Ketersediaan tinggi adalah persentase waktu yang tinggi bahwa sistem bekerja dan merespons sesuai dengan kebutuhan bisnis. Untuk sistem basis data produksi, biasanya prioritas tertinggi adalah menjaganya tetap mendekati 100%. Kami membangun cluster database untuk menghilangkan semua titik kegagalan. Jika sebuah instance menjadi tidak tersedia, node lain harus dapat mengambil beban kerja dan melanjutkan dari sana. Di dunia yang sempurna, cluster database akan menyelesaikan semua masalah ketersediaan sistem kami. Sayangnya, sementara semua mungkin terlihat bagus di atas kertas, kenyataannya seringkali berbeda. Jadi di mana kesalahannya?
Sistem database transaksional dilengkapi dengan mesin penyimpanan yang canggih. Menjaga data tetap konsisten di beberapa node membuat tugas ini jauh lebih sulit. Clustering memperkenalkan sejumlah variabel baru yang sangat bergantung pada jaringan dan infrastruktur yang mendasarinya. Tidak jarang instance database mandiri yang berjalan dengan baik pada satu node tiba-tiba berkinerja buruk di lingkungan cluster.
Di antara sejumlah hal yang dapat memengaruhi ketersediaan cluster, masalah latensi memainkan peran penting. Namun, apa latensinya? Apakah hanya terkait dengan jaringan?
Istilah "latensi" sebenarnya mengacu pada beberapa jenis penundaan yang terjadi dalam pemrosesan data. Ini adalah berapa lama waktu yang dibutuhkan sebuah informasi untuk berpindah dari satu tahap ke tahap lainnya.
Dalam postingan blog ini, kita akan melihat dua solusi ketersediaan tinggi utama untuk MySQL dan MariaDB, dan bagaimana keduanya dapat dipengaruhi oleh masalah latensi.
Di akhir artikel, kita akan melihat load balancer modern dan mendiskusikan bagaimana mereka dapat membantu Anda mengatasi beberapa jenis masalah latensi.
Dalam artikel sebelumnya, rekan saya Krzysztof Książek menulis tentang "Menangani Jaringan yang Tidak Dapat Diandalkan Saat Membuat Solusi HA untuk MySQL atau MariaDB". Anda akan menemukan tips yang dapat membantu Anda merancang arsitektur HA siap produksi, dan menghindari beberapa masalah yang dijelaskan di sini.
Replikasi Master-Slave untuk Ketersediaan Tinggi.
Replikasi master-slave MySQL mungkin adalah tipe cluster database paling populer di planet ini. Salah satu hal utama yang ingin Anda pantau saat menjalankan kluster replikasi master-slave Anda adalah lag slave. Bergantung pada persyaratan aplikasi Anda dan cara Anda menggunakan database, latensi replikasi (slave lag) dapat menentukan apakah data dapat dibaca dari node slave atau tidak. Data yang dikomit pada master tetapi belum tersedia pada slave asinkron berarti bahwa slave memiliki status yang lebih lama. Ketika tidak boleh membaca dari slave, Anda harus pergi ke master, dan itu dapat memengaruhi kinerja aplikasi. Dalam skenario terburuk, sistem Anda tidak akan mampu menangani semua beban kerja pada master.
Slave lag dan data basi
Untuk memeriksa status replikasi master-slave, Anda harus memulai dengan perintah di bawah ini:
SHOW SLAVE STATUS\G
MariaDB [(none)]> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 10.0.3.100
Master_User: rpl_user
Master_Port: 3306
Connect_Retry: 10
Master_Log_File: binlog.000021
Read_Master_Log_Pos: 5101
Relay_Log_File: relay-bin.000002
Relay_Log_Pos: 809
Relay_Master_Log_File: binlog.000021
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 5101
Relay_Log_Space: 1101
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 3
Master_SSL_Crl:
Master_SSL_Crlpath:
Using_Gtid: Slave_Pos
Gtid_IO_Pos: 0-3-1179
Replicate_Do_Domain_Ids:
Replicate_Ignore_Domain_Ids:
Parallel_Mode: conservative
1 row in set (0.01 sec)Dengan menggunakan informasi di atas, Anda dapat menentukan seberapa bagus latensi replikasi secara keseluruhan. Semakin rendah nilai yang Anda lihat di "Seconds_Behind_Master", semakin baik kecepatan transfer data untuk replikasi.
