Selama bertahun-tahun, replikasi MySQL dulunya didasarkan pada peristiwa log biner - semua budak tahu adalah peristiwa yang tepat dan posisi yang tepat yang baru saja dibaca dari master. Setiap transaksi tunggal dari master mungkin telah berakhir di log biner yang berbeda, dan di posisi yang berbeda di log ini. Itu adalah solusi sederhana yang datang dengan keterbatasan - perubahan topologi yang lebih kompleks dapat mengharuskan admin untuk menghentikan replikasi pada host yang terlibat. Atau perubahan ini dapat menyebabkan beberapa masalah lain, misalnya, budak tidak dapat dipindahkan ke rantai replikasi tanpa proses pembangunan kembali yang memakan waktu (kami tidak dapat dengan mudah mengubah replikasi dari A -> B -> C ke A -> C -> B tanpa menghentikan replikasi pada B dan C). Kita semua harus mengatasi keterbatasan ini sambil memimpikan pengenal transaksi global.
GTID diperkenalkan bersama dengan MySQL 5.6, dan membawa beberapa perubahan besar dalam cara MySQL beroperasi. Pertama-tama, setiap transaksi memiliki pengidentifikasi unik yang mengidentifikasinya dengan cara yang sama di setiap server. Tidak penting lagi di mana posisi log biner suatu transaksi dicatat, yang perlu Anda ketahui hanyalah GTID:'966073f3-b6a4-11e4-af2c-080027880ca6:4'. GTID dibangun dari dua bagian - pengidentifikasi unik server tempat transaksi pertama kali dieksekusi, dan nomor urut. Pada contoh di atas, kita dapat melihat bahwa transaksi dijalankan oleh server dengan server_uuid dari ‘966073f3-b6a4-11e4-af2c-080027880ca6’ dan transaksi ke-4 dilakukan di sana. Informasi ini cukup untuk melakukan perubahan topologi yang kompleks - MySQL tahu transaksi mana yang telah dieksekusi dan oleh karena itu tahu transaksi mana yang perlu dieksekusi selanjutnya. Lupakan log biner, semuanya ada di GTID.
Jadi, di mana Anda dapat menemukan GTID? Anda akan menemukannya di dua tempat. Pada budak, di 'tampilkan status budak;' Anda akan menemukan dua kolom:Retrieved_Gtid_Set dan Executed_Gtid_Set. Yang pertama mencakup GTID yang diambil dari master melalui replikasi, yang kedua menginformasikan tentang semua transaksi yang dijalankan pada host yang diberikan - baik melalui replikasi atau dieksekusi secara lokal.
Menyiapkan Cluster Replikasi dengan cara Mudah
Deployment cluster replikasi MySQL sangat mudah di ClusterControl (Anda dapat mencobanya secara gratis). Satu-satunya prasyarat adalah bahwa semua host, yang akan Anda gunakan untuk menyebarkan node MySQL, dapat diakses dari instance ClusterControl menggunakan koneksi SSH tanpa kata sandi.
Saat konektivitas tersedia, Anda dapat menerapkan cluster dengan menggunakan opsi “Deploy”. Ketika jendela wizard terbuka, Anda perlu membuat beberapa keputusan - apa yang ingin Anda lakukan? Terapkan cluster baru? Deploy node Postgresql atau impor cluster yang ada.
Kami ingin men-deploy cluster baru. Kami kemudian akan disajikan dengan layar berikut di mana kami perlu memutuskan jenis cluster apa yang ingin kami gunakan. Mari pilih replikasi lalu berikan detail yang diperlukan tentang konektivitas ssh.
