Pengantar
Dalam artikel ini, kita akan berbicara tentang penggunaan nvarchar tipe data. Kami akan mengeksplorasi bagaimana SQL Server menyimpan tipe data ini pada disk dan bagaimana diproses dalam RAM. Kami juga akan memeriksa bagaimana ukuran nvarchar dapat memengaruhi kinerja.
Ukuran data aktual:nchar vs nvarchar
Kami menggunakan nvarchar ketika ukuran entri data kolom mungkin akan sangat bervariasi. Ukuran penyimpanan (dalam byte) dua kali lipat panjang sebenarnya dari data yang dimasukkan + 2 byte. Ini memungkinkan kami menghemat penyimpanan disk dibandingkan menggunakan nchar tipe data. Mari kita perhatikan contoh berikut. Kami membuat dua tabel. Satu tabel berisi kolom nvarchar, tabel lain berisi kolom nchar. Ukuran kolom adalah 2000 karakter (4000 byte).
CREATE TABLE dbo.testnvarchar (
col1 NVARCHAR(2000) NULL
);
GO
INSERT INTO dbo.testnvarchar (col1)
SELECT
REPLICATE('&', 10)
GO
CREATE TABLE dbo.testnchar (
col1 NCHAR(2000) NULL
);
GO
INSERT INTO dbo.testnchar (col1)
SELECT
REPLICATE('&', 10)
GO
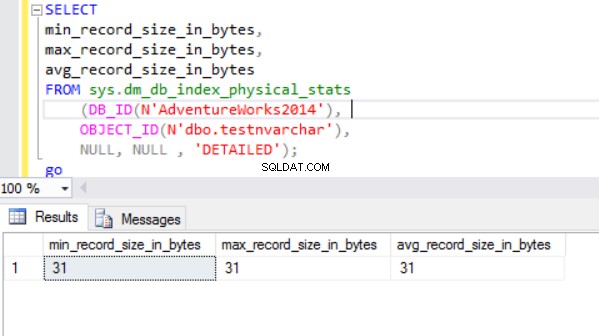
Ukuran baris sebenarnya adalah:
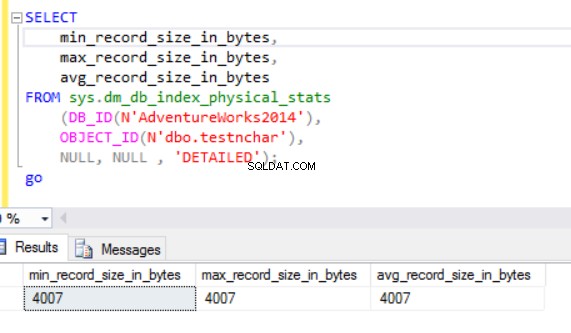
Seperti yang bisa kita lihat, ukuran baris sebenarnya dari tipe data nvarchar jauh lebih kecil daripada tipe data nchar. Dalam kasus tipe data nchar, kami menggunakan ~4000 byte untuk menyimpan 10 simbol karakter string. Kami menggunakan ~20 byte untuk menyimpan string karakter yang sama untuk tipe data nvarchar.
Mesin SQL Server memproses data menjadi RAM (buffer pool). Bagaimana dengan ukuran baris di memori?
Ukuran data aktual:HDD vs RAM
Mari kita jalankan kueri berikut:
SELECT col1 FROM dbo.testnchar;

Tidak ada perbedaan antara penggunaan disk dan RAM dalam hal string karakter dengan panjang tetap.
SELECT col1 FROM dbo.testnvarchar;

Kita dapat melihat bahwa SQL Server Engine meminta memori hanya setengah dari ukuran baris yang dideklarasikan (2000 byte, bukan 20 byte sebenarnya) dan beberapa byte untuk informasi tambahan. Dari satu sisi kami mengurangi penggunaan ruang disk tetapi dari sisi lain kami dapat meningkatkan RAM yang diminta. Ini adalah efek samping dari penggunaan tipe data karakter yang bervariasi. Efek samping ini dapat berdampak besar pada sumber daya dalam beberapa kasus.
FORMAT():RAM yang diminta vs RAM yang digunakan
Kami menggunakan fungsi FORMAT, yang mengembalikan nilai yang diformat dengan format yang ditentukan dan budaya opsional. Nilai yang dikembalikan adalah nvarchar atau nol. Panjang nilai yang dikembalikan ditentukan oleh format . FORMAT(getdate(), 'yyyyMMdd','en-US') akan menghasilkan '20170412'. Kita membutuhkan 16 byte untuk menyimpan hasil ini pada kolom pada disk (hasilnya adalah nvarchar(8)). Berapa ukuran data dalam RAM untuk data tertentu?
Mari kita jalankan kueri berikut. Kami menggunakan lingkungan berikut:
- PetualanganKerja2014
- Edisi pengembangan MS SQL 2016
- dbo.Pelanggan (19'820.000 catatan) berisi data dari Penjualan.Pelanggan (19'820 catatan telah diunggah 1000 kali)):
;WITH rs
AS
(SELECT
c.customerid
,c.modifieddate
,p.LastName
FROM [dbo].[Customer] c
LEFT OUTER JOIN [person].[person] p
ON p.BusinessEntityID = c.PersonID)
SELECT
customerid
,LastName
,FORMAT([modifieddate], 'yyyyMMdd', 'en-US') AS md
,' ' AS code INTO #tmp
FROM rs
Rencana eksekusi kueri cukup sederhana:

Operasi pertama adalah “Clustered index scan” pada tabel dbo.Customer. ~19 000 000 catatan telah dibaca. Perkiraan Ukuran Data adalah 435 Mb.
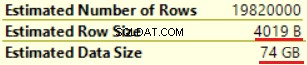
Operasi selanjutnya adalah “Hitung Skalar” (perhitungan fungsi FORMAT()). Hasilnya cukup tidak terduga karena kami memformat string karakter 16 byte. Ukuran baris meningkat secara dramatis dari 23 byte menjadi 4019 byte. Sama dengan Perkiraan Ukuran Data — dari 435 MB hingga 74 GB. Kita dapat melihat bahwa FORMAT() mengembalikan NVARCHAR(4000).
MS SQL Server 2016 memiliki kemampuan hebat untuk menunjukkan pemberian memori yang berlebihan. Kita dapat melihat peringatan pada operasi terakhir (T-SQL SELECT INTO):
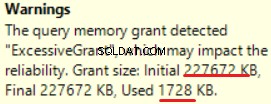
Ini adalah memori yang “terlalu diberikan”:lebih dari 90% memori yang diberikan tidak digunakan.
Statistik waktu kueri adalah:
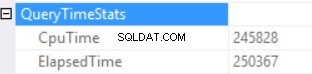
Waktu eksekusi yang lama tergantung pada eksekusi fungsi skalar yang tidak efektif dan efek samping dari Pemberian Memori Berlebihan – Pencocokan Hash (Gabungan Luar Kanan). Kami mendapat efek kumulatif dari dua penyebab berbeda:eksekusi fungsi skalar ganda dan pemberian memori yang berlebihan.
Mesin SQL Server dapat memberikan tidak lebih dari 25% dari memori yang diizinkan per kueri. Kami dapat mengubah jumlah ini di MS SQL Server edisi perusahaan menggunakan gubernur sumber daya. Memori yang diberikan terdiri dari dua bagian:diperlukan dan tambahan. Memori yang diperlukan digunakan untuk kebutuhan internal – untuk menyortir dan menggabungkan operasi hash. Memori tambahan didasarkan pada Perkiraan Ukuran Data. Jika diperlukan dan memori tambahan melebihi batas 25%, mesin SQL Server memberikan 25% dari memori yang tersedia. Baca pos pemberian memori SQL Server untuk detailnya.
Mari kita jalankan kueri yang sama tanpa fungsi FORMAT().
;WITH rs
AS
(SELECT
c.customerid
,c.modifieddate
,p.LastName
FROM [dbo].[Customer] c
LEFT OUTER JOIN [person].[person] p
ON p.BusinessEntityID = c.PersonID)
SELECT
customerid
,LastName
,' ' AS code INTO #tmp
FROM rs
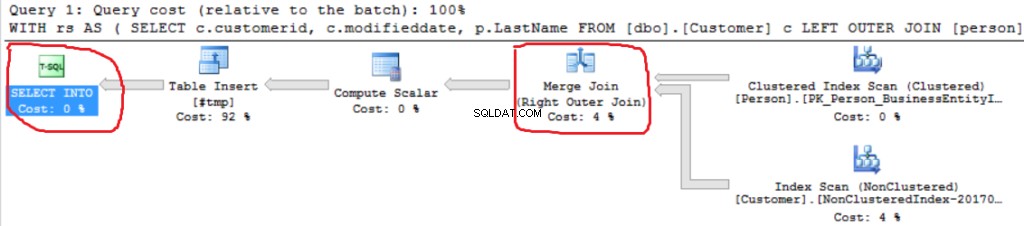
Kita bisa melihat implementasi Right Outer Join lainnya (Merge Join bukan Hash Join).
Info Memory Grant adalah (jika tidak ada Sorting dan Hash Join SQL Server tidak dapat memberikan memori):
Statistik waktu kueri adalah (waktu berkurang secara dapat diprediksi:tidak ada eksekusi fungsi skalar, Perkiraan Ukuran Data lebih kecil dari pada sampel sebelumnya):

