Minggu lalu, saya membuat beberapa perbandingan kinerja cepat, mengadu STRING_AGG() baru berfungsi melawan FOR XML PATH tradisional pendekatan yang telah saya gunakan selama berabad-abad. Saya menguji urutan tidak terdefinisi/sewenang-wenang serta urutan eksplisit, dan STRING_AGG() keluar di atas dalam kedua kasus:
- SQL Server v.Berikutnya :Performa STRING_AGG(), Bagian 1
Untuk tes tersebut, saya mengabaikan beberapa hal (tidak semuanya dengan sengaja):
- Mikael Eriksson dan Grzegorz yp keduanya menunjukkan bahwa saya tidak menggunakan
FOR XML PATHyang paling efisien. membangun (dan untuk menjadi jelas, saya tidak pernah). - Saya tidak melakukan tes apa pun di Linux; hanya di Windows. Saya tidak berharap itu akan sangat berbeda, tetapi karena Grzegorz melihat durasi yang sangat berbeda, ini layak untuk diselidiki lebih lanjut.
- Saya juga hanya menguji ketika output akan menjadi string non-LOB yang terbatas – yang saya yakini adalah kasus penggunaan yang paling umum (saya tidak berpikir orang biasanya akan menggabungkan setiap baris dalam sebuah tabel menjadi satu yang dipisahkan koma string, tetapi inilah mengapa saya bertanya di posting saya sebelumnya untuk kasus penggunaan Anda).
- Untuk pengujian pemesanan, saya tidak membuat indeks yang mungkin berguna (atau mencoba apa pun yang semua datanya berasal dari satu tabel).
Dalam posting ini, saya akan membahas beberapa item ini, tetapi tidak semuanya.
UNTUK JALAN XML
Saya telah menggunakan yang berikut ini:
... FOR XML PATH, TYPE).value(N'.[1]', ...
Setelah komentar dari Mikael ini, saya telah memperbarui kode saya untuk menggunakan konstruksi yang sedikit berbeda ini:
... FOR XML PATH(''), TYPE).value(N'text()[1]', ... Linux vs. Windows
Awalnya, saya hanya repot-repot menjalankan tes di Windows:
Microsoft SQL Server vNext (CTP1.1) - 14.0.100.187 (X64) Dec 10 2016 02:51:11 Copyright (C) 2016 Microsoft Corporation. All rights reserved. Developer Edition (64-bit) on Windows Server 2016 Datacenter 6.3(Build 14393: ) (Hypervisor)
Tapi Grzegorz membuat poin yang adil bahwa dia (dan mungkin banyak lainnya) hanya memiliki akses ke Linux rasa CTP 1.1. Jadi saya menambahkan Linux ke matriks pengujian saya:
Microsoft SQL Server vNext (CTP1.1) - 14.0.100.187 (X64) Dec 10 2016 02:51:11 Copyright (C) 2016 Microsoft Corporation. All rights reserved. on Linux (Ubuntu 16.04.1 LTS)
Beberapa pengamatan yang menarik tetapi sepenuhnya tangensial:
@@VERSIONtidak menampilkan edisi dalam build ini, tetapiSERVERPROPERTY('Edition')mengembalikanDeveloper Edition (64-bit)yang diharapkan .- Berdasarkan waktu pembuatan yang dikodekan ke dalam binari, versi Windows dan Linux tampaknya sekarang dikompilasi pada waktu yang sama dan dari sumber yang sama. Atau ini adalah satu kebetulan yang gila.
Tes tidak berurutan
Saya mulai dengan menguji output yang dipesan secara sewenang-wenang (di mana tidak ada urutan yang ditentukan secara eksplisit untuk nilai gabungan). Mengikuti Grzegorz, saya menggunakan WideWorldImporters (Standar), tetapi melakukan penggabungan antara Sales.Orders dan Sales.OrderLines . Persyaratan fiktif di sini adalah untuk menampilkan daftar semua pesanan, dan bersama dengan setiap pesanan, daftar yang dipisahkan koma dari setiap StockItemID .
