Sejauh menyangkut rencana eksekusi grafis, hanya ada satu ikon untuk pengurutan fisik di SQL Server:

Ikon yang sama ini digunakan untuk tiga operator pengurutan logis:Sort, Top N Sort, dan Distinct Sort:
Lebih dalam lagi, ada empat implementasi Sort yang berbeda di mesin eksekusi (tidak termasuk penyortiran batch untuk gabungan loop yang dioptimalkan, yang bukan merupakan pengurutan penuh, dan toh tidak terlihat dalam rencana). Jika Anda menggunakan SQL Server 2014, jumlah implementasi mesin eksekusi Sort meningkat menjadi tujuh:
- CQScanSortNew
- CQScanTopSortNew
- CQScanIndexSortNew
- CQScanPartitionSortNew (hanya SQL Server 2014)
- CQScanInMemSortNew
- In-Memory OLTP (Hekaton) prosedur yang dikompilasi secara native Top N Sort (hanya SQL Server 2014)
- In-Memory OLTP (Hekaton) secara native dikompilasi prosedur General Sort (SQL Server 2014 saja)
Artikel ini membahas implementasi pengurutan ini dan kapan masing-masing digunakan di SQL Server. Bagian satu mencakup empat item pertama dalam daftar.
1. CQScanSortNew
Ini adalah kelas pengurutan yang paling umum, digunakan ketika tidak ada opsi lain yang tersedia yang dapat diterapkan. Penyortiran umum menggunakan hibah memori ruang kerja yang dicadangkan tepat sebelum eksekusi kueri dimulai. Hibah ini sebanding dengan perkiraan kardinalitas dan ekspektasi ukuran baris rata-rata, dan tidak dapat ditingkatkan setelah eksekusi kueri dimulai.
Implementasi saat ini tampaknya menggunakan berbagai pengurutan gabungan internal (mungkin pengurutan gabungan biner), transisi ke pengurutan gabungan eksternal (dengan beberapa lintasan jika perlu) jika memori yang dicadangkan ternyata tidak mencukupi. Pengurutan gabungan eksternal menggunakan tempdb fisik ruang untuk sortir yang tidak muat di memori (umumnya dikenal sebagai sort spill). Penyortiran umum juga dapat dikonfigurasi untuk menerapkan perbedaan selama operasi penyortiran.
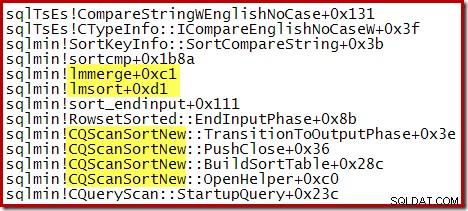
Jejak tumpukan parsial berikut menunjukkan contoh CQScanSortNew kelas menyortir string menggunakan semacam gabungan internal:
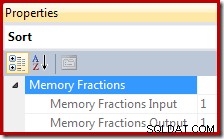
Dalam rencana eksekusi, Sort menyediakan informasi tentang fraksi dari keseluruhan pemberian memori ruang kerja kueri yang tersedia untuk Sortir saat membaca catatan (fase input), dan fraksi yang tersedia saat output yang diurutkan sedang dikonsumsi oleh operator rencana induk (fase output ).
Fraksi pemberian memori adalah angka antara 0 dan 1 (di mana 1 =100% dari memori yang diberikan) dan terlihat di SSMS dengan menyorot Sort dan melihat di jendela Properties. Contoh di bawah ini diambil dari kueri dengan hanya satu operator Sortir, sehingga memiliki hibah memori ruang kerja kueri lengkap yang tersedia selama fase input dan output:
Fraksi memori mencerminkan fakta bahwa selama fase inputnya, Sort harus berbagi keseluruhan pemberian memori kueri dengan operator yang menggunakan memori yang menjalankan secara bersamaan di bawahnya dalam rencana eksekusi. Demikian pula, selama fase keluaran, Sort harus berbagi memori yang diberikan dengan operator yang menggunakan memori yang menjalankan secara bersamaan di atasnya dalam rencana eksekusi.
