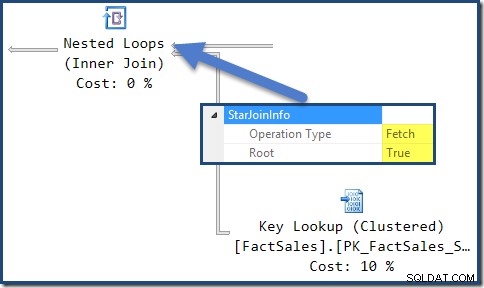
Dari waktu ke waktu, Anda mungkin memperhatikan bahwa satu atau lebih gabungan dalam rencana eksekusi diberi anotasi dengan StarJoinInfo struktur. Skema showplan resmi memiliki hal berikut untuk dikatakan tentang elemen rencana ini (klik untuk memperbesar):
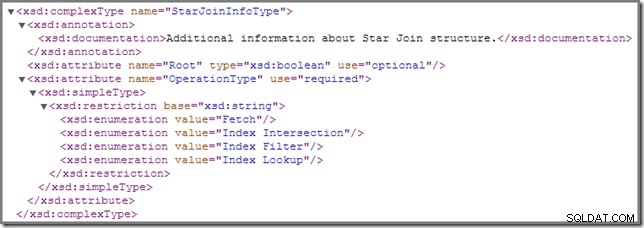
Dokumentasi sebaris ditampilkan di sana ("informasi tambahan tentang struktur Star Join ") tidak terlalu mencerahkan, meskipun detail lainnya cukup menarik – kita akan melihatnya secara detail.
Jika Anda berkonsultasi dengan mesin pencari favorit Anda untuk informasi lebih lanjut menggunakan istilah seperti "pengoptimalan bergabung bintang SQL Server", Anda mungkin akan melihat hasil yang menjelaskan filter bitmap yang dioptimalkan. Ini adalah fitur khusus Perusahaan terpisah yang diperkenalkan di SQL Server 2008, dan tidak terkait dengan StarJoinInfo struktur sama sekali.
Pengoptimalan untuk Kueri Bintang Selektif
Kehadiran StarJoinInfo menunjukkan bahwa SQL Server menerapkan salah satu dari serangkaian pengoptimalan yang ditargetkan pada kueri skema bintang selektif. Pengoptimalan ini tersedia dari SQL Server 2005, di semua edisi (bukan hanya Enterprise). Perhatikan bahwa selektif di sini mengacu pada jumlah baris yang diambil dari tabel fakta. Kombinasi predikat dimensi dalam kueri mungkin masih selektif meskipun predikat individualnya memenuhi syarat sejumlah besar baris.
Persimpangan Indeks Biasa
Pengoptimal kueri dapat mempertimbangkan untuk menggabungkan beberapa indeks nonclustered di mana indeks tunggal yang sesuai tidak ada, seperti yang ditunjukkan oleh kueri AdventureWorks berikut:
SELECT COUNT_BIG(*) FROM Sales.SalesOrderHeader WHERE SalesPersonID = 276 AND CustomerID = 29522;
Pengoptimal menentukan bahwa menggabungkan dua indeks nonclustered (satu di SalesPersonID dan yang lainnya di CustomerID ) adalah cara termurah untuk memenuhi kueri ini (tidak ada indeks di kedua kolom):
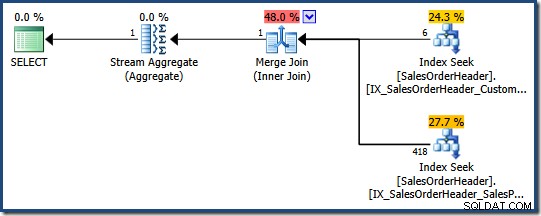
Setiap pencarian indeks mengembalikan kunci indeks berkerumun untuk baris yang melewati predikat. Gabung cocok dengan kunci yang dikembalikan untuk memastikan bahwa hanya baris yang cocok dengan keduanya predikat diteruskan.
Jika tabel adalah tumpukan, setiap pencarian akan mengembalikan pengidentifikasi baris tumpukan (RID) alih-alih kunci indeks berkerumun, tetapi strategi keseluruhannya sama:temukan pengidentifikasi baris untuk setiap predikat, lalu cocokkan.
