Pengelompokan adalah fitur penting yang membantu mengatur dan mengatur data. Ada banyak cara untuk melakukannya, dan salah satu metode yang paling efektif adalah klausa SQL GROUP BY.
Anda dapat menggunakan SQL GROUP BY untuk membagi baris dalam hasil menjadi grup dengan fungsi agregat . Kedengarannya mudah untuk menjumlahkan, rata-rata, atau menghitung catatan dengannya.
Tapi apakah Anda melakukannya dengan benar?
"Benar" bisa subjektif. Ketika berjalan tanpa kesalahan kritis dengan output yang benar, itu dianggap baik-baik saja. Namun, itu juga harus cepat.
Dalam artikel ini, kecepatan juga akan dipertimbangkan. Anda akan melihat banyak analisis kueri menggunakan pembacaan logis dan rencana eksekusi di semua poin.
Mari kita mulai.
1. Filter Lebih Awal
Jika Anda bingung kapan harus menggunakan WHERE dan HAVING, ini untuk Anda. Karena tergantung pada kondisi yang Anda berikan, keduanya dapat memberikan hasil yang sama.
Tapi mereka berbeda.
HAVING memfilter grup menggunakan kolom dalam klausa SQL GROUP BY. WHERE memfilter baris sebelum pengelompokan dan agregasi terjadi. Jadi, jika Anda memfilter menggunakan klausa HAVING, pengelompokan terjadi untuk semua baris dikembalikan.
Dan itu buruk.
Mengapa? Jawaban singkatnya adalah:lambat. Mari kita buktikan ini dengan 2 pertanyaan. Lihat kode di bawah ini. Sebelum menjalankannya di SQL Server Management Studio, tekan Ctrl-M terlebih dahulu.
SET STATISTICS IO ON
GO
-- using WHERE
SELECT
MONTH(soh.OrderDate) AS OrderMonth
,YEAR(soh.OrderDate) AS OrderYear
,p.Name AS Product
,SUM(sod.LineTotal) AS ProductSales
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID
INNER join Production.Product p ON sod.ProductID = p.ProductID
WHERE soh.OrderDate BETWEEN '01/01/2012' AND '12/31/2012'
GROUP BY p.Name, YEAR(soh.OrderDate), MONTH(soh.OrderDate)
ORDER BY Product, OrderYear, OrderMonth;
-- using HAVING
SELECT
MONTH(soh.OrderDate) AS OrderMonth
,YEAR(soh.OrderDate) AS OrderYear
,p.Name AS Product
,SUM(sod.LineTotal) AS ProductSales
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID
INNER join Production.Product p ON sod.ProductID = p.ProductID
GROUP BY p.Name, YEAR(soh.OrderDate), MONTH(soh.OrderDate)
HAVING YEAR(soh.OrderDate) = 2012
ORDER BY Product, OrderYear, OrderMonth;
SET STATISTICS IO OFF
GO
Analisis
2 pernyataan SELECT di atas akan mengembalikan baris yang sama. Keduanya benar dalam mengembalikan pesanan produk berdasarkan bulan di tahun 2012. Tetapi SELECT pertama membutuhkan waktu 136ms. untuk dijalankan di laptop saya, sementara laptop lain membutuhkan waktu 764 md.!
Mengapa?
Mari kita periksa pembacaan logis terlebih dahulu pada Gambar 1. STATISTICS IO mengembalikan hasil ini. Kemudian, saya menempelkannya ke StatisticsParser.com untuk output yang diformat.