Pemroses kueri cukup pintar untuk mengetahui bahwa beberapa operator memblokir (stop-and-go), secara efektif menandai batas di mana pemberian memori dapat didaur ulang dan digunakan kembali. Dalam paket paralel, fraksi pemberian memori yang tersedia untuk Sortir umum dibagi secara merata di antara utas, dan tidak dapat diseimbangkan ulang saat runtime jika terjadi kemiringan (penyebab umum tumpahan dalam paket pengurutan paralel).
SQL Server 2012 dan yang lebih baru menyertakan informasi tambahan tentang pemberian memori ruang kerja minimum yang diperlukan untuk menginisialisasi operator paket yang menghabiskan memori, dan yang diinginkan pemberian memori (jumlah memori "ideal" yang diperkirakan diperlukan untuk menyelesaikan seluruh operasi dalam memori). Dalam rencana eksekusi pasca-eksekusi ("aktual"), ada juga informasi baru tentang penundaan apa pun dalam memperoleh pemberian memori, jumlah maksimum memori yang sebenarnya digunakan, dan bagaimana reservasi memori didistribusikan ke seluruh NUMA node.
Contoh AdventureWorks berikut semuanya menggunakan CQScanSortNew pengurutan umum:
-- An Ordinary Sort (CQScanSortNew)
SELECT
P.FirstName,
P.MiddleName,
P.LastName
FROM Person.Person AS P
ORDER BY
P.FirstName,
P.MiddleName,
P.LastName;
-- Distinct Sort (also CQScanSortNew)
SELECT DISTINCT
P.FirstName,
P.MiddleName,
P.LastName
FROM Person.Person AS P
ORDER BY
P.FirstName,
P.MiddleName,
P.LastName;
-- Same query expressed using GROUP BY
-- Same Distinct Sort (CQScanSortNew) execution plan
SELECT
P.FirstName,
P.MiddleName,
P.LastName
FROM Person.Person AS P
GROUP BY
P.FirstName,
P.MiddleName,
P.LastName
ORDER BY
P.FirstName,
P.MiddleName,
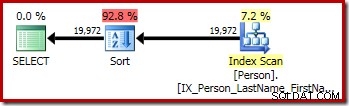
P.LastName; Kueri pertama (pengurutan yang tidak berbeda) menghasilkan rencana eksekusi berikut:
Kueri kedua dan ketiga (setara) menghasilkan rencana ini:
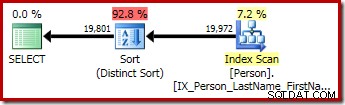
CQScanSortNew dapat digunakan untuk Sortir umum logis dan Sortir Berbeda logis.
2. CQScanTopSortNew
CQScanTopSortNew adalah subkelas dari CQScanSortNew digunakan untuk mengimplementasikan Top N Sort (seperti namanya). CQScanTopSortNew mendelegasikan sebagian besar pekerjaan inti ke CQScanSortNew , tetapi memodifikasi perilaku detail dengan cara yang berbeda, bergantung pada nilai N.
Untuk N> 100, CQScanTopSortNew pada dasarnya hanyalah CQScanSortNew regular biasa sort yang secara otomatis berhenti memproduksi baris yang diurutkan setelah N baris. Untuk N <=100, CQScanTopSortNew hanya menyimpan hasil N Teratas saat ini selama operasi pengurutan, dan melacak nilai kunci terendah yang saat ini memenuhi syarat.
