Artikel ini menggunakan kueri sederhana untuk menjelajahi beberapa internal mendalam terkait kueri pembaruan.
Contoh Data dan Konfigurasi
Contoh skrip pembuatan data di bawah ini memerlukan tabel angka. Jika Anda belum memilikinya, skrip di bawah ini dapat digunakan untuk membuatnya secara efisien. Tabel angka yang dihasilkan akan berisi satu kolom bilangan bulat dengan angka dari satu hingga satu juta:
WITH Ten(N) AS
(
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
)
SELECT TOP (1000000)
n = IDENTITY(int, 1, 1)
INTO dbo.Numbers
FROM Ten T10,
Ten T100,
Ten T1000,
Ten T10000,
Ten T100000,
Ten T1000000;
ALTER TABLE dbo.Numbers
ADD CONSTRAINT PK_dbo_Numbers_n
PRIMARY KEY CLUSTERED (n)
WITH (SORT_IN_TEMPDB = ON, MAXDOP = 1, FILLFACTOR = 100); Skrip di bawah ini membuat tabel data sampel yang dikelompokkan dengan 10.000 ID, dengan sekitar 100 tanggal mulai yang berbeda per ID. Kolom tanggal akhir awalnya disetel ke nilai tetap '99991231'.
CREATE TABLE dbo.Example
(
SomeID integer NOT NULL,
StartDate date NOT NULL,
EndDate date NOT NULL
);
GO
INSERT dbo.Example WITH (TABLOCKX)
(SomeID, StartDate, EndDate)
SELECT DISTINCT
1 + (N.n % 10000),
DATEADD(DAY, 50000 * RAND(CHECKSUM(NEWID())), '20010101'),
CONVERT(date, '99991231', 112)
FROM dbo.Numbers AS N
WHERE
N.n >= 1
AND N.n <= 1000000
OPTION (MAXDOP 1);
CREATE CLUSTERED INDEX
CX_Example_SomeID_StartDate
ON dbo.Example
(SomeID, StartDate)
WITH (MAXDOP = 1, SORT_IN_TEMPDB = ON); Sementara poin yang dibuat dalam artikel ini berlaku cukup umum untuk semua versi SQL Server saat ini, informasi konfigurasi di bawah ini dapat digunakan untuk memastikan Anda melihat rencana eksekusi dan efek kinerja yang serupa:
- SQL Server 2012 Paket Layanan 3 Edisi Pengembang x64
- Memori server maksimum disetel ke 2048 MB
- Empat prosesor logis tersedia untuk instans
- Tidak ada tanda jejak yang diaktifkan
- Level isolasi berkomitmen baca default
- Opsi basis data RCSI dan SI dinonaktifkan
Hash Agregat Tumpahan
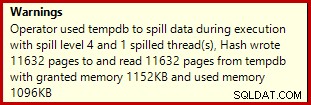
Jika Anda menjalankan skrip pembuatan data di atas dengan rencana eksekusi aktual yang diaktifkan, agregat hash mungkin tumpah ke tempdb, menghasilkan ikon peringatan:

Saat dijalankan pada SQL Server 2012 Service Pack 3, informasi tambahan tentang tumpahan ditampilkan di tooltip:
Tumpahan ini mungkin mengejutkan, mengingat bahwa estimasi baris input untuk Hash Match benar-benar tepat:
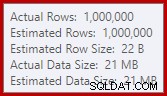
Kami terbiasa membandingkan perkiraan pada masukan untuk pengurutan dan gabungan hash (hanya input build), tetapi agregat hash yang bersemangat berbeda. Agregat hash bekerja dengan mengumpulkan baris hasil yang dikelompokkan dalam tabel hash, jadi ini adalah jumlah output baris yang penting:
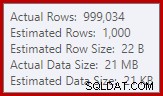
Penaksir kardinalitas di SQL Server 2012 membuat tebakan yang agak buruk pada jumlah nilai berbeda yang diharapkan (1.000 versus 999.034 aktual); agregat hash tumpah secara rekursif ke level 4 saat runtime sebagai konsekuensinya. Penaksir kardinalitas 'baru' yang tersedia di SQL Server 2014 dan seterusnya menghasilkan estimasi yang lebih akurat untuk keluaran hash dalam kueri ini, jadi Anda tidak akan melihat tumpahan hash dalam kasus tersebut:

Jumlah Baris Aktual mungkin sedikit berbeda untuk Anda, mengingat penggunaan generator angka pseudo-acak dalam skrip. Poin pentingnya adalah bahwa tumpahan Hash Aggregate bergantung pada jumlah keluaran nilai unik, bukan pada ukuran masukan.
