Bukankah bagus memiliki versi baru SQL Server yang tersedia? Ini adalah sesuatu yang hanya terjadi setiap beberapa tahun, dan bulan ini kami melihat satu mencapai Ketersediaan Umum. (Oke, saya tahu kami mendapatkan versi baru Database SQL di Azure hampir terus-menerus, tapi saya menganggap ini berbeda.) Mengakui rilis baru ini, T-SQL Tuesday bulan ini (diselenggarakan oleh Michael Swart – @mjswart) menjadi topik semua hal tentang SQL Server 2016!
Bukankah bagus memiliki versi baru SQL Server yang tersedia? Ini adalah sesuatu yang hanya terjadi setiap beberapa tahun, dan bulan ini kami melihat satu mencapai Ketersediaan Umum. (Oke, saya tahu kami mendapatkan versi baru Database SQL di Azure hampir terus-menerus, tapi saya menganggap ini berbeda.) Mengakui rilis baru ini, T-SQL Tuesday bulan ini (diselenggarakan oleh Michael Swart – @mjswart) menjadi topik semua hal tentang SQL Server 2016!
Jadi hari ini saya ingin melihat fitur Tabel Temporal SQL 2016, dan melihat beberapa situasi rencana kueri yang akhirnya bisa Anda lihat. Saya suka Tabel Temporal, tetapi telah menemukan sedikit masalah yang mungkin ingin Anda ketahui.
Sekarang, terlepas dari kenyataan bahwa SQL Server 2016 sekarang dalam RTM, saya menggunakan AdventureWorks2016CTP3, yang dapat Anda unduh di sini – tetapi jangan hanya mengunduh AdventureWorks2016CTP3.bak , juga ambil SQLServer2016CTP3Samples.zip dari situs yang sama.
Anda lihat, di arsip Sampel, ada beberapa skrip yang berguna untuk mencoba fitur baru, termasuk beberapa untuk Tabel Temporal. Ini menang-menang – Anda dapat mencoba banyak fitur baru, dan saya tidak perlu mengulangi banyak skrip di postingan ini. Pokoknya, buka dan ambil dua skrip tentang Tabel Temporal, jalankan AW 2016 CTP3 Temporal Setup.sql , diikuti oleh Temporal System-Versioning Sample.sql .
Skrip ini menyiapkan versi temporal dari beberapa tabel, termasuk HumanResources.Employee . Itu menciptakan HumanResources.Employee_Temporal (walaupun, secara teknis, itu bisa disebut apa saja). Di akhir CREATE TABLE pernyataan, bit ini muncul, menambahkan dua kolom tersembunyi untuk digunakan untuk menunjukkan kapan baris tersebut valid, dan menunjukkan bahwa sebuah tabel harus dibuat bernama HumanResources.Employee_Temporal_History untuk menyimpan versi lama.
... ValidFrom datetime2(7) DIHASILKAN SELALU ROW MULAI TERSEMBUNYI BUKAN NULL, ValidTo datetime2(7) DIHASILKAN SELALU ROW END HIDDEN NOT NULL, PERIODE FOR SYSTEM_TIME (ValidFrom, ValidTo)) WITH (SYSTEM_VERSIONING =HIDDEN (HIDDEN_TABLE) =[Sumber Daya Manusia].[Employee_Temporal_History]));
Apa yang ingin saya jelajahi dalam posting ini adalah apa yang terjadi dengan rencana kueri saat riwayat digunakan.
Jika saya meminta tabel untuk melihat baris terbaru untuk BusinessEntityID tertentu , saya mendapatkan Pencarian Indeks Berkelompok, seperti yang diharapkan.
SELECT e.BusinessEntityID, e.ValidFrom, e.ValidToFROM HumanResources.Employee_Temporal AS eWHERE e.BusinessEntityID =4;
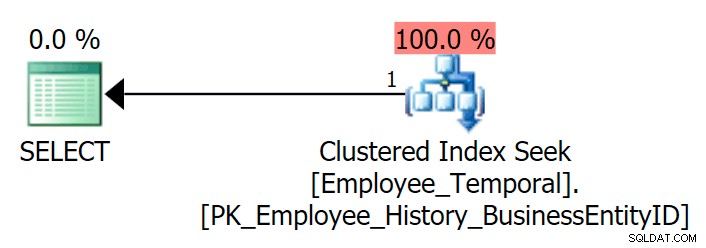
Saya yakin saya bisa menanyakan tabel ini menggunakan indeks lain, jika ada. Tetapi dalam kasus ini, tidak. Mari kita buat.
