Salah satu cara paling populer dalam mencapai ketersediaan tinggi untuk MySQL adalah replikasi. Replikasi telah ada selama bertahun-tahun, dan menjadi jauh lebih stabil dengan diperkenalkannya GTID. Tetapi bahkan dengan peningkatan ini, proses replikasi dapat terhenti karena berbagai alasan - misalnya, ketika master dan slave tidak sinkron karena penulisan dikirim langsung ke slave. Bagaimana Anda memecahkan masalah replikasi, dan bagaimana Anda memperbaikinya?
Dalam posting blog ini, kita akan membahas beberapa masalah umum dengan replikasi dan cara memperbaikinya dengan ClusterControl. Mari kita mulai dengan yang pertama.
Replikasi Dihentikan Dengan Beberapa Kesalahan
Sebagian besar DBA MySQL biasanya akan melihat masalah seperti ini setidaknya sekali dalam karier mereka. Karena berbagai alasan, seorang budak bisa rusak atau mungkin berhenti menyinkronkan dengan master. Ketika ini terjadi, hal pertama yang harus dilakukan untuk memulai pemecahan masalah adalah memeriksa log kesalahan untuk pesan. Sebagian besar waktu, pesan kesalahan mudah dilacak di log kesalahan atau dengan menjalankan kueri SHOW SLAVE STATUS.
Mari kita lihat contoh berikut dari SHOW STATUS SLAVE:
********** 0. row **********
Slave_IO_State:
Master_Host: 10.2.9.71
Master_User: cmon_replication
Master_Port: 3306
Connect_Retry: 10
Master_Log_File: binlog.000111
Read_Master_Log_Pos: 255477362
Relay_Log_File: relay-bin.000001
Relay_Log_Pos: 4
Relay_Master_Log_File: binlog.000111
Slave_IO_Running: No
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 255477362
Relay_Log_Space: 256
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master:
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 1236
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'Could not find GTID state requested by slave in any binlog files. Probably the slave state is too old and required binlog files have been purged.'
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1000
Master_SSL_Crl:
Master_SSL_Crlpath:
Using_Gtid: Slave_Pos
Gtid_IO_Pos: 1000-1000-2268440
Replicate_Do_Domain_Ids:
Replicate_Ignore_Domain_Ids:
Parallel_Mode: optimistic
SQL_Delay: 0
SQL_Remaining_Delay:
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates
Slave_DDL_Groups: 0
Slave_Non_Transactional_Groups: 0
Slave_Transactional_Groups: 0Kita dapat dengan jelas melihat kesalahan yang terkait dengan Mendapat kesalahan fatal 1236 dari master saat membaca data dari log biner:'Tidak dapat menemukan status GTID yang diminta oleh budak di file binlog mana pun. Mungkin status budak terlalu tua dan file binlog yang diperlukan telah dibersihkan.'. Dengan kata lain, kesalahan yang memberitahu kita pada dasarnya adalah bahwa ada inkonsistensi dalam data dan file log biner yang diperlukan telah dihapus.
Ini adalah salah satu contoh bagus di mana proses replikasi berhenti bekerja. Selain SHOW SLAVE STATUS, Anda juga dapat melacak status di tab “Overview” dari cluster di ClusterControl. Jadi bagaimana cara memperbaikinya dengan ClusterControl? Anda memiliki dua opsi untuk dicoba:
-
Anda dapat mencoba memulai kembali slave dari “Tindakan Node”
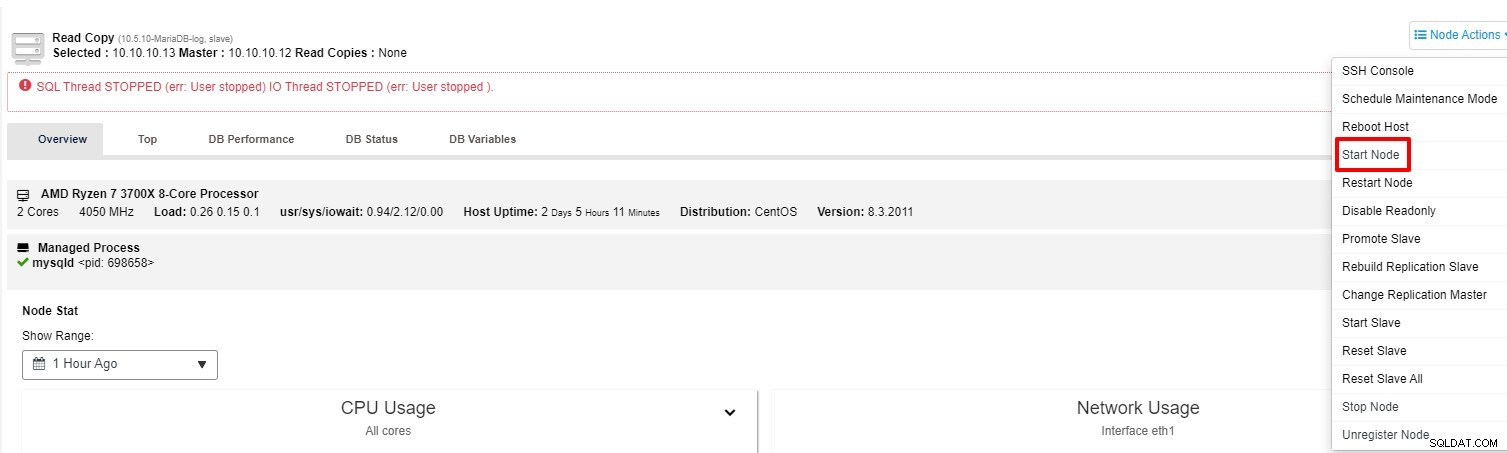
-
Jika slave masih tidak berfungsi, Anda dapat menjalankan tugas “Rebuild Replication Slave” dari “Tindakan Node”
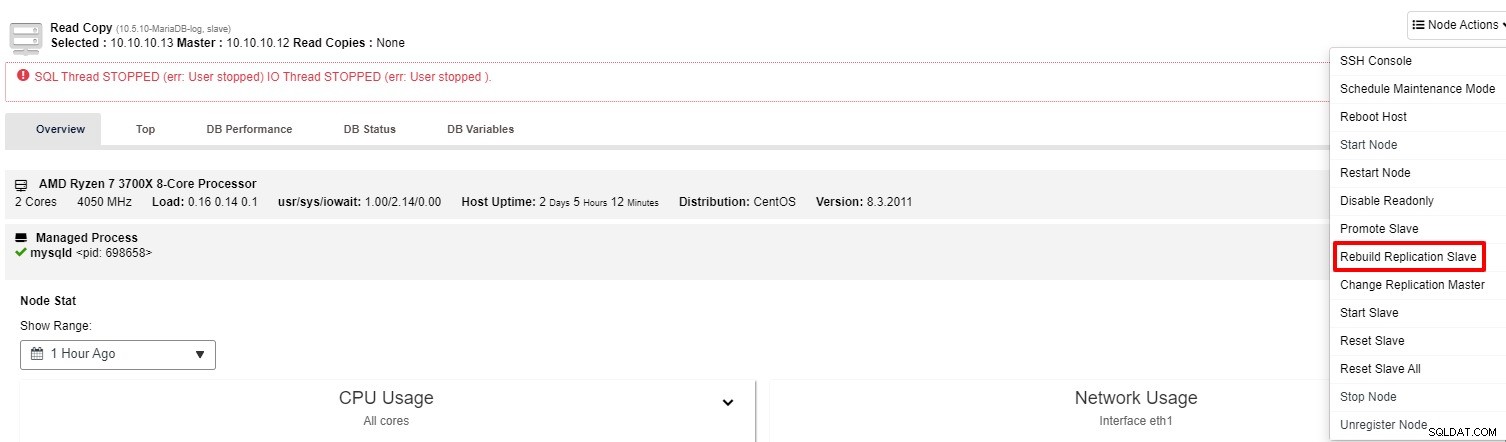
Sebagian besar waktu, opsi kedua akan menyelesaikan masalah. ClusterControl akan mengambil cadangan master, dan membangun kembali budak yang rusak dengan memulihkan data. Setelah data dipulihkan, budak terhubung ke master sehingga dapat mengejar ketinggalan.
Ada juga beberapa cara manual untuk membangun kembali slave seperti yang tercantum di bawah ini, Anda juga dapat merujuk ke link ini untuk detail selengkapnya:
-
Menggunakan Mysqldump untuk Membangun Kembali MySQL Slave yang Tidak Konsisten
-
Menggunakan Mydumper untuk Membangun Kembali MySQL Slave yang Tidak Konsisten
-
Menggunakan Snapshot untuk Membangun Kembali MySQL Slave yang Tidak Konsisten
-
Menggunakan Xtrabackup atau Mariabackup untuk Membangun Kembali MySQL Slave yang Tidak Konsisten
Promosikan Seorang Budak Menjadi Seorang Master
Seiring waktu, OS atau database perlu ditambal atau ditingkatkan untuk menjaga stabilitas dan keamanan. Salah satu praktik terbaik untuk meminimalkan waktu henti terutama untuk peningkatan besar adalah mempromosikan salah satu budak untuk dikuasai setelah pemutakhiran berhasil dilakukan pada node tertentu.