Persimpangan Indeks Bergabung Bintang Manual
Ide yang sama dapat diperluas ke kueri yang memilih baris dari tabel fakta menggunakan predikat yang diterapkan ke tabel dimensi. Untuk melihat cara kerjanya, pertimbangkan kueri berikut (menggunakan database sampel Contoso BI) untuk menemukan jumlah total penjualan pemutar MP3 yang dijual di toko Contoso dengan tepat 50 karyawan:
SELECT
SUM(FS.SalesAmount)
FROM dbo.FactSales AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
WHERE
DS.EmployeeCount = 50
AND DP.ProductName LIKE N'%MP3%'; Sebagai perbandingan dengan upaya selanjutnya, kueri (sangat selektif) ini menghasilkan rencana kueri seperti berikut (klik untuk meluaskan):
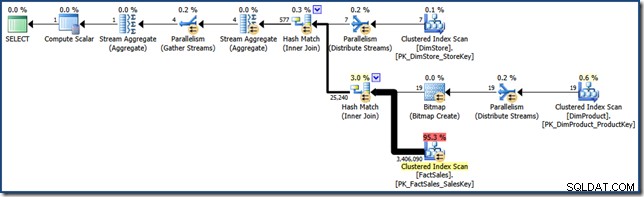
Rencana eksekusi tersebut memiliki perkiraan biaya lebih dari 15,6 unit . Ini menampilkan eksekusi paralel dengan pemindaian penuh tabel fakta (walaupun dengan filter bitmap yang diterapkan).
Tabel fakta dalam database sampel ini tidak menyertakan indeks nonclustered pada kunci asing tabel fakta secara default, jadi kita perlu menambahkan pasangan:
CREATE INDEX ix_ProductKey ON dbo.FactSales (ProductKey); CREATE INDEX ix_StoreKey ON dbo.FactSales (StoreKey);
Dengan adanya indeks-indeks ini, kita dapat mulai melihat bagaimana persimpangan indeks dapat digunakan untuk meningkatkan efisiensi. Langkah pertama adalah menemukan pengidentifikasi baris tabel fakta untuk setiap predikat terpisah. Kueri berikut menerapkan predikat dimensi tunggal, lalu bergabung kembali ke tabel fakta untuk menemukan pengidentifikasi baris (kunci indeks cluster tabel fakta):
-- Product dimension predicate
SELECT FS.SalesKey
FROM dbo.FactSales AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
WHERE DP.ProductName LIKE N'%MP3%';
-- Store dimension predicate
SELECT FS.SalesKey
FROM dbo.FactSales AS FS
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
WHERE DS.EmployeeCount = 50; Rencana kueri menunjukkan pemindaian tabel dimensi kecil, diikuti dengan pencarian menggunakan tabel fakta indeks nonclustered untuk menemukan pengidentifikasi baris (ingat indeks nonclustered selalu menyertakan tabel dasar clustering key atau heap RID):
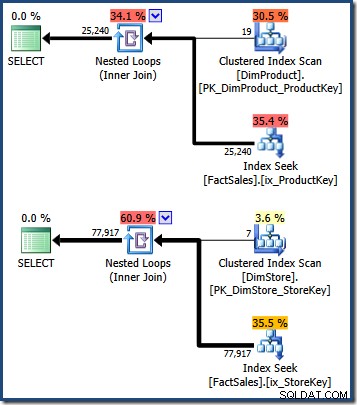
Perpotongan dari dua set kunci indeks berkerumun tabel fakta ini mengidentifikasi baris yang harus dikembalikan oleh kueri asli. Setelah kita memiliki pengidentifikasi baris ini, kita hanya perlu mencari Jumlah Penjualan di setiap baris tabel fakta, dan menghitung jumlahnya.
Kueri Persimpangan Indeks Manual
Menempatkan semua itu bersama-sama dalam kueri memberikan yang berikut:
SELECT SUM(FS.SalesAmount)
FROM
(
SELECT FS.SalesKey
FROM dbo.FactSales AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
WHERE DP.ProductName LIKE N'%MP3%'
INTERSECT
-- Store dimension predicate
SELECT FS.SalesKey
FROM dbo.FactSales AS FS
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
WHERE DS.EmployeeCount = 50
) AS Keys
JOIN dbo.FactSales AS FS WITH (FORCESEEK)
ON FS.SalesKey = Keys.SalesKey
OPTION (MAXDOP 1);
FORCESEEK petunjuk ada untuk memastikan kita mendapatkan pencarian titik ke tabel fakta. Tanpa ini, pengoptimal memilih untuk memindai tabel fakta, yang sebenarnya ingin kita hindari. MAXDOP 1 petunjuk hanya membantu menjaga rencana akhir ke ukuran yang cukup masuk akal untuk tujuan tampilan (klik untuk melihatnya dalam ukuran penuh):
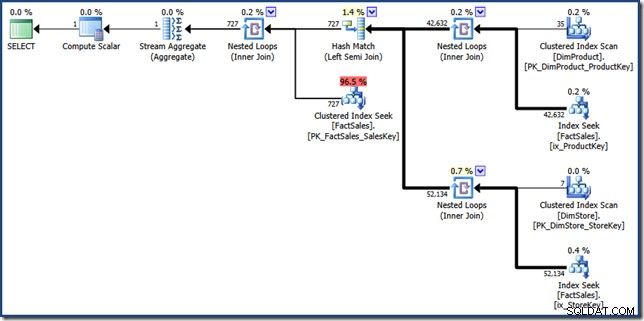
Bagian-bagian komponen rencana simpang indeks manual cukup mudah dikenali. Dua pencarian indeks nonclustered tabel fakta di sisi kanan menghasilkan dua set pengidentifikasi baris tabel fakta. Gabungan hash menemukan persimpangan dua set ini. Pencarian indeks berkerumun ke dalam tabel fakta menemukan Jumlah Penjualan untuk pengidentifikasi baris ini. Terakhir, Stream Aggregate menghitung jumlah totalnya.
