
Ketersediaan, aksesibilitas, dan kinerja data sangat penting untuk kesuksesan bisnis. Penyesuaian kinerja dan pengoptimalan kueri SQL memang rumit, tetapi praktik yang diperlukan untuk profesional database. Mereka perlu melihat berbagai koleksi data menggunakan acara yang diperluas, kinerja, rencana eksekusi, statistik, dan indeks untuk beberapa nama. Terkadang, pemilik aplikasi meminta untuk meningkatkan sumber daya sistem (CPU dan memori) untuk meningkatkan kinerja sistem. Namun, Anda mungkin tidak memerlukan sumber daya tambahan ini dan mereka dapat memiliki biaya yang terkait dengannya. Terkadang, yang diperlukan hanyalah membuat peningkatan kecil untuk mengubah perilaku kueri.
Dalam artikel ini, kita akan membahas beberapa praktik terbaik pengoptimalan kueri SQL untuk diterapkan saat menulis kueri SQL.
PILIH * vs PILIH daftar kolom
Biasanya, developer menggunakan pernyataan SELECT * untuk membaca data dari tabel. Itu membaca semua data kolom yang tersedia di tabel. Misalkan tabel [AdventureWorks2019].[HumanResources].[Employee] menyimpan data untuk 290 karyawan dan Anda memiliki persyaratan untuk mengambil informasi berikut:
- Nomor KTP Karyawan
- DOB
- Jenis Kelamin
- Tanggal perekrutan
Kueri tidak efisien: Jika Anda menggunakan pernyataan SELECT *, ini akan mengembalikan semua data kolom untuk 290 karyawan.
Select * from [AdventureWorks2019].[HumanResources].[Employee]
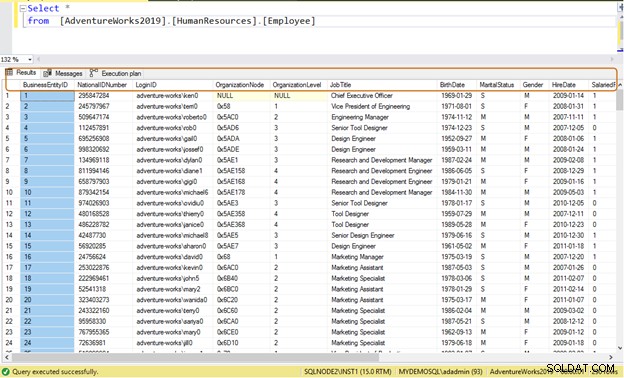
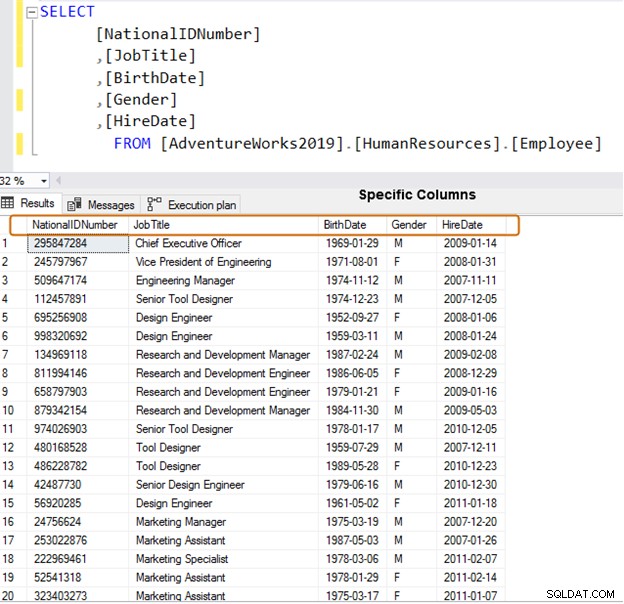
Sebagai gantinya, gunakan nama kolom tertentu untuk pengambilan data.
