failover otomatis cukup banyak harus dimiliki untuk banyak aplikasi - uptime diterima begitu saja. Cukup sulit untuk menerima bahwa aplikasi tidak aktif selama 20 atau 30 menit karena seseorang harus membuka halaman untuk masuk dan menyelidiki situasi sebelum mengambil tindakan.
Di dunia nyata, pengaturan replikasi cenderung tumbuh dari waktu ke waktu menjadi kompleks, terkadang berantakan. Dan ada kendala. Misalnya, tidak setiap node dalam setup membuat kandidat master yang baik. Mungkin perangkat kerasnya berbeda dan beberapa replika memiliki perangkat keras yang kurang kuat karena didedikasikan untuk menangani beberapa jenis beban kerja tertentu? Mungkin Anda berada di tengah-tengah migrasi ke versi MySQL baru dan beberapa budak telah ditingkatkan? Anda lebih suka tidak memiliki master dalam versi yang lebih baru yang mereplikasi ke replika lama, karena ini dapat merusak replikasi. Jika Anda memiliki dua pusat data, satu aktif dan satu untuk pemulihan bencana, Anda dapat memilih untuk memilih kandidat master hanya di pusat data aktif, untuk menjaga master tetap dekat dengan host aplikasi. Itu hanyalah contoh situasi, di mana Anda mungkin membutuhkan intervensi manual selama proses failover. Untungnya, banyak alat failover memiliki opsi untuk mengendalikan proses dengan menggunakan daftar putih dan daftar hitam. Dalam postingan blog ini, kami ingin menunjukkan kepada Anda beberapa contoh bagaimana Anda dapat memengaruhi algoritme ClusterControl untuk memilih kandidat master.
Konfigurasi Daftar Putih dan Daftar Hitam
ClusterControl memberi Anda opsi untuk menentukan daftar putih dan daftar hitam replika. Daftar putih adalah daftar replika yang dimaksudkan untuk menjadi calon master. Jika tidak ada yang tersedia (baik karena down, atau ada transaksi yang salah, atau ada kendala lain yang mencegah salah satu dari mereka untuk dipromosikan), failover tidak akan dilakukan. Dengan cara ini, Anda dapat menentukan host mana yang tersedia untuk menjadi kandidat master. Daftar hitam, di sisi lain, menentukan replika mana yang tidak cocok untuk menjadi kandidat master.
Kedua daftar tersebut dapat didefinisikan dalam file konfigurasi cmon untuk cluster tertentu. Misalnya, jika cluster Anda memiliki id '1', Anda ingin mengedit '/etc/cmon.d/cmon_1.cnf'. Untuk daftar putih Anda akan menggunakan variabel 'replication_failover_whitelist', untuk daftar hitam itu akan menjadi 'replication_failover_blacklist'. Keduanya menerima daftar 'host:port' yang dipisahkan koma.
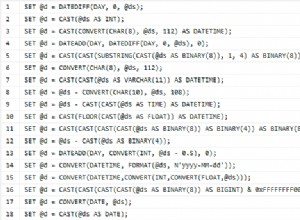
Mari kita pertimbangkan pengaturan replikasi berikut. Kami memiliki master aktif (10.0.0.141) yang memiliki dua replika (10.0.0.142 dan 10.0.0.143), keduanya bertindak sebagai master perantara dan masing-masing memiliki satu replika (10.0.0.144 dan 10.0.0.147). Kami juga memiliki master siaga di pusat data terpisah (10.0.0.145) yang memiliki replika (10.0.0.146). Host tersebut dimaksudkan untuk digunakan jika terjadi bencana. Replika 10.0.0.146 dan 10.0.0.147 bertindak sebagai host cadangan. Lihat tangkapan layar di bawah ini.