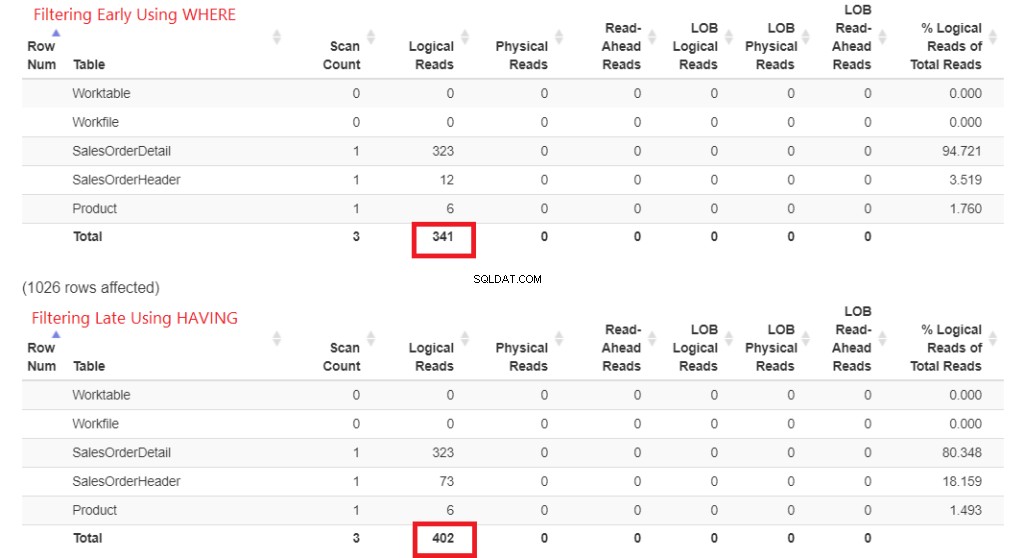
Gambar 1 . Pembacaan logis dari pemfilteran lebih awal menggunakan WHERE vs. pemfilteran terlambat menggunakan HAVING.
Lihatlah total pembacaan logis masing-masing. Untuk memahami angka-angka ini, semakin logis pembacaan yang dibutuhkan, semakin lambat kuerinya. Jadi, ini membuktikan bahwa menggunakan HAVING lebih lambat, dan memfilter lebih awal dengan WHERE lebih cepat.
Tentu saja, ini tidak berarti bahwa MEMILIKI tidak ada gunanya. Satu pengecualian adalah saat menggunakan HAVING dengan agregat seperti HAVING SUM(sod.Linetotal)> 100000 . Anda dapat menggabungkan klausa WHERE dan klausa HAVING dalam satu kueri.
Lihat rencana eksekusi pada Gambar 2.
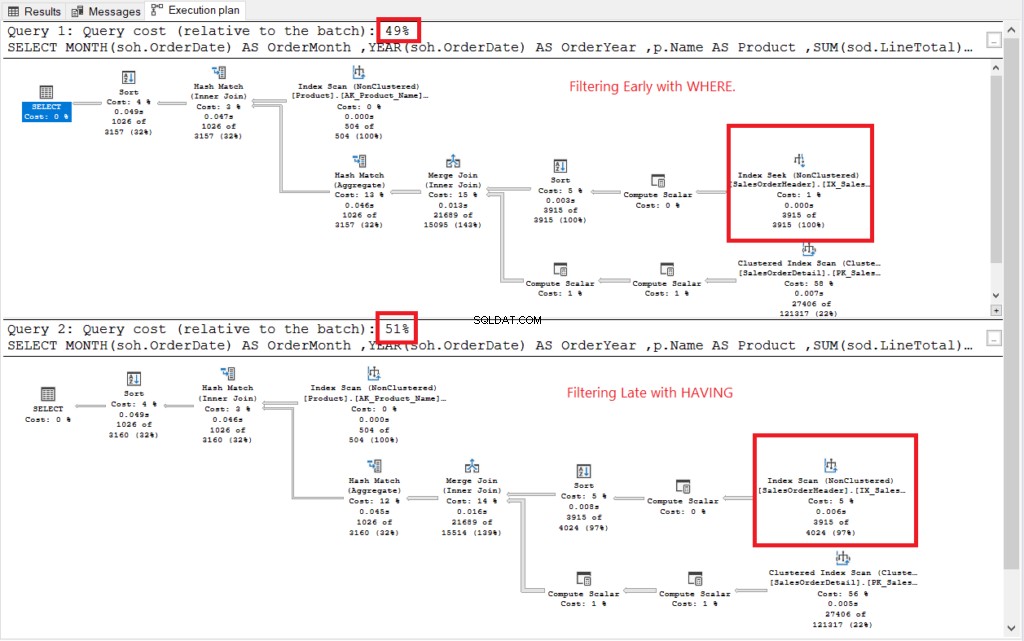
Gambar 2 . Rencana eksekusi pemfilteran lebih awal vs. pemfilteran terlambat.
