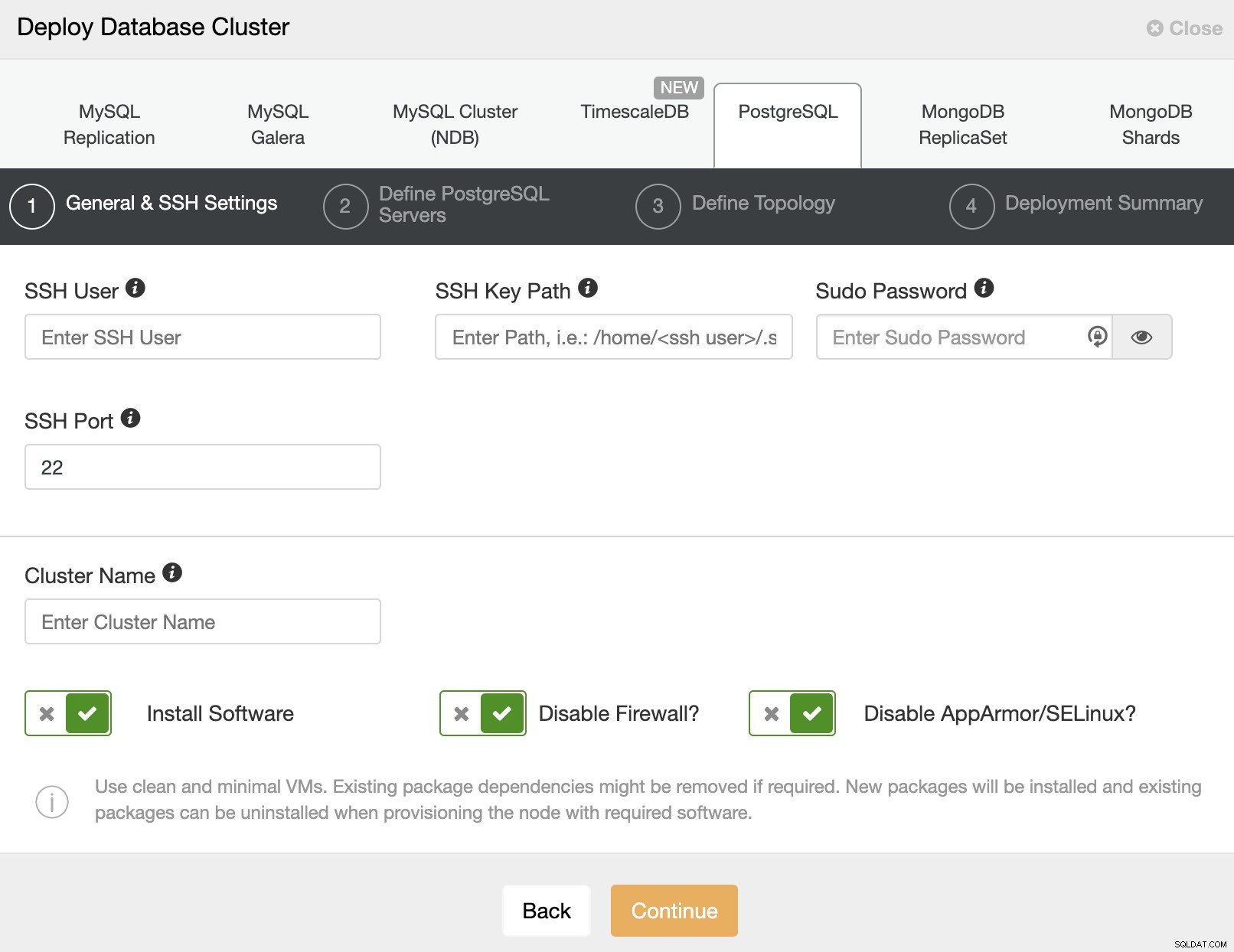
Saat memilih PostgreSQL, Anda harus menentukan Pengguna, Kunci, atau Kata Sandi dan port untuk terhubung dengan SSH ke server kami. Anda juga memerlukan nama untuk cluster baru Anda dan jika Anda ingin ClusterControl menginstal perangkat lunak dan konfigurasi yang sesuai untuk Anda.
Setelah mengatur informasi akses SSH, Anda harus memasukkan data untuk mengakses database Anda. Anda juga dapat menentukan repositori mana yang akan digunakan.
