Partisi adalah fitur SQL Server yang sering diterapkan untuk mengurangi tantangan yang terkait dengan pengelolaan, tugas pemeliharaan, atau penguncian dan pemblokiran. Administrasi tabel besar dapat menjadi lebih mudah dengan partisi, dan dapat meningkatkan skalabilitas dan ketersediaan. Selain itu, produk sampingan dari partisi dapat meningkatkan kinerja kueri. Ini bukan jaminan atau pemberian, dan itu bukan alasan yang mendorong untuk menerapkan partisi, tetapi ini adalah sesuatu yang layak ditinjau ketika Anda mempartisi tabel besar.
Latar Belakang
Sebagai tinjauan singkat, fitur partisi SQL Server hanya tersedia di Edisi Perusahaan dan Pengembang. Partisi dapat diimplementasikan selama desain basis data awal, atau dapat ditempatkan setelah tabel sudah memiliki data di dalamnya. Pahami bahwa mengubah tabel yang ada dengan data ke tabel yang dipartisi tidak selalu cepat dan sederhana, tetapi cukup layak dengan perencanaan yang baik dan manfaatnya dapat segera direalisasikan.
Tabel yang dipartisi adalah tabel di mana data dipisahkan menjadi struktur fisik yang lebih kecil berdasarkan nilai untuk kolom tertentu (disebut kolom partisi, yang didefinisikan dalam fungsi partisi). Jika Anda ingin memisahkan data menurut tahun, Anda dapat menggunakan kolom yang disebut DateSold sebagai kolom partisi, dan semua data untuk 2013 akan berada dalam satu struktur, semua data untuk 2012 akan berada dalam struktur yang berbeda, dll. Kumpulan data yang terpisah ini memungkinkan pemeliharaan terfokus (Anda dapat membangun kembali hanya sebagian dari indeks, bukan seluruh indeks) dan mengizinkan data untuk ditambahkan dan dihapus dengan cepat karena dapat dipentaskan sebelum benar-benar ditambahkan ke, atau dihapus dari, tabel.
Penyiapan
Untuk memeriksa perbedaan kinerja kueri untuk tabel yang dipartisi versus tabel yang tidak dipartisi, saya membuat dua salinan tabel Sales.SalesOrderHeader dari database AdventureWorks2012. Tabel yang tidak dipartisi dibuat hanya dengan indeks berkerumun di SalesOrderID, kunci utama tradisional untuk tabel. Tabel kedua dipartisi pada OrderDate, dengan OrderDate dan SalesOrderID sebagai kunci pengelompokan, dan tidak memiliki indeks tambahan. Perhatikan bahwa ada banyak faktor yang perlu dipertimbangkan ketika memutuskan kolom apa yang akan digunakan untuk mempartisi. Mempartisi sering, tetapi tentu saja tidak selalu, menggunakan bidang tanggal untuk menentukan batas partisi. Dengan demikian, OrderDate dipilih untuk contoh ini, dan kueri sampel digunakan untuk mensimulasikan aktivitas tipikal terhadap tabel SalesOrderHeader. Pernyataan untuk membuat dan mengisi kedua tabel dapat diunduh di sini.
Setelah membuat tabel dan menambahkan data, indeks yang ada diverifikasi dan kemudian statistik diperbarui dengan FULLSCAN:
EXEC sp_helpindex 'Sales.Big_SalesOrderHeader'; GO EXEC sp_helpindex 'Sales.Part_SalesOrderHeader'; GO UPDATE STATISTICS [Sales].[Big_SalesOrderHeader] WITH FULLSCAN; GO UPDATE STATISTICS [Sales].[Part_SalesOrderHeader] WITH FULLSCAN; GO SELECT sch.name + '.' + so.name AS [Table], ss.name AS [Statistic], sp.last_updated AS [Stats Last Updated], sp.rows AS [Rows], sp.rows_sampled AS [Rows Sampled], sp.modification_counter AS [Row Modifications] FROM sys.stats AS ss INNER JOIN sys.objects AS so ON ss.[object_id] = so.[object_id] INNER JOIN sys.schemas AS sch ON so.[schema_id] = sch.[schema_id] OUTER APPLY sys.dm_db_stats_properties(so.[object_id], ss.stats_id) AS sp WHERE so.[object_id] IN (OBJECT_ID(N'Sales.Big_SalesOrderHeader'), OBJECT_ID(N'Sales.Part_SalesOrderHeader')) AND ss.stats_id = 1;
Selain itu, kedua tabel memiliki distribusi data yang sama persis dan fragmentasi minimal.