Kedua rencana eksekusi tampak serupa kecuali yang berkotak merah. Pemfilteran awal menggunakan operator Pencarian Indeks sementara yang lain menggunakan Pemindaian Indeks. Pencarian lebih cepat daripada pemindaian di tabel besar.
Tidak te: Memfilter lebih awal memiliki biaya yang lebih rendah daripada menyaring yang terlambat. Jadi, intinya memfilter baris lebih awal dapat meningkatkan kinerja.
2. Grup Dulu, Gabung Nanti
Bergabung dengan beberapa tabel yang Anda butuhkan nanti juga dapat meningkatkan kinerja.
Katakanlah Anda ingin memiliki penjualan produk bulanan. Anda juga perlu mendapatkan nama produk, nomor, dan subkategori semuanya dalam kueri yang sama. Kolom ini ada di tabel lain. Dan mereka semua perlu ditambahkan dalam klausa GROUP BY agar eksekusi berhasil. Ini kodenya.
SET STATISTICS IO ON
GO
SELECT
p.Name AS Product
,p.ProductNumber
,ps.Name AS ProductSubcategory
,SUM(sod.LineTotal) AS ProductSales
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID
INNER JOIN Production.Product p ON sod.ProductID = p.ProductID
INNER JOIN Production.ProductSubcategory ps ON p.ProductSubcategoryID = ps.ProductSubcategoryID
WHERE soh.OrderDate BETWEEN '01/01/2012' AND '12/31/2012'
GROUP BY p.name, p.ProductNumber, ps.Name
ORDER BY Product
SET STATISTICS IO OFF
GO
Ini akan berjalan dengan baik. Tapi ada cara yang lebih baik dan lebih cepat. Ini tidak akan mengharuskan Anda untuk menambahkan 3 kolom untuk nama produk, nomor, dan subkategori dalam klausa GROUP BY. Padahal, ini akan membutuhkan lebih banyak penekanan tombol. Ini dia.
SET STATISTICS IO ON
GO
;WITH Orders2012 AS
(
SELECT
sod.ProductID
,SUM(sod.LineTotal) AS ProductSales
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID
WHERE soh.OrderDate BETWEEN '01/01/2012' AND '12/31/2012'
GROUP BY sod.ProductID
)
SELECT
P.Name AS Product
,P.ProductNumber
,ps.Name AS ProductSubcategory
,o.ProductSales
FROM Orders2012 o
INNER JOIN Production.Product p ON o.ProductID = p.ProductID
INNER JOIN Production.ProductSubcategory ps ON p.ProductSubcategoryID = ps.ProductSubcategoryID
ORDER BY Product;
SET STATISTICS IO OFF
GO
Analisis
Mengapa ini lebih cepat? Gabungan ke Produk dan Subkategori Produk dilakukan kemudian. Keduanya tidak terlibat dalam klausa GROUP BY. Mari kita buktikan ini dengan angka-angka di STATISTICS IO. Lihat Gambar 4.
