Pentingnya Kegagalan
Failover adalah salah satu praktik database terpenting untuk tata kelola database. Ini berguna tidak hanya saat mengelola database besar dalam produksi, tetapi juga jika Anda ingin memastikan bahwa sistem Anda selalu tersedia kapan pun Anda mengaksesnya - terutama pada tingkat aplikasi.
Sebelum failover dapat terjadi, instance database Anda harus memenuhi persyaratan tertentu. Persyaratan ini, pada kenyataannya, sangat penting untuk ketersediaan tinggi. Salah satu persyaratan yang harus dipenuhi oleh instance database Anda adalah redundansi. Redundansi memungkinkan failover untuk melanjutkan, di mana redundansi diatur untuk memiliki kandidat failover yang dapat berupa node replika (sekunder) atau dari kumpulan replika yang bertindak sebagai node siaga atau siaga panas. Kandidat dipilih secara manual atau otomatis berdasarkan node yang paling canggih atau terbaru. Biasanya, Anda menginginkan replika hot-standby karena dapat menyelamatkan database Anda dari menarik indeks dari disk karena hot-standby sering mengisi indeks ke dalam kumpulan buffer database.
Failover adalah istilah yang digunakan untuk menggambarkan bahwa proses pemulihan telah terjadi. Sebelum proses pemulihan, ini terjadi ketika node database utama (atau master) gagal setelah crash, setelah bencana alam, setelah kegagalan perangkat keras, atau mungkin mengalami partisi jaringan; ini adalah kasus paling umum mengapa failover mungkin terjadi. Proses pemulihan biasanya berjalan secara otomatis dan kemudian mencari sekunder (replika) yang paling diinginkan dan terbaru seperti yang dinyatakan sebelumnya.
Failover lanjutan
Meskipun proses pemulihan selama failover otomatis, ada saat-saat tertentu ketika proses tidak perlu diotomatisasi, dan proses manual harus mengambil alih. Kompleksitas sering menjadi pertimbangan utama yang terkait dengan teknologi yang terdiri dari seluruh tumpukan database Anda - failover otomatis dapat dicampur dengan failover manual juga.
Dalam kebanyakan pertimbangan sehari-hari dengan mengelola database, sebagian besar kekhawatiran seputar failover otomatis sebenarnya tidak sepele. Seringkali berguna untuk menerapkan dan mengatur failover otomatis jika terjadi masalah. Meskipun kedengarannya menjanjikan karena mencakup kompleksitas, ada mekanisme failover lanjutan dan yang melibatkan peristiwa "pra" dan peristiwa "pasca" yang diikat sebagai kait dalam perangkat lunak atau teknologi failover.
Acara pra dan pasca ini muncul dengan pemeriksaan atau tindakan tertentu yang harus dilakukan sebelum akhirnya dapat melanjutkan dengan failover, dan setelah failover selesai, beberapa pembersihan untuk memastikan bahwa failover akhirnya berhasil satu. Untungnya, ada alat yang tersedia yang memungkinkan, tidak hanya Automatic Failover, tetapi juga fitur kemampuan untuk menerapkan kait skrip sebelum dan sesudah.
Di blog ini, kami akan menggunakan failover otomatis ClusterControl (CC) dan akan menjelaskan cara menggunakan kait skrip pra dan pasca dan cluster mana yang menerapkannya.
Kegagalan Replikasi ClusterControl
Mekanisme failover ClusterControl dapat diterapkan secara efisien melalui replikasi asinkron yang berlaku untuk varian MySQL (MySQL/Percona Server/MariaDB). Ini juga berlaku untuk cluster PostgreSQL/TimescaleDB - ClusterControl mendukung replikasi streaming. Cluster MongoDB dan Galera memiliki mekanisme sendiri untuk failover otomatis yang dibangun ke dalam teknologi databasenya sendiri. Baca selengkapnya tentang bagaimana ClusterControl melakukan pemulihan dan failover database otomatis.