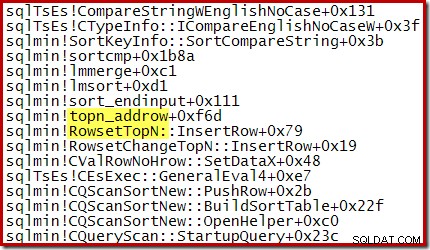
Misalnya, selama Pengurutan N Teratas yang dioptimalkan (dengan N <=100) tumpukan panggilan menampilkan RowsetTopN sedangkan dengan pengurutan umum di bagian 1 kita melihat RowsetSorted :
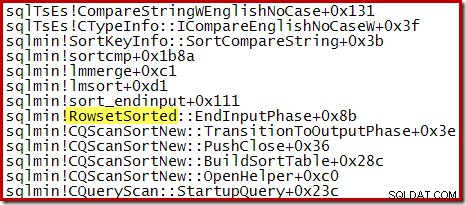
Untuk Pengurutan N Teratas di mana N> 100, tumpukan panggilan pada tahap eksekusi yang sama sama dengan pengurutan umum yang terlihat sebelumnya:
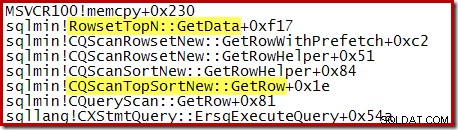
Perhatikan bahwa CQScanTopSortNew nama kelas tidak muncul di salah satu jejak tumpukan tersebut. Ini hanya karena cara kerja sub-klasifikasi. Di titik lain selama eksekusi kueri ini, CQScanTopSortNew metode (misalnya Open, GetRow, dan CreateTopNTable) muncul secara eksplisit di tumpukan panggilan. Sebagai contoh, berikut ini diambil pada saat berikutnya dalam eksekusi kueri dan menampilkan CQScanTopSortNew nama kelas:
Urutan N Teratas dan Pengoptimal Kueri
Pengoptimal kueri tidak tahu apa-apa tentang Top N Sort, yang merupakan operator mesin eksekusi saja. Ketika pengoptimal menghasilkan pohon keluaran dengan operator Top fisik tepat di atas Sortir fisik (tidak berbeda), penulisan ulang pasca-pengoptimalan dapat menciutkan dua operasi fisik menjadi satu operator Sort N Top. Bahkan dalam kasus N> 100, ini menunjukkan penghematan atas baris yang lewat secara iteratif antara output Sort dan input Top.
Kueri berikut menggunakan beberapa tanda pelacakan tidak berdokumen untuk menampilkan keluaran pengoptimal dan penulisan ulang pasca-pengoptimalan yang sedang berjalan:
SELECT TOP (10)
P.FirstName,
P.MiddleName,
P.LastName
FROM Person.Person AS P
ORDER BY
P.FirstName,
P.MiddleName,
P.LastName
OPTION (QUERYTRACEON 3604, QUERYTRACEON 8607, QUERYTRACEON 7352); Pohon keluaran pengoptimal menunjukkan operator Top dan Sort fisik yang terpisah:
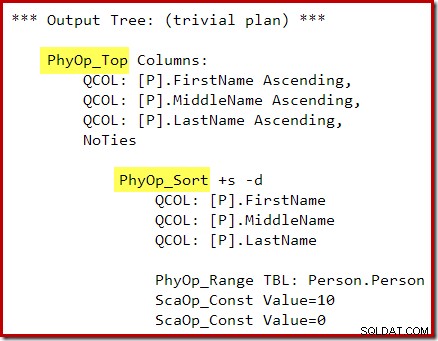
Setelah penulisan ulang pasca-optimasi, Top dan Sort telah diciutkan menjadi satu Top N Sort:
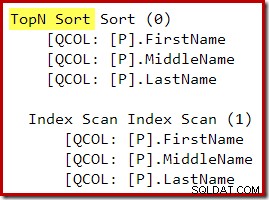
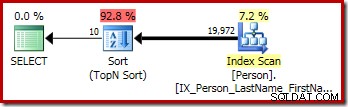
Rencana eksekusi grafis untuk kueri T-SQL di atas menunjukkan operator Top N Sort tunggal:
Mendobrak Top N Sortir menulis ulang
Penulisan ulang pasca optimasi Top N Sort hanya dapat menciutkan Top N Sort yang berdekatan dan tidak berbeda ke dalam Top N Sort. Menambahkan DISTINCT (atau klausa GROUP BY yang setara) ke kueri di atas akan mencegah penulisan ulang Top N Sort:
SELECT DISTINCT TOP (10)
P.FirstName,
P.MiddleName,
P.LastName
FROM Person.Person AS P
ORDER BY
P.FirstName,
P.MiddleName,
P.LastName; Rencana eksekusi akhir untuk kueri ini menampilkan operator Top and Sort (Distinct Sort) yang terpisah:
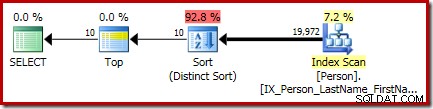
Sortir ada CQScanSortNew umum kelas berjalan dalam mode berbeda seperti yang terlihat di bagian 1 sebelumnya.