Mengingat bahwa pusat data kedua hanya ditujukan untuk pemulihan bencana, kami tidak ingin salah satu dari host tersebut dipromosikan sebagai master. Dalam skenario terburuk, kami akan mengambil tindakan manual. Infrastruktur pusat data kedua tidak diskalakan ke ukuran pusat data produksi (ada tiga replika lebih sedikit di pusat data DR), jadi tindakan manual tetap diperlukan sebelum kami dapat mempromosikan host di pusat data DR. Kami juga tidak ingin replika cadangan (10.0.0.147) dipromosikan. Kami juga tidak ingin replika ketiga dalam rantai diambil sebagai master (meskipun dapat dilakukan dengan GTID).
Konfigurasi Daftar Putih
Kita dapat mengonfigurasi daftar putih atau daftar hitam untuk memastikan bahwa failover akan ditangani sesuai keinginan kita. Dalam pengaturan khusus ini, menggunakan daftar putih mungkin lebih cocok - kami akan menentukan host mana yang dapat digunakan untuk failover dan jika seseorang menambahkan host baru ke pengaturan, itu tidak akan dipertimbangkan sebagai kandidat master sampai seseorang secara manual memutuskannya. ok untuk menggunakannya dan menambahkannya ke daftar putih. Jika kami menggunakan daftar hitam, menambahkan replika baru di suatu tempat dalam rantai dapat berarti bahwa replika tersebut secara teoritis dapat digunakan secara otomatis untuk failover kecuali seseorang secara eksplisit mengatakan itu tidak dapat digunakan. Mari tetap berhati-hati dan tentukan daftar putih di file konfigurasi cluster kami (dalam hal ini /etc/cmon.d/cmon_1.cnf karena kami hanya memiliki satu cluster):
replication_failover_whitelist=10.0.0.141:3306,10.0.0.142:3306,10.0.0.143:3306Kami harus memastikan bahwa proses cmon telah dimulai ulang untuk menerapkan perubahan:
service cmon restartMari kita asumsikan master kita telah crash dan tidak dapat dijangkau oleh ClusterControl. Tugas failover akan dimulai:

Topologinya akan terlihat seperti di bawah ini:

Seperti yang Anda lihat, master lama dinonaktifkan dan ClusterControl tidak akan mencoba memulihkannya secara otomatis. Terserah pengguna untuk memeriksa apa yang telah terjadi, menyalin data apa pun yang mungkin belum direplikasi ke kandidat master dan membangun kembali master lama:

Kemudian tinggal beberapa perubahan topologi dan kita dapat membawa topologi ke keadaan semula, hanya mengganti 10.0.0.141 dengan 10.0.0.142:

Konfigurasi Daftar Hitam
Sekarang kita akan melihat cara kerja daftar hitam. Kami menyebutkan bahwa, dalam contoh kami, ini mungkin bukan pilihan terbaik tetapi kami akan mencobanya demi ilustrasi. Kami akan memasukkan semua host ke daftar hitam kecuali 10.0.0.141, 10.0.0.142 dan 10.0.0.143 karena mereka adalah host yang ingin kami lihat sebagai kandidat master.
replication_failover_blacklist=10.0.0.145:3306,10.0.0.146:3306,10.0.0.144:3306,10.0.0.147:3306Kami juga akan memulai ulang proses cmon untuk menerapkan perubahan konfigurasi:
service cmon restartProses failover serupa. Sekali lagi, setelah master crash terdeteksi, ClusterControl akan memulai tugas failover.