Sejak StockItemID adalah bilangan bulat, kita dapat menggunakan varchar yang ditentukan , yang berarti string bisa menjadi 8000 karakter sebelum kita harus khawatir membutuhkan MAX. Karena int bisa menjadi panjang maksimal 11 (benar-benar 10, jika tidak ditandatangani), ditambah koma, ini berarti pesanan harus mendukung sekitar 8,000/12 (666) item stok dalam skenario terburuk (misalnya semua nilai StockItemID memiliki 11 angka). Dalam kasus kami, ID terpanjang adalah 3 digit, jadi sampai data ditambahkan, kami sebenarnya membutuhkan 8.000/4 (2.000) item stok unik dalam satu urutan untuk membenarkan MAX. Dalam kasus kami, total stok hanya ada 227 item, jadi MAX tidak diperlukan, tetapi Anda harus mengawasinya. Jika string sebesar itu dimungkinkan dalam skenario Anda, Anda harus menggunakan varchar(max) alih-alih default (STRING_AGG() mengembalikan nvarchar(max) , tetapi terpotong menjadi 8.000 byte kecuali input adalah tipe MAX).
Kueri awal (untuk menampilkan contoh keluaran, dan untuk mengamati durasi untuk eksekusi tunggal):
SET STATISTICS TIME ON;
GO
SELECT o.OrderID, StockItemIDs = STRING_AGG(ol.StockItemID, ',')
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID;
GO
SELECT o.OrderID,
StockItemIDs = STUFF((SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),1,1,'')
FROM Sales.Orders AS o
GROUP BY o.OrderID;
GO
SET STATISTICS TIME OFF;
/*
Sample output:
OrderID StockItemIDs
======= ============
1 67
2 50,10
3 114
4 206,130,50
5 128,121,155
Important SET STATISTICS TIME metrics (SQL Server Execution Times):
Windows:
STRING_AGG: CPU time = 217 ms, elapsed time = 405 ms.
FOR XML PATH: CPU time = 1954 ms, elapsed time = 2097 ms.
Linux:
STRING_AGG: CPU time = 627 ms, elapsed time = 472 ms.
FOR XML PATH: CPU time = 2188 ms, elapsed time = 2223 ms.
*/
Saya mengabaikan penguraian dan kompilasi data waktu sepenuhnya, karena mereka selalu persis nol atau cukup dekat untuk menjadi tidak relevan. Ada sedikit perbedaan dalam waktu eksekusi untuk setiap proses, tetapi tidak banyak – komentar di atas mencerminkan delta tipikal dalam waktu proses (STRING_AGG tampaknya mengambil sedikit keuntungan dari paralelisme di sana, tetapi hanya di Linux, sementara FOR XML PATH tidak pada kedua platform). Kedua mesin memiliki satu soket, CPU quad-core yang dialokasikan, memori 8 GB, konfigurasi yang siap pakai, dan tidak ada aktivitas lain.
