Berikut ini adalah kutipan dari whitepaper kami “Cara Mendesain Lingkungan Basis Data Sumber Terbuka yang Sangat Tersedia” yang dapat diunduh secara gratis.
Beberapa Kata tentang “Ketersediaan Tinggi”
Hari-hari ini ketersediaan tinggi adalah suatu keharusan untuk setiap penyebaran yang serius. Lama berlalu adalah hari-hari ketika Anda bisa menjadwalkan downtime database Anda selama beberapa jam untuk melakukan pemeliharaan. Jika layanan Anda tidak tersedia, Anda kehilangan pelanggan dan uang. Oleh karena itu, membuat lingkungan database sangat tersedia biasanya merupakan salah satu prioritas tertinggi.
Hal ini menimbulkan tantangan yang signifikan untuk database administrator. Pertama-tama, bagaimana Anda mengetahui apakah lingkungan Anda sangat tersedia atau tidak? Bagaimana Anda mengukurnya? Apa langkah-langkah yang perlu Anda ambil untuk meningkatkan ketersediaan? Bagaimana merancang penyiapan Anda agar tersedia sejak awal?
Ada banyak solusi HA yang tersedia di ekosistem MySQL (dan MariaDB), tetapi bagaimana kita tahu mana yang bisa kita percayai? Beberapa solusi mungkin bekerja di bawah kondisi tertentu tertentu, tetapi mungkin menyebabkan lebih banyak masalah bila diterapkan di luar kondisi ini. Bahkan fungsi dasar seperti replikasi MySQL, yang dapat dikonfigurasi dalam banyak cara, dapat menyebabkan kerusakan yang signifikan - misalnya, replikasi melingkar dengan beberapa master yang dapat ditulisi. Meskipun mudah untuk mengatur 'pengaturan multi-master' menggunakan replikasi, itu dapat dengan mudah merusak dan meninggalkan kita dengan kumpulan data yang berbeda di server yang berbeda. Untuk database, yang sering dianggap sebagai satu-satunya sumber kebenaran, integritas data yang dikompromikan dapat menimbulkan konsekuensi bencana.
Dalam bab berikut, kita akan membahas persyaratan ketersediaan tinggi dalam penyiapan
database, dan cara mendesain sistem dari awal.
Mengukur Ketersediaan Tinggi
Apa itu ketersediaan tinggi? Untuk dapat memutuskan apakah lingkungan tertentu sangat tersedia atau tidak, seseorang harus memiliki beberapa metrik untuk itu. Ada banyak cara untuk mengukur ketersediaan tinggi, kami akan fokus pada beberapa hal yang paling mendasar.
Namun, pertama-tama, mari kita pikirkan tentang apa semua ketersediaan tinggi ini? Apa tujuannya? Ini tentang memastikan lingkungan Anda memenuhi tujuannya. Tujuan dapat didefinisikan dalam banyak cara tetapi, biasanya, itu tentang memberikan beberapa layanan. Di dunia database, biasanya agak terkait dengan data. Itu bisa menyajikan data ke aplikasi internal Anda. Hal ini dapat untuk menyimpan data dan membuatnya queryable oleh proses analitis. Itu bisa untuk menyimpan beberapa data untuk pengguna Anda, dan menyediakannya saat diminta sesuai permintaan. Setelah kita jelas tentang tujuannya, kita dapat menetapkan faktor-faktor keberhasilan yang terlibat. Ini akan membantu kami menentukan arti ketersediaan tinggi dalam kasus khusus kami.
SLA
Perjanjian Tingkat Layanan (SLA). Juga cukup umum untuk mendefinisikan SLA untuk layanan internal. Apa itu SLA? Ini adalah definisi tingkat layanan yang Anda rencanakan untuk diberikan kepada pelanggan Anda. Ini agar mereka lebih memahami tingkat stabilitas yang Anda rencanakan untuk layanan yang mereka beli atau rencanakan untuk dibeli. Ada banyak metode yang dapat Anda manfaatkan untuk menyiapkan SLA, tetapi yang umum adalah:
- Ketersediaan layanan (persen)
- Responsivitas layanan - latensi (rata-rata, maks, 95 persen, 99 persentil)
- Kehilangan paket melalui jaringan (persen)
- Throughput (rata-rata, minimum, 95 persentil, 99 persentil)
Ini bisa menjadi lebih kompleks dari itu, meskipun. Dalam lingkungan multi-pengguna sharded, Anda dapat menentukan, katakanlah, SLA Anda sebagai:“Layanan akan tersedia 99,99% setiap saat, waktu henti dinyatakan ketika lebih dari 2% pengguna terpengaruh. Tidak ada insiden yang membutuhkan waktu lebih dari 15 menit untuk diselesaikan”. SLA tersebut juga dapat diperluas untuk memasukkan waktu respons kueri:“waktu henti dipanggil jika 99 persentil latensi untuk kueri melebihi 200 milidetik”.