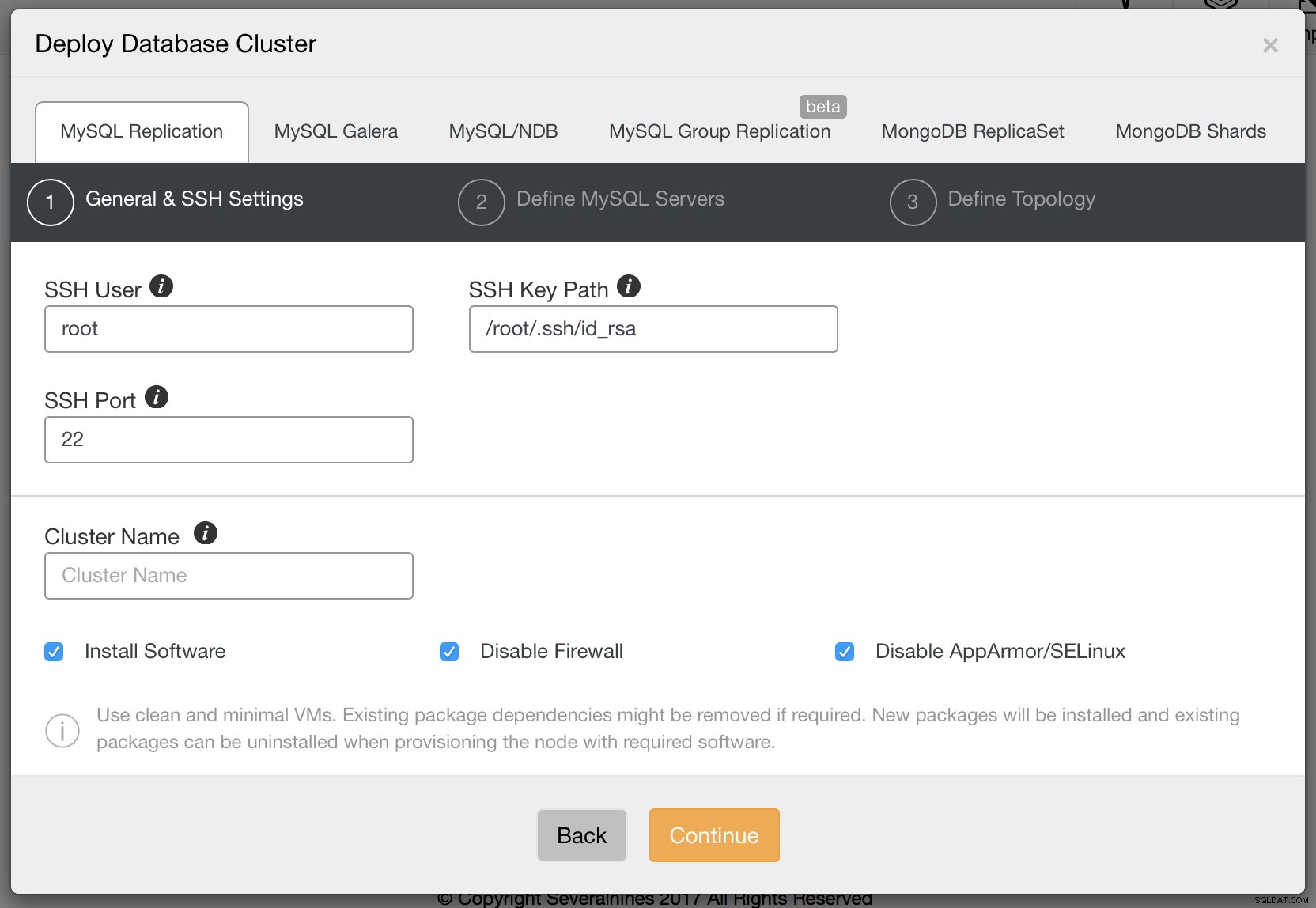
Jika sudah siap, klik Lanjutkan. Kali ini kita perlu memutuskan vendor MySQL mana yang ingin kita gunakan, versi apa dan beberapa pengaturan konfigurasi termasuk, antara lain, kata sandi untuk akun root di MySQL.
