Sementara SQL Server di Linux telah mencuri hampir semua berita utama tentang v.Selanjutnya, ada beberapa kemajuan menarik lainnya yang datang dalam versi berikutnya dari platform database favorit kami. Di bagian depan T-SQL, kami akhirnya memiliki cara bawaan untuk melakukan penggabungan string yang dikelompokkan:STRING_AGG() .
Katakanlah kita memiliki struktur tabel sederhana berikut:
CREATE TABLE dbo.Objects( [object_id] int, [object_name] nvarchar(261), CONSTRAINT PK_Objects PRIMARY KEY([object_id])); CREATE TABLE dbo.Columns( [object_id] int NOT NULL FOREIGN KEY REFERENCES dbo.Objects([object_id]), nama_kolom sysname, CONSTRAINT PK_Columns PRIMARY KEY ([object_id],column_name));
Untuk pengujian kinerja, kita akan mengisi ini menggunakan sys.all_objects dan sys.all_columns . Tapi untuk demonstrasi sederhana dulu, mari kita tambahkan baris berikut:
INSERT dbo.Objects([object_id],[object_name]) VALUES(1,N'Karyawan'),(2,N'Orders'); INSERT dbo.Columns([object_id],column_name) NILAI(1,N'EmployeeID'),(1,N'CurrentStatus'), (2,N'OrderID'),(2,N'OrderDate'),(2 ,N'IDPelanggan');
Jika forum merupakan indikasi, itu adalah persyaratan yang sangat umum untuk mengembalikan baris untuk setiap objek, bersama dengan daftar nama kolom yang dipisahkan koma. (Ekstrapolasikan bahwa untuk jenis entitas apa pun yang Anda modelkan dengan cara ini – nama produk yang terkait dengan pesanan, nama bagian yang terlibat dalam perakitan produk, bawahan yang melapor ke manajer, dll.) Jadi, misalnya, dengan data di atas kami akan ingin keluaran seperti ini:
kolom objek--------- ----------------------------Employees EmployeeID,CurrentStatusOrders OrderID,OrderDate, ID Pelanggan
Cara kita melakukannya dalam versi SQL Server saat ini mungkin menggunakan FOR XML PATH , seperti yang saya tunjukkan sebagai yang paling efisien di luar CLR di posting sebelumnya ini. Dalam contoh ini, akan terlihat seperti ini:
SELECT [object] =o.[object_name], [columns] =STUFF( (SELECT N',' + c.column_name FROM dbo.Columns AS c WHERE c.[object_id] =o.[object_id] UNTUK XML PATH, TYPE ).nilai(N'.[1]',N'nvarchar(max)'),1,1,N'')FROM dbo.Objects AS o;
Bisa ditebak, kita mendapatkan output yang sama seperti yang ditunjukkan di atas. Dalam SQL Server v.Next, kita akan dapat mengungkapkan ini dengan lebih sederhana:
SELECT [object] =o.[object_name], [columns] =STRING_AGG(c.column_name, N',')FROM dbo.Objects AS oINNER JOIN dbo.Columns AS cON o.[object_id] =c.[ object_id]GROUP BY o.[object_name];
Sekali lagi, ini menghasilkan output yang sama persis. Dan kami dapat melakukan ini dengan fungsi asli, menghindari FOR XML PATH yang mahal perancah, dan STUFF() fungsi yang digunakan untuk menghapus koma pertama (ini terjadi secara otomatis).
Bagaimana dengan Pesanan?
Salah satu masalah dengan banyak solusi kludge untuk penggabungan yang dikelompokkan adalah bahwa urutan daftar yang dipisahkan koma harus dianggap arbitrer dan non-deterministik.
Untuk XML PATH solusi, saya menunjukkan di posting lain sebelumnya bahwa menambahkan ORDER BY sepele dan terjamin. Jadi dalam contoh ini, kita dapat mengurutkan daftar kolom menurut nama kolom menurut abjad alih-alih menyerahkannya ke SQL Server untuk diurutkan (atau tidak):
SELECT [object] =[object_name], [columns] =STUFF( (SELECT N',' +c.column_name FROM dbo.Columns AS c WHERE c.[object_id] =o.[object_id] ORDER BY c. column_name -- hanya ubah FOR XML PATH, TYPE ).value(N'.[1]',N'nvarchar(max)'),1,1,N'')FROM dbo.Objects AS o;
Keluaran:
kolom objek--------- ----------------------------Status Saat Ini Karyawan,EmployeeIDOrder CustomerID,OrderDate, IDPesanan
CTP 1.1 menambahkan WITHIN GROUP ke STRING_AGG() , jadi dengan menggunakan pendekatan baru, kita dapat mengatakan:
SELECT [object] =o.[object_name], [columns] =STRING_AGG(c.column_name, N',') WITHIN GROUP (ORDER BY c.column_name) -- hanya changeFROM dbo.Objects AS oINNER JOIN dbo. Kolom SEBAGAI con o.[object_id] =c.[object_id]GROUP BY o.[object_name];
Sekarang kita mendapatkan hasil yang sama. Perhatikan bahwa, seperti ORDER BY biasa klausa, Anda dapat menambahkan beberapa kolom atau ekspresi pemesanan di dalam WITHIN GROUP () .