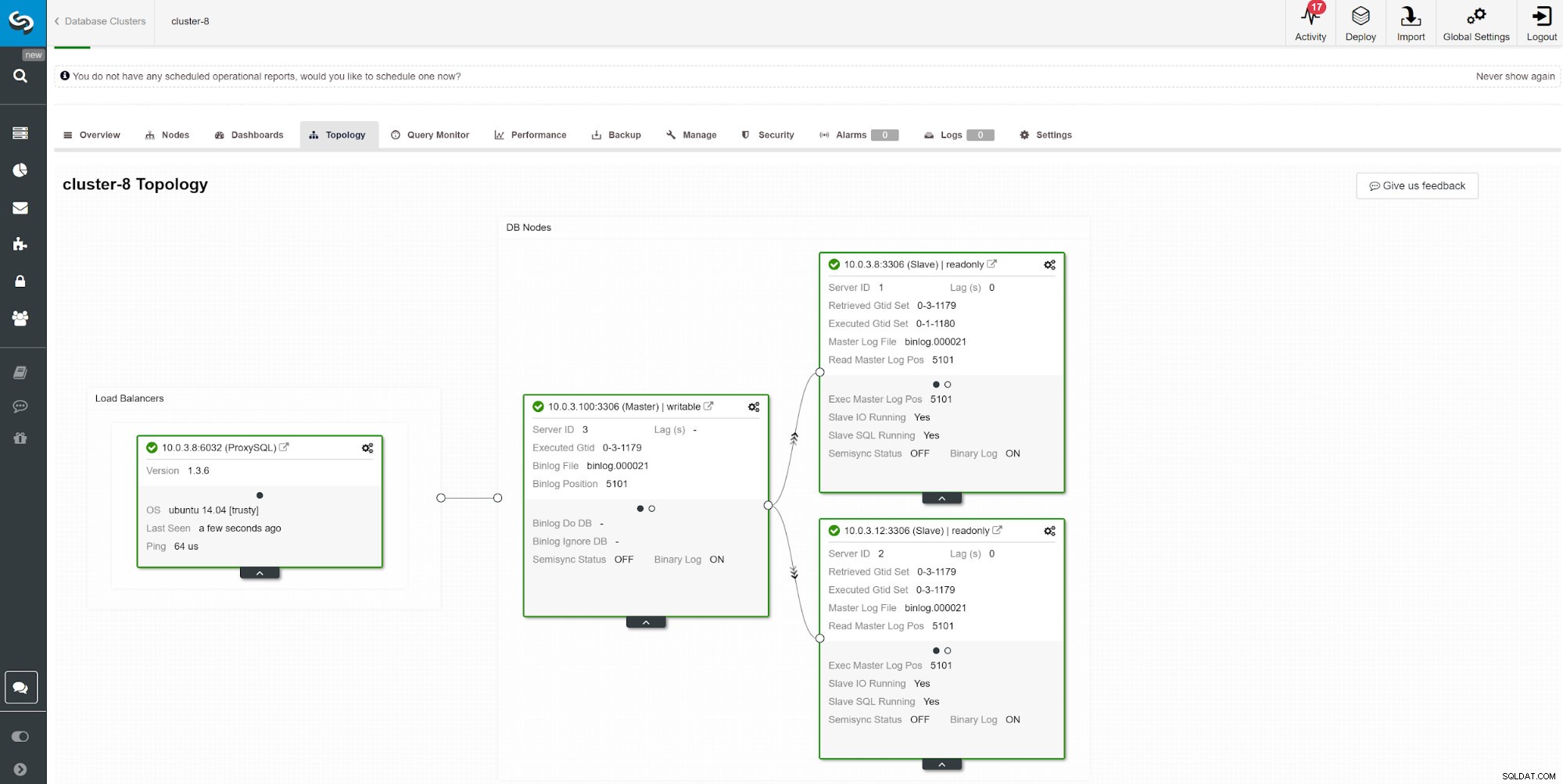 Cara lain untuk memantau kelambatan budak adalah dengan menggunakan pemantauan replikasi ClusterControl. Pada screenshot ini kita dapat melihat status replikasi dari Cluster Master-Slave (2x) asymchoronous dengan ProxySQL.