Sembilan
Ketersediaan biasanya diukur dalam "sembilan", mari kita lihat apa sebenarnya jumlah jaminan "sembilan" yang diberikan. Tabel di bawah ini diambil dari Wikipedia:
| % Ketersediaan | Waktu henti per tahun | Waktu henti per bulan | Waktu henti per minggu | Waktu henti per hari |
|---|---|---|---|---|
| 90% ("satu sembilan") | 36,5 hari | 72 jam | 16,8 jam | 2,4 jam |
| 95% ("satu setengah sembilan") | 18,25 hari | 36 jam | 8,4 jam | 1,2 jam |
| 97% | 10,96 hari | 21,6 jam | 5,04 jam | 43,2 menit |
| 98% | 7,30 hari | 14,4 jam | 3,36 jam | 28,8 menit |
| 99% ("dua sembilan") | 3,65 hari | 7,20 jam | 1,68 jam | 14,4 menit |
| 99,5% ("dua setengah sembilan") | 1,83 hari | 3,60 jam | 50,4 menit | 7,2 menit |
| 99,8% | 17,52 jam | 86,23 menit | 20,16 menit | 2,88 mnt |
| 99,9% ("tiga sembilan") | 8,76 jam | 43,8 menit | 10,1 menit | 1,44 menit |
| 99,95% ("tiga setengah sembilan") | 4,38 jam | 21,56 menit | 5,04 mnt | 43,2 detik |
| 99,99% ("empat sembilan") | 52,56 mnt | 4,38 mnt | 1,01 mnt | 8.64 s |
| 99,995% ("empat setengah sembilan") | 26,28 menit | 2,16 mnt | 30,24 detik | 4.32 s |
| 99,999% ("lima sembilan") | 5,26 mnt | 25,9 detik | 6.05 s | 864.3 md |
| 99,9999% ("enam sembilan") | 31,5 detik | 2,59 detik | 604,8 md | 86,4 md |
| 99,999999% ("tujuh sembilan") | 3,15 detik | 262,97 md | 60,48 md | 8.64 md |
| 99,999999% ("delapan sembilan") | 315.569 md | 26,297 md | 6.048 md | 0.864 md |
| 99,9999999% ("sembilan sembilan") | 31,5569 md | 2,6297 md | 0,6048 md | 0,0864 md |
Seperti yang kita lihat, itu meningkat dengan cepat. Lima sembilan (ketersediaan 99,999%) setara dengan 5,26 menit waktu henti selama setahun. Ketersediaan juga dapat dihitung dalam rentang yang berbeda dan lebih kecil:per bulan, per minggu, per hari. Ingatlah angka-angka tersebut, karena akan berguna saat kita mulai membahas biaya yang terkait dengan mempertahankan tingkat ketersediaan yang berbeda.
Mengukur Ketersediaan
Untuk mengetahui apakah ada downtime atau tidak, seseorang harus memiliki wawasan tentang lingkungan. Anda perlu melacak metrik yang menentukan ketersediaan sistem Anda. Penting untuk diingat bahwa Anda harus mengukurnya dari sudut pandang pelanggan, dengan mempertimbangkan gambaran yang lebih luas. Tidak masalah jika database Anda aktif, katakanlah, karena masalah jaringan, tidak ada aplikasi yang tidak dapat menjangkaunya. Setiap blok penyusun penyiapan Anda berdampak pada ketersediaan.
Salah satu tempat yang bagus untuk mencari data ketersediaan adalah log server web. Semua permintaan yang berakhir dengan kesalahan berarti telah terjadi sesuatu. Bisa jadi HTTP error 500 dikembalikan oleh aplikasi, karena koneksi database gagal. Itu bisa berupa kesalahan program yang menunjuk ke beberapa masalah basis data, dan yang berakhir di log kesalahan Apache. Anda juga dapat menggunakan metrik sederhana sebagai waktu aktif server basis data, meskipun, dengan SLA yang lebih kompleks, mungkin sulit untuk menentukan bagaimana tidak tersedianya satu basis data memengaruhi basis pengguna Anda. Apa pun yang Anda lakukan, Anda harus menggunakan lebih dari satu metrik - ini diperlukan untuk menangkap masalah yang mungkin terjadi pada berbagai lapisan lingkungan Anda.