Kinerja untuk Kueri Sederhana
Sebelum indeks tambahan ditambahkan, kueri dasar dijalankan terhadap kedua tabel untuk menghitung total yang diperoleh staf penjualan untuk pesanan yang dilakukan pada bulan Desember 2012:
SELECT [SalesPersonID], SUM([TotalDue]) FROM [Sales].[Big_SalesOrderHeader] WHERE [OrderDate] BETWEEN '2012-12-01' AND '2012-12-31' GROUP BY [SalesPersonID]; GO SELECT [SalesPersonID], SUM([TotalDue]) FROM [Sales].[Part_SalesOrderHeader] WHERE [OrderDate] BETWEEN '2012-12-01' AND '2012-12-31' GROUP BY [SalesPersonID]; GOSTATISTIK IO OUTPUT
Meja 'Meja Kerja'. Hitungan pemindaian 0, pembacaan logis 0, pembacaan fisik 0, pembacaan ke depan 0, pembacaan logika lob 0, pembacaan fisik lob 0, pembacaan depan pembacaan lob 0.
Tabel 'Big_SalesOrderHeader'. Hitungan pindai 9, pembacaan logis 2710440, pembacaan fisik 2226, pembacaan depan membaca 2658769, pembacaan logika lob 0, pembacaan fisik lob 0, pembacaan depan pembacaan lob 0.
Meja 'Meja Kerja'. Hitungan pindai 0, pembacaan logis 0, pembacaan fisik 0, pembacaan ke depan 0, pembacaan logika lob 0, pembacaan fisik lob 0, pembacaan depan pembacaan lob 0.
Tabel 'Part_SalesOrderHeader'. Hitungan pindai 9, pembacaan logis 248128, pembacaan fisik 3, pembacaan depan membaca 245030, pembacaan logika lob 0, pembacaan fisik lob 0, pembacaan depan pembacaan lob 0.

Total menurut Tenaga Penjualan untuk Desember – Tabel Tanpa Partisi
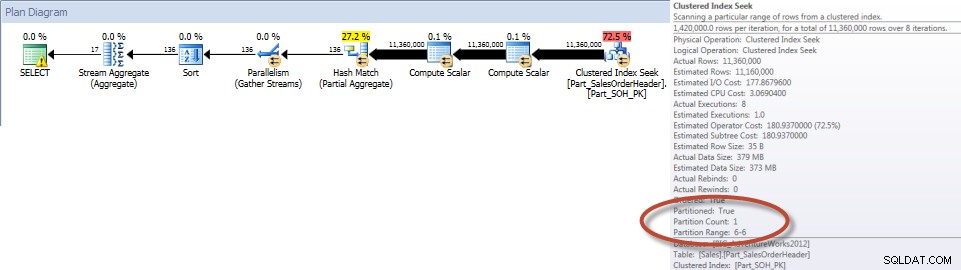
Total menurut Staf Penjualan untuk Desember – Tabel yang Dipartisi
Seperti yang diharapkan, kueri terhadap tabel yang tidak dipartisi harus melakukan pemindaian penuh tabel karena tidak ada indeks yang mendukungnya. Sebaliknya, kueri terhadap tabel yang dipartisi hanya diperlukan untuk mengakses satu partisi tabel.
Agar adil, jika ini adalah kueri yang berulang kali dieksekusi dengan rentang tanggal yang berbeda, indeks nonclustered yang sesuai akan ada. Misalnya:
CREATE NONCLUSTERED INDEX [Big_SalesOrderHeader_SalesPersonID] ON [Sales].[Big_SalesOrderHeader] ([OrderDate]) INCLUDE ([SalesPersonID], [TotalDue]);
Dengan indeks ini dibuat, ketika kueri dijalankan kembali, statistik I/O turun dan rencana berubah untuk menggunakan indeks nonclustered:
STATISTIK IO OUTPUT
Meja 'Meja Kerja'. Hitungan pemindaian 0, pembacaan logis 0, pembacaan fisik 0, pembacaan ke depan 0, pembacaan logika lob 0, pembacaan fisik lob 0, pembacaan depan pembacaan lob 0.