Cara lain untuk memantau kelambatan budak adalah dengan menggunakan pemantauan replikasi ClusterControl. Pada screenshot ini kita dapat melihat status replikasi dari Cluster Master-Slave (2x) asymchoronous dengan ProxySQL. Ada beberapa hal yang dapat mempengaruhi waktu replikasi. Yang paling jelas adalah throughput jaringan dan berapa banyak data yang dapat Anda transfer. MySQL hadir dengan beberapa opsi konfigurasi untuk mengoptimalkan proses replikasi. Parameter penting terkait replikasi adalah:
- Terapkan paralel
- Algoritme jam logis
- Kompresi
- Replikasi master-slave selektif
- Mode replikasi
Terapkan paralel
Tidak jarang memulai penyetelan replikasi dengan mengaktifkan proses paralel. Alasan untuk itu adalah secara default, MySQL menggunakan log biner sekuensial yang berlaku, dan server database biasa dilengkapi dengan beberapa CPU untuk digunakan.
Untuk menyiasati penerapan log sekuensial, MariaDB dan MySQL menawarkan replikasi paralel. Implementasinya mungkin berbeda per vendor dan versi. Misalnya. MySQL 5.6 menawarkan replikasi paralel selama skema memisahkan kueri sementara MariaDB (mulai versi 10.0) dan MySQL 5.7 keduanya dapat menangani replikasi paralel di seluruh skema. Vendor dan versi yang berbeda hadir dengan keterbatasan dan fiturnya, jadi selalu periksa dokumentasinya.
Menjalankan kueri melalui utas budak paralel dapat mempercepat aliran replikasi Anda jika Anda menulis banyak. Namun, jika tidak, sebaiknya tetap menggunakan replikasi utas tunggal tradisional. Untuk mengaktifkan pemrosesan paralel, ubah slave_parallel_workers ke jumlah utas CPU yang ingin Anda libatkan dalam proses. Disarankan untuk menjaga nilai lebih rendah dari jumlah utas CPU yang tersedia.
Replikasi paralel bekerja paling baik dengan komit grup. Untuk memeriksa apakah Anda memiliki komit grup, jalankan kueri berikut.
show global status like 'binlog_%commits';Semakin besar rasio antara kedua nilai ini semakin baik.
Jam logis
Slave_parallel_type=LOGICAL_CLOCK adalah implementasi dari algoritma clock Lamport. Saat menggunakan budak multithreaded, variabel ini menentukan metode yang digunakan untuk memutuskan transaksi mana yang diizinkan untuk dieksekusi secara paralel pada budak. Variabel tidak berpengaruh pada slave yang multithreadingnya tidak diaktifkan, jadi pastikan slave_parallel_workers disetel lebih tinggi dari 0.
Pengguna MariaDB juga harus memeriksa mode optimis yang diperkenalkan di versi 10.1.3 karena ini juga dapat memberi Anda hasil yang lebih baik.