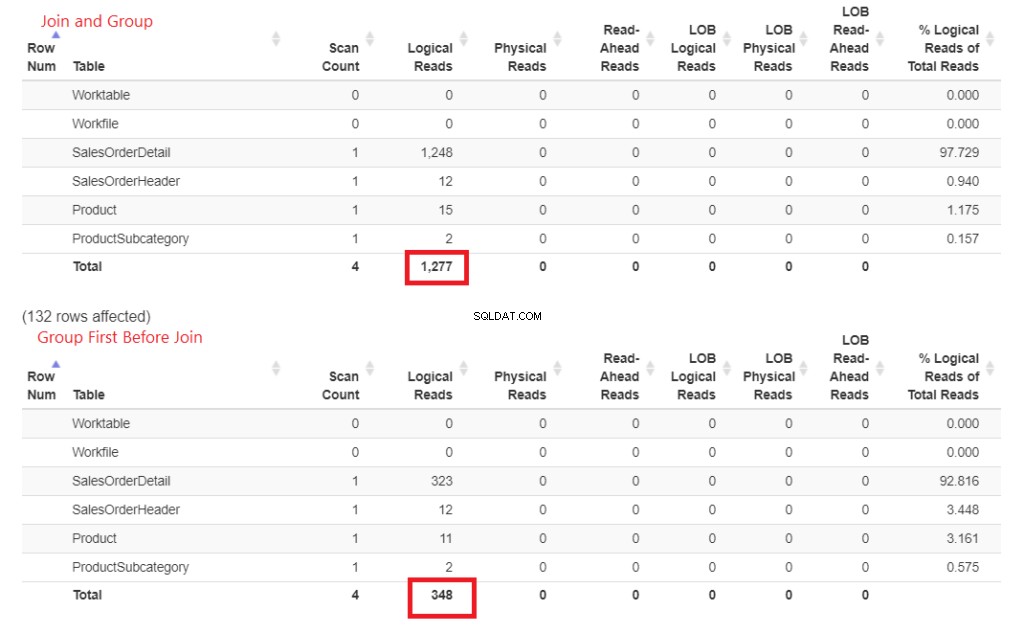
Gambar 3 . Bergabung lebih awal lalu pengelompokan menghabiskan lebih banyak pembacaan logis daripada melakukan penggabungan nanti.
Lihat bacaan logis itu? Perbedaannya jauh, dan pemenangnya sudah jelas.
Mari kita bandingkan rencana eksekusi dari 2 kueri untuk melihat alasan di balik angka-angka di atas. Pertama, lihat Gambar 4 untuk rencana eksekusi kueri dengan semua tabel bergabung saat dikelompokkan.
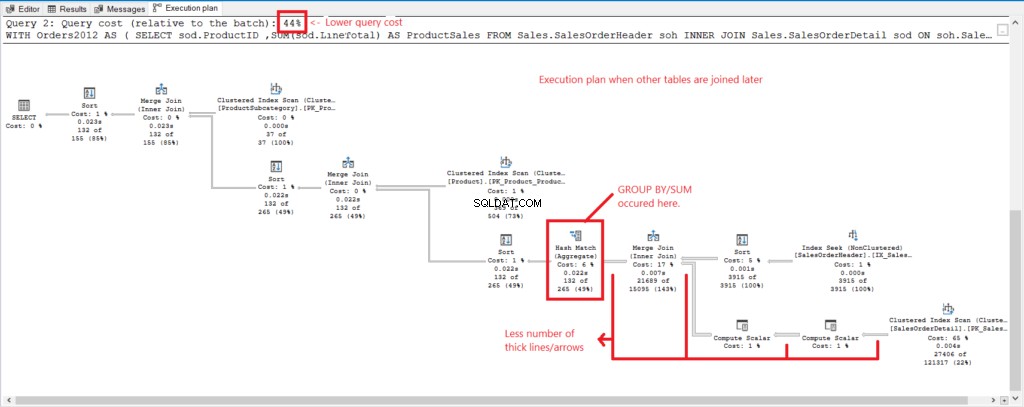
Gambar 4 . Rencana eksekusi saat semua tabel digabungkan.
Dan kami memiliki pengamatan berikut:
- GROUP BY dan SUM selesai terlambat dalam proses setelah menggabungkan semua tabel.
- Banyak garis dan panah yang lebih tebal – ini menjelaskan 1.277 pembacaan logis.
- Penggabungan 2 kueri membentuk 100% biaya kueri. Namun paket kueri ini memiliki biaya kueri yang lebih tinggi (56%).
Nah, ini dia rencana eksekusinya saat kita group dulu, dan bergabung dengan Product dan Subkategori Produk tabel nanti. Lihat Gambar 5.
Gambar 5 . Rencana eksekusi ketika grup pertama, bergabung kemudian selesai.
Dan kami memiliki pengamatan berikut pada Gambar 5.
- GROUP BY dan SUM selesai lebih awal.
- Lebih sedikit garis tebal dan panah – ini menjelaskan 348 pembacaan logis saja.
- Biaya kueri lebih rendah (44%).
