Pada bagian sebelumnya, kita telah menguji waktu pencadangan dan efektivitas kompresi untuk tingkat dan metode kompresi cadangan yang berbeda. Di blog ini kami akan melanjutkan upaya kami dan kami akan berbicara tentang lebih banyak pengaturan yang, mungkin, sebagian besar pengguna tidak benar-benar berubah namun mereka mungkin memiliki efek yang terlihat pada proses pencadangan.
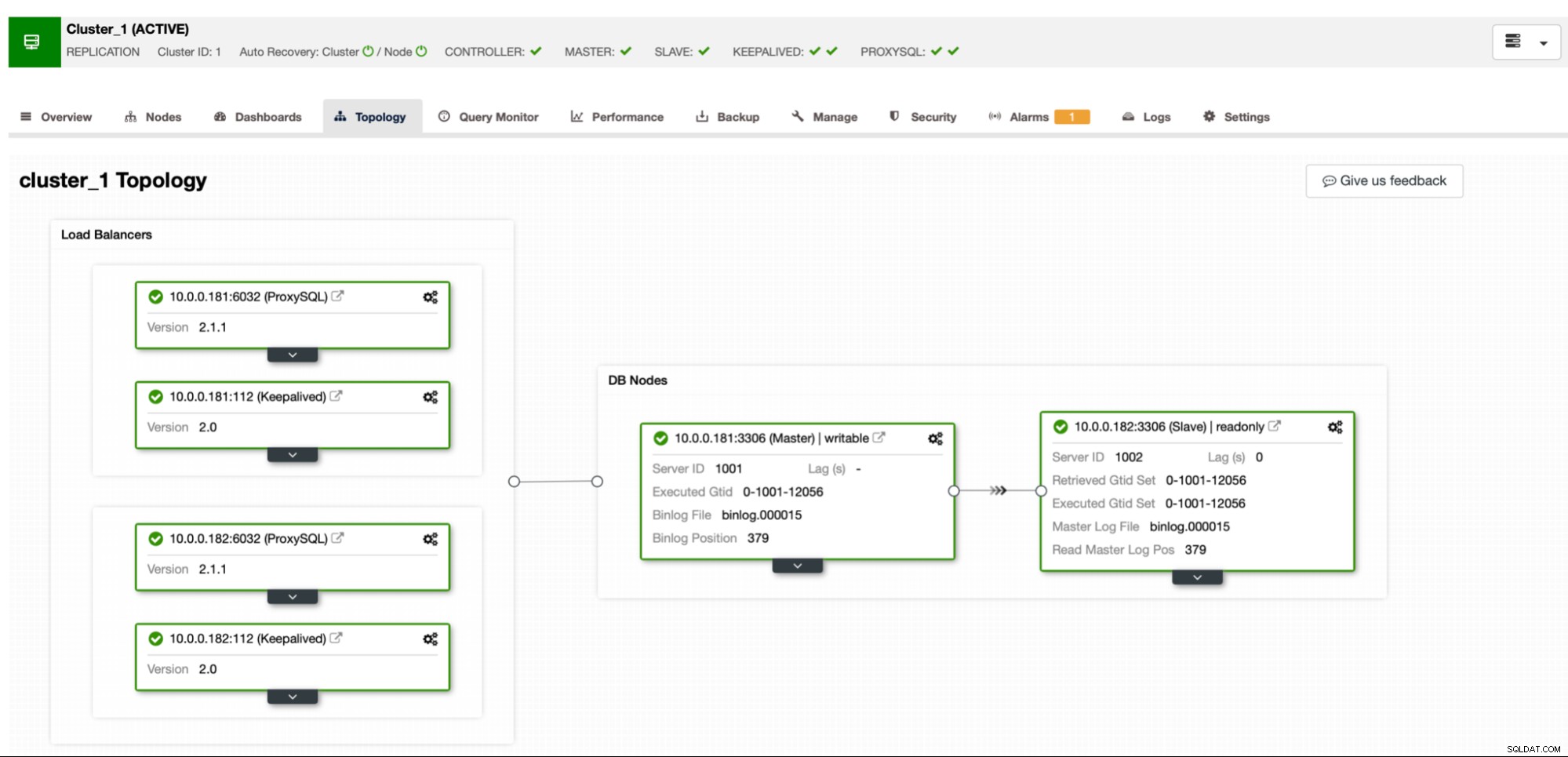
Pengaturannya sama seperti di bagian sebelumnya:kita akan menggunakan cluster replikasi master-slave MariaDB dengan ProxySQL dan Keepalive.