Kegagalan ClusterControl tidak berfungsi kecuali pemulihan Node dan Cluster (Pemulihan Otomatis diaktifkan). Itu berarti tombol ini harus berwarna hijau.

Dokumentasi menyatakan bahwa opsi konfigurasi ini dapat digunakan juga untuk mengaktifkan / nonaktifkan yang berikut ini:
| enable_cluster_autorecovery= |
|
| enable_node_autorecovery= |
|
$ systemctl restart cmon
Untuk blog ini, kami terutama berfokus pada cara menggunakan kait skrip pra/pasca yang pada dasarnya merupakan keuntungan besar untuk kegagalan replikasi lanjutan.
Dukungan skrip pra/pasca replikasi failover cluster
Seperti yang disebutkan sebelumnya, varian MySQL yang menggunakan replikasi asinkron (termasuk semi-sinkron) dan replikasi streaming untuk PostgreSQL/TimescaleDB mendukung mekanisme ini. ClusterControl memiliki opsi konfigurasi berikut yang dapat digunakan untuk kait skrip pra dan pasca. Pada dasarnya, opsi konfigurasi ini dapat diatur melalui file konfigurasinya atau dapat diatur melalui UI web (kita akan membahasnya nanti).
Dokumentasi kami menyatakan bahwa ini adalah opsi konfigurasi berikut yang dapat mengubah mekanisme failover dengan menggunakan kait skrip pra/pasca:
| replication_pre_failover_script= |
|
| replication_post_failover_script= |
|
| replication_post_unsuccessful_failover_script= |
|
Secara teknis, setelah Anda menyetel opsi konfigurasi berikut di file konfigurasi /etc/cmon.d/cmon_
$ systemctl restart cmonAtau, Anda juga dapat mengatur opsi konfigurasi dengan membuka