Baiklah, Performa Sudah!
Menggunakan prosesor quad-core 2,6 GHz, memori 8 GB, dan SQL Server CTP1.1 (14.0.100.187), saya membuat database baru, membuat ulang tabel ini, dan menambahkan baris dari sys.all_objects dan sys.all_columns . Saya memastikan untuk hanya menyertakan objek yang memiliki setidaknya satu kolom:
INSERT dbo.Objects([object_id], [object_name]) -- 656 baris PILIH [object_id], QUOTENAME(s.name) + N'.' + QUOTENAME(o.name) FROM sys.all_objects AS o INNER JOIN sys.schemas AS s ON o.[schema_id] =s.[schema_id] WHERE EXISTS ( SELECT 1 FROM sys.all_columns WHERE [object_id] =o.[object_id] ] ); INSERT dbo.Columns([object_id], column_name) -- 8.085 baris SELECT [object_id], nama FROM sys.all_columns AS c WHERE EXISTS ( SELECT 1 FROM dbo.Objects WHERE [object_id] =c.[object_id] );Di sistem saya, ini menghasilkan 656 objek dan 8.085 kolom (sistem Anda mungkin menghasilkan angka yang sedikit berbeda).
Rencana
Pertama, mari kita bandingkan paket dan tab Tabel I/O untuk dua kueri tidak berurutan, menggunakan Plan Explorer. Berikut adalah metrik waktu proses keseluruhan:
Metrik waktu proses untuk XML PATH (atas) dan STRING_AGG() (bawah)
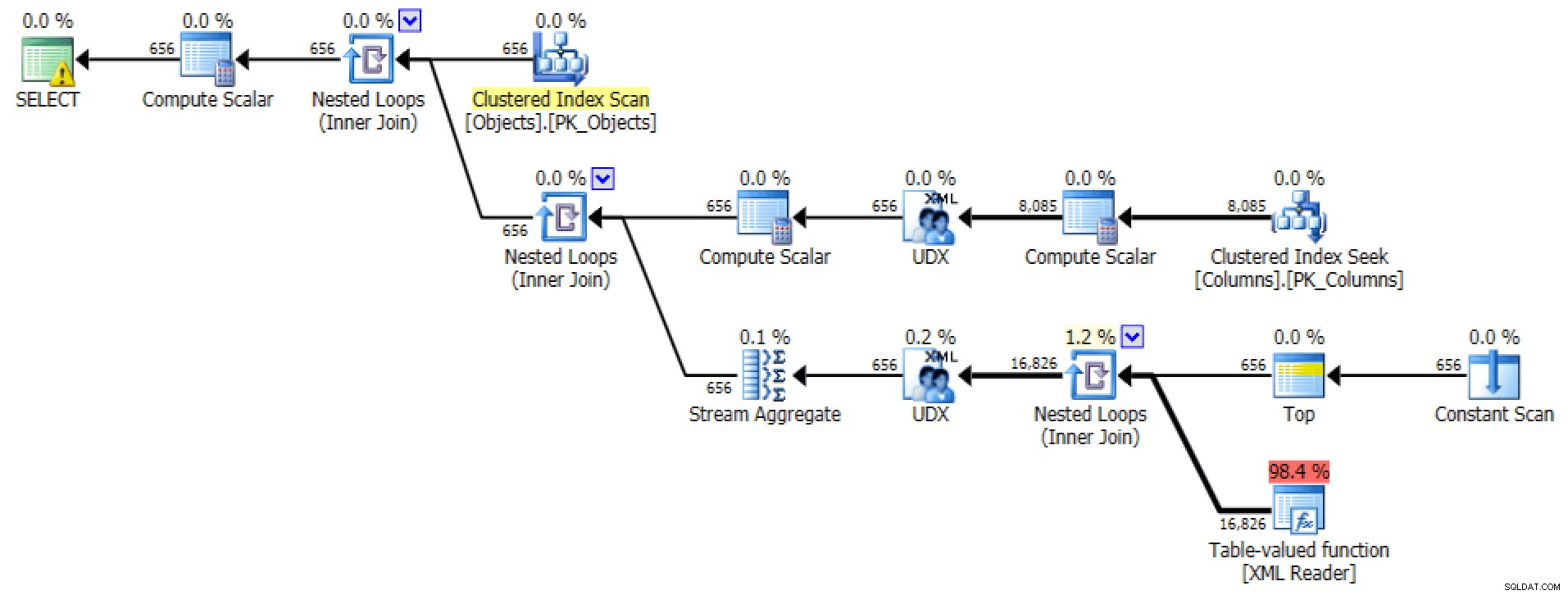
Rencana grafis dan Tabel I/O dari
FOR XML PATHpermintaan:
Rencana dan Tabel I/O untuk XML PATH, tidak ada pesanan
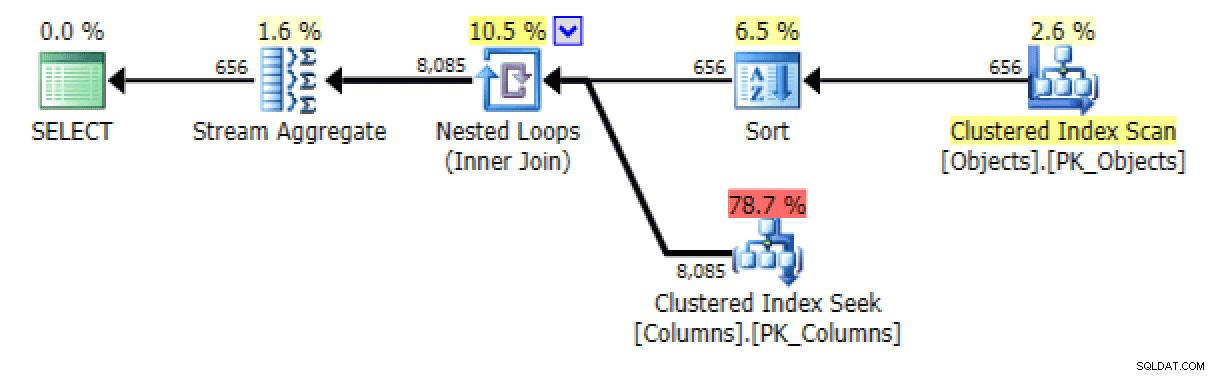
Dan dari
STRING_AGGversi:
Rencana dan Tabel I/O untuk STRING_AGG, tidak ada pemesanan
Untuk yang terakhir, pencarian indeks berkerumun tampaknya sedikit mengganggu saya. Ini sepertinya kasus yang bagus untuk menguji
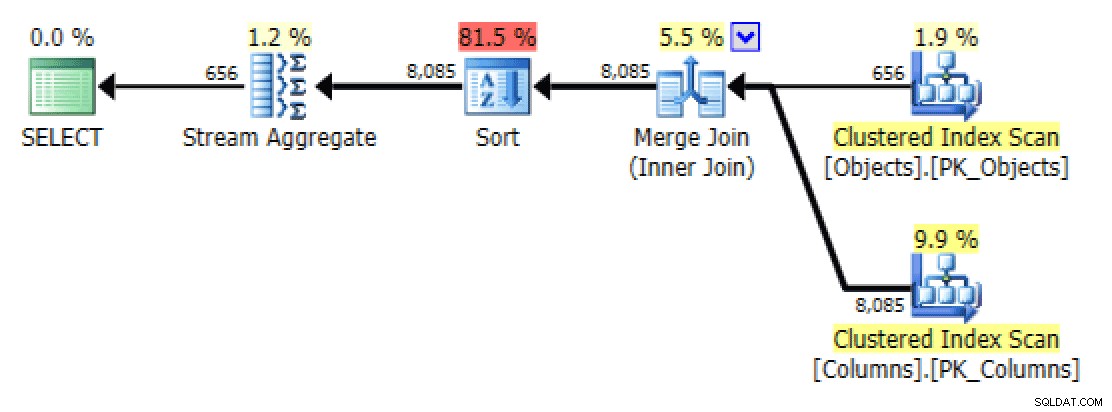