Rencana kueri ini melakukan pencarian yang relatif sedikit ke dalam tabel fakta indeks nonclustered dan clustered. Jika kueri cukup selektif, ini mungkin merupakan strategi eksekusi yang lebih murah daripada memindai tabel fakta sepenuhnya. Basis data sampel Contoso BI relatif kecil, dengan hanya 3,4 juta baris dalam tabel fakta penjualan. Untuk tabel fakta yang lebih besar, perbedaan antara pemindaian penuh dan beberapa ratus pencarian bisa sangat signifikan. Sayangnya, penulisan ulang manual menimbulkan beberapa kesalahan kardinalitas serius, menghasilkan rencana dengan perkiraan biaya 46,5 unit .
Bintang Otomatis Bergabung dengan Persimpangan Indeks dengan Pencarian
Untungnya, kita tidak harus memutuskan apakah kueri yang kita tulis cukup selektif untuk membenarkan penulisan ulang manual ini. Pengoptimalan gabungan bintang untuk kueri selektif berarti pengoptimal kueri dapat menjelajahi opsi ini untuk kami, menggunakan sintaks kueri asli yang lebih ramah pengguna:
SELECT
SUM(FS.SalesAmount)
FROM dbo.FactSales AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
WHERE
DS.EmployeeCount = 50
AND DP.ProductName LIKE N'%MP3%'; Pengoptimal menghasilkan rencana eksekusi berikut dengan perkiraan biaya 1,64 unit (klik untuk memperbesar):
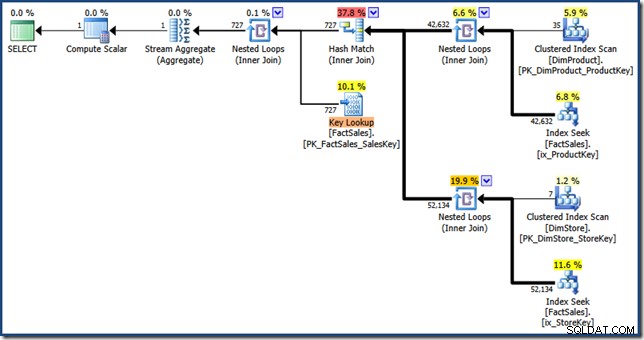
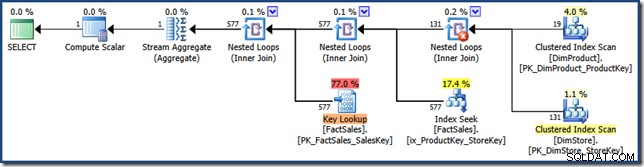
Perbedaan antara rencana ini dan versi manual adalah:persimpangan indeks adalah gabungan dalam, bukan semigabung; dan pencarian indeks berkerumun ditampilkan sebagai Pencarian Kunci alih-alih Pencarian Indeks Tergugus. Dengan risiko gagal, jika tabel fakta adalah tumpukan, Pencarian Kunci akan menjadi Pencarian RID.
Properti StarJoinInfo
Semua yang bergabung dalam paket ini memiliki StarJoinInfo struktur. Untuk melihatnya, klik pada join iterator dan lihat di jendela SSMS Properties. Klik panah di sebelah kiri StarJoinInfo elemen untuk memperluas simpul.