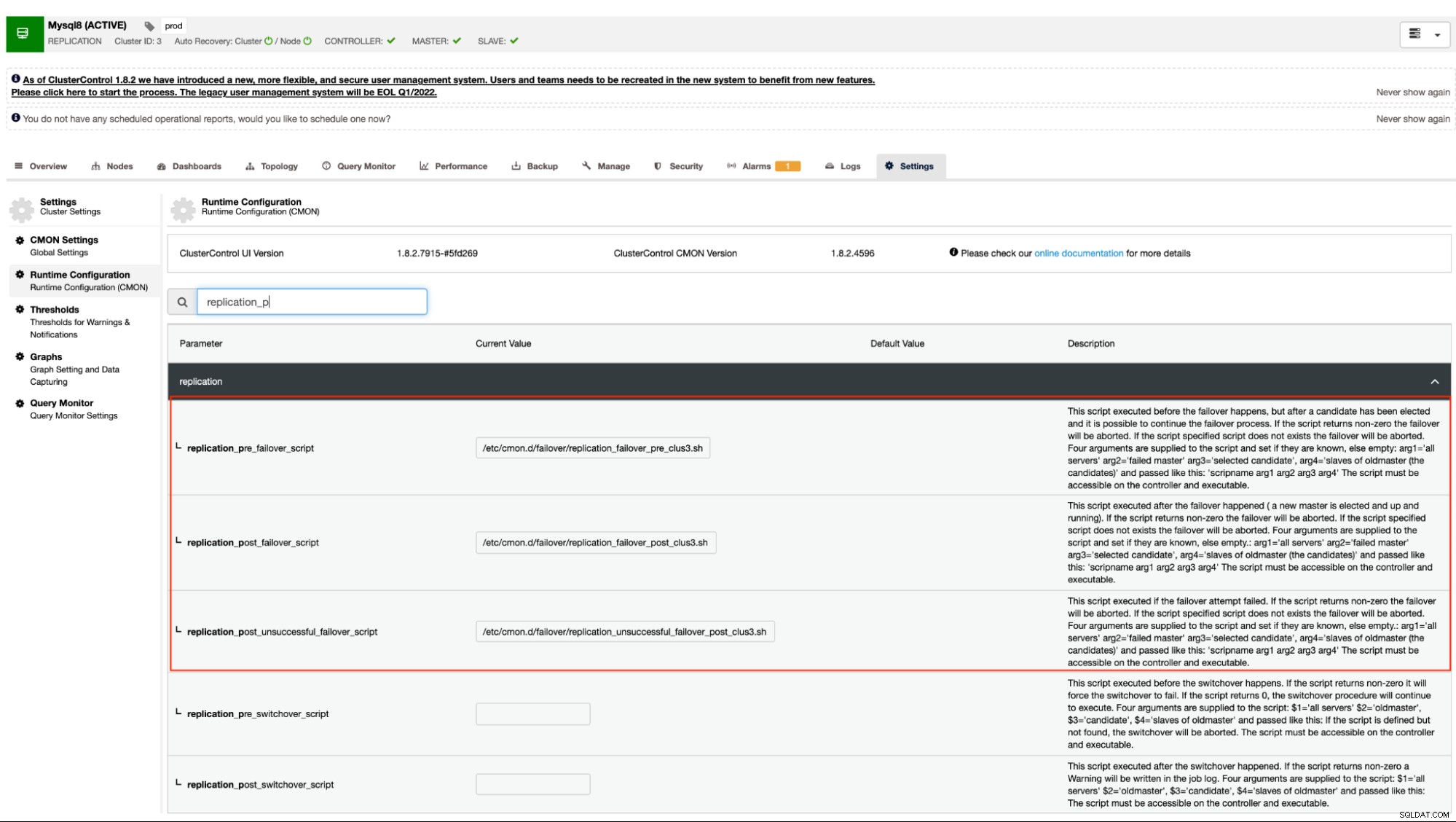
Pendekatan ini masih memerlukan restart ke layanan cmon sebelum dapat mencerminkan perubahan yang dibuat untuk opsi konfigurasi ini untuk kait skrip pra/pasca.
Contoh kait skrip sebelum/sesudah
Idealnya, kait skrip pra/pasca didedikasikan saat Anda memerlukan failover lanjutan yang ClusterControl tidak dapat mengelola kerumitan penyiapan basis data Anda. Misalnya, jika Anda menjalankan pusat data yang berbeda dengan keamanan yang diperketat dan Anda ingin menentukan apakah peringatan jaringan yang tidak dapat dijangkau bukanlah alarm positif palsu. Itu harus memeriksa apakah primer dan budak dapat menjangkau satu sama lain dan sebaliknya dan juga dapat menjangkau dari node database menuju ke host ClusterControl.
Mari kita lakukan itu dalam contoh kita dan tunjukkan bagaimana Anda bisa mendapatkan keuntungan darinya.
Detail server dan skrip
Dalam contoh ini, saya menggunakan kluster Replikasi MariaDB hanya dengan primer dan replika. Dikelola oleh ClusterControl untuk mengelola failover.
ClusterControl =192.168.40.110
utama (debnode5) =192.168.30.50
replika (debnode9) =192.168.30.90
Di node utama, buat skrip seperti yang dinyatakan di bawah ini,
example@sqldat.com:~# cat /opt/pre_failover.sh
#!/bin/bash
date -u +%s | ssh -i /home/vagrant/.ssh/id_rsa example@sqldat.com -T "cat >> /tmp/debnode5.tmp"Pastikan /opt/pre_failover.sh dapat dieksekusi, mis.