Angka Ajaib:“Tiga”
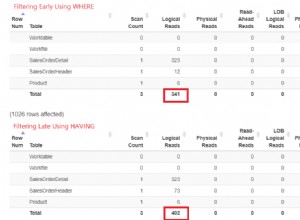
Meskipun ketersediaan tinggi juga tentang redundansi, dalam kasus cluster database, tiga adalah angka ajaib. Tidaklah cukup memiliki dua node untuk redundansi - pengaturan seperti itu tidak menyediakan ketersediaan tinggi bawaan. Tentu, ini mungkin lebih baik daripada hanya satu node, tetapi campur tangan manusia diperlukan untuk memulihkan layanan. Mari kita lihat mengapa demikian.
Mari kita asumsikan kita memiliki dua node, A dan B. Ada tautan jaringan di antara mereka. Mari kita asumsikan bahwa A dan B melayani penulisan dan aplikasi secara acak memilih tempat untuk terhubung (yang berarti bahwa bagian dari aplikasi akan terhubung ke node A dan bagian lainnya akan terhubung ke node B). Sekarang, bayangkan kita memiliki masalah jaringan yang mengakibatkan hilangnya konektivitas jaringan antara A dan B.
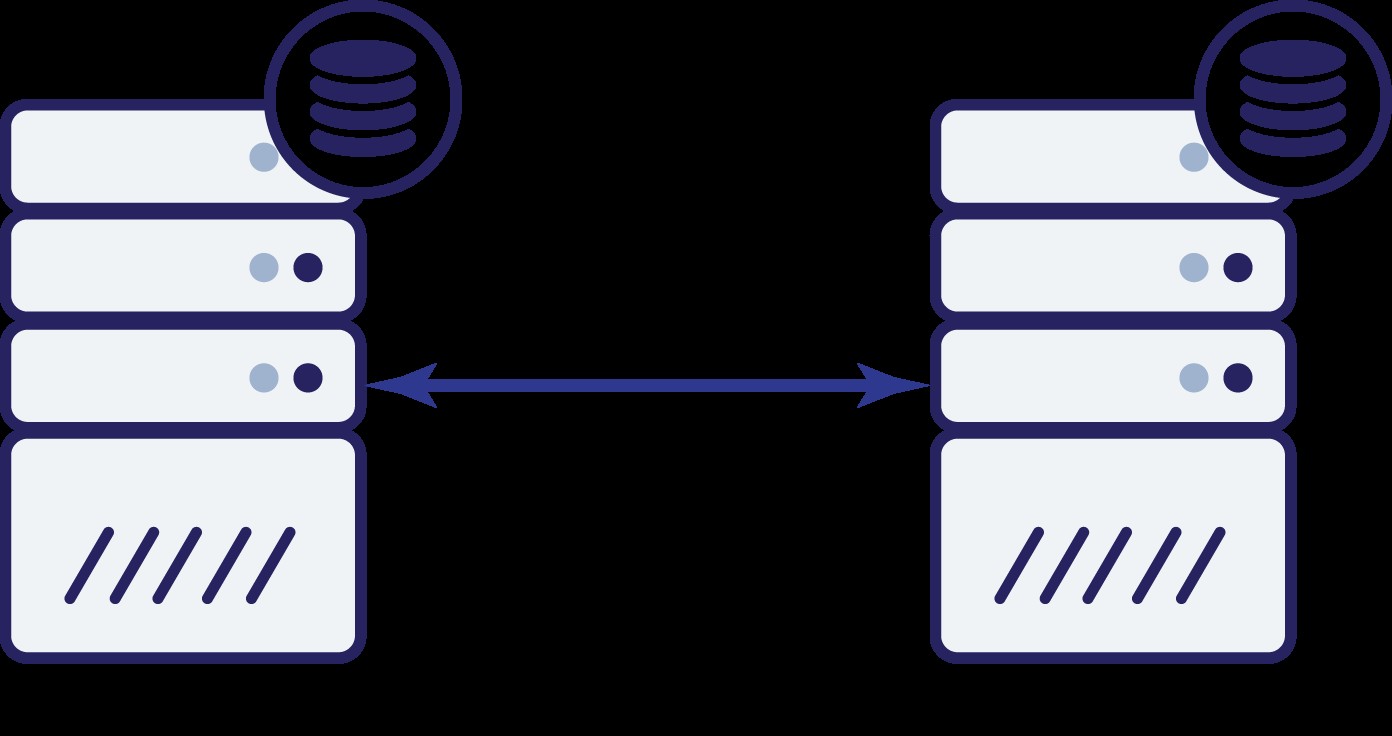
Apa sekarang? Baik A maupun B tidak dapat mengetahui status node lainnya. Ada dua tindakan yang dapat dilakukan oleh kedua node:
- Mereka dapat terus menerima lalu lintas
- Mereka dapat berhenti beroperasi dan menolak melayani lalu lintas apa pun