Cara kedua untuk mencegah penulisan ulang ke Top N Sort adalah dengan memperkenalkan satu atau lebih operator tambahan antara Top dan Sort. Misalnya:
SELECT TOP (10)
P.FirstName,
P.MiddleName,
P.LastName,
rn = RANK() OVER (ORDER BY P.FirstName)
FROM Person.Person AS P
ORDER BY
P.FirstName,
P.MiddleName,
P.LastName; Output pengoptimal kueri sekarang kebetulan memiliki operasi antara Top dan Sort, sehingga Top N Sort tidak dihasilkan selama fase penulisan ulang pasca-optimasi:
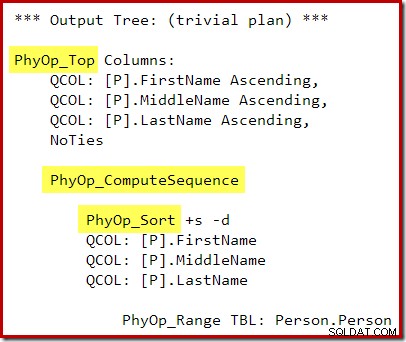
Rencana eksekusi adalah:

Urutan komputasi (diimplementasikan sebagai dua Segmen dan Proyek Urutan) antara Top dan Sort mencegah runtuhnya Top dan Sort ke satu operator Top N Sort. Tentu saja, hasil yang benar akan tetap diperoleh dari rencana ini, tetapi pelaksanaannya mungkin sedikit kurang efisien dibandingkan dengan kombinasi operator Top N Sort.
3. CQScanIndexSortNew
CQScanIndexSortNew hanya digunakan untuk menyortir dalam rencana pembangunan indeks DDL. Ini menggunakan kembali beberapa fasilitas pengurutan umum yang telah kita lihat, tetapi menambahkan pengoptimalan khusus untuk penyisipan indeks. Ini juga satu-satunya kelas pengurutan yang dapat secara dinamis meminta lebih banyak memori setelah eksekusi dimulai.
Estimasi kardinalitas seringkali akurat untuk rencana pembangunan indeks karena jumlah baris dalam tabel biasanya merupakan kuantitas yang diketahui. Itu tidak berarti bahwa pemberian memori untuk jenis rencana pembangunan indeks akan selalu akurat; itu hanya membuatnya sedikit kurang mudah untuk demo. Jadi, contoh berikut menggunakan ekstensi yang tidak terdokumentasi, tetapi cukup terkenal, ke perintah UPDATE STATISTICS untuk mengelabui pengoptimal dengan berpikir bahwa tabel tempat kita membuat indeks hanya memiliki satu baris:
-- Test table
CREATE TABLE dbo.People
(
FirstName dbo.Name NOT NULL,
LastName dbo.Name NOT NULL
);
GO
-- Copy rows from Person.Person
INSERT dbo.People WITH (TABLOCKX)
(
FirstName,
LastName
)
SELECT
P.FirstName,
P.LastName
FROM Person.Person AS P;
GO
-- Pretend the table only has 1 row and 1 page
UPDATE STATISTICS dbo.People
WITH ROWCOUNT = 1, PAGECOUNT = 1;
GO
-- Index building plan
CREATE CLUSTERED INDEX cx
ON dbo.People (LastName, FirstName);
GO
-- Tidy up
DROP TABLE dbo.People; Rencana eksekusi pasca-eksekusi ("aktual") untuk pembuatan indeks tidak menampilkan peringatan untuk jenis tumpahan (saat dijalankan di SQL Server 2012 atau yang lebih baru) meskipun perkiraan 1 baris dan 19.972 baris benar-benar diurutkan:
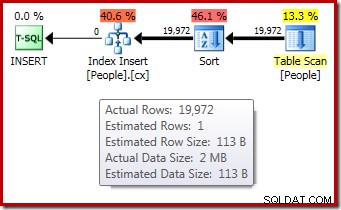
Konfirmasi bahwa pemberian memori awal diperluas secara dinamis berasal dari melihat properti iterator root. Kueri awalnya diberikan 1024KB memori, tetapi akhirnya menghabiskan 1576KB:
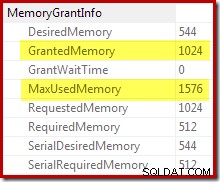
Peningkatan dinamis dalam memori yang diberikan juga dapat dilacak menggunakan Saluran Debug Extended Event sort_memory_grant_adjustment. Acara ini dihasilkan setiap kali alokasi memori meningkat secara dinamis. Jika peristiwa ini sedang dipantau, kami dapat menangkap jejak tumpukan saat diterbitkan, baik melalui Peristiwa yang Diperpanjang (dengan beberapa konfigurasi yang canggung dan tanda jejak) atau dari debugger yang dilampirkan, seperti di bawah ini:
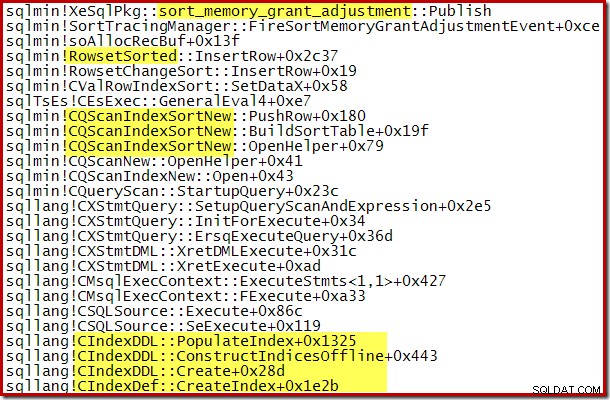
Perluasan hibah memori dinamis juga dapat membantu dengan rencana pembangunan indeks paralel di mana distribusi baris di seluruh utas tidak merata. Namun, jumlah memori yang dapat dikonsumsi dengan cara ini tidak terbatas. SQL Server memeriksa setiap kali perluasan diperlukan untuk melihat apakah permintaan tersebut wajar mengingat sumber daya yang tersedia pada saat itu.
Beberapa wawasan tentang proses ini dapat diperoleh dengan mengaktifkan bendera pelacakan tidak berdokumen 1504, bersama dengan 3604 (untuk keluaran pesan ke konsol) atau 3605 (keluaran ke log kesalahan SQL Server). Jika rencana pembangunan indeks paralel, hanya 3605 yang efektif karena pekerja paralel tidak dapat mengirim pesan pelacakan lintas-utas ke konsol.
Bagian berikut dari keluaran pelacakan ditangkap saat membuat indeks yang cukup besar pada instans SQL Server 2014 dengan memori terbatas:
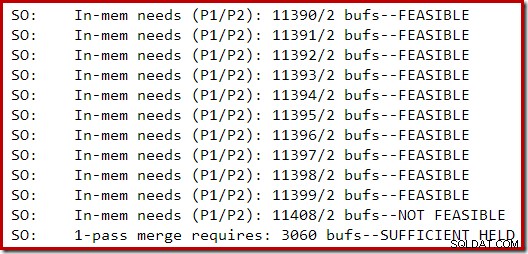
Perluasan memori untuk pengurutan berlangsung hingga permintaan dianggap tidak layak, dan pada titik itu ditentukan bahwa memori yang cukup telah disimpan untuk menyelesaikan tumpahan sortir satu arah.
4. CQScanPartitionSortNew
Nama kelas ini mungkin menyarankan bahwa jenis pengurutan ini digunakan untuk data tabel yang dipartisi, atau saat membangun indeks pada tabel yang dipartisi, tetapi tidak satu pun dari itu yang benar-benar terjadi. Menyortir data yang dipartisi menggunakan CQScanSortNew atau CQScanTopSortNew seperti biasa; menyortir baris untuk dimasukkan ke indeks yang dipartisi umumnya menggunakan CQScanIndexSortNew seperti yang terlihat di bagian 3.