SELECT [NationalIDNumber] ,[JobTitle] ,[BirthDate] ,[Gender] ,[HireDate] FROM [AdventureWorks2019].[HumanResources].[Employee]
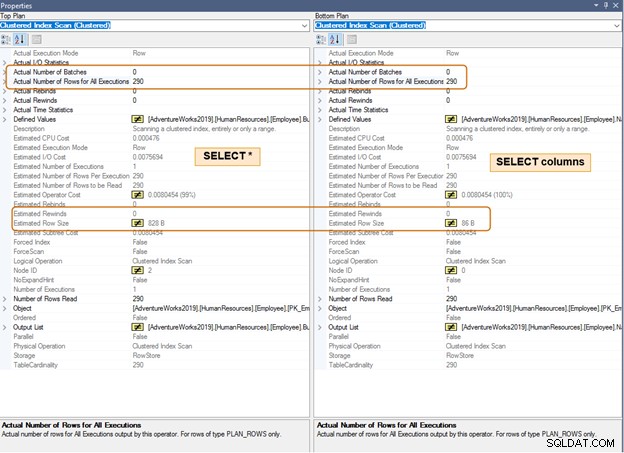
Dalam rencana eksekusi di bawah ini, perhatikan perbedaan dalam perkiraan ukuran baris untuk jumlah baris yang sama. Anda juga akan melihat perbedaan dalam CPU dan IO untuk sejumlah besar baris.
Penggunaan COUNT() vs. EXISTS
Misalkan Anda ingin memeriksa apakah catatan tertentu ada di tabel SQL. Biasanya, kami menggunakan COUNT (*) untuk memeriksa catatan, dan mengembalikan jumlah catatan dalam output.
Namun, kita dapat menggunakan fungsi IF EXISTS() untuk tujuan ini. Sebagai perbandingan, saya mengaktifkan statistik sebelum menjalankan kueri.
Kueri untuk COUNT()
SET STATISTICS IO ON Select count(*) from [AdventureWorks2019].[Sales].[SalesOrderDetail] where [SalesOrderDetailID]=44824 SET STATISTICS IO OFF
Kueri untuk JIKA ADA()
SET STATISTICS IO ON IF EXISTS(Select [CarrierTrackingNumber] from [AdventureWorks2019].[Sales].[SalesOrderDetail] where [SalesOrderDetailID]=44824) PRINT 'YES' ELSE PRINT 'NO' SET STATISTICS IO OFF
Saya menggunakan statisticsparser untuk menganalisis hasil statistik dari kedua kueri. Lihatlah hasilnya di bawah ini. Kueri dengan COUNT(*) memiliki 276 pembacaan logis sedangkan IF EXISTS() memiliki 83 pembacaan logis. Anda bahkan bisa mendapatkan pengurangan yang lebih signifikan dalam pembacaan logis dengan IF EXISTS(). Oleh karena itu, Anda harus menggunakannya untuk mengoptimalkan kueri SQL untuk kinerja yang lebih baik.

Hindari menggunakan SQL DISTINCT
Setiap kali kita menginginkan catatan unik dari kueri, kita biasanya menggunakan klausa SQL DISTINCT. Misalkan Anda menggabungkan dua tabel bersama-sama, dan dalam output itu mengembalikan baris duplikat. Perbaikan cepat adalah dengan menentukan operator DISTINCT yang menekan baris duplikat.
Mari kita lihat pernyataan SELECT sederhana dan bandingkan rencana eksekusi. Satu-satunya perbedaan antara kedua kueri adalah operator DISTINCT.
SELECT SalesOrderID FROM Sales.SalesOrderDetail Go SELECT DISTINCT SalesOrderID FROM Sales.SalesOrderDetail Go
Dengan operator DISTINCT, biaya kueri adalah 77%, sedangkan kueri sebelumnya (tanpa DISTINCT) hanya memiliki biaya batch 23%.
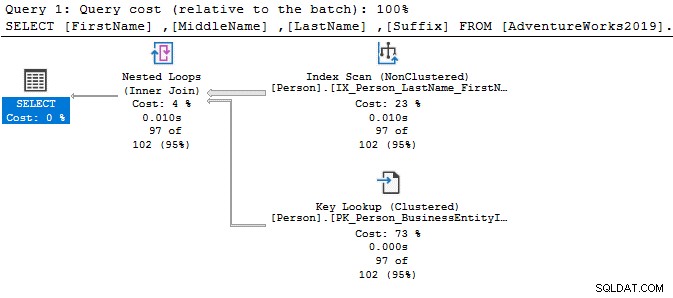
Anda dapat menggunakan GROUP BY, CTE atau subquery untuk menulis kode SQL yang efisien daripada menggunakan DISTINCT untuk mendapatkan nilai yang berbeda dari kumpulan hasil. Selain itu, Anda dapat mengambil kolom tambahan untuk kumpulan hasil yang berbeda.