Tabel 'Big_SalesOrderHeader'. Hitungan pindai 9, pembacaan logis 42901, pembacaan fisik 3, pembacaan depan membaca 42346, pembacaan logika lob 0, pembacaan fisik lob 0, pembacaan depan pembacaan lob 0.

Total menurut Tenaga Penjualan untuk Desember – NCI pada Tabel Tanpa Partisi
Dengan indeks pendukung, kueri terhadap Sales.Big_SalesOrderHeader membutuhkan pembacaan yang jauh lebih sedikit daripada pemindaian indeks berkerumun terhadap Sales.Part_SalesOrderHeader, yang tidak terduga karena indeks berkerumun jauh lebih luas. Jika kami membuat indeks nonclustered yang sebanding untuk Sales.Part_SalesOrderHeader, kami melihat nomor I/O yang serupa:
CREATE NONCLUSTERED INDEX [Part_SalesOrderHeader_SalesPersonID] ON [Sales].[Part_SalesOrderHeader]([SalesPersonID]) INCLUDE ([TotalDue]);STATISTIK IO OUTPUT
Tabel 'Part_SalesOrderHeader'. Hitungan pindai 9, pembacaan logis 42894, pembacaan fisik 1, pembacaan depan membaca 42378, pembacaan logika lob 0, pembacaan fisik lob 0, pembacaan depan pembacaan lob 0.
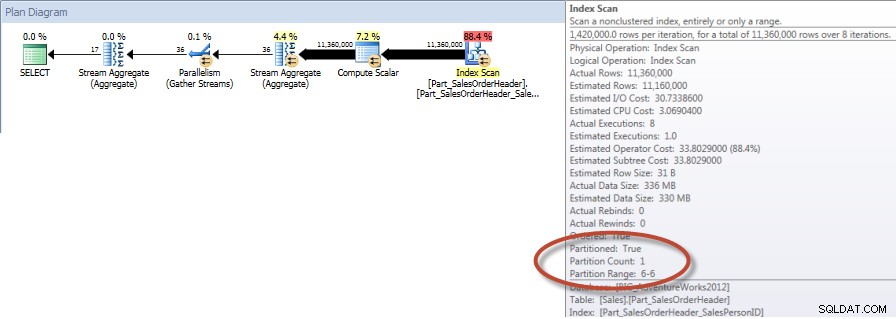
Total menurut Staf Penjualan untuk bulan Desember – NCI pada Tabel yang Dipartisi dengan Penghapusan
Dan jika kita melihat properti dari Scan Indeks nonclustered, kita dapat memverifikasi bahwa mesin hanya mengakses satu partisi (6).
Seperti yang dinyatakan sebelumnya, partisi biasanya tidak diimplementasikan untuk meningkatkan kinerja. Dalam contoh yang ditunjukkan di atas, kueri terhadap tabel yang dipartisi tidak berkinerja lebih baik secara signifikan selama indeks nonclustered yang sesuai ada.