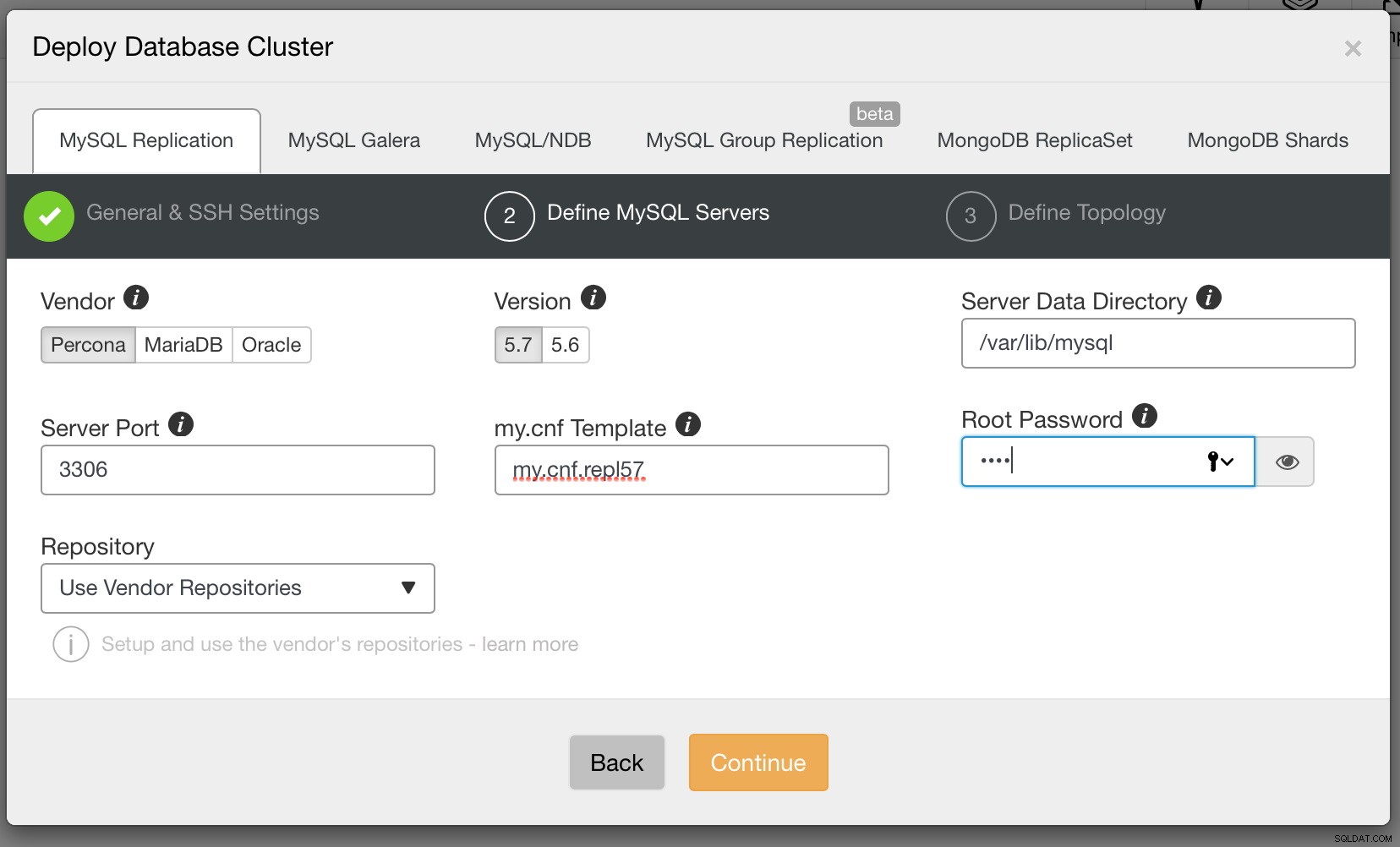
Terakhir, kita perlu memutuskan topologi replikasi - Anda dapat menggunakan master tipikal - pengaturan slave atau membuat pasangan master - master siaga aktif yang lebih kompleks (+ slave jika Anda ingin menambahkannya). Setelah siap, cukup klik “Deploy” dan dalam beberapa menit cluster Anda akan di-deploy.