SELECT SalesOrderID FROM Sales.SalesOrderDetail Group by SalesOrderID
Penggunaan karakter pengganti dalam kueri SQL
Misalkan Anda ingin mencari catatan tertentu yang berisi nama yang dimulai dengan string yang ditentukan. Pengembang menggunakan karakter pengganti untuk menelusuri catatan yang cocok.
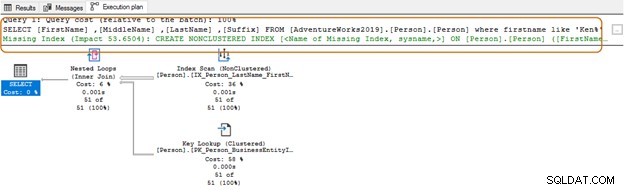
Dalam kueri di bawah ini, ia mencari string Ken di kolom nama depan. Kueri ini mengambil hasil yang diharapkan dari Ken dra dan Ken bersih. Namun, ini juga memberikan hasil yang tidak terduga, misalnya, Macken zie dan Nken ge.
Dalam rencana eksekusi, Anda melihat pemindaian indeks dan pencarian kunci untuk kueri di atas.
Anda dapat menghindari hasil yang tidak diharapkan menggunakan karakter wildcard di akhir string.
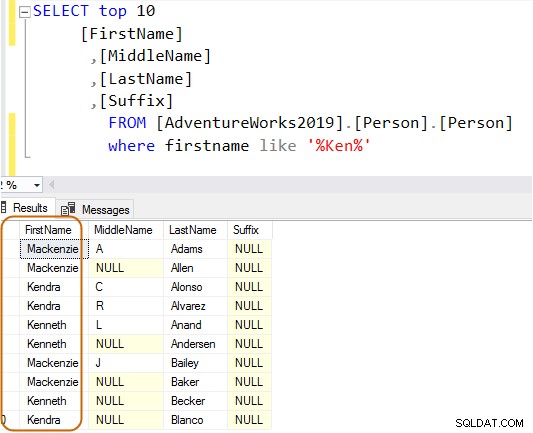
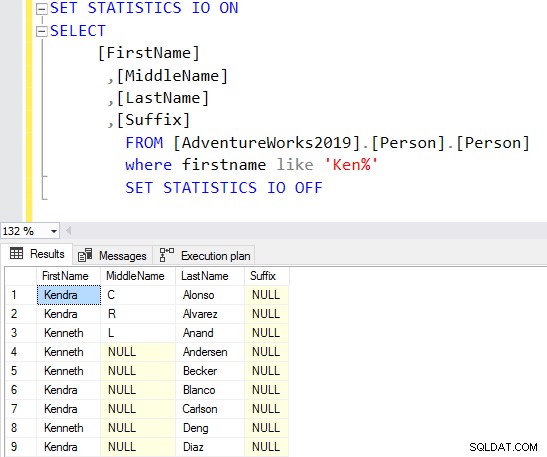
SELECT Top 10 [FirstName] ,[MiddleName] ,[LastName] ,[Suffix] FROM [AdventureWorks2019].[Person].[Person] Where firstname like 'Ken%'
Sekarang, Anda mendapatkan hasil yang difilter berdasarkan kebutuhan Anda.