Kami telah menghasilkan 7,6 GB data menggunakan sysbench:
sysbench /root/sysbench/src/lua/oltp_read_write.lua --threads=4 --mysql-host=10.0.0.111 --mysql-user=sbtest --mysql-password=sbtest --mysql-port=6033 --tables=32 --table-size=1000000 prepareMenggunakan PIGZ
Kali ini kita akan mengaktifkan Use PIGZ for parallel gzip untuk backup kita. Seperti sebelumnya, kami akan menguji setiap level kompresi untuk melihat kinerjanya.
Kami menyimpan cadangan secara lokal pada instance, instance dikonfigurasi dengan 4 vCPU.
Hasilnya seperti yang diharapkan. Proses pencadangan jauh lebih cepat daripada saat kami hanya menggunakan satu inti CPU. Ukuran cadangan tetap hampir sama, tidak ada alasan nyata untuk itu berubah secara signifikan. Jelas bahwa menggunakan pigz meningkatkan waktu pencadangan. Ada sisi gelap dari penggunaan gzip paralel, dan itu adalah penggunaan CPU:
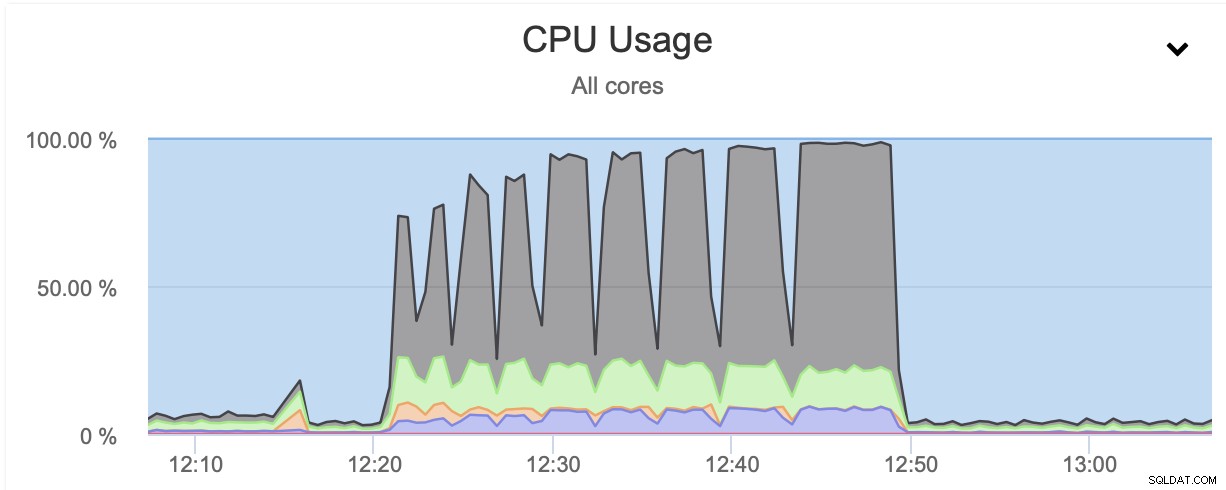
Seperti yang Anda lihat, penggunaan CPU meroket dan mencapai hampir 100% untuk tingkat kompresi yang lebih tinggi. Meningkatkan pemanfaatan CPU pada server database tidak selalu merupakan ide terbaik karena, biasanya, kami ingin CPU tersedia untuk database. Di sisi lain, jika kita kebetulan memiliki replika yang didedikasikan untuk mengambil cadangan dan, katakanlah, kueri yang lebih berat - sebuah simpul yang tidak digunakan untuk melayani jenis lalu lintas OLTP, kita dapat mengaktifkan gzip paralel untuk sangat mengurangi cadangan waktu. Seperti dapat dilihat dengan jelas, ini bukan pilihan untuk semua orang, tetapi ini pasti sesuatu yang menurut Anda berguna dalam beberapa skenario tertentu. Perlu diingat bahwa penggunaan CPU adalah sesuatu yang perlu Anda lacak karena akan memengaruhi latensi kueri dan, karena melaluinya, hal itu akan memengaruhi pengalaman pengguna - sesuatu yang harus selalu kami pertimbangkan saat bekerja dengan database.