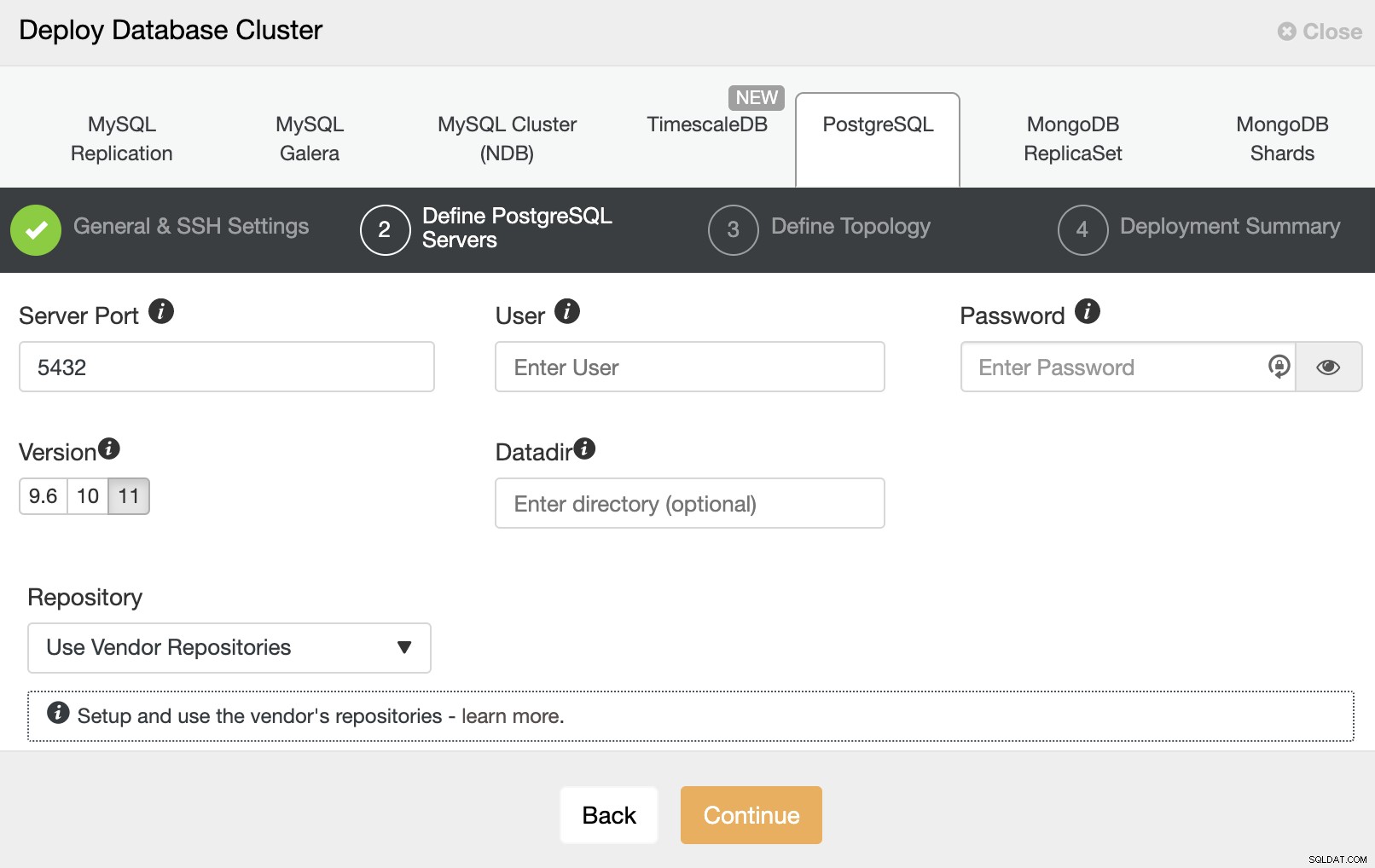
Pada langkah selanjutnya, Anda perlu menambahkan server Anda ke cluster yang Anda akan membuat. Saat menambahkan server Anda, Anda dapat memasukkan IP atau nama host.