Ketika Replika Mungkin Bukan Kandidat Master yang Baik
Di bagian singkat ini, kami ingin membahas lebih detail beberapa kasus di mana Anda mungkin tidak ingin mempromosikan replika tertentu untuk menjadi master baru. Mudah-mudahan, ini akan memberi Anda beberapa gagasan tentang kasus-kasus di mana Anda mungkin perlu mempertimbangkan untuk mendorong lebih banyak kontrol manual dari proses failover.
Versi MySQL Berbeda
Pertama, jika replika Anda menggunakan versi MySQL yang berbeda dari masternya, mempromosikannya bukanlah ide yang baik. Secara umum, versi yang lebih baru selalu tidak dapat digunakan karena replikasi dari versi MySQL baru ke versi lama tidak didukung dan mungkin tidak berfungsi dengan benar. Ini sebagian besar relevan untuk versi utama (misalnya, 8.0 mereplikasi ke 5.7) tetapi praktik yang baik adalah menghindari pengaturan ini sama sekali, bahkan jika kita berbicara tentang perbedaan versi kecil (5.7.x+1 -> 5.7.x). Replikasi dari versi yang lebih rendah ke yang lebih tinggi/lebih baru didukung karena ini adalah suatu keharusan untuk proses peningkatan, tetapi tetap saja, Anda lebih suka menghindari ini (misalnya, jika master Anda menggunakan 5.7.x+1 Anda lebih suka tidak menggantinya dengan replika di 5.7.x).
Peran Berbeda
Anda dapat menetapkan peran yang berbeda untuk replika Anda. Anda dapat memilih salah satunya agar tersedia bagi pengembang untuk menguji kueri mereka pada kumpulan data produksi. Anda dapat menggunakan salah satunya untuk beban kerja OLAP. Anda dapat menggunakan salah satunya untuk cadangan. Tidak peduli apa itu, biasanya Anda tidak ingin mempromosikan replika tersebut untuk dikuasai. Semua beban kerja tambahan non-standar tersebut dapat menyebabkan masalah kinerja karena overhead tambahan. Pilihan yang baik untuk calon master adalah replika yang menangani beban "normal", kurang lebih jenis beban yang sama seperti master saat ini. Anda kemudian dapat yakin itu akan menangani beban master setelah failover jika menanganinya sebelum itu.
Spesifikasi Perangkat Keras Berbeda
Kami menyebutkan peran yang berbeda untuk replika. Tidak jarang melihat spesifikasi perangkat keras yang berbeda juga, terutama dalam hubungannya dengan peran yang berbeda. Misalnya, budak cadangan kemungkinan besar tidak harus sekuat replika biasa. Pengembang juga dapat menguji kueri mereka pada basis data yang lebih lambat daripada produksi (kebanyakan karena Anda tidak mengharapkan tingkat konkurensi yang sama pada basis data pengembangan dan produksi) dan, misalnya, jumlah inti CPU dapat dikurangi. Penyiapan pemulihan bencana juga dapat dikurangi ukurannya jika peran utamanya adalah mengikuti replikasi dan diharapkan penyiapan DR harus ditingkatkan (baik secara vertikal, dengan mengukur instans dan secara horizontal, dengan menambahkan lebih banyak replika) sebelum lalu lintas dapat dialihkan ke sana.
Replika Tertunda
Beberapa replika mungkin tertunda - ini adalah cara yang sangat baik untuk mengurangi waktu pemulihan jika data hilang, tetapi itu membuat mereka menjadi calon master yang sangat buruk. Jika replika tertunda 30 menit, Anda akan kehilangan 30 menit transaksi tersebut atau Anda harus menunggu (mungkin bukan 30 menit karena, kemungkinan besar, replika dapat mengejar lebih cepat) agar replika menerapkan semua transaksi yang tertunda. ClusterControl memungkinkan Anda untuk memilih apakah Anda ingin menunggu atau jika Anda ingin segera melakukan failover, tetapi ini akan bekerja dengan baik untuk jeda yang sangat kecil - paling lama puluhan detik. Jika failover seharusnya memakan waktu beberapa menit, tidak ada gunanya menggunakan replika seperti itu dan oleh karena itu sebaiknya Anda memasukkannya ke daftar hitam.
Pusat Data Berbeda
Kami menyebutkan pengaturan DR yang diperkecil tetapi bahkan jika pusat data kedua Anda diskalakan ke ukuran produksi, mungkin masih merupakan ide yang baik untuk menyimpan failover dalam satu DC saja. Sebagai permulaan, host aplikasi aktif Anda mungkin terletak di pusat data utama sehingga memindahkan master ke DC siaga akan secara signifikan meningkatkan latensi untuk kueri tulis. Juga, jika terjadi perpecahan jaringan, Anda mungkin ingin menangani situasi ini secara manual. MySQL tidak memiliki mekanisme kuorum bawaan oleh karena itu agak sulit untuk menangani dengan benar (secara otomatis) kehilangan jaringan antara dua pusat data.