Spesifikasi Pembaruan
Tugas yang ada adalah memperbarui contoh data sehingga tanggal akhir diatur ke hari sebelum tanggal mulai berikut (per SomeID). Misalnya, beberapa baris pertama dari sampel data mungkin terlihat seperti ini sebelum pembaruan (semua tanggal akhir disetel ke 9999-12-31):

Kemudian seperti ini setelah pembaruan:
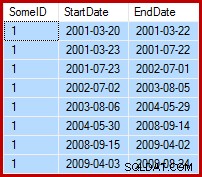
1. Kueri Pembaruan Dasar
Salah satu cara yang wajar untuk mengekspresikan pembaruan yang diperlukan dalam T-SQL adalah sebagai berikut:
UPDATE dbo.Example WITH (TABLOCKX)
SET EndDate =
ISNULL
(
(
SELECT TOP (1)
DATEADD(DAY, -1, E2.StartDate)
FROM dbo.Example AS E2 WITH (TABLOCK)
WHERE
E2.SomeID = dbo.Example.SomeID
AND E2.StartDate > dbo.Example.StartDate
ORDER BY
E2.StartDate ASC
),
CONVERT(date, '99991231', 112)
)
OPTION (MAXDOP 1); Rencana eksekusi pasca-eksekusi (sebenarnya) adalah:
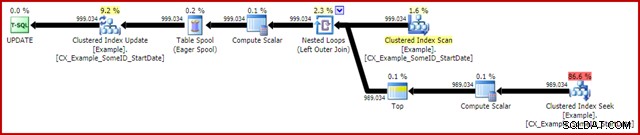
Fitur yang paling menonjol adalah penggunaan Eager Table Spool untuk memberikan Perlindungan Halloween. Ini diperlukan untuk operasi yang benar di sini karena self-join dari tabel target pembaruan. Efeknya adalah semua yang ada di sebelah kanan spool dijalankan sampai selesai, menyimpan semua informasi yang diperlukan untuk membuat perubahan dalam tabel kerja tempdb. Setelah operasi pembacaan selesai, konten tabel kerja diputar ulang untuk menerapkan perubahan pada iterator Pembaruan Indeks Cluster.
Kinerja
Untuk fokus pada potensi kinerja maksimum dari rencana eksekusi ini, kami dapat menjalankan kueri pembaruan yang sama beberapa kali. Jelas, hanya putaran pertama yang akan menghasilkan perubahan apa pun pada data, tetapi ini ternyata menjadi pertimbangan kecil. Jika ini mengganggu Anda, jangan ragu untuk mengatur ulang kolom tanggal akhir sebelum setiap menjalankan menggunakan kode berikut. Poin luas yang akan saya buat tidak bergantung pada jumlah perubahan data yang sebenarnya dibuat.
UPDATE dbo.Example WITH (TABLOCKX) SET EndDate = CONVERT(date, '99991231', 112);
Dengan menonaktifkan kumpulan rencana eksekusi, semua halaman yang diperlukan di kumpulan buffer, dan tidak ada penyetelan ulang nilai tanggal akhir di antara proses, kueri ini biasanya dijalankan dalam waktu sekitar 5700 md di laptop saya. Output statistik IO adalah sebagai berikut:(baca ke depan, pembacaan dan penghitung LOB adalah nol, dan dihilangkan karena alasan spasi)
Table 'Example'. Scan count 999035, logical reads 6186219, physical reads 0 Table 'Worktable'. Scan count 1, logical reads 2895875, physical reads 0
Hitungan pemindaian menunjukkan berapa kali operasi pemindaian dimulai. Untuk tabel Contoh, ini adalah 1 untuk Pemindaian Indeks Clustered, dan 999.034 untuk setiap kali Pencarian Indeks Clustered yang berkorelasi rebound. Meja kerja yang digunakan oleh Eager Spool memiliki operasi pemindaian yang dimulai hanya sekali.
Pembacaan Logis
Informasi yang lebih menarik dalam keluaran IO adalah jumlah pembacaan logis:lebih dari 6 juta untuk tabel Contoh, dan hampir 3 juta untuk meja kerja.
Pembacaan logis tabel Contoh sebagian besar terkait dengan Pencarian dan Pembaruan. Seek menimbulkan 3 pembacaan logis untuk setiap iterasi:masing-masing 1 untuk level root, intermediate, dan leaf dari indeks. Pembaruan juga dikenakan biaya 3 kali pembacaan setiap baris diperbarui, saat mesin menavigasi ke b-tree untuk menemukan baris target. Pemindaian Indeks Berkelompok hanya bertanggung jawab untuk beberapa ribu pembacaan, satu per halaman baca.