Kemudian saya ingin menguji pada skala (cukup satu sesi menjalankan kueri yang sama 500 kali). Saya tidak ingin mengembalikan semua output, seperti pada kueri di atas, 500 kali, karena itu akan membuat SSMS kewalahan – dan semoga tidak mewakili skenario kueri dunia nyata. Jadi saya menetapkan output ke variabel dan hanya mengukur waktu keseluruhan untuk setiap batch:
SELECT sysdatetime();
GO
DECLARE @i int, @x varchar(8000);
SELECT @i = o.OrderID, @x = STRING_AGG(ol.StockItemID, ',')
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID;
GO 500
SELECT sysdatetime();
GO
DECLARE @i int, @x varchar(8000);
SELECT @i = o.OrderID,
@x = STUFF((SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),1,1,'')
FROM Sales.Orders AS o
GROUP BY o.OrderID;
GO 500
SELECT sysdatetime(); Saya menjalankan tes itu tiga kali, dan perbedaannya sangat besar – hampir seperti urutan besarnya. Berikut adalah durasi rata-rata di ketiga tes:
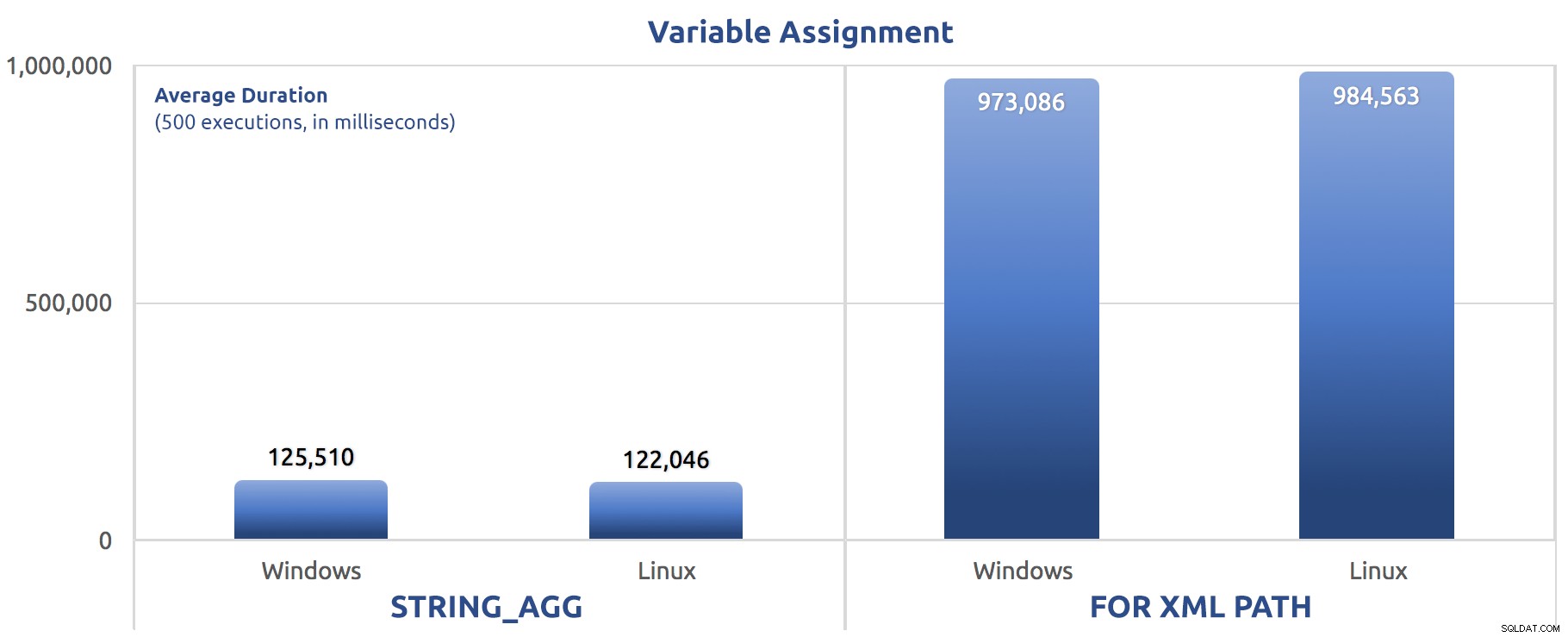 Durasi rata-rata, dalam milidetik, untuk 500 eksekusi penetapan variabel
Durasi rata-rata, dalam milidetik, untuk 500 eksekusi penetapan variabel
Saya menguji berbagai hal lain dengan cara ini juga, sebagian besar untuk memastikan saya mencakup jenis tes yang dijalankan Grzegorz (tanpa bagian LOB).
- Memilih hanya panjang keluaran
- Mendapatkan panjang maksimum keluaran (dari baris arbitrer)
- Memilih semua output ke dalam tabel baru
Memilih hanya panjang keluaran
Kode ini hanya berjalan melalui setiap pesanan, menggabungkan semua nilai StockItemID, dan kemudian mengembalikan panjangnya saja.
SET STATISTICS TIME ON;
GO
SELECT LEN(STRING_AGG(ol.StockItemID, ','))
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID;
GO
SELECT LEN(STUFF((SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),1,1,''))
FROM Sales.Orders AS o
GROUP BY o.OrderID;
GO
SET STATISTICS TIME OFF;
/*
Windows:
STRING_AGG: CPU time = 142 ms, elapsed time = 351 ms.
