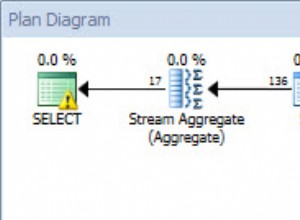
Jelas, masalahnya adalah bahwa kueri sedang melakukan pemindaian indeks. Pendekatan alternatif adalah melakukan dua pencarian indeks, untuk nilai pertama dan terakhir yang sama, dan kemudian menggunakan informasi meta dalam indeks untuk perhitungan. Berdasarkan pengamatan Anda, MySQL melakukan keduanya.
Sisa dari jawaban ini adalah spekulasi.
Alasan kinerja "hanya" 300 kali lebih lambat, daripada 200.000 kali lebih lambat, adalah karena overhead dalam membaca indeks. Sebenarnya pemindaian entri cukup cepat dibandingkan dengan operasi lain yang diperlukan.
Ada perbedaan mendasar antara angka dan string dalam hal perbandingan. Mesin hanya dapat melihat representasi bit dari dua angka dan mengenali apakah keduanya sama atau berbeda. Sayangnya, untuk string, Anda perlu mempertimbangkan penyandian/penyusunan. Saya pikir itu sebabnya perlu melihat nilainya.
Mungkin saja jika Anda memiliki 216.000 eksemplar persis string yang sama, maka MySQL akan dapat melakukan penghitungan menggunakan metadata di index. Dengan kata lain, pengindeks cukup pintar untuk menggunakan metadata untuk perbandingan kesetaraan yang tepat. Tapi, itu tidak cukup pintar untuk memperhitungkan penyandian.