Tabel kerja Spool juga terstruktur secara internal sebagai b-tree, dan menghitung beberapa kali pembacaan saat spool menempatkan posisi insert saat menggunakan inputnya. Mungkin berlawanan dengan intuisi, spool tidak menghitung pembacaan logis saat sedang dibaca untuk mendorong Pembaruan Indeks Cluster. Ini hanyalah konsekuensi dari implementasi:pembacaan logis dihitung setiap kali kode mengeksekusi BPool::Get metode. Menulis ke spool memanggil metode ini di setiap level indeks; membaca dari spool mengikuti jalur kode berbeda yang tidak memanggil BPool::Get sama sekali.
Perhatikan juga bahwa statistik keluaran IO melaporkan total tunggal untuk tabel Contoh, meskipun faktanya diakses oleh tiga iterator berbeda dalam rencana eksekusi (Pindai, Cari, dan Perbarui). Fakta terakhir ini membuat sulit untuk mengkorelasikan pembacaan logis dengan iterator yang menyebabkannya. Saya harap batasan ini diatasi di versi produk yang akan datang.
2. Perbarui menggunakan Nomor Baris
Cara lain untuk mengekspresikan kueri pembaruan melibatkan penomoran baris per ID dan bergabung:
WITH Numbered AS
(
SELECT
E.SomeID,
E.StartDate,
E.EndDate,
rn = ROW_NUMBER() OVER (
PARTITION BY E.SomeID
ORDER BY E.StartDate ASC)
FROM dbo.Example AS E
)
UPDATE This WITH (TABLOCKX)
SET EndDate =
ISNULL
(
DATEADD(DAY, -1, NextRow.StartDate),
CONVERT(date, '99991231', 112)
)
FROM Numbered AS This
LEFT JOIN Numbered AS NextRow WITH (TABLOCK)
ON NextRow.SomeID = This.SomeID
AND NextRow.rn = This.rn + 1
OPTION (MAXDOP 1, MERGE JOIN); Rencana pasca eksekusi adalah sebagai berikut:
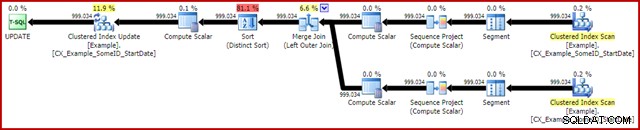
Kueri ini biasanya berjalan dalam 2950 md di laptop saya, yang lebih baik dibandingkan dengan 5700ms (dalam keadaan yang sama) terlihat untuk pernyataan pembaruan asli. Output IO statistik adalah:
Table 'Example'. Scan count 2, logical reads 3001808, physical reads 0 Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0
Ini menunjukkan dua pemindaian dimulai untuk tabel Contoh (satu untuk setiap iterator Pemindaian Indeks Clustered). Pembacaan logis sekali lagi merupakan agregat dari semua iterator yang mengakses tabel ini dalam rencana kueri. Seperti sebelumnya, kurangnya perincian membuat tidak mungkin untuk menentukan iterator mana (dari dua Pemindaian dan Pembaruan) yang bertanggung jawab atas 3 juta pembacaan.
Namun demikian, saya dapat memberi tahu Anda bahwa Pemindaian Indeks Clustered hanya menghitung beberapa ribu pembacaan logis masing-masing. Sebagian besar pembacaan logis disebabkan oleh Pembaruan Indeks Cluster yang menavigasi ke bawah pohon-b indeks untuk menemukan posisi pembaruan untuk setiap baris yang diprosesnya. Anda harus mengambil kata-kata saya untuk itu untuk saat ini; penjelasan lebih lanjut akan segera hadir.
Kerugian
Itu adalah akhir dari kabar baik untuk bentuk kueri ini. Performanya jauh lebih baik daripada aslinya, tetapi jauh kurang memuaskan karena sejumlah alasan lain. Masalah utama disebabkan oleh batasan pengoptimal, yang berarti tidak mengenali bahwa operasi penomoran baris menghasilkan nomor unik untuk setiap baris dalam partisi SomeID.