FOR XML PATH: CPU time = 1984 ms, elapsed time = 2120 ms.
Linux:
STRING_AGG: CPU time = 310 ms, elapsed time = 191 ms.
FOR XML PATH: CPU time = 2149 ms, elapsed time = 2167 ms.
*/ Untuk versi batch, sekali lagi, saya menggunakan penetapan variabel, daripada mencoba mengembalikan banyak hasil ke SSMS. Penetapan variabel akan berakhir pada baris arbitrer, tetapi ini masih memerlukan pemindaian penuh, karena baris arbitrer tidak dipilih terlebih dahulu.
SELECT sysdatetime();
GO
DECLARE @i int;
SELECT @i = LEN(STRING_AGG(ol.StockItemID, ','))
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID;
GO 500
SELECT sysdatetime();
GO
DECLARE @i int;
SELECT @i = LEN(STUFF((SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),1,1,''))
FROM Sales.Orders AS o
GROUP BY o.OrderID;
GO 500
SELECT sysdatetime(); Metrik kinerja dari 500 eksekusi:
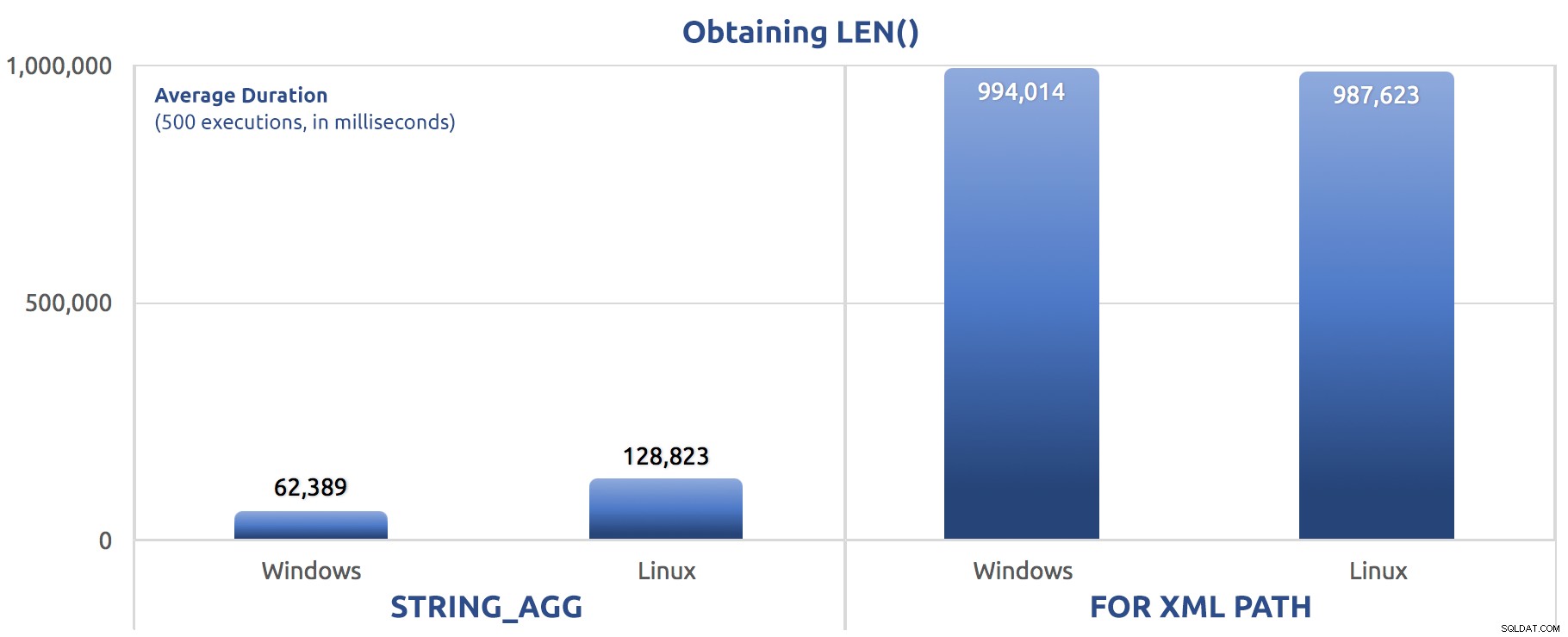 500 eksekusi penetapan LEN() ke variabel
500 eksekusi penetapan LEN() ke variabel
Sekali lagi, kita melihat FOR XML PATH jauh lebih lambat, baik di Windows maupun Linux.
