Saya kira alasannya adalah mereka tidak menganggap ini sebagai fitur prioritas yang layak untuk diterapkan. Sepertinya Postgres ada dukung keduanya
UNION dan UNION ALL .
Jika Anda memiliki alasan kuat untuk fitur ini, Anda dapat memberikan masukan di Hubungkan (atau apa pun URL penggantinya).
Mencegah duplikat ditambahkan dapat berguna karena baris duplikat yang ditambahkan di langkah selanjutnya ke baris sebelumnya hampir selalu berakhir dengan loop tak terbatas atau melebihi batas rekursi maksimum.
Ada beberapa tempat di Standar SQL
di mana kode digunakan menunjukkan UNION seperti di bawah ini
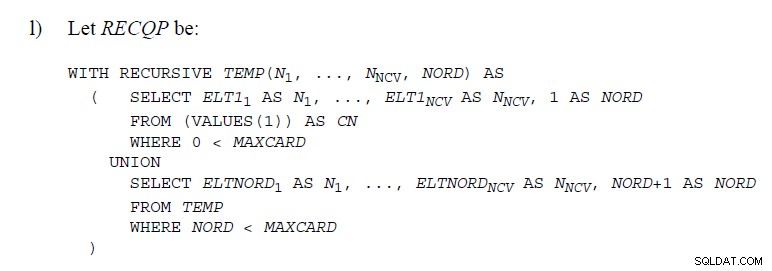
Artikel ini menjelaskan bagaimana mereka diimplementasikan di SQL Server . Mereka tidak melakukan hal seperti itu "di bawah tenda". Spool tumpukan menghapus baris saat berjalan sehingga tidak mungkin untuk mengetahui apakah baris selanjutnya adalah duplikat dari yang dihapus. Mendukung UNION akan membutuhkan pendekatan yang agak berbeda.
Sementara itu, Anda dapat dengan mudah mencapai hal yang sama dalam TVF multi-pernyataan.
Untuk mengambil contoh konyol di bawah ini (Postgres Fiddle )
WITH R
AS (SELECT 0 AS N
UNION
SELECT ( N + 1 )%10
FROM R)
SELECT N
FROM R
Mengubah UNION ke UNION ALL dan menambahkan DISTINCT pada akhirnya tidak akan menyelamatkan Anda dari rekursi tak terbatas.
Tetapi Anda dapat menerapkan ini sebagai
CREATE FUNCTION dbo.F ()
RETURNS @R TABLE(n INT PRIMARY KEY WITH (IGNORE_DUP_KEY = ON))
AS
BEGIN
INSERT INTO @R
VALUES (0); --anchor
WHILE @@ROWCOUNT > 0
BEGIN
INSERT INTO @R
SELECT ( N + 1 )%10
FROM @R
END
RETURN
END
GO
SELECT *
FROM dbo.F ()
Di atas menggunakan IGNORE_DUP_KEY untuk membuang duplikat. Jika daftar kolom terlalu lebar untuk diindeks, Anda memerlukan DISTINCT dan NOT EXISTS alih-alih. Anda juga mungkin menginginkan parameter untuk mengatur jumlah maksimum rekursi dan menghindari pengulangan tak terbatas.