Fakta sederhana ini menyebabkan sejumlah konsekuensi yang tidak diinginkan. Untuk satu hal, gabungan gabungan dikonfigurasikan untuk dijalankan dalam mode gabungan banyak-ke-banyak. Ini adalah alasan untuk tabel kerja (tidak terpakai) dalam statistik IO (penggabungan banyak-ke-banyak memerlukan tabel kerja untuk penggandaan kunci gabung duplikat). Mengharapkan gabungan banyak-ke-banyak juga berarti perkiraan kardinalitas untuk keluaran gabungan sangat salah:
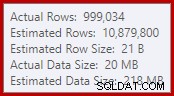
Sebagai akibatnya, Sort meminta terlalu banyak pemberian memori. Properti simpul akar menunjukkan Sortir akan menyukai memori 812,752 KB, meskipun hanya diberikan 379,440 KB karena pengaturan memori server maks yang dibatasi (2048 MB). Jenis tersebut sebenarnya menggunakan maksimum 58.968 KB saat runtime:
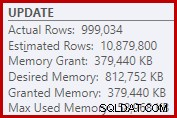
Pemberian memori yang berlebihan mencuri memori dari penggunaan produktif lainnya, dan dapat menyebabkan kueri menunggu hingga memori tersedia. Dalam banyak hal, pemberian memori yang berlebihan bisa menjadi masalah daripada meremehkan.
Batasan pengoptimal juga menjelaskan mengapa petunjuk penggabungan gabungan diperlukan pada kueri untuk kinerja terbaik. Tanpa petunjuk ini, pengoptimal salah menilai bahwa gabungan hash akan lebih murah daripada penggabungan banyak ke banyak. Paket hash join berjalan rata-rata dalam 3350 md.
Sebagai konsekuensi negatif terakhir, perhatikan bahwa Sortir dalam rencana adalah Sortir Berbeda. Sekarang ada beberapa alasan untuk Sortir itu (paling tidak karena dapat memberikan Perlindungan Halloween yang diperlukan) tetapi itu hanya Berbeda Urutkan karena pengoptimal melewatkan informasi keunikan. Secara keseluruhan, sulit untuk menyukai rencana eksekusi ini selain kinerjanya.
3. Perbarui menggunakan Fungsi Analitik LEAD
Karena artikel ini terutama menargetkan SQL Server 2012 dan yang lebih baru, kami dapat mengekspresikan kueri pembaruan secara alami menggunakan fungsi analitik LEAD. Di dunia yang ideal, kita bisa menggunakan sintaks yang sangat ringkas seperti:
-- Not allowed
UPDATE dbo.Example WITH (TABLOCKX)
SET EndDate = LEAD(StartDate) OVER (
PARTITION BY SomeID ORDER BY StartDate); Sayangnya, ini tidak sah. Ini menghasilkan pesan kesalahan 4108, "Fungsi berjendela hanya dapat muncul di klausa SELECT atau ORDER BY". Ini sedikit membuat frustrasi karena kami mengharapkan rencana eksekusi yang dapat menghindari self-join (dan pembaruan terkait Halloween Protection).
Kabar baiknya adalah kita masih bisa menghindari self-join menggunakan Common Table Expression atau tabel turunan. Sintaksnya sedikit lebih bertele-tele, tetapi idenya hampir sama:
WITH CED AS
(
SELECT
E.EndDate,
CalculatedEndDate =
DATEADD(DAY, -1,
LEAD(E.StartDate) OVER (
PARTITION BY E.SomeID
ORDER BY E.StartDate))
FROM dbo.Example AS E
)
UPDATE CED WITH (TABLOCKX)
SET CED.EndDate =
ISNULL
(
CED.CalculatedEndDate,
CONVERT(date, '99991231', 112)
)
OPTION (MAXDOP 1); Rencana pasca-eksekusi adalah:

Ini biasanya berjalan dalam waktu sekitar 3400 md di laptop saya, yang lebih lambat dari solusi nomor baris (2950ms) tetapi masih jauh lebih cepat dari aslinya (5700ms). Satu hal yang menonjol dari rencana eksekusi adalah tumpahan sortir (sekali lagi, informasi tumpahan tambahan berkat perbaikan di SP3):
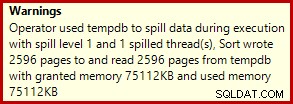
Ini adalah tumpahan yang cukup kecil, tetapi mungkin masih mempengaruhi kinerja sampai batas tertentu. Hal yang aneh tentang itu adalah bahwa perkiraan input ke Sort benar-benar tepat:
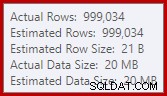
Untungnya, ada "perbaikan" untuk kondisi khusus ini di SQL Server 2012 SP2 CU8 (dan rilis lainnya – lihat artikel KB untuk detailnya). Menjalankan kueri dengan perbaikan dan tanda pelacakan yang diperlukan 7470 diaktifkan berarti Sort meminta memori yang cukup untuk memastikannya tidak akan tumpah ke disk jika perkiraan ukuran pengurutan input tidak terlampaui.