GTID
MariaDB hadir dengan implementasi GTID-nya sendiri. Urutan MariaDB terdiri dari domain, server, dan transaksi. Domain memungkinkan replikasi multi-sumber dengan ID berbeda. ID domain yang berbeda dapat digunakan untuk mereplikasi bagian data yang rusak (secara paralel). Selama tidak masalah untuk aplikasi Anda, ini dapat mengurangi latensi replikasi.
Teknik serupa berlaku untuk MySQL 5.7 yang juga dapat menggunakan master multisumber dan saluran replikasi independen.
Kompresi
Daya CPU semakin murah dari waktu ke waktu, jadi menggunakannya untuk kompresi binlog bisa menjadi pilihan yang baik untuk banyak lingkungan basis data. Parameter slave_compressed_protocol memberitahu MySQL untuk menggunakan kompresi jika master dan slave mendukungnya. Secara default, parameter ini dinonaktifkan.
Mulai dari MariaDB 10.2.3, peristiwa yang dipilih dalam log biner dapat dikompres secara opsional, untuk menyimpan transfer jaringan.
Format replikasi
MySQL menawarkan beberapa mode replikasi. Memilih format replikasi yang tepat membantu meminimalkan waktu untuk melewatkan data antar node cluster.
Replikasi Multimaster Untuk Ketersediaan Tinggi
Beberapa aplikasi tidak dapat beroperasi pada data yang sudah usang.
Dalam kasus seperti itu, Anda mungkin ingin menerapkan konsistensi di seluruh node dengan replikasi sinkron. Menjaga data tetap sinkron memerlukan plugin tambahan, dan untuk beberapa, solusi terbaik di pasar untuk itu adalah Galera Cluster.
Cluster Galera hadir dengan wsrep API yang bertanggung jawab untuk mentransmisikan transaksi ke semua node dan mengeksekusinya sesuai dengan pemesanan di seluruh cluster. Ini akan memblokir eksekusi kueri berikutnya hingga node menerapkan semua set tulis dari antrian appliernya. Meskipun ini adalah solusi yang baik untuk konsistensi, Anda mungkin menemukan beberapa batasan arsitektur. Masalah latensi umum dapat dikaitkan dengan:
- Node paling lambat dalam cluster
- Penskalaan horizontal dan operasi tulis
- Kluster yang ditempatkan secara geografis
- Ping Tinggi
- Ukuran transaksi
Node paling lambat di cluster
Secara desain, kinerja penulisan cluster tidak boleh lebih tinggi dari kinerja node paling lambat di cluster. Mulai peninjauan klaster Anda dengan memeriksa sumber daya mesin dan memverifikasi file konfigurasi untuk memastikan semuanya berjalan pada setelan kinerja yang sama.
Paralelisasi
Utas paralel tidak menjamin kinerja yang lebih baik, tetapi dapat mempercepat sinkronisasi node baru dengan cluster. Status wsrep_cert_deps_distance memberitahu kita kemungkinan derajat paralelisasi. Ini adalah nilai jarak rata-rata antara nilai seqno tertinggi dan terendah yang mungkin dapat diterapkan secara paralel. Anda dapat menggunakan variabel status wsrep_cert_deps_distance untuk menentukan jumlah maksimum utas budak yang mungkin.
Penskalaan horizontal
Dengan menambahkan lebih banyak node di cluster, kami memiliki lebih sedikit poin yang bisa gagal; namun, informasi harus melewati multi-instance hingga di-commit, yang melipatgandakan waktu respons. Jika Anda membutuhkan penulisan yang dapat diskalakan, pertimbangkan arsitektur berdasarkan sharding. Solusi yang baik adalah mesin penyimpanan Spider.
Dalam beberapa kasus, untuk mengurangi informasi yang dibagikan di seluruh node cluster, Anda dapat mempertimbangkan untuk memiliki satu penulis dalam satu waktu. Ini relatif mudah diterapkan saat menggunakan penyeimbang beban. Saat Anda melakukan ini secara manual, pastikan Anda memiliki prosedur untuk mengubah nilai DNS saat node penulis Anda turun.