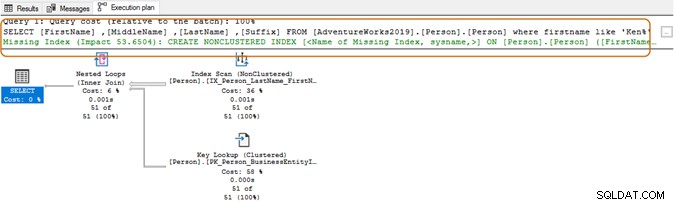
Dalam menggunakan karakter wildcard di awal, pengoptimal kueri mungkin tidak dapat menggunakan indeks yang sesuai. Seperti yang ditunjukkan pada tangkapan layar di bawah, dengan karakter liar yang tertinggal, pengoptimal kueri juga menyarankan indeks yang hilang.
Di sini, Anda ingin mengevaluasi persyaratan aplikasi Anda. Anda harus mencoba untuk menghindari penggunaan karakter wildcard dalam string pencarian, karena mungkin memaksa pengoptimal kueri untuk menggunakan pemindaian tabel. Jika tabelnya sangat besar, itu akan membutuhkan sumber daya sistem yang lebih tinggi untuk IO, CPU, dan memori, dan dapat menyebabkan masalah kinerja untuk kueri SQL Anda.
Penggunaan klausa WHERE dan HAVING
Klausa WHERE dan HAVING digunakan sebagai filter baris data. Klausa WHERE memfilter data sebelum menerapkan logika pengelompokan, sedangkan klausa HAVING memfilter baris setelah penghitungan agregat.
Misalnya, dalam kueri di bawah ini, kami menggunakan filter data dalam klausa HAVING tanpa klausa WHERE.
Select SalesOrderID, SUM(UnitPrice* OrderQty) as OrderTotal From Sales.salesOrderDetail GROUP BY SalesOrderID HAVING SalesOrderID>30000 and SalesOrderID<55555 and SUM(UnitPrice* OrderQty)>1 Go
Kueri berikut memfilter data terlebih dahulu di klausa WHERE lalu menggunakan klausa HAVING untuk filter data agregat.
Select SalesOrderID, SUM(UnitPrice* OrderQty) as OrderTotal From Sales.salesOrderDetail where SalesOrderID>30000 and SalesOrderID<55555 GROUP BY SalesOrderID HAVING SUM(UnitPrice* OrderQty)>1000 Go
Sebaiknya gunakan klausa WHERE untuk pemfilteran data dan klausa HAVING untuk filter data agregat Anda sebagai praktik terbaik.
Penggunaan klausa IN dan EXISTS
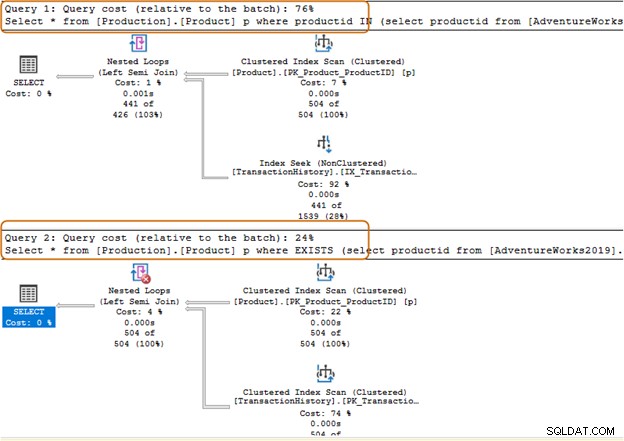
Anda harus menghindari penggunaan klausa IN-operator untuk kueri SQL Anda. Misalnya, dalam kueri di bawah ini, pertama-tama, kami menemukan id produk dari tabel [Produksi].[TransactionHistory]) dan kemudian mencari catatan yang sesuai di tabel [Produksi].[Produk].
Select * from [Production].[Product] p where productid IN (select productid from [AdventureWorks2019].[Production].[TransactionHistory]); Go
Dalam kueri di bawah, kami mengganti klausa IN dengan klausa EXISTS.
Select * from [Production].[Product] p where EXISTS (select productid from [AdventureWorks2019].[Production].[TransactionHistory])
Sekarang, mari kita bandingkan statistik setelah menjalankan kedua kueri.
Klausa IN menggunakan 504 scan, sedangkan klausa EXISTS menggunakan 1 scan untuk tabel [Production].[TransactionHistory])].