Memilih panjang maksimum keluaran
Sedikit variasi pada tes sebelumnya, yang ini hanya mengambil maksimum panjang output gabungan:
SET STATISTICS TIME ON;
GO
SELECT MAX(s) FROM (SELECT s = LEN(STRING_AGG(ol.StockItemID, ','))
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID) AS x;
GO
SELECT MAX(s) FROM (SELECT s = LEN(STUFF(
(SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),
1,1,''))
FROM Sales.Orders AS o
GROUP BY o.OrderID) AS x;
GO
SET STATISTICS TIME OFF;
/*
Windows:
STRING_AGG: CPU time = 188 ms, elapsed time = 48 ms.
FOR XML PATH: CPU time = 1891 ms, elapsed time = 907 ms.
Linux:
STRING_AGG: CPU time = 270 ms, elapsed time = 83 ms.
FOR XML PATH: CPU time = 2725 ms, elapsed time = 1205 ms.
*/ Dan pada skala, kami hanya menetapkan output itu ke variabel lagi:
SELECT sysdatetime();
GO
DECLARE @i int;
SELECT @i = MAX(s) FROM (SELECT s = LEN(STRING_AGG(ol.StockItemID, ','))
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID) AS x;
GO 500
SELECT sysdatetime();
GO
DECLARE @i int;
SELECT @i = MAX(s) FROM (SELECT s = LEN(STUFF
(
(SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),
1,1,''))
FROM Sales.Orders AS o
GROUP BY o.OrderID) AS x;
GO 500
SELECT sysdatetime(); Hasil kinerja, untuk 500 eksekusi, rata-rata dalam tiga kali proses:
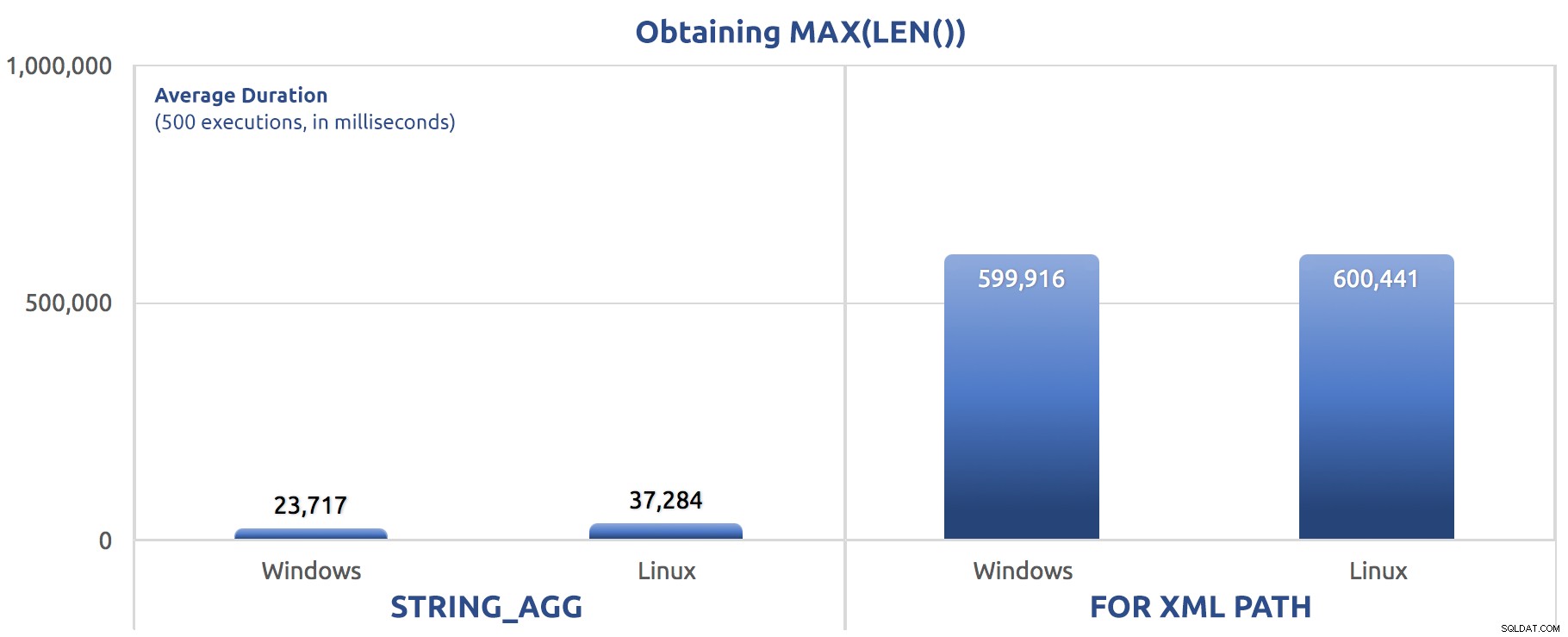 500 eksekusi penetapan MAX(LEN()) ke variabel
500 eksekusi penetapan MAX(LEN()) ke variabel
Anda mungkin mulai melihat pola di seluruh pengujian ini – FOR XML PATH selalu anjing, bahkan dengan peningkatan kinerja yang disarankan di posting saya sebelumnya.
PILIH KE
Saya ingin melihat apakah metode penggabungan berdampak pada menulis data kembali ke disk, seperti yang terjadi dalam beberapa skenario lain:
SET NOCOUNT ON;
GO
SET STATISTICS TIME ON;
GO
DROP TABLE IF EXISTS dbo.HoldingTank_AGG;
SELECT o.OrderID, x = STRING_AGG(ol.StockItemID, ',')
INTO dbo.HoldingTank_AGG
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID;
GO
DROP TABLE IF EXISTS dbo.HoldingTank_XML;
SELECT o.OrderID, x = STUFF((SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),1,1,'')
INTO dbo.HoldingTank_XML
FROM Sales.Orders AS o
GROUP BY o.OrderID;
GO
SET STATISTICS TIME OFF;
/*
Windows:
STRING_AGG: CPU time = 218 ms, elapsed time = 90 ms.
FOR XML PATH: CPU time = 4202 ms, elapsed time = 1520 ms.
Linux:
STRING_AGG: CPU time = 277 ms, elapsed time = 108 ms.
FOR XML PATH: CPU time = 4308 ms, elapsed time = 1583 ms.
*/
Dalam hal ini kita melihat bahwa mungkin SELECT INTO dapat memanfaatkan sedikit paralelisme, tetapi kami masih melihat FOR XML PATH berjuang, dengan runtime urutan besarnya lebih lama dari STRING_AGG .