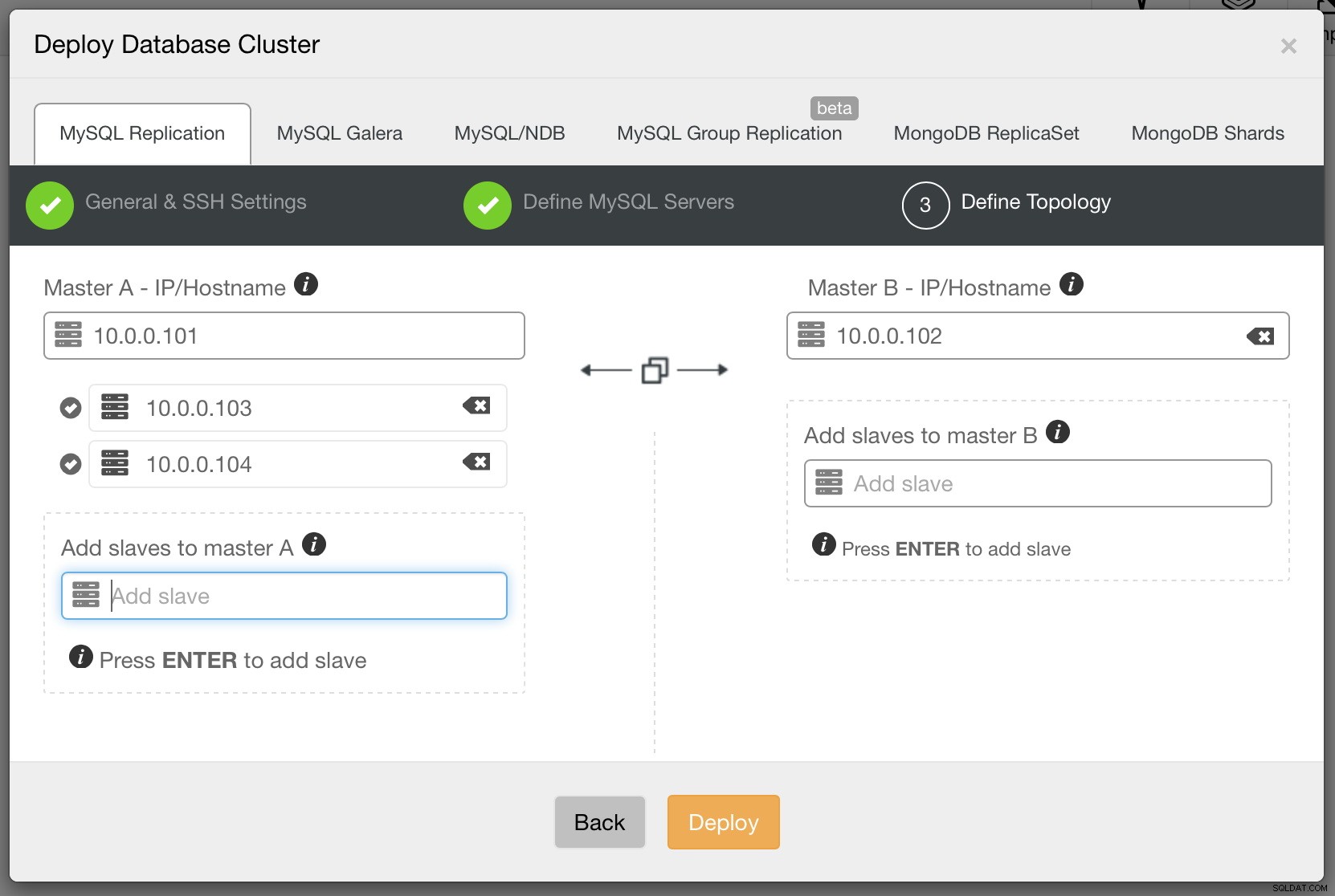
Setelah ini selesai, Anda akan melihat cluster Anda di daftar cluster UI ClusterControl.