Dengan melakukan ini, Anda dapat mengarahkan aplikasi Anda ke master baru dan replikasi master-slave akan terus bekerja. Sementara itu, Anda juga dapat melanjutkan dengan peningkatan pada master lama dengan tenang. Dengan ClusterControl, ini dapat dijalankan dengan beberapa klik hanya dengan asumsi replikasi dikonfigurasi sebagai berbasis ID Transaksi Global atau singkatnya berbasis GTID. Untuk menghindari kehilangan data, ada baiknya menghentikan kueri aplikasi apa pun jika master lama beroperasi dengan benar. Ini bukan satu-satunya situasi di mana Anda dapat mempromosikan budak. Jika master node sedang down, Anda juga dapat melakukan tindakan ini.
Tanpa ClusterControl, ada beberapa langkah untuk mempromosikan slave. Setiap langkah memerlukan beberapa kueri untuk dijalankan juga:
-
Hapus master secara manual
-
Pilih budak paling mahir untuk menjadi master dan persiapkan
-
Hubungkan kembali slave lain ke master baru
-
Mengubah master lama menjadi budak
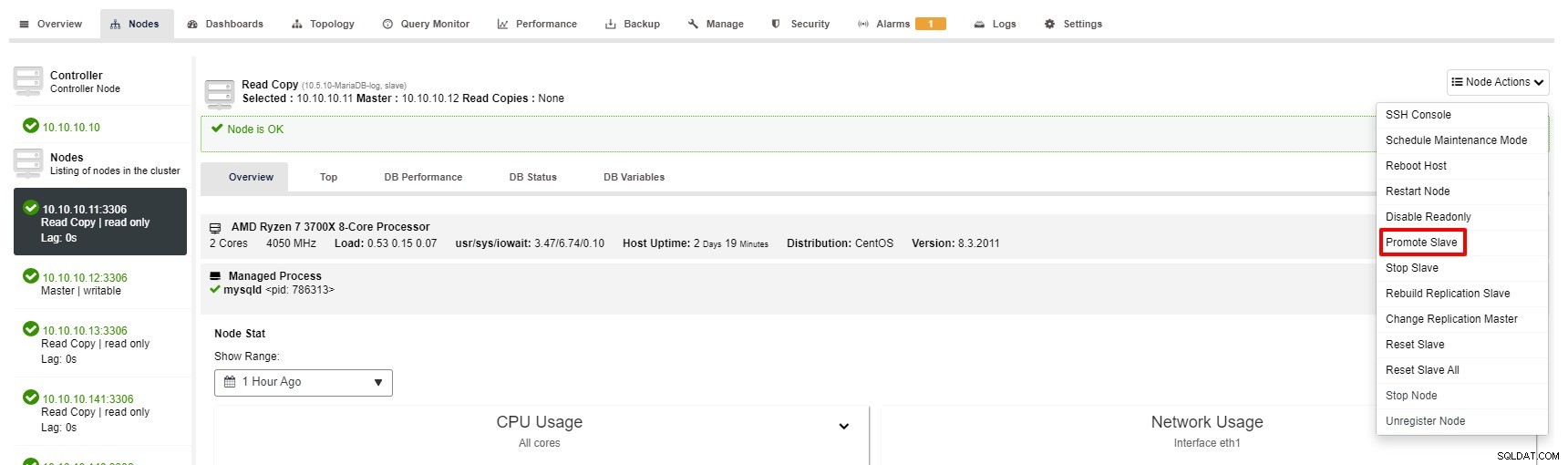
Namun demikian, langkah-langkah untuk Mempromosikan Slave dengan ClusterControl hanya dengan beberapa klik:Cluster> Nodes> pilih slave node> Promote Slave seperti screenshot di bawah ini:
Master Menjadi Tidak Tersedia
Bayangkan Anda memiliki transaksi besar untuk dijalankan tetapi database sedang down. Tidak peduli seberapa hati-hati Anda, ini mungkin situasi paling serius atau kritis untuk pengaturan replikasi. Ketika ini terjadi, database Anda tidak dapat menerima satu penulisan pun, yang buruk. Selain itu, aplikasi Anda tentu saja tidak akan berfungsi dengan baik.