Versi batch baru saja menukar perintah SET STATISTICS untuk SELECT sysdatetime(); dan menambahkan GO 500 yang sama setelah dua batch utama seperti tes sebelumnya. Begini hasilnya (sekali lagi, beri tahu saya jika Anda pernah mendengar yang ini sebelumnya):
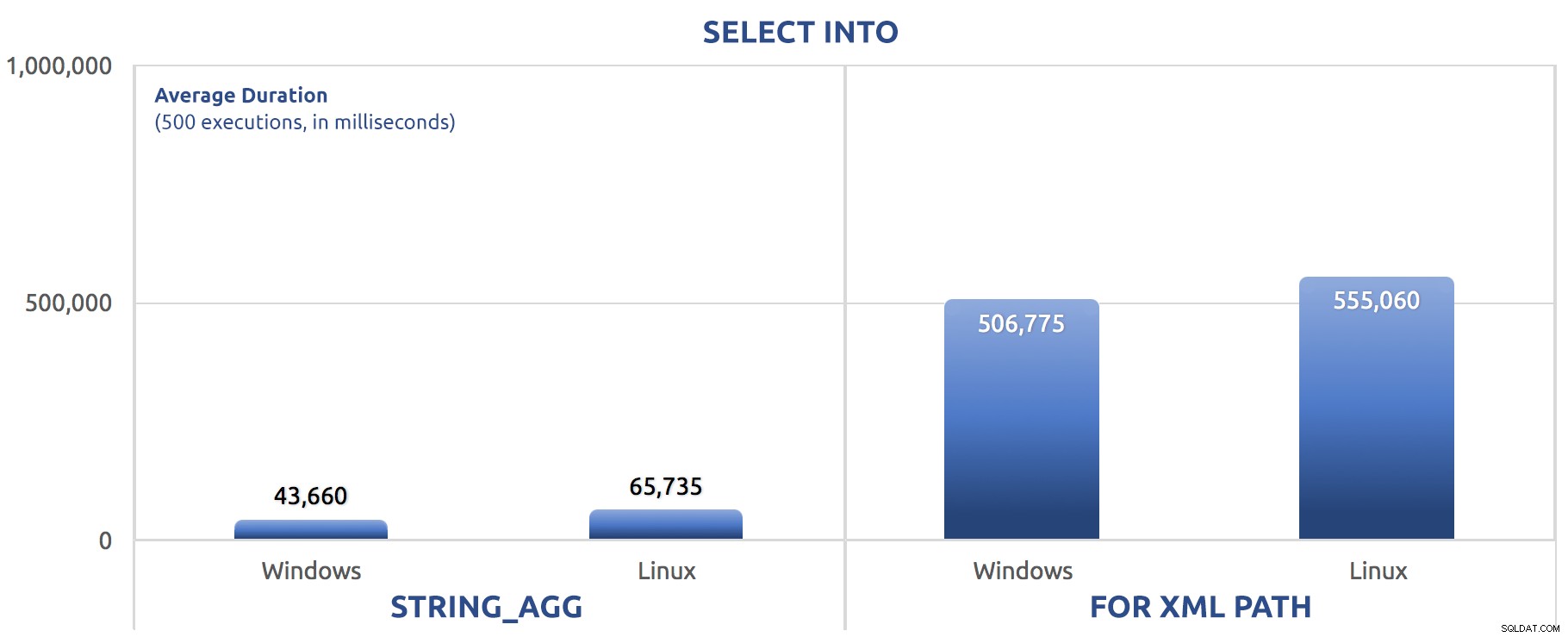 500 eksekusi SELECT INTO
500 eksekusi SELECT INTO
Tes yang Dipesan
Saya menjalankan tes yang sama menggunakan sintaks yang dipesan, mis.:
... STRING_AGG(ol.StockItemID, ',')
WITHIN GROUP (ORDER BY ol.StockItemID) ...
... WHERE ol.OrderID = o.OrderID
ORDER BY ol.StockItemID
FOR XML PATH('') ... Ini berdampak sangat kecil pada apa pun – rangkaian empat rig uji yang sama menunjukkan metrik dan pola yang hampir identik di seluruh papan.
Saya akan penasaran untuk melihat apakah ini berbeda ketika output gabungan di non-LOB atau di mana rangkaian perlu memesan string (dengan atau tanpa indeks pendukung).
Kesimpulan
Untuk string non-LOB , jelas bagi saya bahwa STRING_AGG memiliki keunggulan kinerja definitif dibandingkan FOR XML PATH , di Windows dan Linux. Perhatikan bahwa, untuk menghindari persyaratan varchar(max) atau nvarchar(max) , saya tidak menggunakan apa pun yang mirip dengan tes yang dijalankan Grzegorz, yang berarti hanya menggabungkan semua nilai dari kolom, di seluruh tabel, menjadi satu string. Dalam posting saya berikutnya, saya akan melihat kasus penggunaan di mana output dari string yang digabungkan secara layak bisa lebih besar dari 8.000 byte, sehingga jenis dan konversi LOB harus digunakan.