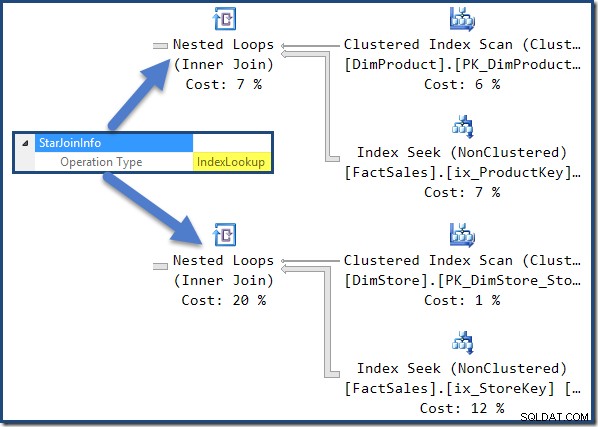
Tabel fakta nonclustered bergabung di sebelah kanan rencana adalah Pencarian Indeks yang dibuat oleh pengoptimal:
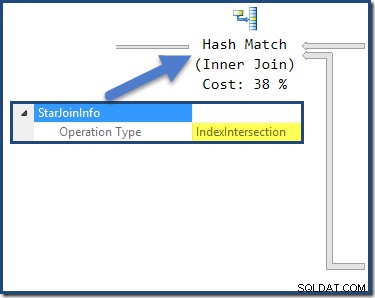
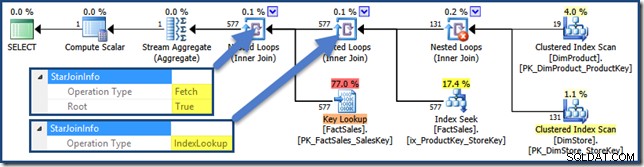
Gabungan hash memiliki StarJoinInfo struktur yang menunjukkan ia melakukan Persimpangan Indeks (sekali lagi, dibuat oleh pengoptimal):
StarJoinInfo untuk gabungan Nested Loops paling kiri menunjukkan itu dihasilkan untuk mengambil baris tabel fakta dengan pengidentifikasi baris. Itu adalah akar dari subpohon bergabung bintang yang dihasilkan pengoptimal:
Produk Cartesian dan Pencarian Indeks Multi-Kolom
Rencana persimpangan indeks yang dianggap sebagai bagian dari pengoptimalan gabungan bintang berguna untuk kueri tabel fakta selektif di mana indeks nonclustered kolom tunggal ada pada kunci asing tabel fakta (praktik desain umum).
Terkadang juga masuk akal untuk membuat indeks multi-kolom pada kunci asing tabel fakta, untuk kombinasi yang sering ditanyakan. Pengoptimalan kueri bintang selektif bawaan berisi penulisan ulang untuk skenario ini juga. Untuk melihat cara kerjanya, tambahkan indeks multi-kolom berikut ke tabel fakta:
CREATE INDEX ix_ProductKey_StoreKey ON dbo.FactSales (ProductKey, StoreKey);
Kompilasi kueri pengujian lagi:
SELECT
SUM(FS.SalesAmount)
FROM dbo.FactSales AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
WHERE
DS.EmployeeCount = 50
AND DP.ProductName LIKE N'%MP3%'; Paket kueri tidak lagi menampilkan perpotongan indeks (klik untuk memperbesar):
Strategi yang dipilih di sini adalah menerapkan setiap predikat ke tabel dimensi, mengambil produk kartesius dari hasil, dan menggunakannya untuk mencari kedua kunci indeks multi-kolom. Rencana kueri kemudian melakukan Pencarian Kunci ke dalam tabel fakta menggunakan pengidentifikasi baris persis seperti yang terlihat sebelumnya.
Rencana kueri sangat menarik karena menggabungkan tiga fitur yang sering dianggap sebagai Hal Buruk (pemindaian penuh, produk kartesius, dan pencarian kunci) dalam pengoptimalan kinerja . Ini adalah strategi yang valid ketika produk dari dua dimensi diharapkan sangat kecil.
Tidak ada StarJoinInfo untuk produk cartesian, tetapi gabungan yang lain memiliki informasi (klik untuk memperbesar):
Filter Indeks
Merujuk kembali ke skema showplan, ada satu lagi StarJoinInfo operasi yang perlu kita bahas:
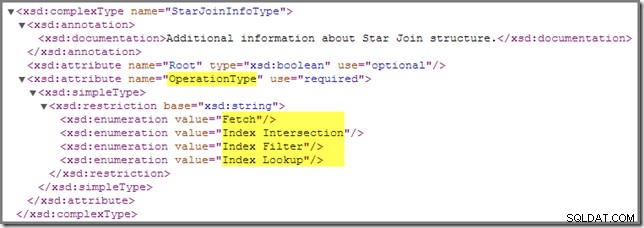
Index Filter nilai terlihat dengan gabungan yang dianggap cukup selektif untuk dilakukan sebelum tabel fakta diambil. Penggabungan yang tidak cukup selektif akan dilakukan setelah pengambilan, dan tidak akan memiliki StarJoinInfo struktur.