Mari kita pikirkan opsi pertama. Selama node lain benar-benar down, ini adalah tindakan yang lebih disukai untuk dilakukan - kami ingin database kami terus melayani lalu lintas. Bagaimanapun, ini adalah ide utama di balik ketersediaan tinggi. Namun, apa yang akan terjadi jika kedua node terus menerima lalu lintas saat terputus satu sama lain? Data baru akan ditambahkan di kedua sisi, dan kumpulan data akan tidak sinkron. Ketika masalah jaringan akan teratasi, akan menjadi tugas yang berat untuk menggabungkan kedua kumpulan data tersebut. Oleh karena itu, tidak dapat diterima untuk membuat kedua node tetap aktif dan berjalan. Masalahnya adalah - bagaimana simpul A dapat mengetahui apakah simpul B hidup atau tidak (dan sebaliknya)? Jawabannya adalah - tidak bisa. Jika semua konektivitas mati, tidak ada cara untuk membedakan node yang gagal dari jaringan yang gagal. Akibatnya, satu-satunya tindakan aman adalah kedua node menghentikan semua operasi dan menolak
melayani lalu lintas.
Mari kita pikirkan sekarang bagaimana simpul ketiga dapat membantu kita dalam situasi seperti itu.
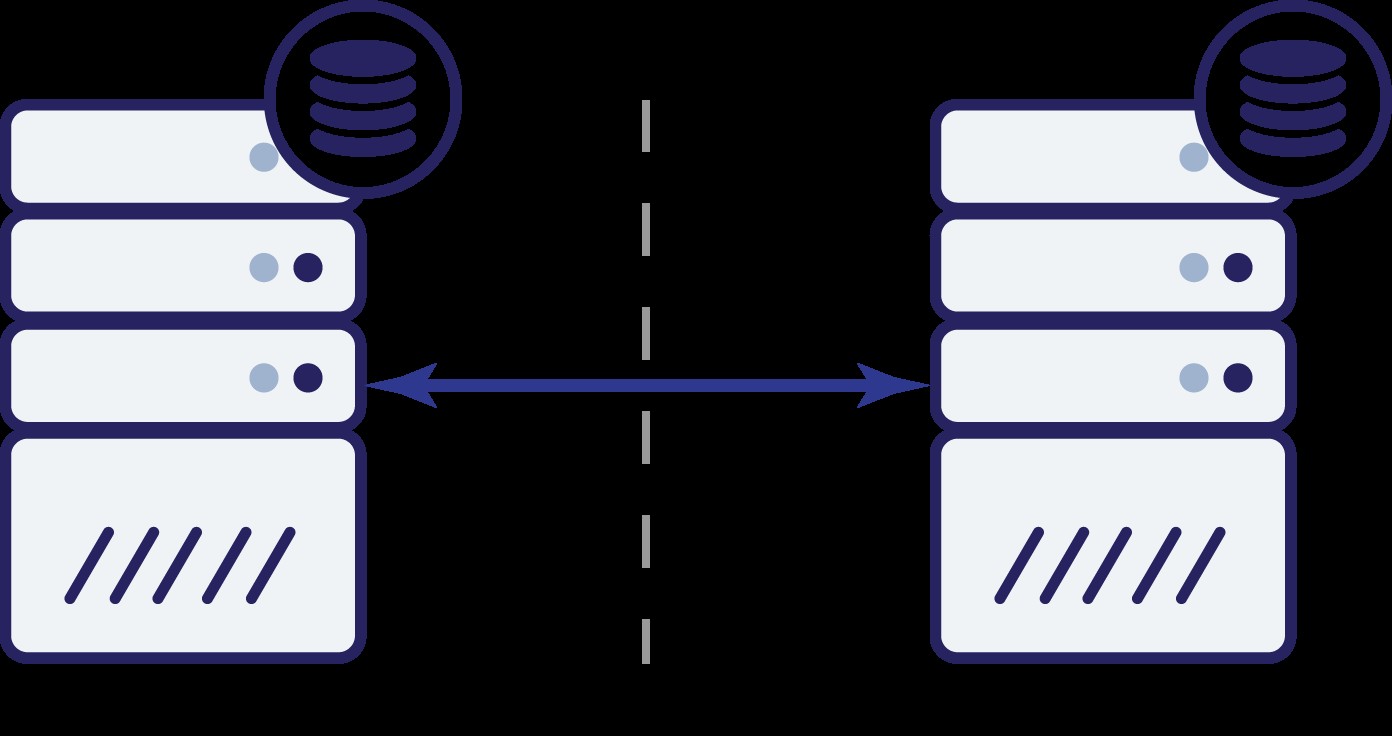
Jadi sekarang kita memiliki tiga node:A, B dan C. Semuanya saling berhubungan, semuanya menangani pembacaan dan penulisan.