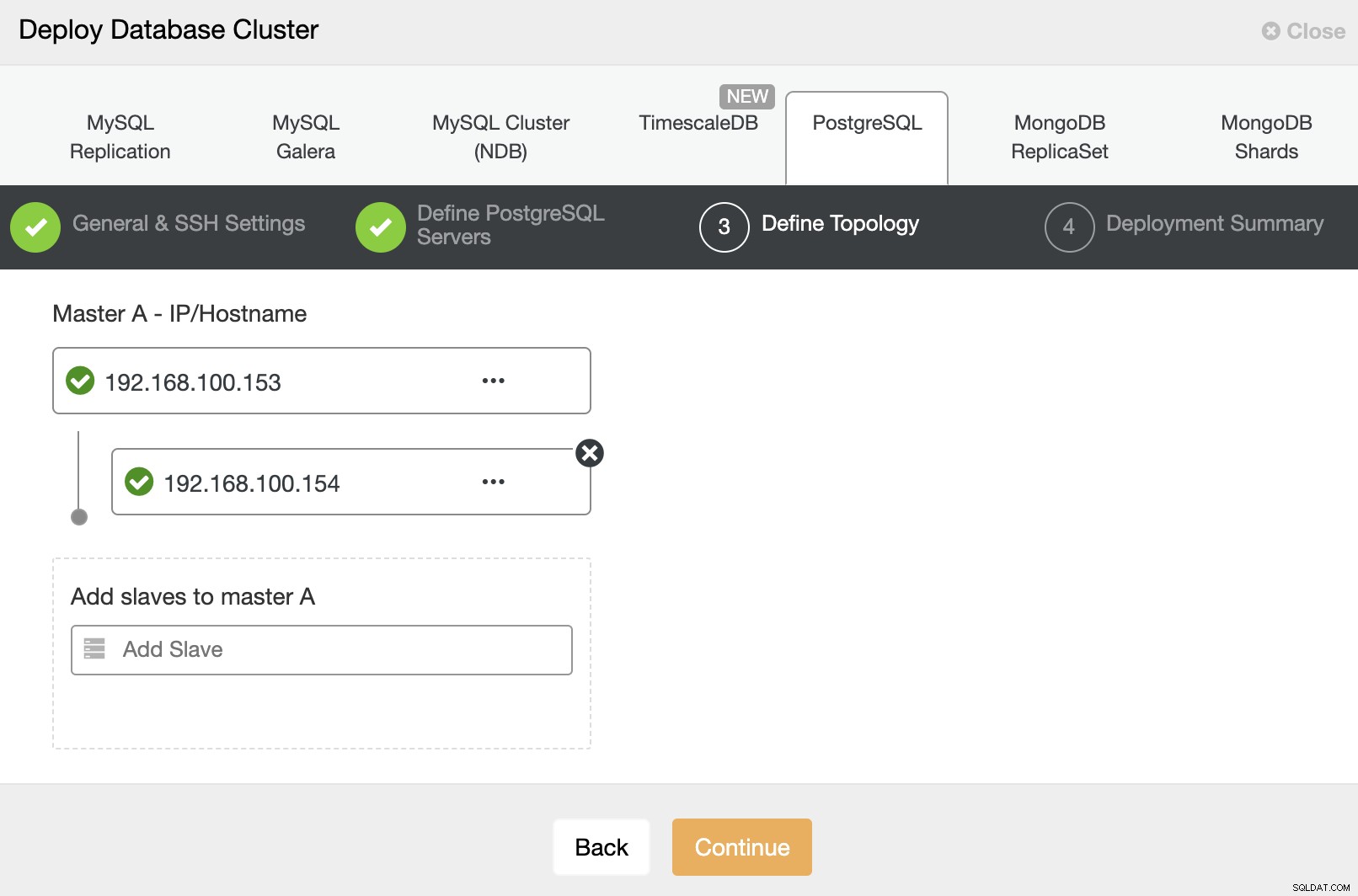
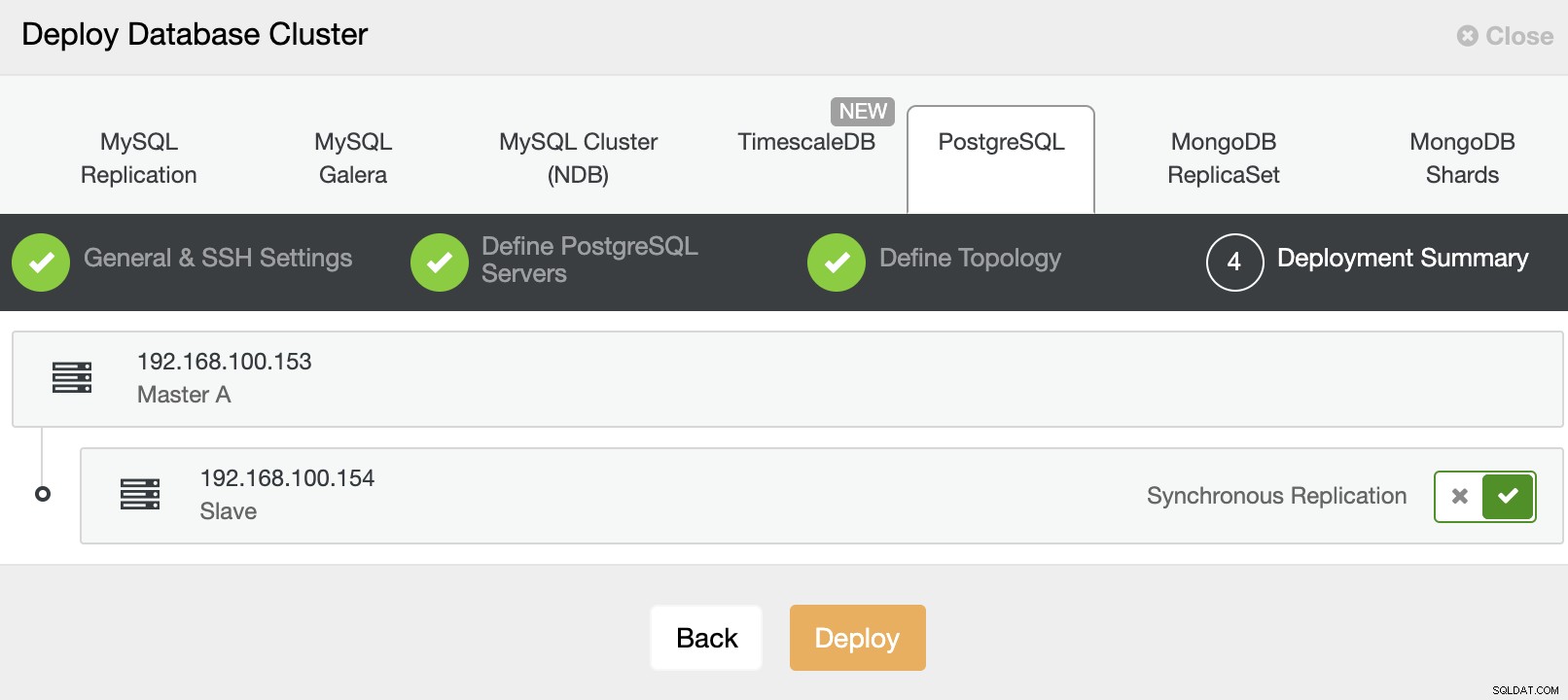
Dan terakhir, pada langkah terakhir, Anda dapat memilih metode replikasi, yang dapat berupa replikasi asinkron atau sinkron.
Itu dia. Anda dapat memantau status pekerjaan di bagian aktivitas ClusterControl.
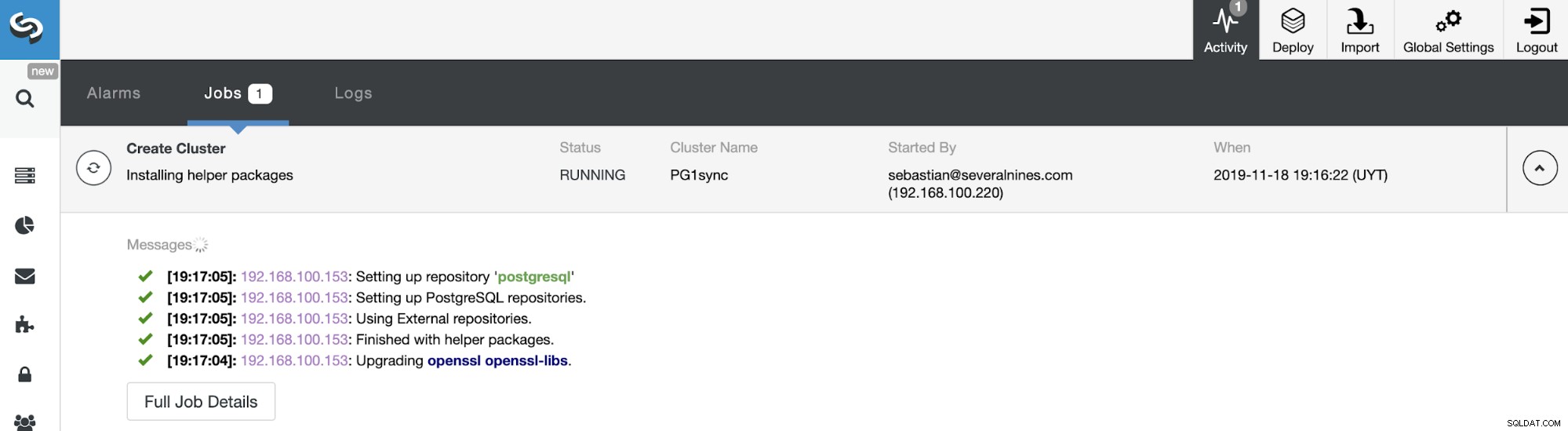
Dan ketika pekerjaan ini selesai, Anda akan menginstal cluster sinkron PostgreSQL, dikonfigurasi dan dipantau oleh ClusterControl.
Kesimpulan
Seperti yang kami sebutkan di awal blog ini, Ketersediaan Tinggi adalah persyaratan untuk semua perusahaan, jadi Anda harus mengetahui opsi yang tersedia untuk mencapainya untuk setiap teknologi yang digunakan. Untuk PostgreSQL, Anda dapat menggunakan replikasi streaming sinkron sebagai cara teraman untuk mengimplementasikannya, tetapi metode ini tidak berfungsi untuk semua lingkungan dan beban kerja.
Berhati-hatilah dengan latensi yang dihasilkan dengan menunggu konfirmasi setiap transaksi yang dapat menjadi masalah, bukan solusi Ketersediaan Tinggi.