Ada beberapa alasan atau penyebab yang menyebabkan masalah ini. Beberapa contohnya adalah kegagalan perangkat keras, kerusakan OS, kerusakan basis data, dan sebagainya. Sebagai DBA, Anda harus bertindak cepat untuk memulihkan database master.
Berkat fungsi cluster “Pemulihan Otomatis” yang tersedia di ClusterControl, proses failover dapat diotomatisasi. Itu dapat diaktifkan atau dinonaktifkan dengan satu klik. Seperti namanya, apa yang akan dilakukan adalah memunculkan seluruh topologi cluster bila diperlukan. Misalnya, replikasi master-slave harus memiliki setidaknya satu master yang hidup pada waktu tertentu, terlepas dari jumlah slave yang tersedia. Ketika master tidak tersedia, maka secara otomatis akan mempromosikan salah satu budak.
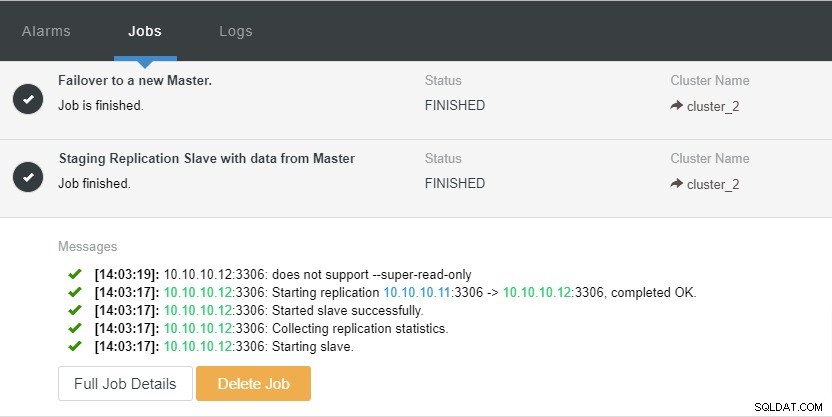
Mari kita lihat screenshot di bawah ini:
Pada tangkapan layar di atas, kita dapat melihat bahwa "Pemulihan Otomatis" diaktifkan untuk Cluster dan Node.js. Dalam topologi, perhatikan bahwa alamat IP master saat ini adalah 10.10.10.11. Apa yang akan terjadi jika kita menghapus master node untuk tujuan pengujian?
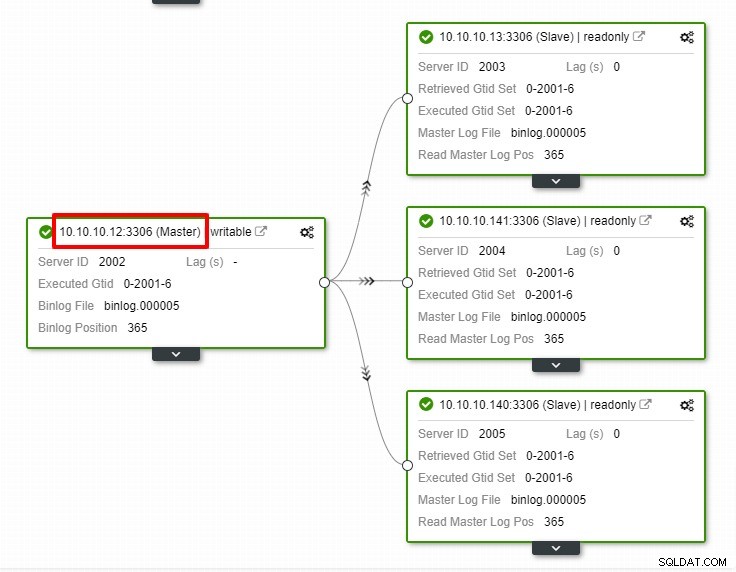
Seperti yang Anda lihat, node slave dengan IP 10.10.10.12 secara otomatis dipromosikan menjadi master, sehingga topologi replikasi dikonfigurasi ulang. Alih-alih melakukannya secara manual yang, tentu saja, akan melibatkan banyak langkah, ClusterControl membantu Anda mempertahankan penyiapan replikasi dengan menghilangkan kerumitan.
Kesimpulan
Dalam setiap kejadian yang tidak menguntungkan dengan replikasi Anda, perbaikannya sangat sederhana dan tidak merepotkan dengan ClusterControl. ClusterControl membantu Anda memulihkan masalah replikasi dengan cepat, yang meningkatkan waktu aktif database Anda.