Setelah replikasi berjalan, kita dapat melihat lebih dekat cara kerja GTID.
Transaksi salah - apa masalahnya?
Seperti yang kami sebutkan di awal posting ini, GTID membawa perubahan signifikan dalam cara orang berpikir tentang replikasi MySQL. Ini semua tentang kebiasaan. Katakanlah, untuk beberapa alasan, bahwa aplikasi melakukan penulisan pada salah satu budak. Seharusnya tidak terjadi tetapi mengejutkan, itu terjadi sepanjang waktu. Akibatnya, replikasi berhenti dengan kesalahan kunci duplikat. Ada beberapa cara untuk mengatasi masalah seperti itu. Salah satunya adalah menghapus baris yang menyinggung dan memulai ulang replikasi. Yang lainnya adalah melewati peristiwa log biner dan kemudian memulai ulang replikasi.
STOP SLAVE SQL_THREAD; SET GLOBAL sql_slave_skip_counter = 1; START SLAVE SQL_THREAD;Kedua cara tersebut akan mengembalikan replikasi ke pekerjaan, tetapi mereka dapat memperkenalkan penyimpangan data sehingga perlu diingat bahwa konsistensi slave harus diperiksa setelah peristiwa tersebut (pt-table-checksum dan pt-table-sync bekerja dengan baik di sini).
Jika masalah serupa terjadi saat menggunakan GTID, Anda akan melihat beberapa perbedaan. Menghapus baris yang menyinggung mungkin tampaknya memperbaiki masalah, replikasi harus dapat dimulai. Metode lainnya, menggunakan sql_slave_skip_counter tidak akan berfungsi sama sekali - ini akan mengembalikan kesalahan. Ingat, sekarang ini bukan tentang peristiwa binlog, ini semua tentang GTID yang dijalankan atau tidak.
Mengapa menghapus baris hanya 'sepertinya' untuk memperbaiki masalah? Salah satu hal yang paling penting untuk diingat mengenai GTID adalah bahwa seorang budak, saat menghubungkan ke master, memeriksa apakah ada transaksi yang hilang yang dijalankan pada master. Ini disebut transaksi yang salah. Jika seorang budak menemukan transaksi seperti itu, ia akan mengeksekusinya. Mari kita asumsikan kita menjalankan SQL berikut untuk menghapus baris yang menyinggung:
DELETE FROM mytable WHERE id=100;Mari kita periksa tampilkan status budak:
Master_UUID: 966073f3-b6a4-11e4-af2c-080027880ca6
Retrieved_Gtid_Set: 966073f3-b6a4-11e4-af2c-080027880ca6:1-29
Executed_Gtid_Set: 84d15910-b6a4-11e4-af2c-080027880ca6:1,
966073f3-b6a4-11e4-af2c-080027880ca6:1-29,Dan lihat dari mana asal 84d15910-b6a4-11e4-af2c-080027880ca6:1:
mysql> SHOW VARIABLES LIKE 'server_uuid'\G
*************************** 1. row ***************************
Variable_name: server_uuid
Value: 84d15910-b6a4-11e4-af2c-080027880ca6
1 row in set (0.00 sec)Seperti yang Anda lihat, kami memiliki 29 transaksi yang berasal dari master, UUID 966073f3-b6a4-11e4-af2c-080027880ca6 dan satu yang dieksekusi secara lokal. Katakanlah pada titik tertentu kita failover dan master (966073f3-b6a4-11e4-af2c-080027880ca6) menjadi budak. Ini akan memeriksa daftar GTID yang dieksekusi dan tidak akan menemukan yang ini:84d15910-b6a4-11e4-af2c-080027880ca6:1. Akibatnya, SQL terkait akan dieksekusi:
DELETE FROM mytable WHERE id=100;Ini bukan sesuatu yang kami harapkan… Jika, sementara itu, binlog yang berisi transaksi ini akan dihapus dari slave lama, maka slave baru akan mengeluh setelah failover:
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'The slave is connecting using CHANGE MASTER TO MASTER_AUTO_POSITION = 1, but the master has purged binary logs containing GTIDs that the slave requires.'Bagaimana cara mendeteksi transaksi yang salah?