Utas Salin Paralel Xtrabackup
Setelan lain yang ingin kami soroti adalah Xtrabackup Parallel Copy Threads. Untuk memahami apa itu, mari kita bicara sedikit tentang cara kerja Xtrabackup (atau MariaBackup). Singkatnya, alat-alat itu melakukan dua tindakan secara bersamaan. Mereka menyalin data, file fisik, dari server database ke lokasi pencadangan sambil memantau log redo InnoDB untuk pembaruan apa pun. Cadangan terdiri dari file dan catatan semua perubahan pada InnoDB yang terjadi selama proses pencadangan. Ini, dengan kunci cadangan atau FLUSH TABLES WITH READ LOCK, memungkinkan untuk membuat cadangan yang konsisten pada titik waktu ketika transfer data telah selesai. Xtrabackup Parallel Copy Threads menentukan jumlah thread yang akan melakukan transfer data. Jika kita set ke 1, satu file akan disalin pada waktu yang sama. Jika kita set ke 8, secara teoritis hingga 8 file dapat ditransfer sekaligus. Tentu saja, harus ada penyimpanan yang cukup cepat untuk benar-benar mendapat manfaat dari pengaturan seperti itu. Kami akan melakukan beberapa pengujian, mengubah Xtrabackup Parallel Copy Threads dari 1 hingga 2 dan 4 menjadi 8. Kami akan menjalankan pengujian pada tingkat kompresi 6 (default satu) dengan dan tanpa mengaktifkan gzip paralel.
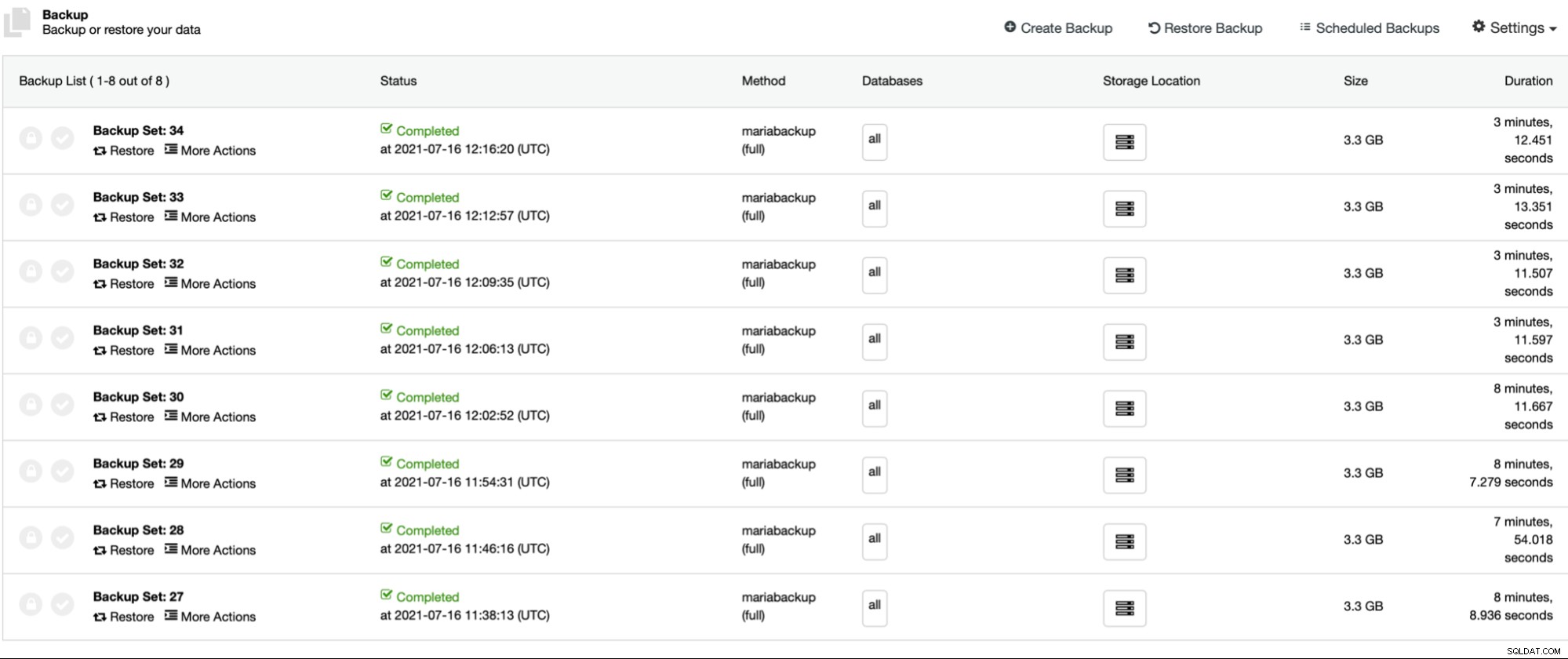