Kinerja untuk Kueri Ad-Hoc
Kueri terhadap tabel yang dipartisi bisa mengungguli kueri yang sama terhadap tabel yang tidak dipartisi dalam beberapa kasus, misalnya ketika kueri harus menggunakan indeks berkerumun. Meskipun ideal untuk memiliki sebagian besar kueri yang didukung oleh indeks nonclustered, beberapa sistem mengizinkan kueri ad-hoc dari pengguna, dan yang lain memiliki kueri yang mungkin berjalan sangat jarang sehingga tidak memerlukan indeks pendukung. Terhadap tabel SalesOrderHeader, pengguna mungkin menjalankan kueri berikut untuk menemukan pesanan dari Desember 2012 yang perlu dikirim pada akhir tahun tetapi tidak, untuk kumpulan pelanggan tertentu dan dengan TotalDue lebih besar dari $1000:
SELECT [SalesOrderID], [OrderDate], [DueDate], [ShipDate], [AccountNumber], [CustomerID], [SalesPersonID], [SubTotal], [TotalDue] FROM [Sales].[Big_SalesOrderHeader] WHERE [TotalDue] > 1000 AND [CustomerID] BETWEEN 10000 AND 20000 AND [OrderDate] BETWEEN '2012-12-01' AND '2012-12-31' AND [DueDate] < '2012-12-31' AND [ShipDate] > '2012-12-31'; GO SELECT [SalesOrderID], [OrderDate], [DueDate], [ShipDate], [AccountNumber], [CustomerID], [SalesPersonID], [SubTotal], [TotalDue] FROM [Sales].[Part_SalesOrderHeader] WHERE [TotalDue] > 1000 AND [CustomerID] BETWEEN 10000 AND 20000 AND [OrderDate] BETWEEN '2012-12-01' AND '2012-12-31' AND [DueDate] < '2012-12-31' AND [ShipDate] > '2012-12-31'; GOSTATISTIK IO OUTPUT
Tabel 'Big_SalesOrderHeader'. Hitungan pindai 9, pembacaan logis 2711220, pembacaan fisik 8386, pembacaan depan pembacaan 2662400, pembacaan logika lob 0, pembacaan fisik lob 0, pembacaan depan pembacaan lob 0.
Tabel 'Part_SalesOrderHeader'. Hitungan pindai 9, pembacaan logis 248128, pembacaan fisik 0, pembacaan depan membaca 243792, pembacaan logika lob 0, pembacaan fisik lob 0, pembacaan depan pembacaan lob 0.
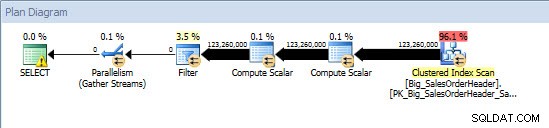
Kueri Ad-Hoc – Tabel Tanpa Partisi
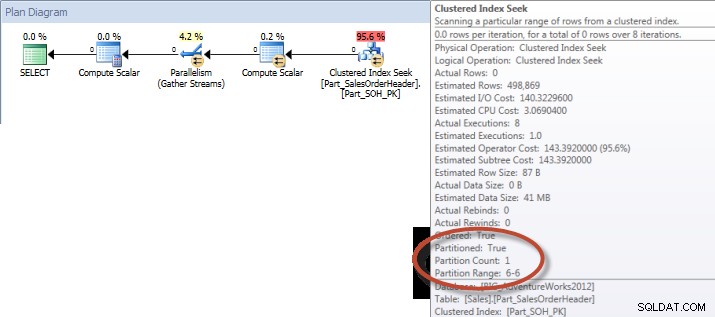
Kueri Ad-Hoc – Tabel yang Dipartisi
Terhadap tabel yang tidak dipartisi, kueri memerlukan pemindaian penuh terhadap indeks berkerumun, tetapi terhadap tabel yang dipartisi, kueri melakukan pencarian indeks dari indeks berkerumun, karena mesin menggunakan penghapusan partisi dan hanya membaca data yang benar-benar diperlukan. Dalam contoh ini, ini adalah perbedaan yang signifikan dalam hal I/O, dan tergantung pada perangkat kerasnya, dapat menjadi perbedaan dramatis dalam waktu eksekusi. Kueri dapat dioptimalkan dengan menambahkan indeks yang sesuai, tetapi biasanya tidak layak untuk diindeks untuk setiap lajang pertanyaan. Khususnya, untuk solusi yang memungkinkan kueri ad-hoc, wajar untuk mengatakan bahwa Anda tidak pernah tahu apa yang akan dilakukan pengguna. Kueri dapat berjalan sekali dan tidak pernah berjalan lagi, dan membuat indeks setelah fakta adalah sia-sia. Oleh karena itu, ketika mengubah dari tabel yang tidak dipartisi ke tabel yang dipartisi, penting untuk menerapkan upaya dan pendekatan yang sama seperti penyetelan indeks biasa; Anda ingin memverifikasi bahwa indeks yang sesuai ada untuk mendukung sebagian besar kueri.