BUAT INDEKS UNIK rf_ix_Login di HumanResources.Employee_Temporal(LoginID);
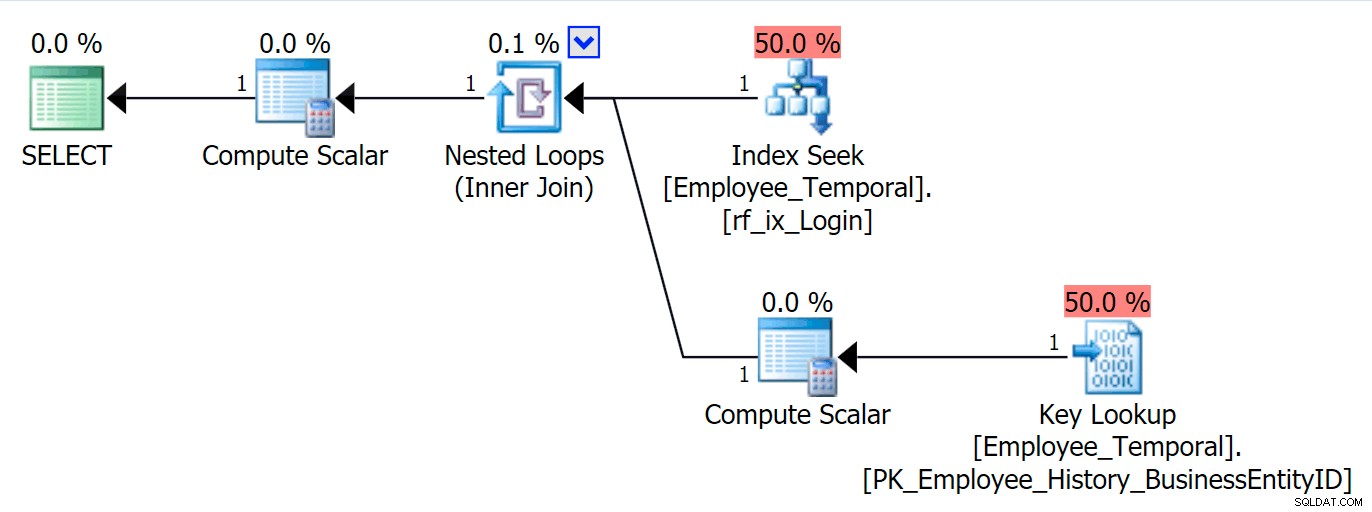
Sekarang saya dapat menanyakan tabel dengan LoginID , dan akan melihat Pencarian Kunci jika saya meminta kolom selain Loginid atau BusinessEntityID . Semua ini tidak mengejutkan.
SELECT * FROM HumanResources.Employee_Temporal eWHERE e.LoginID =N'adventure-works\rob0';
Mari kita gunakan SQL Server Management Studio sebentar, dan lihat bagaimana tabel ini terlihat di Object Explorer.

Kita dapat melihat tabel History yang disebutkan di bawah HumanResources.Employee_Temporal , dan kolom serta indeks dari tabel itu sendiri dan tabel riwayat. Tetapi sementara indeks pada tabel yang tepat adalah Kunci Utama (pada BusinessEntityID ) dan indeks yang baru saja saya buat, tabel Riwayat tidak memiliki indeks yang cocok.
Indeks pada tabel riwayat ada di ValidTo dan ValidFrom . Kita dapat mengklik kanan indeks dan memilih Properties, dan kita melihat dialog ini:
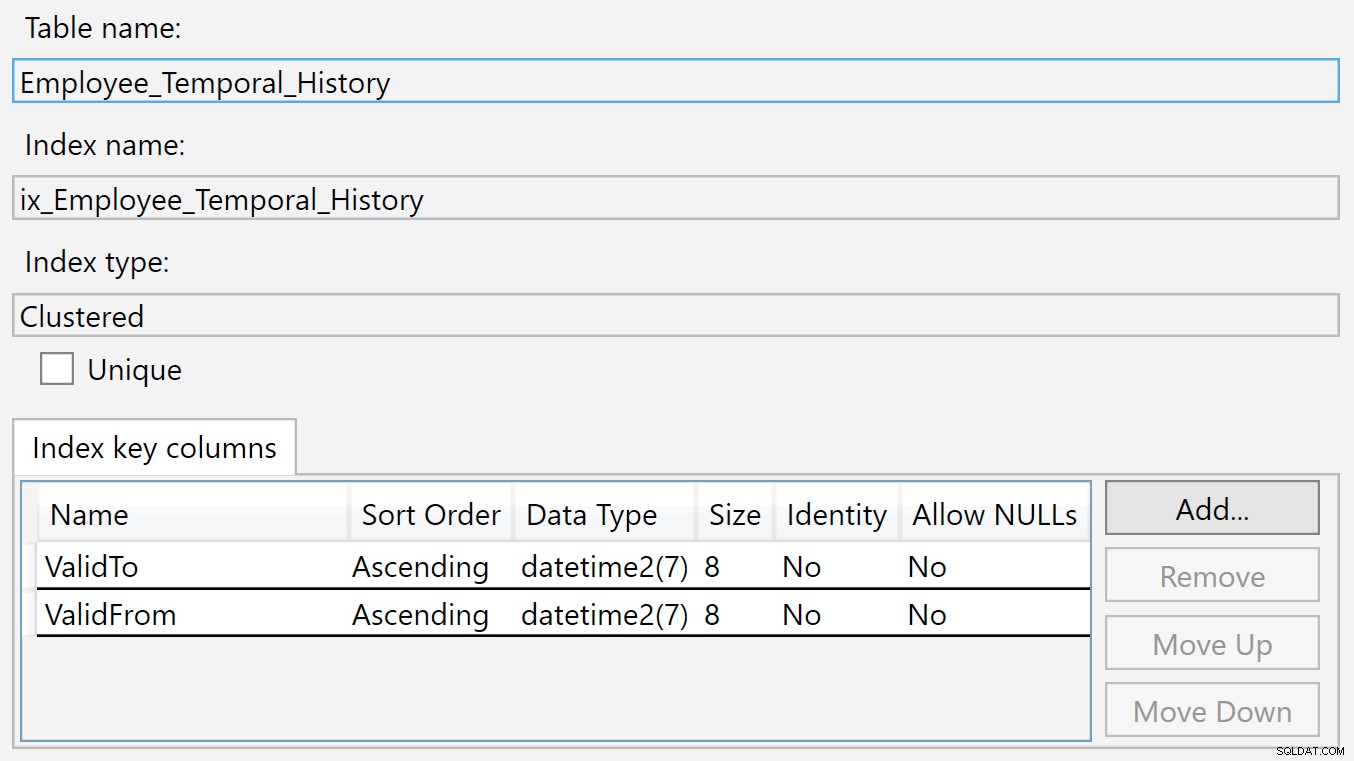