LEAD Perbarui Kueri Tanpa Tumpahan Urutkan
Untuk variasi, kueri yang diaktifkan-perbaikan di bawah ini menggunakan sintaks tabel turunan alih-alih CTE:
UPDATE CED WITH (TABLOCKX)
SET CED.EndDate =
ISNULL
(
CED.CalculatedEndDate, CONVERT(date, '99991231', 112)
)
FROM
(
SELECT
E.EndDate,
CalculatedEndDate =
DATEADD(DAY, -1,
LEAD(E.StartDate) OVER (
PARTITION BY E.SomeID
ORDER BY E.StartDate))
FROM dbo.Example AS E
) AS CED
OPTION (MAXDOP 1, QUERYTRACEON 7470); Rencana pasca-eksekusi yang baru adalah:

Menghilangkan tumpahan kecil meningkatkan kinerja dari 3400 md menjadi 3250 md . Output IO statistik adalah:
Table 'Example'. Scan count 1, logical reads 2999455, physical reads 0 Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0
Jika Anda membandingkan ini dengan pembacaan logis untuk kueri bernomor baris, Anda akan melihat bahwa pembacaan logis telah menurun dari 3.001.808 menjadi 2.999.455 – perbedaan 2.353 pembacaan. Ini sama persis dengan penghapusan satu Pemindaian Indeks Clustered (satu pembacaan per halaman).
Anda mungkin ingat saya menyebutkan bahwa sebagian besar pembacaan logis untuk kueri pembaruan ini terkait dengan Pembaruan Indeks Berkelompok, dan bahwa Pemindaian dikaitkan dengan "hanya beberapa ribu pembacaan". Sekarang kita dapat melihat ini sedikit lebih langsung dengan menjalankan kueri penghitungan baris sederhana terhadap tabel Contoh:
SET STATISTICS IO ON; SELECT COUNT(*) FROM dbo.Example WITH (TABLOCK); SET STATISTICS IO OFF;
Keluaran IO menunjukkan dengan tepat 2.353 perbedaan pembacaan logis antara nomor baris dan pembaruan prospek:
Table 'Example'. Scan count 1, logical reads 2353, physical reads 0
Peningkatan Lebih Lanjut?
Kueri prospek tetap-tumpahan (3250 md) masih sedikit lebih lambat daripada kueri bernomor baris ganda (2950 md), yang mungkin sedikit mengejutkan. Secara intuitif, orang mungkin mengharapkan satu pemindaian dan fungsi analitik (Window Spool dan Stream Aggregate) lebih cepat daripada dua pemindaian, dua set penomoran baris, dan gabungan.
Terlepas dari itu, hal yang melompat keluar dari rencana eksekusi permintaan utama adalah Sort. Itu juga hadir dalam kueri bernomor baris, di mana ia berkontribusi Perlindungan Halloween serta urutan pengurutan yang dioptimalkan untuk Pembaruan Indeks Cluster (yang memiliki set properti DMRLequestSort).
Masalahnya, Sortir ini sama sekali tidak diperlukan dalam rencana kueri prospek. Tidak diperlukan untuk Halloween Protection karena self-join telah hilang. Itu juga tidak diperlukan untuk urutan penyisipan yang dioptimalkan:baris sedang dibaca dalam urutan Kunci Tergugus, dan tidak ada rencana yang mengganggu urutan itu. Masalah sebenarnya dapat dilihat dengan melihat properti Sort:

Perhatikan bagian Order By disana. Sortir diurutkan berdasarkan SomeID dan StartDate (kunci indeks berkerumun) tetapi juga oleh [Uniq1002], yang merupakan uniquifier. Ini adalah konsekuensi dari tidak mendeklarasikan indeks berkerumun sebagai unik, meskipun kami mengambil langkah-langkah dalam kueri populasi data untuk memastikan bahwa kombinasi SomeID dan StartDate sebenarnya unik. (Ini disengaja, jadi saya bisa membicarakan ini.)
Meski begitu, ini adalah batasan. Baris dibaca dari Indeks Clustered secara berurutan, dan ada jaminan internal yang diperlukan sehingga pengoptimal dapat dengan aman menghindari Sortir ini. Ini hanyalah sebuah kesalahan bahwa pengoptimal tidak mengenali bahwa aliran masuk diurutkan berdasarkan uniquifier serta SomeID dan StartDate. Ia mengakui bahwa urutan (SomeID, StartDate) dapat dipertahankan, tetapi tidak (SomeID, StartDate, uniquifier). Sekali lagi, saya harap ini akan dibahas di versi mendatang.
