Apa yang membuat kueri penerapan silang berkinerja sangat buruk pada dokumen XML sederhana ini, dan kinerjanya secara eksponensial lebih lambat seiring bertambahnya kumpulan data?
Ini adalah penggunaan sumbu induk untuk mendapatkan ID atribut dari node item.
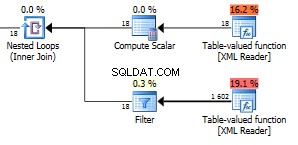
Ini adalah bagian dari rencana kueri yang bermasalah.

Perhatikan 423 baris yang keluar dari fungsi bernilai Tabel yang lebih rendah.
Menambahkan hanya satu simpul item lagi dengan tiga simpul bidang memberi Anda ini.
732 baris dikembalikan.
Bagaimana jika kita menggandakan node dari kueri pertama menjadi total 6 node item?
Kami mencapai 1602 baris kekalahan yang dikembalikan.
Angka 18 di fungsi teratas adalah semua node bidang dalam XML Anda. Kami memiliki 6 item di sini dengan tiga bidang di setiap item. 18 node tersebut digunakan dalam loop bersarang yang digabungkan dengan fungsi lainnya sehingga 18 eksekusi yang mengembalikan 1602 baris memberikan bahwa ia mengembalikan 89 baris per iterasi. Itu kebetulan jumlah yang tepat dari node di seluruh XML. Yah itu sebenarnya satu lebih dari semua node yang terlihat. Saya tidak tahu mengapa. Anda dapat menggunakan kueri ini untuk memeriksa jumlah total node dalam XML Anda.
select count(*)
from @XML.nodes('//*, //@*, //*/text()') as T(X)
Jadi algoritma yang digunakan oleh SQL Server untuk mendapatkan nilai saat Anda menggunakan sumbu induk .. dalam fungsi nilai adalah bahwa ia pertama kali menemukan semua simpul yang Anda hancurkan, 18 dalam kasus terakhir. Untuk setiap node tersebut, ia akan mencabik-cabik dan mengembalikan seluruh dokumen XML dan memeriksa operator filter untuk node yang sebenarnya Anda inginkan. Di sana Anda memiliki pertumbuhan eksponensial. Alih-alih menggunakan sumbu induk, Anda harus menggunakan satu penerapan silang tambahan. Rusak pertama pada item dan kemudian di lapangan.
select I.X.value('@name', 'varchar(5)') as item_name,
F.X.value('@id', 'uniqueidentifier') as field_id,
F.X.value('@type', 'int') as field_type,
F.X.value('text()[1]', 'nvarchar(15)') as field_value
from #temp as T
cross apply T.x.nodes('/data/item') as I(X)
cross apply I.X.nodes('field') as F(X)
Saya juga mengubah cara Anda mengakses nilai teks bidang. Menggunakan . akan membuat SQL Server mencari node anak ke field dan menggabungkan nilai-nilai tersebut dalam hasil. Anda tidak memiliki nilai turunan sehingga hasilnya sama, tetapi sebaiknya hindari bagian tersebut dalam rencana kueri (operator UDX).
Paket kueri tidak memiliki masalah dengan sumbu induk jika Anda menggunakan indeks XML tetapi Anda masih akan mendapat manfaat dari mengubah cara Anda mengambil nilai bidang.