Jadi, kami menggembungkan "memori yang diberikan" hingga 222 MB (dan menggunakan kurang dari 2 MB) dengan menggunakan fungsi FORMAT(). Volume data dalam contoh kecil.
Kueri eksekusi lama
Pertimbangkan kueri SQL nyata dari lingkungan produksi. Kueri ini telah dijalankan selama proses pemuatan batch (bukan skenario transaksional klasik). Kami menggunakan MS SQL Server yang dimulai di Amazon Web Services (AWS, Amazon Relational Database Service). Karakteristik instans DB adalah 160 GB RAM (tidak lebih dari ~30 GB RAM yang dapat diberikan per kueri) dan 40 vCPU. Query SQL-nya hampir sama dengan contoh di atas (perbedaannya pada jumlah tabel dan ukuran data):CTE termasuk join antara 6 tabel. "Tabel Master" (tabel dalam klausa FROM) berisi ~175'000'000 record dan ukuran datanya adalah 20GB. Tabel Lookup (tabel kanan dalam klausa JOIN) berukuran kecil (dibandingkan dengan tabel utama). Kueri SQL berisi dua panggilan fungsi FORMAT() (dua kolom dari tabel "tabel master" adalah parameter dari fungsi ini).
Kueri produksi terlihat seperti ini:
;WITH rs AS ( SELECT <in column list>, c.modifieddate, c.createddate FROM [Master table] c LEFT OUTER JOIN [table1 ] p1 ON … LEFT OUTER JOIN [table2 ] p2 ON … LEFT OUTER JOIN [table3 ] p3 ON … LEFT OUTER JOIN [table4 ] p4 ON … LEFT OUTER JOIN [table5 ] p5 ON … ) SELECT DISTINT <out column list>, FORMAT([modifieddate], 'yyyyMMdd','en-US') AS md, FORMAT([createddate], 'yyyyMMdd','en-US') AS cd INTO #tmp FROM rs
“Gambar” rencana eksekusi ada di bawah (rencana eksekusi sederhana:penggabungan dan pengurutan berurutan (kata kunci BERBEDA) di atas):

Mari kita telusuri informasinya secara detail.
Operasi pertama adalah "Pemindaian tabel" (semuanya benar, tidak ada kejutan):

Operasi "Komputasi skalar" meningkatkan secara dramatis Perkiraan Ukuran Baris serta Perkiraan Ukuran Baris (dari 19 GB hingga 1,3 TB). Dua panggilan fungsi FORMAT() menambahkan sekitar 8000 byte ke Perkiraan Ukuran Baris (tetapi ukuran data sebenarnya lebih kecil).

Salah satu operasi JOIN (Hash Match, Right Outer Join) menggunakan kolom non-unik dari tabel kanan. Tidak masalah dalam kasus beberapa catatan. Ini bukan kasus kami. Akibatnya, Perkiraan Ukuran Data meningkat hingga ~2,4 TB.

Ada peringatan juga (RAM tidak cukup untuk memproses operasi ini):
Kueri SQL berisi operasi "Urutan Berbeda" di bagian atas, yang terlihat seperti buah ceri di bagian atas kue. Kita bisa melihat peringatan yang sama di sana.
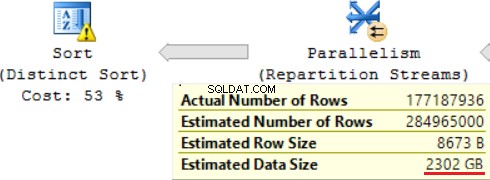
Hasil dari penggunaan fungsi skalar adalah waktu yang lama untuk eksekusi query:24 jam. Salah satu penyebab masalah ini adalah perkiraan yang salah dari ukuran data yang diminta berdasarkan "Perkiraan Ukuran Data". Tanpa menggunakan fungsi FORMAT(), MS SQL Server mengeksekusi query ini dalam 2 jam.
Kesimpulan
Pengembang harus berhati-hati saat menggunakan tipe data nvarchar dan varchar. Memilih tipe data yang berlebihan untuk kolom dapat menyebabkan peningkatan memori yang diperlukan. Akibatnya, RAM akan terbuang percuma, kinerja database akan menurun.