Untuk mengatasinya, kita dapat melakukan apa yang seharusnya kita lakukan sejak awal:membangun indeks berkerumun sebagai unik:
CREATE UNIQUE CLUSTERED INDEX CX_Example_SomeID_StartDate ON dbo.Example (SomeID, StartDate) WITH (DROP_EXISTING = ON, MAXDOP = 1);
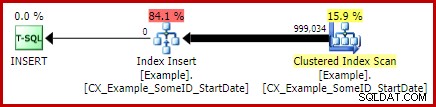
Saya akan membiarkannya sebagai latihan bagi pembaca untuk menunjukkan bahwa dua kueri (non-LEAD) pertama tidak mendapat manfaat dari perubahan pengindeksan ini (dihilangkan semata-mata karena alasan ruang – banyak yang harus dibahas).
Bentuk Akhir dari Permintaan Pembaruan Prospek
Dengan unik indeks berkerumun di tempat, kueri LEAD yang sama persis (CTE atau tabel turunan sesuka Anda) menghasilkan perkiraan (pra-eksekusi) rencana yang kami harapkan:

Hal ini tampaknya cukup optimal. Operasi baca dan tulis tunggal dengan minimal operator di antaranya. Tentu saja, tampaknya jauh lebih baik daripada versi sebelumnya dengan Sort yang tidak perlu, yang dijalankan dalam 3250 md setelah tumpahan yang dapat dihindari dihapus (dengan sedikit meningkatkan pemberian memori).
Rencana pasca-eksekusi (sebenarnya) hampir sama persis dengan rencana pra-eksekusi:

Semua perkiraan tepat benar, kecuali output dari Window Spool, yang turun sebanyak 2 baris. Informasi statistik IO sama persis seperti sebelum Sortir dihapus, seperti yang Anda harapkan:
Table 'Example'. Scan count 1, logical reads 2999455, physical reads 0 Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0
Untuk meringkas secara singkat, satu-satunya perbedaan nyata antara rencana baru ini dan rencana sebelumnya adalah Sortir (dengan perkiraan kontribusi biaya hampir 80%) telah dihapus.
Mungkin mengejutkan saat mengetahui bahwa kueri baru – tanpa Sortir – dijalankan dalam 5000 md . Ini jauh lebih buruk daripada 3250ms dengan Sortir, dan hampir selama kueri bergabung loop asli 5700ms. Solusi penomoran baris ganda masih jauh di depan pada 2950 md.
Penjelasan
Penjelasannya agak esoteris dan berkaitan dengan cara kait ditangani untuk kueri terbaru. Kami dapat menunjukkan efek ini dalam beberapa cara, tetapi yang paling sederhana mungkin adalah dengan melihat statistik wait and latch menggunakan DMV:
DBCC SQLPERF('sys.dm_os_wait_stats', CLEAR);
DBCC SQLPERF('sys.dm_os_latch_stats', CLEAR);
WITH CED AS
(
SELECT
E.EndDate,
CalculatedEndDate =
DATEADD(DAY, -1,
LEAD(E.StartDate) OVER (
PARTITION BY E.SomeID
ORDER BY E.StartDate))
FROM dbo.Example AS E
)
UPDATE CED WITH (TABLOCKX)
SET CED.EndDate =
ISNULL
(
CED.CalculatedEndDate,
CONVERT(date, '99991231', 112)
)
OPTION (MAXDOP 1);
SELECT * FROM sys.dm_os_latch_stats AS DOLS
WHERE DOLS.waiting_requests_count > 0
ORDER BY DOLS.latch_class;
SELECT * FROM sys.dm_os_wait_stats AS DOWS
WHERE DOWS.waiting_tasks_count > 0
ORDER BY DOWS.waiting_tasks_count DESC; Ketika indeks berkerumun tidak unik, dan ada Sortir dalam rencana, tidak ada penantian yang signifikan, hanya beberapa PAGEIOLATCH_UP menunggu dan SOS_SCHEDULER_YIELD yang diharapkan.
Ketika indeks berkerumun unik, dan Sort dihapus, menunggu adalah:
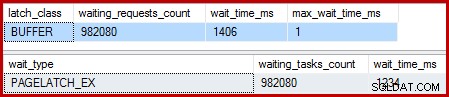
Ada 982.080 halaman eksklusif di sana, dengan waktu tunggu yang menjelaskan hampir semua waktu eksekusi ekstra. Untuk menekankan, itu hampir satu kait menunggu per baris diperbarui! Kita mungkin mengharapkan selot per baris berubah, tapi bukan selot menunggu , terutama jika kueri pengujian adalah satu-satunya aktivitas pada instance. Penantian gerendelnya pendek, tetapi jumlahnya sangat banyak.
Kancing Malas
Mengikuti eksekusi query dengan debugger dan analyzer terpasang, penjelasannya adalah sebagai berikut.