MySQL menyediakan dua fungsi yang sangat berguna ketika Anda ingin membandingkan set GTID pada host yang berbeda.
GTID_SUBSET() mengambil dua set GTID dan memeriksa apakah set pertama adalah subset dari yang kedua.
Katakanlah kita memiliki status berikut.
Guru:
mysql> show master status\G
*************************** 1. row ***************************
File: binlog.000002
Position: 160205927
Binlog_Do_DB:
Binlog_Ignore_DB:
Executed_Gtid_Set: 8a6962d2-b907-11e4-bebc-080027880ca6:1-153,
9b09b44a-b907-11e4-bebd-080027880ca6:1,
ab8f5793-b907-11e4-bebd-080027880ca6:1-2
1 row in set (0.00 sec)Budak:
mysql> show slave status\G
[...]
Retrieved_Gtid_Set: 8a6962d2-b907-11e4-bebc-080027880ca6:1-153,
9b09b44a-b907-11e4-bebd-080027880ca6:1
Executed_Gtid_Set: 8a6962d2-b907-11e4-bebc-080027880ca6:1-153,
9b09b44a-b907-11e4-bebd-080027880ca6:1,
ab8f5793-b907-11e4-bebd-080027880ca6:1-4Kita dapat memeriksa apakah slave memiliki transaksi yang salah dengan menjalankan SQL berikut:
mysql> SELECT GTID_SUBSET('8a6962d2-b907-11e4-bebc-080027880ca6:1-153,ab8f5793-b907-11e4-bebd-080027880ca6:1-4', '8a6962d2-b907-11e4-bebc-080027880ca6:1-153, 9b09b44a-b907-11e4-bebd-080027880ca6:1, ab8f5793-b907-11e4-bebd-080027880ca6:1-2') as is_subset\G
*************************** 1. row ***************************
is_subset: 0
1 row in set (0.00 sec)Sepertinya ada transaksi yang salah. Bagaimana kita mengidentifikasi mereka? Kita bisa menggunakan fungsi lain, GTID_SUBTRACT()
mysql> SELECT GTID_SUBTRACT('8a6962d2-b907-11e4-bebc-080027880ca6:1-153,ab8f5793-b907-11e4-bebd-080027880ca6:1-4', '8a6962d2-b907-11e4-bebc-080027880ca6:1-153, 9b09b44a-b907-11e4-bebd-080027880ca6:1, ab8f5793-b907-11e4-bebd-080027880ca6:1-2') as mising\G
*************************** 1. row ***************************
mising: ab8f5793-b907-11e4-bebd-080027880ca6:3-4
1 row in set (0.01 sec)GTID kami yang hilang adalah ab8f5793-b907-11e4-bebd-080027880ca6:3-4 - transaksi tersebut dieksekusi pada slave tetapi tidak pada master.
Bagaimana mengatasi masalah yang disebabkan oleh transaksi yang salah?
Ada dua cara - memasukkan transaksi kosong atau mengecualikan transaksi dari riwayat GTID.
Untuk menyuntikkan transaksi kosong kita dapat menggunakan SQL berikut:
mysql> SET gtid_next='ab8f5793-b907-11e4-bebd-080027880ca6:3';
Query OK, 0 rows affected (0.01 sec)mysql> begin ; commit;
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected (0.01 sec)mysql> SET gtid_next='ab8f5793-b907-11e4-bebd-080027880ca6:4';
Query OK, 0 rows affected (0.00 sec)mysql> begin ; commit;
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected (0.01 sec)mysql> SET gtid_next=automatic;
Query OK, 0 rows affected (0.00 sec)Ini harus dijalankan pada setiap host dalam topologi replikasi yang tidak menjalankan GTID tersebut. Jika master tersedia, Anda dapat menyuntikkan transaksi tersebut di sana dan membiarkannya mereplikasi rantai. Jika master tidak tersedia (misalnya, crash), transaksi kosong tersebut harus dijalankan pada setiap slave. Oracle mengembangkan alat yang disebut mysqlslavetrx yang dirancang untuk mengotomatisasi proses ini.