$ chmod +x /opt/pre_failover.shKemudian gunakan skrip ini untuk terlibat melalui cron. Dalam contoh ini, saya membuat file /etc/cron.d/ccfailover dan memiliki konten sebagai berikut:
example@sqldat.com:~# cat /etc/cron.d/ccfailover
#!/bin/bash
* * * * * vagrant /opt/pre_failover.shDi replika Anda, cukup gunakan langkah-langkah berikut yang kami lakukan untuk yang utama kecuali mengubah nama host. Lihat yang berikut ini dari apa yang saya miliki di bawah ini di replika saya:
example@sqldat.com:~# tail -n+1 /etc/cron.d/ccfailover /opt/pre_failover.sh
==> /etc/cron.d/ccfailover <==
#!/bin/bash
* * * * * vagrant /opt/pre_failover.sh
==> /opt/pre_failover.sh <==
#!/bin/bash
date -u +%s | ssh -i /home/vagrant/.ssh/id_rsa example@sqldat.com -T "cat > /tmp/debnode9.tmp"dan pastikan bahwa skrip yang dipanggil di cron kami dapat dieksekusi,
example@sqldat.com:~# ls -alth /opt/pre_failover.sh
-rwxr-xr-x 1 root root 104 Jun 14 05:09 /opt/pre_failover.shskrip pra/posting ClusterControl
Dalam demonstrasi ini, cluster_id saya adalah 3. Seperti yang dinyatakan sebelumnya dalam dokumentasi kami, skrip ini harus berada di host pengontrol CC kami. Jadi di /etc/cmon.d/cmon_3.cnf saya, saya memiliki yang berikut:
[example@sqldat.com cmon.d]# tail -n3 /etc/cmon.d/cmon_3.cnf
replication_pre_failover_script = /etc/cmon.d/failover/replication_failover_pre_clus3.sh
replication_post_failover_script = /etc/cmon.d/failover/replication_failover_post_clus3.sh
replication_post_unsuccessful_failover_script = /etc/cmon.d/failover/replication_unsuccessful_failover_post_clus3.shSedangkan, skrip failover "pra" berikut menentukan apakah kedua node dapat mencapai host pengontrol CC. Lihat berikut ini:
[example@sqldat.com cmon.d]# tail -n+1 /etc/cmon.d/failover/replication_failover_pre_clus3.sh
#!/bin/bash
arg1=$1
debnode5_tstamp=$(tail /tmp/debnode5.tmp)
debnode9_tstamp=$(tail /tmp/debnode9.tmp)
cc_tstamp=$(date -u +%s)
diff_debnode5=$(expr $cc_tstamp - $debnode5_tstamp)
diff_debnode9=$(expr $cc_tstamp - $debnode5_tstamp)
if [[ "$diff_debnode5" -le 60 && "$diff_debnode9" -le 60 ]]; then
echo "failover cannot proceed. It's just a false alarm. Checkout the firewall in your CC host";
exit 1;
elif [[ "$diff_debnode5" -gt 60 || "$diff_debnode9" -gt 60 ]]; then
echo "Either both nodes ($arg1) or one of them were not able to connect the CC host. One can be unreachable. Failover proceed!";
exit 0;
else
echo "false alarm. Failover discarded!"
exit 1;
fi
Whereas my post scripts just simply echoes and redirects the output to a file, just for the test.
[example@sqldat.com failover]# tail -n+1 replication_*_post*3.sh
==> replication_failover_post_clus3.sh <==
#!/bin/bash
echo "post failover script on cluster 3 with args: example@sqldat.com" > /tmp/post_failover_script_cid3.txt
==> replication_unsuccessful_failover_post_clus3.sh <==
#!/bin/bash
echo "post unsuccessful failover script on cluster 3 with args: example@sqldat.com" > /tmp/post_unsuccessful_failover_script_cid3.txt
Demokan failover
Sekarang, mari kita coba simulasikan pemadaman jaringan pada node utama dan lihat bagaimana reaksinya. Di node utama saya, saya menghapus antarmuka jaringan yang digunakan untuk berkomunikasi dengan replika dan pengontrol CC.