FORCESCANyang jarang digunakan petunjuk (dan tidak, ini pasti tidak akan membantuFOR XML PATHpermintaan):SELECT [object] =o.[object_name], [columns] =STRING_AGG(c.column_name, N',')FROM dbo.Objects AS oINNER JOIN dbo.Columns AS c WITH (FORCESCAN) -- menambahkan petunjuk o .[object_id] =c.[object_id]GROUP BY o.[object_name];Sekarang tab rencana dan Tabel I/O terlihat banyak lebih baik, setidaknya pada pandangan pertama:
Rencana dan Tabel I/O untuk STRING_AGG(), tanpa pemesanan, dengan FORCESCAN
Versi kueri yang dipesan menghasilkan rencana yang kira-kira sama. Untuk
FOR XML PATHversi, semacam ditambahkan:
Menambahkan pengurutan dalam versi UNTUK XML PATH
Untuk
STRING_AGG(), pemindaian dipilih dalam kasus ini, bahkan tanpaFORCESCANpetunjuk, dan tidak diperlukan operasi pengurutan tambahan – sehingga rencana terlihat identik denganFORCESCANversi.Pada Skala
Melihat rencana dan metrik runtime satu kali dapat memberi kita gambaran tentang apakah
STRING_AGG()berkinerja lebih baik daripadaFOR XML PATHyang ada solusi, tetapi tes yang lebih besar mungkin lebih masuk akal. Apa yang terjadi ketika kita melakukan penggabungan yang dikelompokkan 5.000 kali?SELECT SYSDATETIME();GO DECLARE @x nvarchar(max);SELECT @x =STRING_AGG(c.column_name, N',') FROM dbo.Objects AS o INNER JOIN dbo.Columns AS c ON o.[object_id ] =c.[object_id] GROUP BY o.[object_name];GO 5000SELECT [string_agg, unordered] =SYSDATETIME();GO DECLARE @x nvarchar(max);SELECT @x =STRING_AGG(c.column_name, N',' ) DARI dbo.Objects SEBAGAI o INNER JOIN dbo.Columns AS c WITH (FORCESCAN) ON o.[object_id] =c.[object_id] GROUP BY o.[object_name];GO 5000SELECT [string_agg, unordered, forcecan] =SYSDATETIME( ); GODECLARE @x nvarchar(max);SELECT @x =STUFF((SELECT N',' +c.column_name FROM dbo.Columns AS c WHERE c.[object_id] =o.[object_id] FOR XML PATH, TYPE).nilai (N'.