Ini adalah bagian dari seri Operator Bermasalah Internal SQL Server. Pastikan untuk membaca postingan pertama dan postingan kedua Kalen tentang topik ini.
SQL Server telah ada selama lebih dari 30 tahun, dan saya telah bekerja dengan SQL Server hampir selama itu. Saya telah melihat banyak perubahan selama bertahun-tahun (dan beberapa dekade!) Dan versi produk luar biasa ini. Dalam posting ini, saya akan berbagi dengan Anda bagaimana saya melihat beberapa fitur atau aspek SQL Server, terkadang bersama dengan sedikit perspektif historis.
Terakhir kali saya berbicara tentang hashing dalam rencana kueri SQL Server sebagai operator yang berpotensi bermasalah dalam diagnostik server SQL. Hashing sering digunakan untuk bergabung dan agregasi ketika tidak ada indeks yang berguna. Dan seperti pemindaian (yang saya bicarakan di posting pertama dalam seri ini), ada kalanya hashing sebenarnya merupakan pilihan yang lebih baik daripada alternatifnya. Untuk hash join, salah satu alternatifnya adalah LOOP JOIN, yang juga saya ceritakan terakhir kali.
Dalam posting ini, saya akan memberi tahu Anda tentang alternatif lain untuk hashing. Sebagian besar alternatif untuk hashing mengharuskan data diurutkan, jadi rencana perlu menyertakan operator SORT, atau data yang diperlukan harus sudah diurutkan karena indeks yang ada.
Berbagai Jenis Penggabungan untuk Diagnostik SQL Server
Untuk operasi JOIN, jenis JOIN yang paling umum dan berguna adalah LOOP JOIN. Saya menjelaskan algoritma untuk LOOP JOIN di posting sebelumnya. Meskipun data itu sendiri tidak perlu diurutkan untuk LOOP JOIN, keberadaan indeks pada tabel bagian dalam membuat penggabungan menjadi jauh lebih efisien dan seperti yang harus Anda ketahui, keberadaan indeks menyiratkan beberapa penyortiran. Sementara indeks berkerumun mengurutkan data itu sendiri, indeks tidak berkerumun mengurutkan kolom kunci indeks. Bahkan, dalam banyak kasus, tanpa indeks, pengoptimal SQL Server akan memilih untuk menggunakan algoritma HASH JOIN. Kami melihat ini dalam contoh terakhir kali, bahwa tanpa indeks, HASH JOIN dipilih, dan dengan indeks, kami mendapat LOOP JOIN.
Jenis join yang ketiga adalah MERGE JOIN. Algoritma ini bekerja pada dua set data yang sudah diurutkan. Jika kita mencoba untuk menggabungkan (atau GABUNG) dua set data yang sudah diurutkan, hanya dibutuhkan satu kali melewati setiap set untuk menemukan baris yang cocok. Berikut pseudocode untuk algoritma merge join:
get first row R1 from input 1
get first row R2 from input 2
while not at the end of either input
begin
if R1 joins with R2
begin
output (R1, R2)
get next row R2 from input 2
end
else if R1 < R2
get next row R1 from input 1
else
get next row R2 from input 2
end
Meskipun MERGE JOIN adalah algoritme yang sangat efisien, ini mengharuskan kedua set data input diurutkan berdasarkan kunci gabung, yang biasanya berarti memiliki indeks berkerumun pada kunci gabung untuk kedua tabel. Karena Anda hanya mendapatkan satu indeks berkerumun per tabel, memilih kolom kunci berkerumun hanya untuk memungkinkan MERGE JOINS terjadi mungkin bukan pilihan keseluruhan terbaik untuk mengelompokkan kunci.
Jadi biasanya, saya tidak menyarankan Anda mencoba membangun indeks hanya untuk tujuan MERGE JOINS, tetapi jika Anda akhirnya mendapatkan MERGE JOIN karena indeks yang sudah ada, biasanya itu hal yang baik. Selain mengharuskan kedua set data input diurutkan, MERGE JOIN juga mengharuskan setidaknya satu set data memiliki nilai unik untuk kunci gabung.
Mari kita lihat sebuah contoh. Pertama, kita akan membuat ulang Header dan Rincian tabel:
USE AdventureWorks2016;
GO
DROP TABLE IF EXISTS Details;
GO
SELECT * INTO Details FROM Sales.SalesOrderDetail;
GO
DROP TABLE IF EXISTS Headers;
GO
SELECT * INTO Headers FROM Sales.SalesOrderHeader;
GO
CREATE CLUSTERED INDEX Header_index on Headers(SalesOrderID);
GO
CREATE CLUSTERED INDEX Detail_index on Details(SalesOrderID);
GO
Selanjutnya, lihat rencana untuk bergabung di antara tabel-tabel ini:
SELECT *
FROM Details d JOIN Headers h
ON d.SalesOrderID = h.SalesOrderID;
GO
Ini rencananya:

Perhatikan bahwa bahkan dengan indeks berkerumun di kedua tabel, kami mendapatkan HASH JOIN. Kita dapat membangun kembali salah satu indeks menjadi UNIK. Dalam hal ini, itu harus berupa indeks pada Header tabel, karena hanya itu yang memiliki nilai unik untuk SalesOrderID.
CREATE UNIQUE CLUSTERED INDEX Header_index on Headers(SalesOrderID) WITH DROP_EXISTING;
GO
Sekarang, jalankan kueri lagi, dan perhatikan bahwa rencana melakukan cara MERGE JOIN.