example@sqldat.com:~# ip link set enp0s8 downSelama upaya failover pertama, CC dapat menjalankan pra-skrip saya yang terletak di /etc/cmon.d/failover/replication_failover_pre_clus3.sh. Lihat di bawah cara kerjanya:
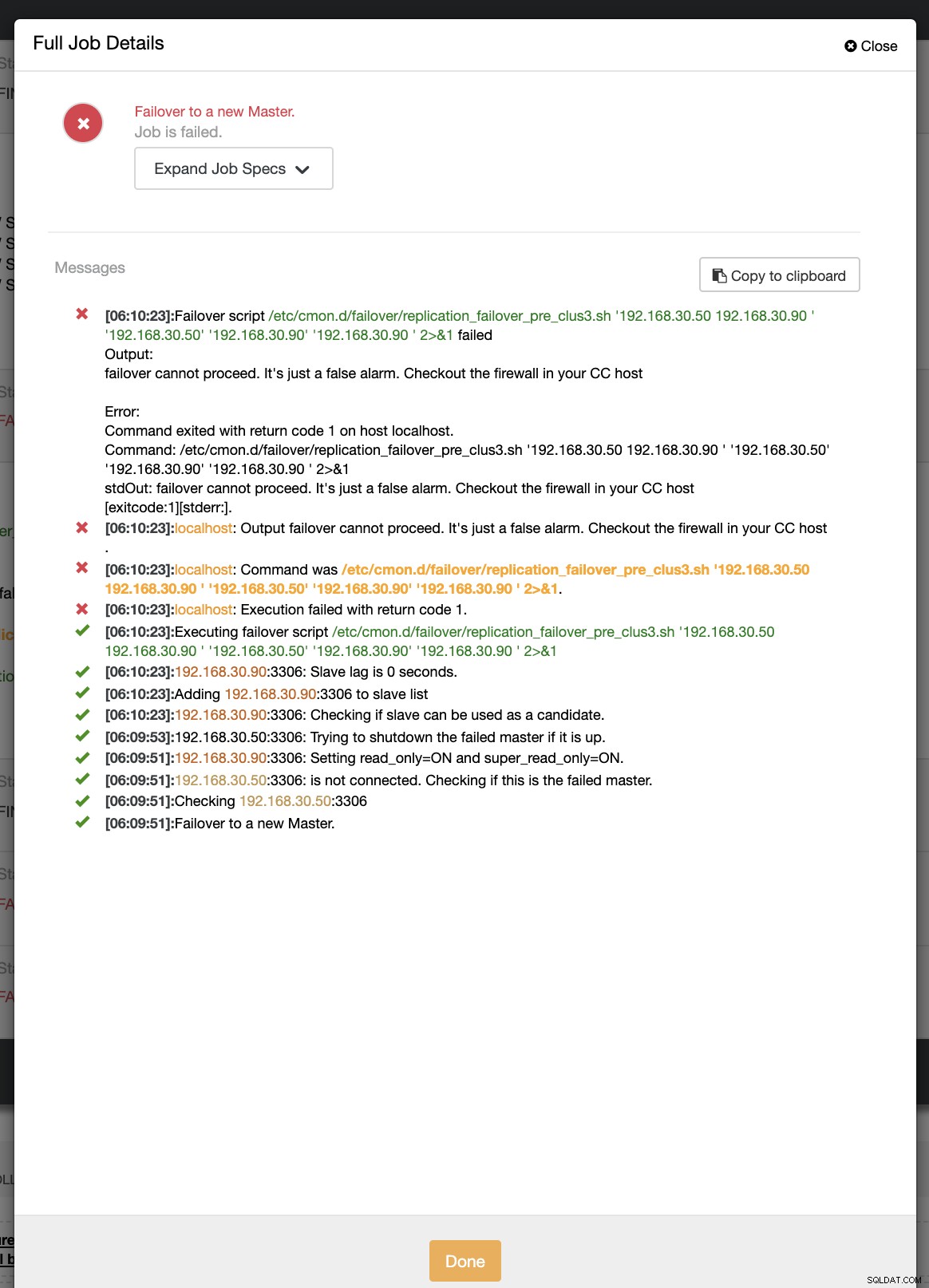
Jelas gagal karena stempel waktu yang telah dicatat belum lebih dari satu menit atau baru beberapa detik yang lalu primer masih dapat terhubung dengan pengontrol CC. Jelas, itu bukan pendekatan yang sempurna ketika Anda berhadapan dengan skenario nyata. Namun, ClusterControl dapat menjalankan dan menjalankan skrip dengan sempurna seperti yang diharapkan. Nah, bagaimana jika memang mencapai lebih dari satu menit (yaitu> 60 detik)?