Empat cadangan pertama (27 - 30) telah dibuat tanpa gzip paralel, mulai dari 1 hingga 2, 4 dan 8 utas salinan paralel. Kemudian kami mengulangi proses yang sama untuk cadangan 31 hingga 34, kali ini menggunakan gzip paralel. Seperti yang Anda lihat, dalam kasus kami hampir tidak ada perbedaan antara utas salinan paralel. Ini kemungkinan besar akan lebih berdampak jika kita meningkatkan ukuran kumpulan data. Ini juga akan meningkatkan kinerja pencadangan jika kami menggunakan penyimpanan yang lebih cepat dan lebih andal. Seperti biasa, jarak tempuh Anda akan bervariasi dan di lingkungan yang berbeda, setelan ini dapat memengaruhi proses pencadangan lebih dari yang kami lihat di sini.
Pembatasan jaringan
Akhirnya, di bagian seri pendek ini, kami ingin berbicara tentang kemampuan untuk membatasi penggunaan jaringan.
Seperti yang mungkin telah Anda lihat, cadangan dapat disimpan secara lokal di node atau itu juga dapat dialirkan ke host pengontrol. Ini terjadi melalui jaringan dan, secara default, ini akan dilakukan "secepat mungkin".
Dalam beberapa kasus, di mana throughput jaringan Anda terbatas (misalnya, instance cloud), Anda mungkin ingin mengurangi penggunaan jaringan yang disebabkan oleh MariaBackup dengan menetapkan batas pada transfer jaringan. Saat Anda melakukannya, ClusterControl akan menggunakan alat 'pv' untuk membatasi bandwidth yang tersedia untuk proses tersebut.