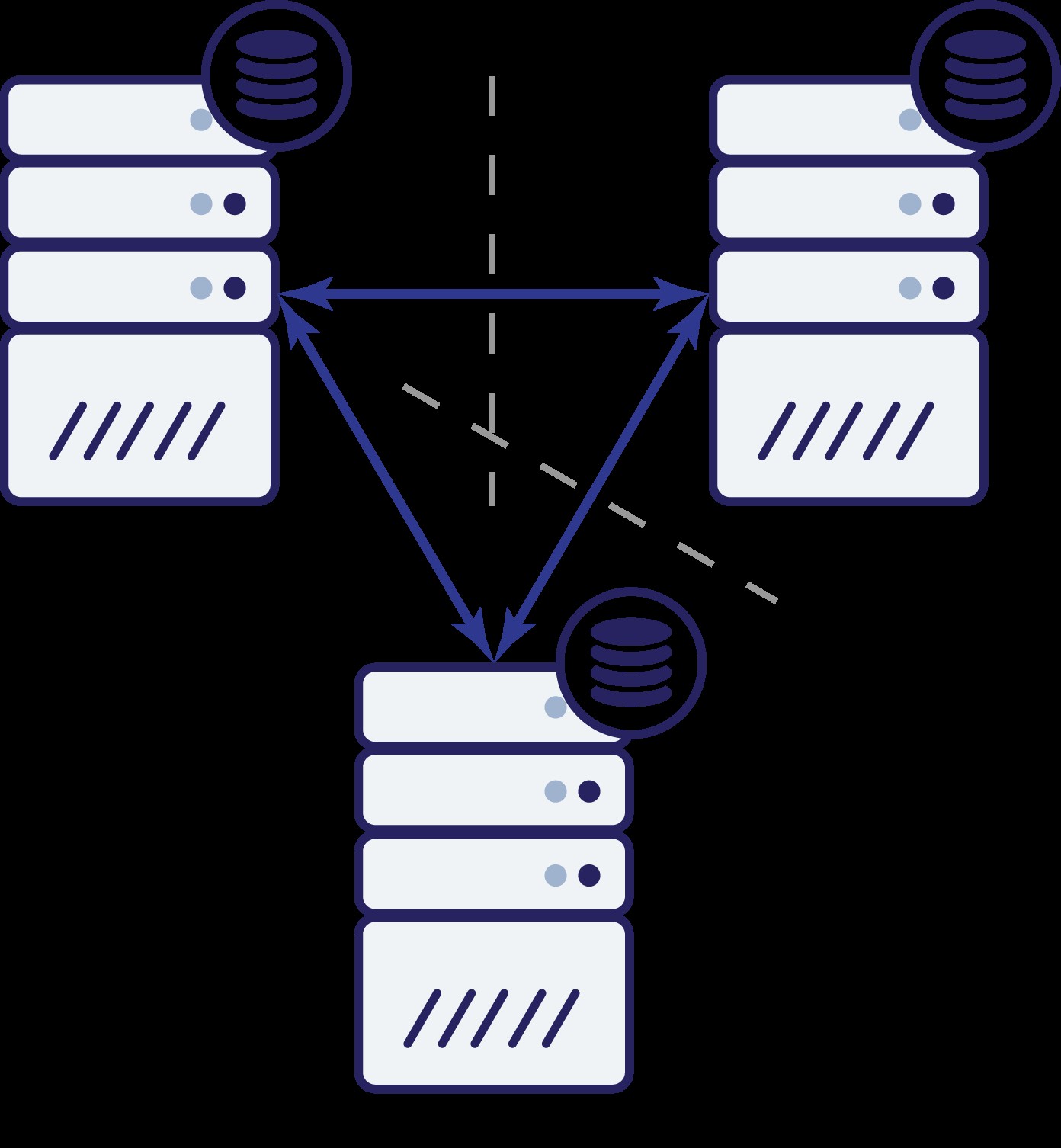
Sekali lagi, seperti pada contoh sebelumnya, node B telah terputus dari cluster lainnya karena masalah jaringan. Apa yang bisa terjadi selanjutnya? Nah, situasinya cukup mirip dengan apa yang kita bahas sebelumnya. Dua opsi - node B bisa down (dan cluster lainnya harus melanjutkan) atau bisa juga up, dalam hal ini node tidak boleh menangani lalu lintas apa pun. Bisakah kita sekarang memberi tahu bagaimana keadaan cluster? Sebenarnya ya. Kita dapat melihat bahwa node A dan C dapat berbicara satu sama lain dan, sebagai hasilnya, mereka dapat menyetujui bahwa node B tidak tersedia. Mereka tidak akan dapat menjelaskan mengapa hal itu terjadi, tetapi yang mereka ketahui adalah bahwa dari tiga node di cluster, dua masih memiliki konektivitas satu sama lain. Mengingat bahwa kedua node tersebut membentuk mayoritas cluster, memungkinkan untuk terus menangani lalu lintas. Pada saat yang sama simpul B juga dapat menyimpulkan bahwa masalahnya ada di pihaknya. Itu tidak dapat mengakses baik node A maupun node C, membuat node B terpisah dari cluster lainnya. Karena terisolasi dan bukan bagian dari mayoritas (1 dari 3), satu-satunya tindakan aman yang dapat dilakukan adalah berhenti melayani lalu lintas dan menolak untuk menerima kueri apa pun, memastikan bahwa penyimpangan data tidak akan terjadi.
Tentu saja, itu tidak berarti Anda hanya dapat memiliki tiga node di cluster. Jika Anda ingin toleransi kegagalan yang lebih baik, Anda mungkin ingin menambahkan lebih banyak. Perlu diingat, meskipun, itu harus menjadi angka ganjil jika Anda ingin meningkatkan ketersediaan tinggi. Juga, kami berbicara tentang "simpul" dalam contoh di atas. Harap diingat bahwa ini juga berlaku untuk pusat data, zona