Baris baru dimasukkan ke dalam tabel Riwayat ini jika sudah tidak valid lagi di tabel utama, karena baru saja dihapus atau diubah. Nilai dalam ValidTo kolom secara alami diisi dengan waktu saat ini, jadi ValidTo bertindak sebagai kunci menaik, seperti kolom identitas, sehingga sisipan baru muncul di akhir struktur b-tree.
Tetapi bagaimana kinerjanya saat Anda ingin membuat kueri tabel?
Jika kita ingin menanyakan tabel kita untuk apa yang sedang berlangsung pada titik waktu tertentu, maka kita harus menggunakan struktur kueri seperti:
SELECT * FROM HumanResources.Employee_TemporalFOR SYSTEM_TIME AS OF '20160612 11:22';
Kueri ini perlu menggabungkan baris yang sesuai dari tabel utama dengan baris yang sesuai dari tabel riwayat.
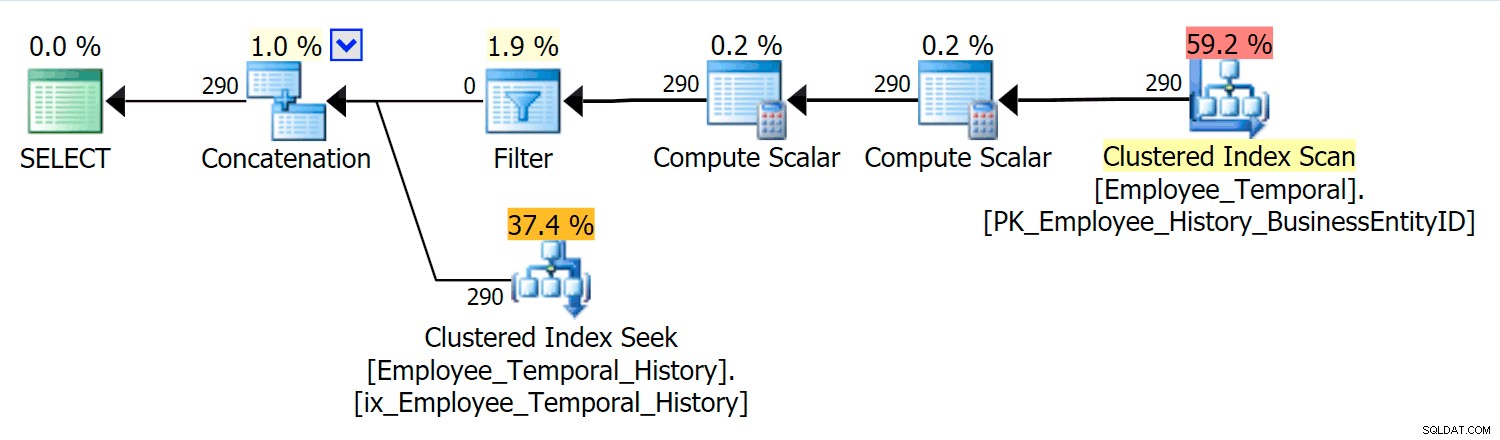
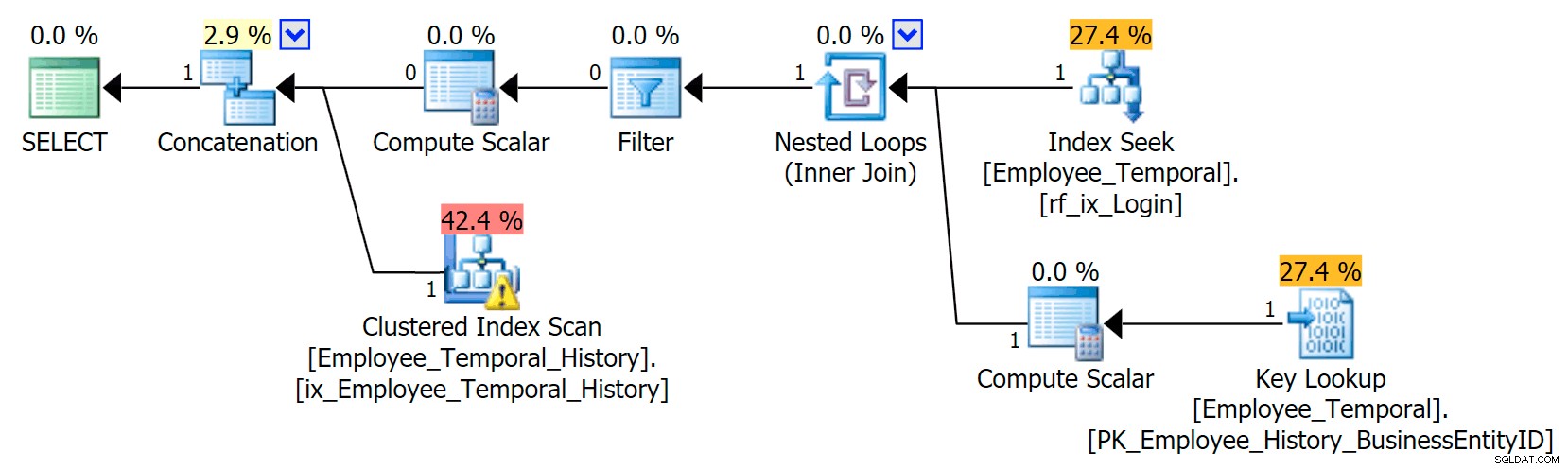
Dalam skenario ini, baris yang valid untuk saat yang saya pilih semuanya berasal dari tabel riwayat, namun demikian, kami melihat Pemindaian Indeks Berkelompok terhadap tabel utama, yang difilter oleh operator Filter. Predikat filter ini adalah:
[HumanResources].[Employee_Temporal].[ValidFrom] <='2016-06-12 11:22:00.0000000' AND [HumanResources].[Employee_Temporal].[ValidTo]> '06-12-12 11:22 :000,0000000'
Mari kita tinjau kembali ini sebentar lagi.