CQScanPartitionSortNew kelas sortir hanya ada di SQL Server 2014. Ini hanya digunakan saat menyortir baris berdasarkan id partisi, sebelum dimasukkan ke dalam indeks penyimpanan kolom berkerumun yang dipartisi . Perhatikan bahwa ini hanya digunakan untuk dipartisi toko kolom berkerumun; paket penyisipan columnstore berkerumun reguler (tidak dipartisi) tidak mendapat manfaat dari penyortiran.
Sisipan ke dalam indeks penyimpanan kolom berkerumun yang dipartisi tidak akan selalu menampilkan pengurutan. Ini adalah keputusan berbasis biaya yang bergantung pada perkiraan jumlah baris yang akan disisipkan. Jika pengoptimal memperkirakan bahwa pengurutan sisipan menurut partisi perlu dilakukan untuk mengoptimalkan I/O, operator penyisipan columnstore akan memiliki DMRLequestSort properti disetel ke true, dan CQScanPartitionSortNew sort mungkin muncul dalam rencana eksekusi.
Demo di bagian ini menggunakan tabel nomor urut permanen. Jika Anda tidak memilikinya, skrip berikut dapat digunakan untuk membuatnya:
-- Itzik Ben-Gan's row generator
WITH
L0 AS (SELECT 1 AS c UNION ALL SELECT 1),
L1 AS (SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B),
L2 AS (SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B),
L3 AS (SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B),
L4 AS (SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B),
L5 AS (SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B),
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS n FROM L5)
SELECT
-- Destination column type integer NOT NULL
ISNULL(CONVERT(integer, N.n), 0) AS n
INTO dbo.Numbers
FROM Nums AS N
WHERE N.n >= 1
AND N.n <= 1000000
OPTION (MAXDOP 1);
GO
ALTER TABLE dbo.Numbers
ADD CONSTRAINT PK_Numbers_n
PRIMARY KEY CLUSTERED (n)
WITH (SORT_IN_TEMPDB = ON, MAXDOP = 1, FILLFACTOR = 100); Demo itu sendiri melibatkan pembuatan tabel terindeks kolomstore terpartisi, dan memasukkan cukup banyak baris (dari tabel Numbers di atas) untuk meyakinkan pengoptimal untuk menggunakan jenis partisi pra-sisipkan:
CREATE PARTITION FUNCTION PF (integer)
AS RANGE RIGHT
FOR VALUES (1000, 2000, 3000);
GO
CREATE PARTITION SCHEME PS
AS PARTITION PF
ALL TO ([PRIMARY]);
GO
-- A partitioned heap
CREATE TABLE dbo.Partitioned
(
col1 integer NOT NULL,
col2 integer NOT NULL DEFAULT ABS(CHECKSUM(NEWID())),
col3 integer NOT NULL DEFAULT ABS(CHECKSUM(NEWID()))
)
ON PS (col1);
GO
-- Convert heap to partitioned clustered columnstore
CREATE CLUSTERED COLUMNSTORE INDEX ccsi
ON dbo.Partitioned
ON PS (col1);
GO
-- Add rows to the partitioned clustered columnstore table
INSERT dbo.Partitioned (col1)
SELECT N.n
FROM dbo.Numbers AS N
WHERE N.n BETWEEN 1 AND 4000; Rencana eksekusi untuk penyisipan menunjukkan pengurutan yang digunakan untuk memastikan baris tiba di iterator penyisipan columnstore berkerumun dalam urutan id partisi:

Tumpukan panggilan ditangkap saat CQScanPartitionSortNew sort sedang berlangsung ditunjukkan di bawah ini:
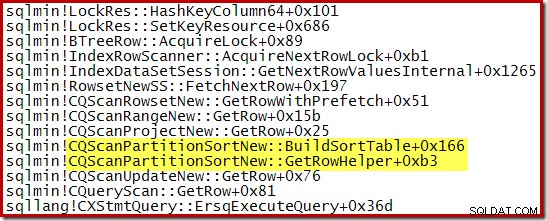
Ada hal lain yang menarik tentang kelas semacam ini. Sortasi biasanya menggunakan seluruh inputnya dalam panggilan metode Open mereka. Setelah menyortir, mereka mengembalikan kontrol ke operator induknya. Kemudian, pengurutan mulai menghasilkan baris keluaran yang diurutkan satu per satu dengan cara biasa melalui panggilan GetRow. CQScanPartitionSortNew berbeda, seperti yang Anda lihat di tumpukan panggilan di atas:Ia tidak menggunakan inputnya selama metode Open-nya – ia menunggu hingga GetRow dipanggil oleh induknya untuk pertama kalinya.