ketersediaan, dll. Jika Anda memiliki dua pusat data, masing-masing memiliki jumlah node yang sama (katakanlah masing-masing tiga node), dan Anda kehilangan konektivitas antara kedua DC tersebut, prinsip yang sama berlaku di sini - Anda tidak dapat membedakan bagian mana dari cluster yang harus mulai menangani lalu lintas. Untuk dapat mengetahuinya, Anda harus memiliki pengamat di pusat data ketiga. Ini bisa berupa kumpulan node lain, atau hanya satu host, dengan tugas
untuk mengamati status sumber data yang tersisa dan mengambil bagian dalam pengambilan keputusan (contoh di sini adalah arbiter Galera).
Satu Poin Kegagalan
Ketersediaan tinggi adalah tentang menghilangkan titik kegagalan tunggal (SPOF) dan tidak memasukkan yang baru dalam proses. Apa itu SPOF? Setiap bagian dari infrastruktur Anda yang, ketika gagal, menyebabkan waktu henti seperti yang didefinisikan dalam SLA, disebut SPOF. Desain infrastruktur membutuhkan pendekatan holistik, komponen yang berbeda tidak dapat dirancang secara independen satu sama lain. Kemungkinan besar, Anda tidak bertanggung jawab atas keseluruhan desain -
administrator basis data cenderung berfokus pada basis data dan bukan, misalnya, lapisan jaringan. Namun, Anda harus mengingat bagian lain dan bekerja dengan tim yang bertanggung jawab untuk mereka, untuk memastikan bahwa tidak hanya bagian yang menjadi tanggung jawab Anda dirancang dengan benar, tetapi juga bagian infrastruktur yang tersisa dirancang menggunakan prinsip yang sama. Selain itu, pengetahuan tentang bagaimana keseluruhan
infrastruktur dirancang, membantu Anda mendesain tumpukan database juga. Mengetahui masalah apa yang mungkin terjadi membantu membangun beberapa mekanisme untuk mencegahnya memengaruhi ketersediaan database.