Kinerja dan Keselarasan Indeks
Faktor tambahan yang perlu dipertimbangkan saat membuat indeks untuk tabel yang dipartisi adalah apakah akan menyelaraskan indeks atau tidak. Indeks harus sejajar dengan tabel jika Anda berencana untuk mengganti data masuk dan keluar dari partisi. Membuat indeks nonclustered pada tabel yang dipartisi membuat indeks selaras secara default, di mana kolom partisi ditambahkan sebagai kolom yang disertakan ke indeks.
Indeks yang tidak selaras dibuat dengan menentukan skema partisi yang berbeda atau grup file yang berbeda. Kolom partisi dapat menjadi bagian dari indeks sebagai kolom kunci atau kolom yang disertakan, tetapi jika skema partisi tabel tidak digunakan, atau grup file yang berbeda digunakan, indeks tidak akan disejajarkan.
Indeks selaras dipartisi seperti tabel – data akan ada dalam struktur terpisah – dan oleh karena itu penghapusan partisi dapat terjadi. Indeks yang tidak selaras ada sebagai satu struktur fisik, dan mungkin tidak memberikan manfaat yang diharapkan untuk kueri, tergantung pada predikatnya. Pertimbangkan kueri yang menghitung penjualan berdasarkan nomor akun, dikelompokkan berdasarkan bulan:
SELECT DATEPART(MONTH,[OrderDate]),COUNT([AccountNumber]) FROM [Sales].[Part_SalesOrderHeader] WHERE [OrderDate] BETWEEN '2013-01-01' AND '2013-07-31' GROUP BY DATEPART(MONTH,[OrderDate]) ORDER BY DATEPART(MONTH,[OrderDate]);
Jika Anda tidak begitu akrab dengan partisi, Anda dapat membuat indeks seperti ini untuk mendukung kueri (perhatikan bahwa grup file PRIMARY ditentukan):
CREATE NONCLUSTERED INDEX [Part_SalesOrderHeader_AccountNumber_NotAL] ON [Sales].[Part_SalesOrderHeader]([AccountNumber]) ON [PRIMARY];
Indeks ini tidak selaras, meskipun termasuk OrderDate karena merupakan bagian dari kunci utama. Kolom juga disertakan jika kita membuat indeks sejajar, tetapi perhatikan perbedaan sintaksisnya:
CREATE NONCLUSTERED INDEX [Part_SalesOrderHeader_AccountNumber_AL] ON [Sales].[Part_SalesOrderHeader]([AccountNumber]);
Kami dapat memverifikasi kolom apa yang ada di indeks menggunakan sp_helpindex Kimberly Tripp:
EXEC sp_SQLskills_SQL2008_helpindex 'Sales.Part_SalesOrderHeader’;

sp_helpindex untuk Penjualan.Part_SalesOrderHeader
Saat kami menjalankan kueri dan memaksanya untuk menggunakan indeks yang tidak selaras, seluruh indeks dipindai. Meskipun OrderDate adalah bagian dari indeks, itu bukan kolom terdepan sehingga mesin harus memeriksa nilai OrderDate untuk setiap AccountNumber untuk melihat apakah itu jatuh antara 1 Januari 2013 dan 31 Juli 2013:
SELECT DATEPART(MONTH,[OrderDate]),COUNT([AccountNumber]) FROM [Sales].[Part_SalesOrderHeader] WITH(INDEX([Part_SalesOrderHeader_AccountNumber_NotAL])) WHERE [OrderDate] BETWEEN '2013-01-01' AND '2013-07-31' GROUP BY DATEPART(MONTH,[OrderDate]) ORDER BY DATEPART(MONTH,[OrderDate]);STATISTIK IO OUTPUT
Meja 'Meja Kerja'. Hitungan pindai 0, pembacaan logis 0, pembacaan fisik 0, pembacaan ke depan 0, pembacaan logika lob 0, pembacaan fisik lob 0, pembacaan depan pembacaan lob 0.
Tabel 'Part_SalesOrderHeader'. Hitungan pindai 9, pembacaan logis 786861, pembacaan fisik 1, pembacaan depan membaca 770929, pembacaan logika lob 0, pembacaan fisik lob 0, pembacaan depan pembacaan lob 0.