Pendekatan lain adalah menghapus GTID dari riwayat:
Hentikan budak:
mysql> STOP SLAVE;Cetak Executed_Gtid_Set pada slave:
mysql> SHOW MASTER STATUS\GSetel ulang info GTID:
RESET MASTER;Setel GTID_PURGED ke set GTID yang benar. berdasarkan data dari SHOW MASTER STATUS. Anda harus mengecualikan transaksi yang salah dari set.
SET GLOBAL GTID_PURGED='8a6962d2-b907-11e4-bebc-080027880ca6:1-153, 9b09b44a-b907-11e4-bebd-080027880ca6:1, ab8f5793-b907-11e4-bebd-080027880ca6:1-2';Mulai budak.
mysql> START SLAVE\GDalam setiap kasus, Anda harus memverifikasi konsistensi slave Anda menggunakan pt-table-checksum dan pt-table-sync (jika diperlukan) - transaksi yang salah dapat mengakibatkan penyimpangan data.
Kegagalan di ClusterControl
Mulai dari versi 1.4, ClusterControl meningkatkan proses penanganan failover untuk Replikasi MySQL. Anda masih dapat melakukan sakelar master manual dengan mempromosikan salah satu budak ke master. Sisa budak kemudian akan beralih ke master baru. Dari versi 1.4, ClusterControl juga memiliki kemampuan untuk melakukan failover otomatis sepenuhnya jika master gagal. Kami membahasnya secara mendalam dalam posting blog yang menjelaskan ClusterControl dan failover otomatis. Kami masih ingin menyebutkan satu fitur, yang terkait langsung dengan topik postingan ini.
Secara default, ClusterControl melakukan failover dengan "cara yang aman" - pada saat failover (atau peralihan, jika pengguna yang mengeksekusi master switch), ClusterControl memilih kandidat master dan kemudian memverifikasi bahwa node ini tidak memiliki transaksi yang salah yang akan berdampak pada replikasi setelah dipromosikan menjadi master. Jika transaksi yang salah terdeteksi, ClusterControl akan menghentikan proses failover dan kandidat master tidak akan dipromosikan menjadi master baru.
Jika Anda ingin 100% yakin bahwa ClusterControl akan mempromosikan master baru bahkan jika beberapa masalah (seperti transaksi yang salah) terdeteksi, Anda dapat melakukannya dengan menggunakan pengaturan replica_stop_on_error=0 dalam konfigurasi cmon. Tentu saja, seperti yang telah kita diskusikan, ini dapat menyebabkan masalah dengan replikasi - slave mungkin mulai meminta peristiwa log biner yang tidak tersedia lagi.
Untuk menangani kasus seperti itu, kami menambahkan dukungan eksperimental untuk pembangunan kembali budak. Jika Anda mengatur replikasi_auto_rebuild_slave=1 dalam konfigurasi cmon dan slave Anda ditandai sebagai down dengan kesalahan berikut di MySQL, ClusterControl akan mencoba membangun kembali slave menggunakan data dari master:
Mendapat kesalahan fatal 1236 dari master saat membaca data dari log biner:'Budak terhubung menggunakan CHANGE MASTER TO MASTER_AUTO_POSITION =1, tetapi master telah menghapus log biner yang berisi GTID yang dibutuhkan budak.'
Pengaturan seperti itu mungkin tidak selalu tepat karena proses pembangunan kembali akan menyebabkan peningkatan beban pada master. Mungkin juga kumpulan data Anda sangat besar dan pembangunan kembali reguler bukanlah opsi - itulah sebabnya perilaku ini dinonaktifkan secara default.