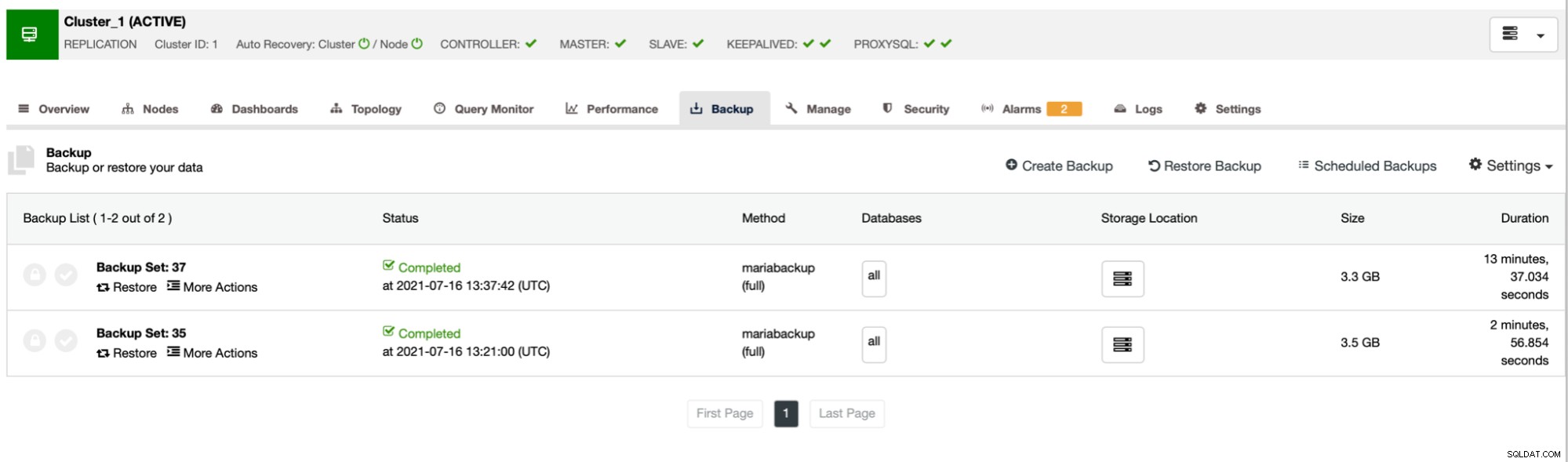
Seperti yang Anda lihat, pencadangan pertama memakan waktu sekitar 3 menit tetapi ketika kami membatasi throughput jaringan, pencadangan membutuhkan waktu 13 menit dan 37 detik.
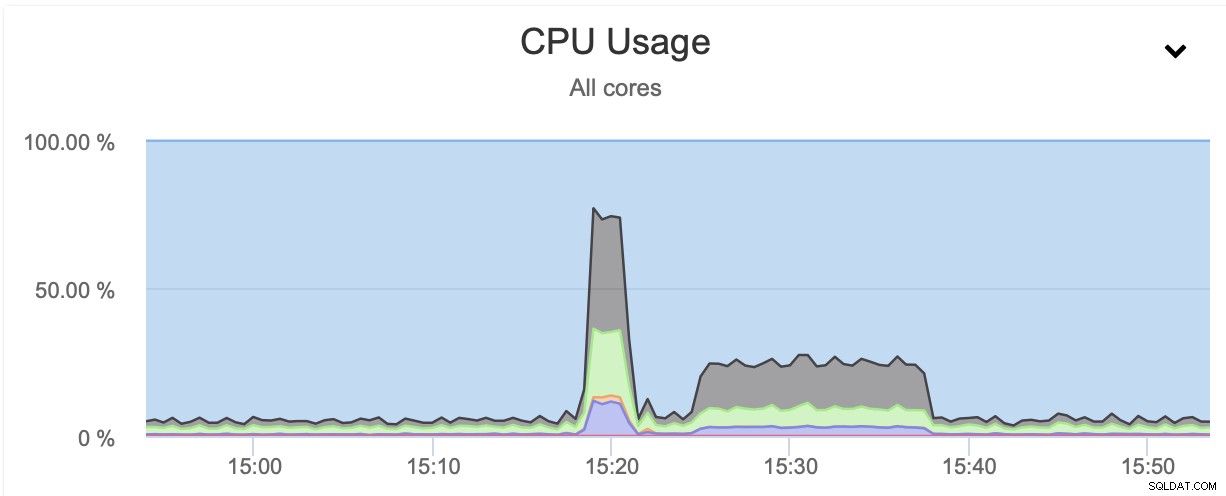
Dalam kedua kasus kami menggunakan pigz dan tingkat kompresi 1. Grafik di atas menunjukkan bahwa pembatasan jaringan juga mengurangi penggunaan CPU. Masuk akal, jika pigz harus menunggu jaringan untuk mentransfer data, ia tidak perlu menekan CPU dengan keras karena harus sering menganggur.
Semoga blog singkat ini menarik bagi Anda dan mungkin akan mendorong Anda untuk bereksperimen dengan beberapa fitur dan opsi MariaBackup yang jarang digunakan. Jika Anda ingin berbagi beberapa pengalaman Anda, kami ingin mendengar dari Anda di komentar di bawah.