3. Kelompokkan Kolom Terindeks
Setiap kali SQL GROUP BY dilakukan pada kolom, kolom itu harus memiliki indeks. Anda akan meningkatkan kecepatan eksekusi setelah Anda mengelompokkan kolom dengan indeks. Mari ubah kueri sebelumnya dan gunakan tanggal pengiriman alih-alih tanggal pemesanan. Kolom tanggal pengiriman tidak memiliki indeks di SalesOrderHeader .
SET STATISTICS IO ON
GO
SELECT
MONTH(soh.ShipDate) AS ShipMonth
,YEAR(soh.ShipDate) AS ShipYear
,p.Name AS Product
,SUM(sod.LineTotal) AS ProductSales
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID
INNER join Production.Product p ON sod.ProductID = p.ProductID
WHERE soh.ShipDate BETWEEN '01/01/2012' AND '12/31/2012'
GROUP BY p.Name, YEAR(soh.ShipDate), MONTH(soh.ShipDate)
ORDER BY Product, ShipYear, ShipMonth;
SET STATISTICS IO OFF
GO
Tekan Ctrl-M, lalu jalankan kueri di atas di SSMS. Kemudian, buat indeks non-cluster pada ShipDate kolom. Perhatikan pembacaan logis dan rencana eksekusi. Terakhir, jalankan kembali kueri di atas di tab kueri lain. Perhatikan perbedaan dalam pembacaan logis dan rencana eksekusi.
Berikut perbandingan pembacaan logika pada Gambar 6.
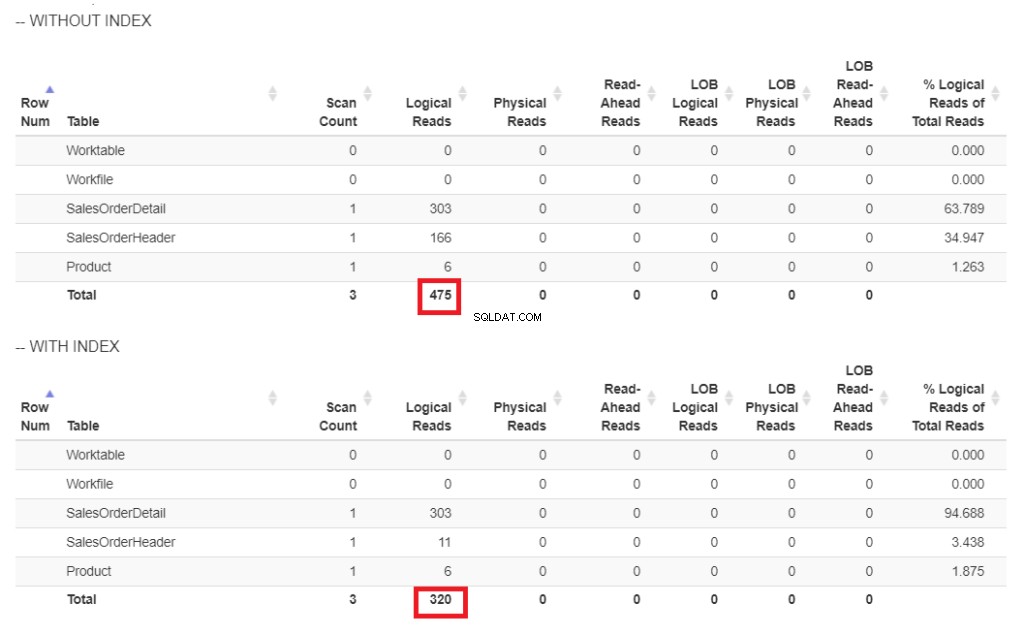
Gambar 6 . Pembacaan logis dari contoh kueri kami dengan dan tanpa indeks pada TanggalPengiriman.
Pada Gambar 6, ada pembacaan logis yang lebih tinggi dari kueri tanpa indeks pada ShipDate .
Sekarang mari kita buat rencana eksekusi ketika tidak ada indeks pada ShipDate ada pada Gambar 7.