Pemindaian Indeks Clustered menggunakan latches malas – pengoptimalan yang berarti kait hanya dilepaskan ketika utas lain membutuhkan akses ke halaman. Biasanya, kait dilepaskan segera setelah membaca atau menulis. Kait malas mengoptimalkan kasus di mana pemindaian seluruh halaman akan memperoleh dan melepaskan kait halaman yang sama untuk setiap baris. Saat latch malas digunakan tanpa pertengkaran, hanya satu kait yang diambil untuk seluruh halaman.
Masalahnya adalah bahwa sifat rencana eksekusi pipa (tidak ada operator pemblokiran) berarti bahwa membaca tumpang tindih dengan menulis. Ketika Pembaruan Indeks Clustered mencoba untuk memperoleh kait EX untuk memodifikasi baris, itu hampir selalu akan menemukan bahwa halaman tersebut sudah terkunci SH (latch malas yang diambil oleh Pemindaian Indeks Clustered). Situasi ini menyebabkan penundaan.
Sebagai bagian dari persiapan untuk menunggu dan beralih ke item yang dapat dijalankan berikutnya pada penjadwal, kode berhati-hati untuk melepaskan kait yang malas. Melepaskan kait malas menandakan pelayan pertama yang memenuhi syarat, yang kebetulan adalah dirinya sendiri. Jadi, kami memiliki situasi aneh di mana sebuah utas memblokir dirinya sendiri, melepaskan kait malasnya, lalu memberi sinyal pada dirinya sendiri bahwa itu dapat dijalankan lagi. Utas mengambil lagi, dan melanjutkan, tetapi hanya setelah semua penangguhan dan sakelar yang sia-sia, sinyal dan lanjutkan pekerjaan telah dilakukan. Seperti yang saya katakan sebelumnya, antriannya pendek, tetapi ada banyak.
Sejauh yang saya tahu, urutan kejadian yang aneh ini dirancang dan untuk alasan internal yang baik. Meski begitu, tidak dapat disangkal bahwa itu memiliki pengaruh yang cukup dramatis pada kinerja di sini. Saya akan mengajukan beberapa pertanyaan tentang ini dan memperbarui artikel jika ada pernyataan publik yang harus dibuat. Sementara itu, self-latch waiting yang berlebihan mungkin perlu diwaspadai dengan kueri pembaruan berpipa, meskipun tidak jelas apa yang harus dilakukan dari sudut pandang penulis kueri.
Apakah ini berarti pendekatan penomoran baris ganda adalah yang terbaik yang dapat kami lakukan untuk kueri ini? Tidak cukup.
4. Perlindungan Halloween Manual
Opsi terakhir ini mungkin terdengar dan terlihat agak gila. Ide umumnya adalah menulis semua informasi yang diperlukan untuk membuat perubahan pada variabel tabel, kemudian melakukan pembaruan sebagai langkah terpisah.
Untuk mendapatkan deskripsi yang lebih baik, saya menyebutnya pendekatan "HP manual" karena secara konseptual mirip dengan menulis semua informasi perubahan ke Eager Table Spool (seperti yang terlihat pada kueri pertama) sebelum menjalankan Update dari Spool itu.
Bagaimanapun, kodenya adalah sebagai berikut:
DECLARE @U AS table
(
SomeID integer NOT NULL,
StartDate date NOT NULL,
NewEndDate date NULL,
PRIMARY KEY CLUSTERED (SomeID, StartDate)
);
INSERT @U
(SomeID, StartDate, NewEndDate)
SELECT
E.SomeID,
E.StartDate,
DATEADD(DAY, -1,
LEAD(E.StartDate) OVER (
PARTITION BY E.SomeID
ORDER BY E.StartDate))
FROM dbo.Example AS E WITH (TABLOCK)
OPTION (MAXDOP 1);
UPDATE E WITH (TABLOCKX)
SET E.EndDate =
ISNULL
(
U.NewEndDate, CONVERT(date, '99991231', 112)
)
FROM dbo.Example AS E
JOIN @U AS U
ON U.SomeID = E.SomeID
AND U.StartDate = E.StartDate
OPTION (MAXDOP 1, MERGE JOIN); Kode itu sengaja menggunakan variabel tabel untuk menghindari biaya statistik yang dibuat secara otomatis yang menggunakan tabel sementara akan dikenakan. Tidak apa-apa di sini karena saya tahu bentuk rencana yang saya inginkan, dan tidak bergantung pada perkiraan biaya atau informasi statistik.
Satu-satunya downside ke variabel tabel (tanpa tanda jejak) adalah bahwa pengoptimal biasanya akan memperkirakan satu baris dan memilih loop bersarang untuk pembaruan. Untuk mencegah hal ini, saya telah menggunakan petunjuk bergabung bergabung. Sekali lagi, hal ini didorong dengan mengetahui secara pasti bentuk rencana yang ingin dicapai.
