Spark mulai hidup pada tahun 2009 sebagai proyek dalam AMPLab di University of California, Berkeley. Lebih spesifiknya, lahir dari keharusan untuk membuktikan konsep Mesos yang juga dibuat dalam AMPLab. Spark pertama kali dibahas dalam buku putih Mesos berjudul Mesos:A Platform for Fine-Grained Resource Sharing in the Data Center, yang ditulis terutama oleh Benjamin Hindman dan Matei Zaharia.
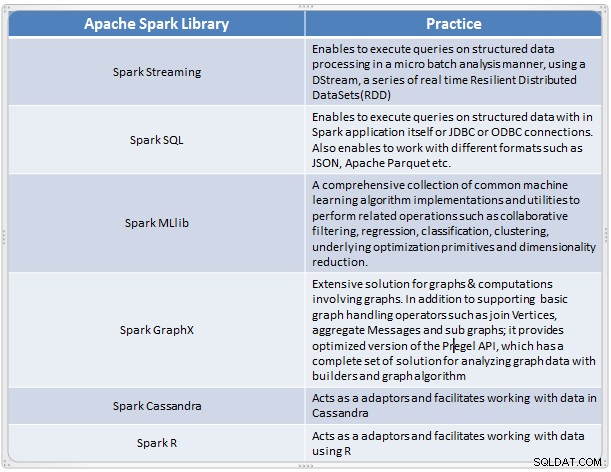
Ini muncul sebagai solusi cepat dan nyaman untuk melakukan analisis kompleks data skala besar. Spark berkembang sebagai kerangka kerja pemrosesan baru untuk data besar yang mengatasi banyak kekurangan dalam model MapReduce. Ini mendukung untuk Analisis Data skala besar, dan data dapat berasal dari sumber yang berbeda seperti waktu nyata, pemrosesan batch dalam berbagai format seperti gambar, teks, grafik, dan banyak lagi. Selain inti Apache Spark-nya, ia juga menyediakan beberapa kumpulan pustaka yang berguna untuk analitik data besar.
Ikhtisar Komponen Spark
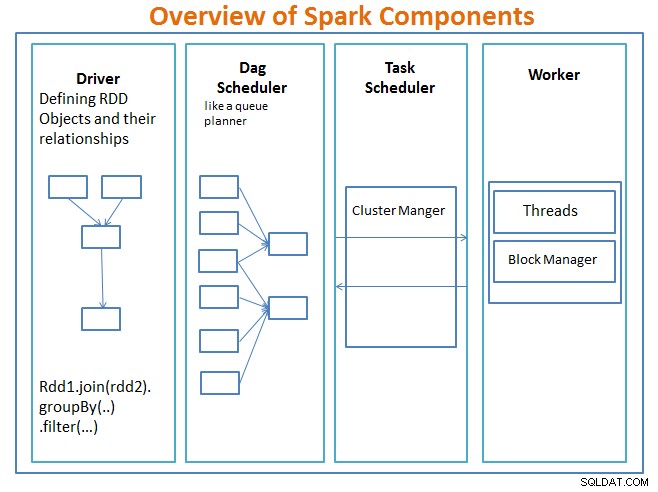
Sang pengemudi adalah kode yang menyertakan fungsi utama dan mendefinisikan kumpulan data terdistribusi tangguh (RDD) dan transformasinya. RDD adalah struktur data utama yang akan digunakan dalam program Spark kami.
Operasi paralel pada RDD dikirim ke DAG scheduler , yang akan mengoptimalkan kode dan sampai pada DAG efisien yang mewakili langkah-langkah pemrosesan data dalam aplikasi.
DAG yang dihasilkan dikirim ke pengelola klaster dan manajer cluster memiliki informasi tentang pekerja, utas yang ditetapkan, dan lokasi blok data dan bertanggung jawab untuk menetapkan tugas pemrosesan khusus kepada pekerja. Hal ini juga menangani kembali pucat dalam kasus jika kegagalan pekerja. Pengelola cluster dapat berupa YARN, Mesos, Pengelola cluster Spark.
Pekerja menerima unit kerja dan data untuk dikelola dan pekerja menjalankan tugas spesifiknya tanpa mengetahui seluruh DAG dan hasilnya dikirim kembali ke aplikasi driver.
Spark, seperti alat data besar lainnya, kuat, mampu, dan sangat cocok untuk mengatasi berbagai tantangan data. Spark, seperti teknologi data besar lainnya, belum tentu merupakan pilihan terbaik untuk setiap tugas pemrosesan data.
Di Bagian 2 – kita akan membahas Dasar-dasar Konsep Spark seperti Kumpulan Data Terdistribusi yang Tangguh, Variabel Bersama, SparkContext, Transformasi, Tindakan , dan Keuntungan menggunakan Spark beserta contoh dan waktu penggunaan Spark.
Referensi:
Pelajari Spark dalam Sehari Dengan Arsitektur Aplikasi Acodemy &Hadoop.