Kluster yang ditempatkan secara geografis
Meskipun Galera Cluster sinkron, adalah mungkin untuk menyebarkan Galera Cluster di seluruh pusat data. Replikasi sinkron seperti MySQL Cluster (NDB) mengimplementasikan komit dua fase, di mana pesan dikirim ke semua node dalam kluster dalam fase 'persiapan', dan kumpulan pesan lainnya dikirim dalam fase 'komit'. Pendekatan ini biasanya tidak cocok untuk node yang berbeda secara geografis, karena latensi dalam pengiriman pesan antar node.
Ping Tinggi
Galera Cluster dengan pengaturan default tidak menangani latensi jaringan yang tinggi dengan baik. Jika Anda memiliki jaringan dengan node yang menunjukkan waktu ping tinggi, pertimbangkan untuk mengubah parameter evs.send_window dan evs.user_send_window. Variabel-variabel ini menentukan jumlah maksimum paket data dalam replikasi pada suatu waktu. Untuk penyiapan WAN, variabel dapat disetel ke nilai yang jauh lebih tinggi daripada nilai default 2. Biasanya disetel ke 512. Parameter ini adalah bagian dari wsrep_provider_options.
--wsrep_provider_options="evs.send_window=512;evs.user_send_window=512"Ukuran transaksi
Salah satu hal yang perlu Anda perhatikan saat menjalankan Galera Cluster adalah ukuran transaksi. Menemukan keseimbangan antara ukuran transaksi, kinerja, dan proses sertifikasi Galera adalah sesuatu yang harus Anda perkirakan dalam aplikasi Anda. Anda dapat menemukan informasi lebih lanjut tentang itu di artikel Cara Meningkatkan Kinerja Galera Cluster untuk MySQL atau MariaDB oleh Ashraf Sharif.
Pembacaan Konsistensi Penyebab Penyeimbang Beban
Bahkan dengan risiko masalah latensi data yang diminimalkan, replikasi asinkron MySQL standar tidak dapat menjamin konsistensi. Masih ada kemungkinan bahwa data belum direplikasi ke slave saat aplikasi Anda membacanya dari sana. Replikasi sinkron dapat mengatasi masalah ini, tetapi memiliki keterbatasan arsitektur dan mungkin tidak sesuai dengan persyaratan aplikasi Anda (mis., penulisan massal intensif). Lalu bagaimana cara mengatasinya?
Langkah pertama untuk menghindari pembacaan data yang basi adalah membuat aplikasi menyadari penundaan replikasi. Biasanya diprogram dalam kode aplikasi. Untungnya, ada penyeimbang beban basis data modern dengan dukungan perutean kueri adaptif berdasarkan pelacakan GTID. Yang paling populer adalah ProxySQL dan Maxscale.
ProxySQL 2.0
ProxySQL Binlog Reader memungkinkan ProxySQL untuk mengetahui secara real time GTID mana yang telah dieksekusi di setiap server MySQL, slave, dan master itu sendiri. Berkat ini, ketika klien mengeksekusi pembacaan yang perlu memberikan pembacaan konsistensi kausal, ProxySQL segera mengetahui di server mana kueri dapat dieksekusi. Jika karena alasan apa pun penulisan belum dieksekusi pada slave mana pun, ProxySQL akan mengetahui bahwa penulis telah dieksekusi pada master dan mengirim pembacaan ke sana.
Maxscale 2.3
MariaDB memperkenalkan pembacaan biasa di Maxscale 2.3.0. Cara kerjanya mirip dengan ProxySQL 2.0. Pada dasarnya ketika pembacaan-causal diaktifkan, setiap pembacaan berikutnya yang dilakukan pada server budak akan dilakukan dengan cara yang mencegah penundaan replikasi agar tidak mempengaruhi hasil. Jika budak belum mengejar master dalam waktu yang dikonfigurasi, kueri akan dicoba ulang pada master.