Untuk melihat Filter Indeks menggunakan kueri pengujian kami, kami perlu menambahkan tabel gabungan ketiga ke dalam campuran, menghapus indeks tabel fakta nonclustered yang dibuat sejauh ini, dan menambahkan yang baru:
CREATE INDEX ix_ProductKey_StoreKey_PromotionKey
ON dbo.FactSales (ProductKey, StoreKey, PromotionKey);
SELECT
SUM(FS.SalesAmount)
FROM dbo.FactSales AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
JOIN dbo.DimPromotion AS DPR
ON DPR.PromotionKey = FS.PromotionKey
WHERE
DS.EmployeeCount = 50
AND DP.ProductName LIKE N'%MP3%'
AND DPR.DiscountPercent <= 0.1; Rencana kueri sekarang (klik untuk memperbesar):
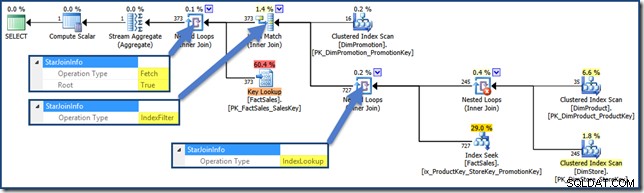
Rencana Kueri Persimpangan Indeks Heap
Untuk kelengkapan, berikut adalah skrip untuk membuat salinan tumpukan tabel fakta dengan dua indeks nonclustered yang diperlukan untuk mengaktifkan penulisan ulang pengoptimal persimpangan indeks:
SELECT * INTO FS FROM dbo.FactSales;
CREATE INDEX i1 ON dbo.FS (ProductKey);
CREATE INDEX i2 ON dbo.FS (StoreKey);
SELECT SUM(FS.SalesAmount)
FROM FS AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
WHERE DS.EmployeeCount <= 10
AND DP.ProductName LIKE N'%MP3%'; Rencana eksekusi untuk kueri ini memiliki fitur yang sama seperti sebelumnya, tetapi perpotongan indeks dilakukan menggunakan RID alih-alih kunci indeks kluster tabel fakta, dan pengambilan terakhir adalah Pencarian RID (klik untuk meluaskan):
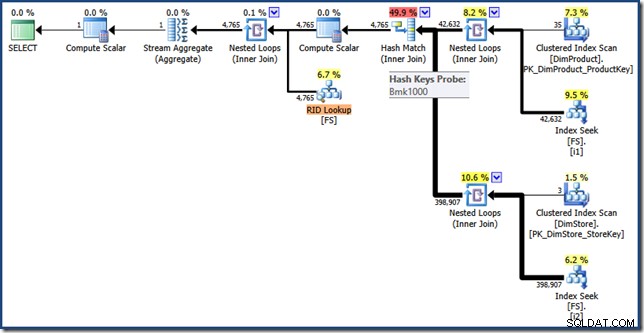
Pemikiran Akhir
Penulisan ulang pengoptimal yang ditampilkan di sini ditargetkan pada kueri yang mengembalikan jumlah baris yang relatif kecil dari besar tabel fakta. Penulisan ulang ini telah tersedia di semua edisi SQL Server sejak 2005.
Meskipun dimaksudkan untuk mempercepat kueri skema bintang (dan kepingan salju) selektif dalam pergudangan data, pengoptimal dapat menerapkan teknik ini di mana pun ia mendeteksi kumpulan tabel dan gabungan yang sesuai. Heuristik yang digunakan untuk mendeteksi kueri bintang cukup luas, sehingga Anda mungkin menemukan bentuk denah dengan StarJoinInfo struktur di hampir semua jenis database. Tabel apa pun dengan ukuran yang wajar (misalnya 100 halaman atau lebih) dengan referensi ke tabel yang lebih kecil (seperti dimensi) adalah kandidat potensial untuk pengoptimalan ini (perhatikan bahwa kunci asing eksplisit tidak diperlukan).
Bagi Anda yang menyukai hal-hal seperti itu, aturan pengoptimal yang bertanggung jawab untuk menghasilkan pola gabungan bintang selektif dari gabungan n-tabel logis disebut StarJoinToIdxStrategy (bintang bergabung dengan strategi indeks).