[1]',N'nvarchar(max)'),1,1,N'')FROM dbo.Objects AS o;GO 5000SELECT [untuk jalur xml, tidak berurutan] =SYSDATETIME(); GODECLARE @x nvarchar(max);SELECT @x =STRING_AGG(c.column_name, N',') WITHIN GROUP (ORDER BY c.column_name) FROM dbo.Objects AS o INNER JOIN dbo.Columns AS c ON o.[object_id ] =c.[object_id] KELOMPOK OLEH o.[object_name];PERGI 5000SELECT [string_agg, dipesan] =SYSDATETIME(); GODECLARE @x nvarchar(max);SELECT @x =STUFF((SELECT N',' +c.column_name FROM dbo.Columns AS c WHERE c.[object_id] =o.[object_id] ORDER BY c.column_name FOR XML PATH , TYPE).nilai(N'.[1]',N'nvarchar(max)'),1,1,N'')FROM dbo.Objects AS oORDER BY o.[object_name];GO 5000SELECT [untuk jalur xml , dipesan] =SYSDATETIME();Setelah menjalankan script ini sebanyak lima kali, saya rata-ratakan angka durasinya dan inilah hasilnya:
Durasi (milidetik) untuk berbagai pendekatan penggabungan yang dikelompokkan
Kita dapat melihat bahwa
FORCESCANpetunjuk benar-benar memperburuk keadaan – sementara kami mengalihkan biaya dari pencarian indeks berkerumun, jenisnya sebenarnya jauh lebih buruk, meskipun perkiraan biaya menganggapnya relatif setara. Lebih penting lagi, kita dapat melihat bahwaSTRING_AGG()memang menawarkan manfaat kinerja, apakah string yang digabungkan perlu dipesan dengan cara tertentu atau tidak. SepertiSTRING_SPLIT(), yang saya lihat kembali pada bulan Maret, saya cukup terkesan bahwa fungsi ini diskalakan dengan baik sebelum "v1."Saya memiliki tes lebih lanjut yang direncanakan, mungkin untuk posting mendatang:
- Ketika semua data berasal dari satu tabel, dengan dan tanpa indeks yang mendukung pengurutan
- Tes kinerja serupa di Linux
Sementara itu, jika Anda memiliki kasus penggunaan khusus untuk penggabungan yang dikelompokkan, silakan bagikan di bawah ini (atau kirim email kepada saya di abertrand@sentryone.com). Saya selalu terbuka untuk memastikan tes saya senyata mungkin.