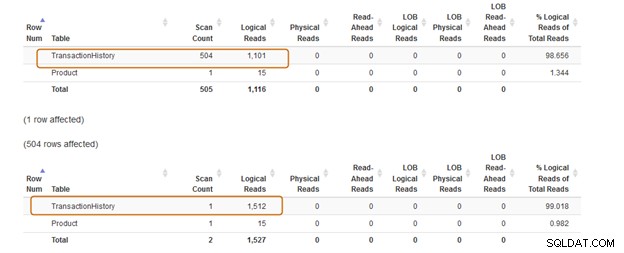
Batch kueri klausa IN berharga 74%, sedangkan biaya klausa EXISTS adalah 24%. Oleh karena itu, Anda harus menghindari klausa IN terutama jika subquery mengembalikan kumpulan data yang besar.
Indeks tidak ada
Terkadang, saat kami menjalankan kueri SQL dan mencari rencana eksekusi sebenarnya di SSMS, Anda mendapatkan saran tentang indeks yang dapat meningkatkan kueri SQL Anda.
Atau, Anda dapat menggunakan tampilan manajemen dinamis untuk memeriksa detail indeks yang hilang di lingkungan Anda.
- sys.dm_db_missing_index_details
- sys.dm_db_missing_index_group_stats
- sys.dm_db_missing_index_groups
- sys.dm_db_missing_index_columns
Biasanya, DBA mengikuti saran dari SSMS dan membuat indeks. Ini mungkin meningkatkan kinerja kueri untuk saat ini. Namun, Anda tidak boleh membuat indeks secara langsung berdasarkan rekomendasi tersebut. Ini mungkin memengaruhi kinerja kueri lainnya dan memperlambat pernyataan INSERT dan UPDATE Anda.
- Pertama, tinjau indeks yang ada untuk tabel SQL Anda.
- Perhatikan, pengindeksan yang berlebihan dan pengindeksan yang kurang keduanya buruk untuk kinerja kueri.
- Terapkan rekomendasi indeks yang hilang dengan dampak tertinggi setelah meninjau indeks yang ada dan menerapkannya di lingkungan yang lebih rendah. Jika beban kerja Anda berfungsi dengan baik setelah menerapkan indeks baru yang hilang, ada baiknya menambahkannya.
Sebaiknya lihat artikel ini untuk praktik terbaik pengindeksan mendetail: 11 Praktik Terbaik Indeks SQL Server untuk Penyesuaian Performa yang Lebih Baik.
Petunjuk kueri
Pengembang menentukan petunjuk kueri secara eksplisit dalam pernyataan t-SQL mereka. Petunjuk kueri ini menggantikan perilaku pengoptimal kueri dan memaksanya untuk menyiapkan rencana eksekusi berdasarkan petunjuk kueri Anda. Petunjuk kueri yang sering digunakan adalah NOLOCK, Optimize For dan Recompile Merge/Hash/Loop. Itu adalah perbaikan jangka pendek untuk kueri Anda. Namun, Anda harus bekerja menganalisis kueri, indeks, statistik, dan rencana eksekusi untuk solusi permanen.
Sesuai praktik terbaik, Anda harus meminimalkan penggunaan petunjuk kueri apa pun. Anda ingin menggunakan petunjuk kueri dalam kueri SQL setelah terlebih dahulu memahami implikasinya, dan jangan menggunakannya secara tidak perlu.
Pengingat pengoptimalan kueri SQL
Seperti yang telah kita bahas, optimasi query SQL adalah jalan terbuka. Anda dapat menerapkan praktik terbaik dan perbaikan kecil yang dapat sangat meningkatkan kinerja. Pertimbangkan tip berikut untuk pengembangan kueri yang lebih baik:
- Selalu perhatikan alokasi sumber daya sistem (disk, CPU, memori)
- Tinjau tanda pelacakan startup, indeks, dan tugas pemeliharaan database
- Analisis beban kerja Anda menggunakan peristiwa yang diperluas, profiler, atau alat pemantauan database pihak ketiga
- Selalu terapkan solusi apa pun (bahkan jika Anda 100% yakin) pada lingkungan pengujian terlebih dahulu dan analisis dampaknya; setelah Anda puas, rencanakan implementasi produksi