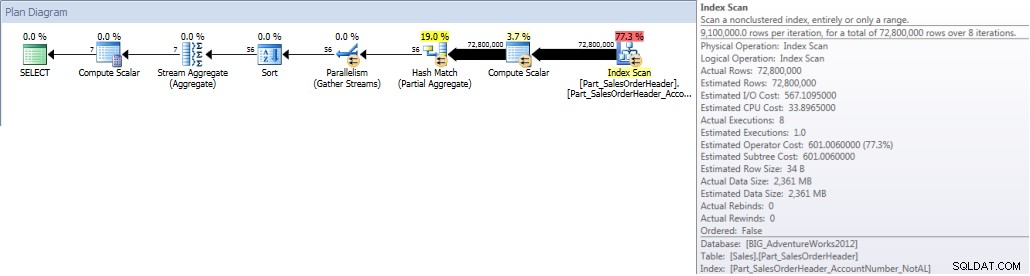
Total Akun berdasarkan Bulan (Januari – Juli 2013) Menggunakan Non- NCI selaras (dipaksa)
Sebaliknya, ketika kueri dipaksa untuk menggunakan indeks yang disejajarkan, penghapusan partisi dapat digunakan, dan lebih sedikit I/O yang diperlukan, meskipun OrderDate bukan kolom utama dalam indeks.
SELECT DATEPART(MONTH,[OrderDate]),COUNT([AccountNumber]) FROM [Sales].[Part_SalesOrderHeader] WITH(INDEX([Part_SalesOrderHeader_AccountNumber_AL])) WHERE [OrderDate] BETWEEN '2013-01-01' AND '2013-07-31' GROUP BY DATEPART(MONTH,[OrderDate]) ORDER BY DATEPART(MONTH,[OrderDate]);STATISTIK IO OUTPUT
Meja 'Meja Kerja'. Hitungan pindai 0, pembacaan logis 0, pembacaan fisik 0, pembacaan ke depan 0, pembacaan logika lob 0, pembacaan fisik lob 0, pembacaan depan pembacaan lob 0.
Tabel 'Part_SalesOrderHeader'. Hitungan pindai 9, pembacaan logis 456258, pembacaan fisik 16, pembacaan depan membaca 453241, pembacaan logika lob 0, pembacaan fisik lob 0, pembacaan depan pembacaan lob 0.
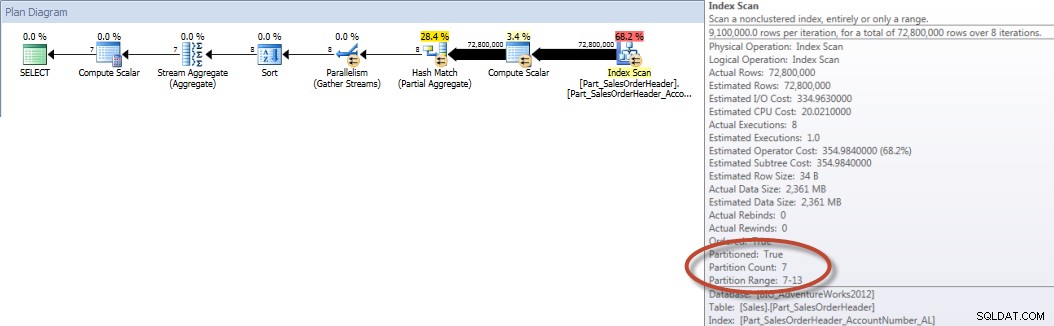
Total Akun berdasarkan Bulan (Januari – Juli 2013) Menggunakan NCI Sejajar (dipaksa)
Ringkasan
Keputusan untuk menerapkan partisi adalah keputusan yang membutuhkan pertimbangan dan perencanaan yang matang. Kemudahan manajemen, peningkatan skalabilitas dan ketersediaan, dan pengurangan pemblokiran adalah alasan umum untuk tabel partisi. Meningkatkan kinerja kueri bukanlah alasan untuk menggunakan partisi, meskipun ini dapat menjadi efek samping yang menguntungkan dalam beberapa kasus. Dalam hal kinerja, penting untuk memastikan bahwa rencana penerapan Anda mencakup tinjauan kinerja kueri. Konfirmasikan bahwa indeks Anda terus mendukung kueri Anda dengan tepat setelah tabel dipartisi, dan verifikasi bahwa kueri menggunakan indeks berkerumun dan tidak berkerumun mendapat manfaat dari penghapusan partisi jika berlaku.