Dalam upaya failover kedua kami, karena stempel waktu mencapai lebih dari 60 detik, maka itu dianggap benar-benar positif, dan itu berarti kami harus melakukan failover sebagaimana dimaksud. CC telah mampu mengeksekusinya dengan sempurna dan bahkan mengeksekusi skrip postingan sebagaimana dimaksud. Ini bisa dilihat di log pekerjaan. Lihat tangkapan layar di bawah ini:
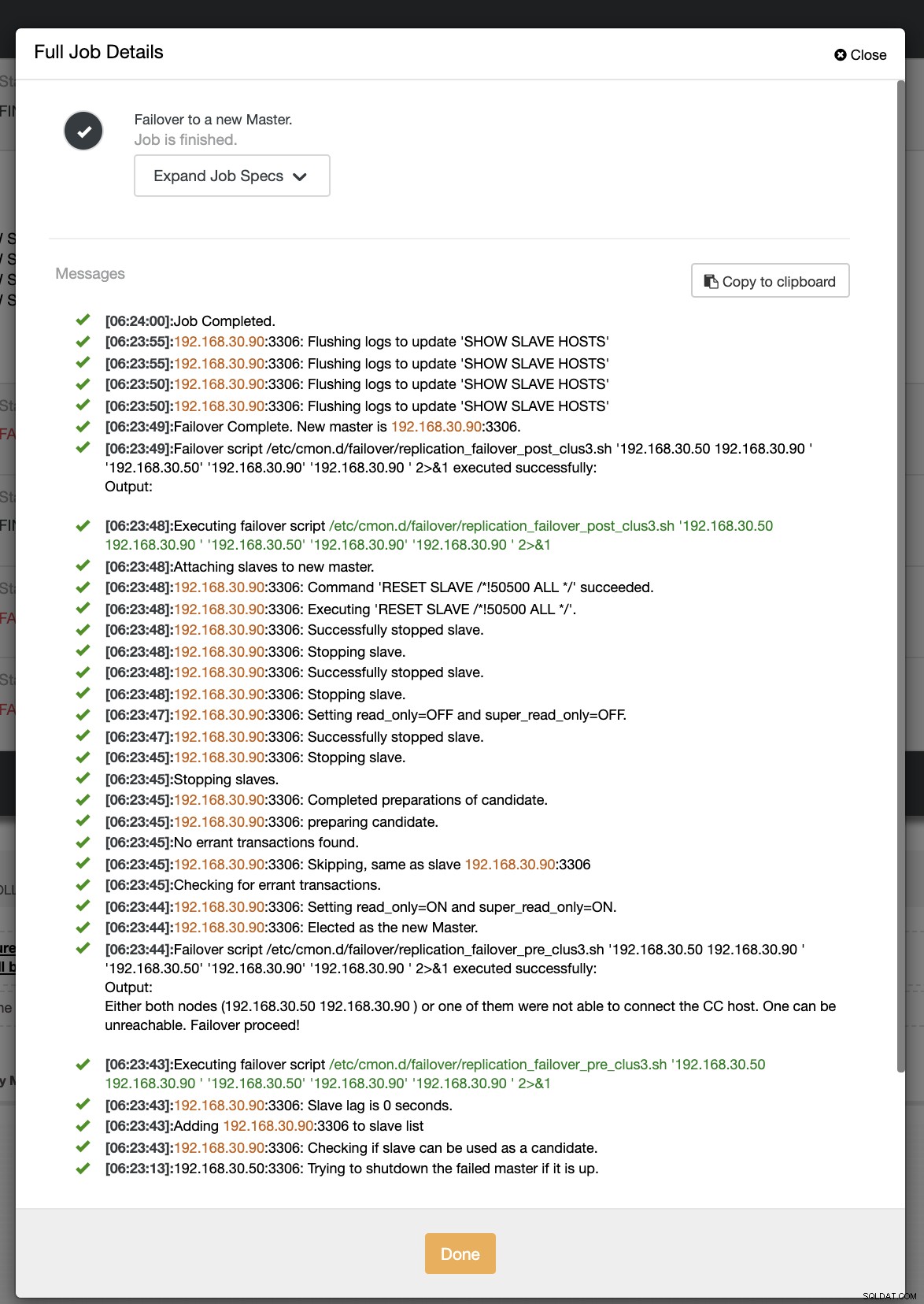
Memverifikasi apakah skrip posting saya dijalankan, ia dapat membuat log file di direktori CC /tmp seperti yang diharapkan,
[example@sqldat.com tmp]# cat /tmp/post_failover_script_cid3.txtskrip failover posting pada cluster 3 dengan argumen:192.168.30.50 192.168.30.90 192.168.30.50 192.168.30.90 192.168.30.90