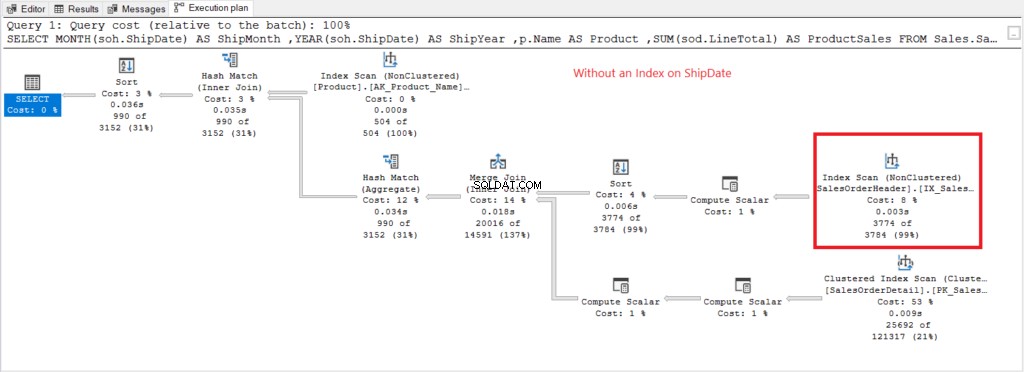
Gambar 7 . Rencana eksekusi saat menggunakan GROUP BY pada Tanggal Pengiriman tidak diindeks.
Pemindaian Indeks operator yang digunakan dalam rencana pada Gambar 7 menjelaskan pembacaan logis yang lebih tinggi (475). Berikut adalah rencana eksekusi setelah mengindeks ShipDate kolom.
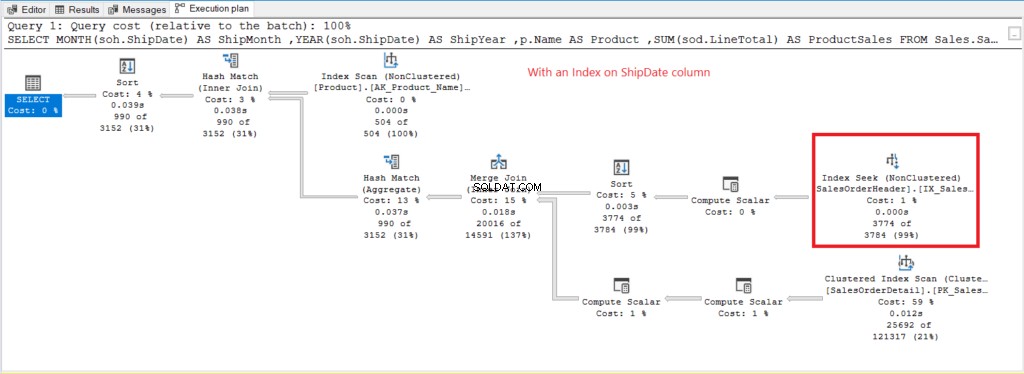
Gambar 8 . Rencana eksekusi saat menggunakan GROUP BY pada ShipDate yang diindeks.
Alih-alih Pemindaian Indeks, Pencarian Indeks digunakan setelah mengindeks ShipDate kolom. Ini menjelaskan pembacaan logis yang lebih rendah pada Gambar 6.
Jadi, untuk meningkatkan kinerja saat menggunakan GROUP BY, pertimbangkan untuk mengindeks kolom yang Anda gunakan untuk pengelompokan.
Ingat dalam Menggunakan SQL GROUP BY
SQL GROUP BY mudah digunakan. Tetapi Anda perlu mengambil langkah berikutnya untuk lebih dari sekadar meringkas data untuk laporan. Ini poinnya lagi:
- Filter lebih awal . Hapus baris yang tidak perlu Anda rangkum menggunakan klausa WHERE alih-alih klausa HAVING.
- Grup dulu, gabung nanti . Terkadang, akan ada kolom yang perlu Anda tambahkan selain dari kolom yang Anda kelompokkan. Daripada memasukkannya ke dalam klausa GROUP BY, bagi kueri dengan CTE, dan gabungkan tabel lain nanti.
- Gunakan GROUP BY dengan kolom yang diindeks . Hal dasar ini mungkin berguna ketika database secepat siput.
Semoga ini membantu Anda meningkatkan level permainan Anda dalam mengelompokkan hasil.
Jika Anda menyukai postingan ini, silakan bagikan di platform media sosial favorit Anda.