Paket ini mendapat manfaat dari memiliki data yang sudah diurutkan dalam indeks, karena rencana eksekusi dapat memanfaatkan penyortiran. Namun terkadang, SQL Server harus melakukan pengurutan sebagai bagian dari eksekusi kuerinya. Anda mungkin kadang-kadang melihat operator SORT muncul dalam rencana meskipun Anda tidak meminta keluaran yang diurutkan. Jika SQL Server berpikir bahwa MERGE JOIN mungkin merupakan pilihan yang baik, tetapi salah satu tabel tidak memiliki indeks berkerumun yang sesuai, dan cukup kecil untuk membuat penyortiran menjadi sangat murah, SORT dapat dilakukan untuk memungkinkan MERGE JOIN menjadi digunakan.
Namun biasanya, operator SORT muncul dalam kueri di mana kami telah meminta data yang diurutkan dengan ORDER BY, seperti pada contoh berikut.
SELECT * FROM Details
ORDER BY ProductID;
GO

Indeks berkerumun dipindai (yang sama dengan memindai tabel) dan kemudian baris diurutkan seperti yang diminta.
Menangani Indeks Cluster yang Sudah Diurutkan
Tetapi bagaimana jika data sudah diurutkan dalam indeks berkerumun, dan kueri menyertakan ORDER BY pada kolom kunci berkerumun? Dalam contoh di atas, kami membangun indeks berkerumun di SalesOrderID di tabel Detail. Lihat dua pertanyaan berikut:
SELECT * FROM Details;
GO
SELECT * FROM Details
ORDER BY SalesOrderID;
GO
Jika kita menjalankan kueri ini bersama-sama, Jendela Analisis Paket Penyetelan Spotlight Quest menunjukkan bahwa kedua paket tersebut memiliki biaya yang sama; masing-masing adalah 50% dari total. Jadi, apa sebenarnya perbedaan di antara keduanya?
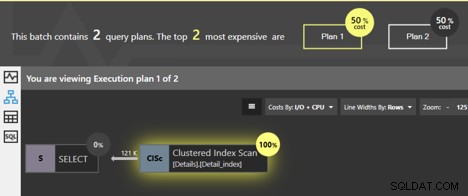
Kedua kueri memindai indeks berkerumun dan SQL Server mengetahui bahwa jika halaman tingkat daun diikuti secara berurutan, data akan kembali dalam urutan kunci berkerumun. Tidak ada penyortiran tambahan yang perlu dilakukan, jadi tidak ada operator SORT yang ditambahkan ke rencana. Tapi ada perbedaan. Kita dapat mengklik operator Clustered Index Scan dan akan mendapatkan beberapa informasi rinci.
Pertama, lihat informasi detail untuk paket pertama, untuk kueri tanpa ORDER BY.

Detailnya memberi tahu kami bahwa properti "Dipesan" adalah Salah. Tidak ada persyaratan di sini bahwa data dikembalikan dalam urutan yang diurutkan. Ternyata dalam kebanyakan kasus, cara termudah untuk mengambil data adalah dengan mengikuti halaman indeks berkerumun, sehingga data akan dikembalikan secara berurutan, tetapi tidak ada jaminan. Arti dari properti False adalah bahwa tidak ada persyaratan bahwa SQL Server mengikuti halaman yang dipesan untuk mengembalikan hasilnya. Sebenarnya ada cara lain SQL Server bisa mendapatkan semua baris untuk tabel, tanpa mengikuti indeks berkerumun. Jika selama eksekusi, SQL Server memilih untuk menggunakan metode yang berbeda untuk mendapatkan baris, kami tidak akan melihat hasil yang diurutkan.
Untuk kueri kedua, detailnya terlihat seperti ini:
 Karena kueri menyertakan ORDER BY, ada persyaratan bahwa data dikembalikan dalam urutan terurut dan SQL Server akan mengikuti halaman indeks berkerumun, secara berurutan.
Karena kueri menyertakan ORDER BY, ada persyaratan bahwa data dikembalikan dalam urutan terurut dan SQL Server akan mengikuti halaman indeks berkerumun, secara berurutan.
Hal terpenting untuk diingat di sini adalah TIDAK ADA jaminan data yang diurutkan jika Anda tidak menyertakan ORDER BY dalam kueri Anda. Hanya karena Anda memiliki indeks berkerumun, masih tidak ada jaminan! Bahkan jika setiap kali selama setahun terakhir Anda menjalankan kueri, Anda mendapatkan data kembali secara berurutan tanpa ORDER BY, tidak ada jaminan bahwa Anda akan terus mendapatkan data kembali secara berurutan. Menggunakan ORDER BY adalah satu-satunya cara untuk menjamin urutan pengembalian hasil Anda.
Tips Menggunakan Operasi Sortir
Jadi, apakah SORT merupakan operasi yang harus dihindari dalam diagnostik server SQL? Sama seperti pemindaian dan operasi hash, jawabannya tentu saja 'tergantung'. Penyortiran bisa sangat mahal, terutama pada kumpulan data yang besar. Pengindeksan yang tepat memang membantu SQL Server menghindari melakukan operasi SORT karena indeks pada dasarnya berarti data Anda sudah disortir. Tapi pengindeksan datang dengan biaya. Ada biaya penyimpanan, selain biaya pemeliharaan, untuk setiap indeks. Jika data Anda sangat diperbarui, Anda harus menjaga jumlah indeks seminimal mungkin.
Jika Anda menemukan bahwa beberapa kueri yang berjalan lambat memang menunjukkan operasi SORT dalam rencana mereka, dan jika SORT tersebut adalah salah satu operator yang paling mahal dalam rencana, Anda dapat mempertimbangkan membangun indeks yang memungkinkan SQL Server untuk menghindari penyortiran. Tetapi Anda harus melakukan pengujian menyeluruh untuk memastikan bahwa indeks tambahan tidak memperlambat kueri lain yang penting bagi kinerja aplikasi Anda secara keseluruhan.