Sekarang, topologi saya telah diubah dan failover berhasil!
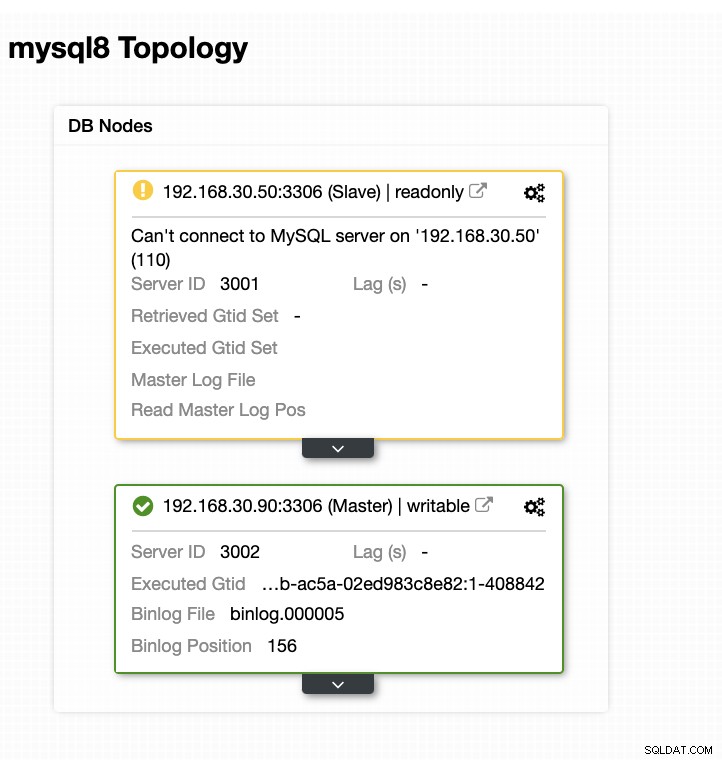
Kesimpulan
Untuk pengaturan basis data rumit apa pun yang mungkin Anda miliki, ketika failover lanjutan diperlukan, skrip pra/pasca dapat sangat membantu untuk membuat segala sesuatunya dapat dicapai. Karena ClusterControl mendukung fitur-fitur ini, kami telah menunjukkan betapa kuat dan bermanfaatnya fitur ini. Bahkan dengan keterbatasannya, selalu ada cara untuk membuat sesuatu dapat dicapai dan berguna terutama di lingkungan produksi.