Rencana pasca-eksekusi untuk penyisipan variabel tabel terlihat persis sama dengan kueri yang memiliki masalah dengan kait menunggu:

Keuntungan yang dimiliki rencana ini adalah tidak mengubah tabel yang sama dengan yang dibaca. Tidak diperlukan Perlindungan Halloween, dan tidak ada kemungkinan gangguan kait. Selain itu, ada pengoptimalan internal yang signifikan untuk objek tempdb (penguncian dan pencatatan) dan pengoptimalan pemuatan massal normal lainnya juga diterapkan. Ingat bahwa pengoptimalan massal hanya tersedia untuk sisipan, bukan pembaruan atau penghapusan.
Rencana pasca-eksekusi untuk pernyataan pembaruan adalah:
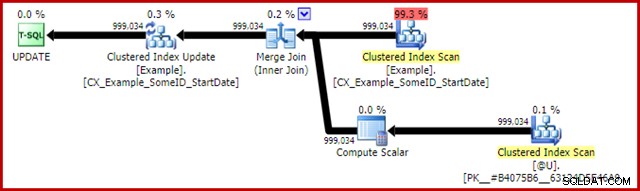
Gabung Gabung di sini adalah tipe satu-ke-banyak yang efisien. Lebih penting lagi, paket ini memenuhi syarat untuk optimasi khusus yang berarti Clustered Index Scan dan Clustered Index Update berbagi rowset yang sama. Konsekuensi penting adalah bahwa Pembaruan tidak lagi harus mencari baris yang akan diperbarui – baris tersebut sudah diposisikan dengan benar oleh pembacaan. Ini menghemat banyak sekali pembacaan logis (dan aktivitas lainnya) di Pembaruan.
Tidak ada dalam rencana eksekusi normal untuk menunjukkan di mana pengoptimalan Baris Bersama ini diterapkan, tetapi mengaktifkan tanda jejak tidak berdokumen 8666 memperlihatkan properti tambahan pada Pembaruan dan Pemindaian yang menunjukkan berbagi rowset sedang digunakan, dan langkah-langkah diambil untuk memastikan pembaruan aman dari Masalah Halloween.
Output IO statistik untuk dua kueri adalah sebagai berikut:
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0 Table 'Example'. Scan count 1, logical reads 2353, physical reads 0 (999034 row(s) affected) Table 'Example'. Scan count 1, logical reads 2353, physical reads 0 Table '#B9C034B8'. Scan count 1, logical reads 2353, physical reads 0
Kedua pembacaan tabel Contoh melibatkan pemindaian tunggal dan satu pembacaan logis per halaman (lihat kueri penghitungan baris sederhana sebelumnya). Tabel #B9C034B8 adalah nama objek tempdb internal yang mendukung variabel tabel. Total pembacaan logis untuk kedua kueri adalah 3 * 2353 =7.059. Meja kerja adalah penyimpanan internal dalam memori yang digunakan oleh Window Spool.
Waktu eksekusi umum untuk kueri ini adalah 2300 md . Terakhir, kami memiliki sesuatu yang mengalahkan kueri penomoran baris ganda (2950 md), yang kelihatannya tidak mungkin.
Pemikiran Terakhir
Mungkin ada cara yang lebih baik untuk menulis pembaruan ini yang berkinerja lebih baik daripada solusi "HP manual" di atas. Hasil kinerja bahkan mungkin berbeda pada perangkat keras dan konfigurasi SQL Server Anda, tetapi keduanya bukanlah poin utama dari artikel ini. Itu tidak berarti bahwa saya tidak tertarik untuk melihat kueri atau perbandingan kinerja yang lebih baik – saya tertarik.
Intinya adalah bahwa ada lebih banyak hal yang terjadi di dalam SQL Server daripada yang terungkap dalam rencana eksekusi. Semoga beberapa detail yang dibahas dalam artikel yang agak panjang ini dapat menarik atau bahkan bermanfaat bagi sebagian orang.
Adalah baik untuk memiliki ekspektasi kinerja, dan mengetahui bentuk dan properti denah apa yang umumnya bermanfaat. Pengalaman dan pengetahuan semacam itu akan membantu Anda dengan baik untuk 99% atau lebih dari pertanyaan yang pernah Anda minta untuk disetel. Namun, terkadang ada baiknya mencoba sesuatu yang sedikit aneh atau tidak biasa hanya untuk melihat apa yang terjadi, dan untuk memvalidasi ekspektasi tersebut.