Tidak setiap pengurutan pada id partisi yang muncul dalam rencana eksekusi yang memasukkan baris ke dalam indeks penyimpanan kolom berkerumun yang dipartisi akan menjadi CQScanPartitionSortNew menyortir. Jika pengurutan muncul segera di sebelah kanan operator penyisipan indeks columnstore, kemungkinan besar itu adalah CQScanPartitionSortNew urutkan.
Terakhir, CQScanPartitionSortNew adalah salah satu dari hanya dua kelas pengurutan yang menyetel properti Sortir Lunak terekspos ketika properti rencana eksekusi operator Sortir dihasilkan dengan bendera pelacakan tidak berdokumen 8666 diaktifkan:
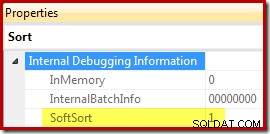
Arti dari "soft sort" dalam konteks ini tidak jelas. Ini dilacak sebagai properti dalam kerangka kerja pengoptimal kueri, dan tampaknya terkait dengan penyisipan data yang dipartisi yang dioptimalkan, tetapi menentukan dengan tepat artinya memerlukan penelitian lebih lanjut. Sementara itu, properti ini dapat digunakan untuk menyimpulkan bahwa Sortir diimplementasikan dengan CQScanPartitionSortNew tanpa melampirkan debugger. Arti dari flag properti InMemory yang ditampilkan di atas akan dibahas di bagian 2. Ini tidak menunjukkan apakah pengurutan reguler dilakukan dalam memori atau tidak.
Ringkasan Bagian Satu
- CQScanSortNew adalah kelas sortir umum yang digunakan ketika tidak ada opsi lain yang berlaku. Tampaknya menggunakan berbagai jenis gabungan internal di memori, transisi ke jenis gabungan eksternal menggunakan tempdb jika diberikan ruang kerja memori ternyata tidak mencukupi. Class ini dapat digunakan untuk General Sort dan Distinct Sort.
- CQScanTopSortNew mengimplementasikan Top N Sort. Di mana N <=100, pengurutan gabungan internal dalam memori dilakukan, dan tidak pernah tumpah ke tempdb . Hanya n item teratas saat ini yang disimpan dalam memori selama pengurutan. Untuk N> 100 CQScanTopSortNew setara dengan CQScanSortNew sort yang secara otomatis berhenti setelah N baris telah dikeluarkan. Pengurutan N> 100 dapat tumpah ke tempdb jika perlu.
- Urutan N Teratas yang terlihat dalam rencana eksekusi adalah penulisan ulang pengoptimalan pasca-kueri. Jika pengoptimal kueri menghasilkan pohon keluaran dengan Top N Sort yang berdekatan, penulisan ulang ini dapat menciutkan dua operator fisik menjadi satu operator Top N Sort.
- CQScanIndexSortNew hanya digunakan dalam rencana pembangunan indeks DDL. Ini adalah satu-satunya kelas sortir standar yang secara dinamis dapat memperoleh lebih banyak memori selama eksekusi. Jenis pembuatan indeks masih dapat tumpah ke disk dalam beberapa keadaan, termasuk ketika SQL Server memutuskan bahwa peningkatan memori yang diminta tidak kompatibel dengan beban kerja saat ini.
- CQScanPartitionSortNew hanya ada di SQL Server 2014 dan digunakan hanya untuk mengoptimalkan penyisipan ke indeks penyimpanan kolom berkerumun yang dipartisi. Ini memberikan "sort lembut".
Bagian kedua dari artikel ini akan membahas CQScanInMemSortNew , dan dua jenis prosedur tersimpan yang dikompilasi secara native OLTP Dalam Memori.