Clustered Index Seek pada tabel History harus dengan jelas memanfaatkan Seek Predicate di ValidTo. Awal dari Pemindaian Jangkauan Seek adalah HumanResources.Employee_Temporal_History.ValidTo > Operator Skalar('2016-06-12 11:22:00') , tetapi tidak ada Akhir, karena setiap baris yang memiliki ValidTo setelah waktu yang kita pedulikan adalah baris kandidat, dan harus diuji untuk ValidFrom yang sesuai nilai dengan Predikat Residual, yaitu HumanResources.Employee_Temporal_History.ValidFrom <= '2016-06-12 11:22:00' .
Sekarang, interval sulit untuk diindeks; itu adalah hal yang diketahui yang telah dibahas di banyak blog. Solusi paling efektif mempertimbangkan cara kreatif untuk menulis kueri, tetapi tidak ada kecerdasan seperti itu yang dibangun ke dalam Tabel Temporal. Namun, Anda juga dapat meletakkan indeks di kolom lain, seperti pada ValidFrom, atau bahkan memiliki indeks yang cocok dengan tipe kueri yang mungkin Anda miliki di tabel utama. Dengan indeks berkerumun menjadi kunci komposit pada kedua ValidTo dan ValidFrom , dua kolom ini disertakan pada setiap kolom lainnya, memberikan peluang bagus untuk beberapa pengujian Predikat Residual.
Jika saya tahu loginid mana yang saya minati, rencana saya akan membentuk bentuk yang berbeda.
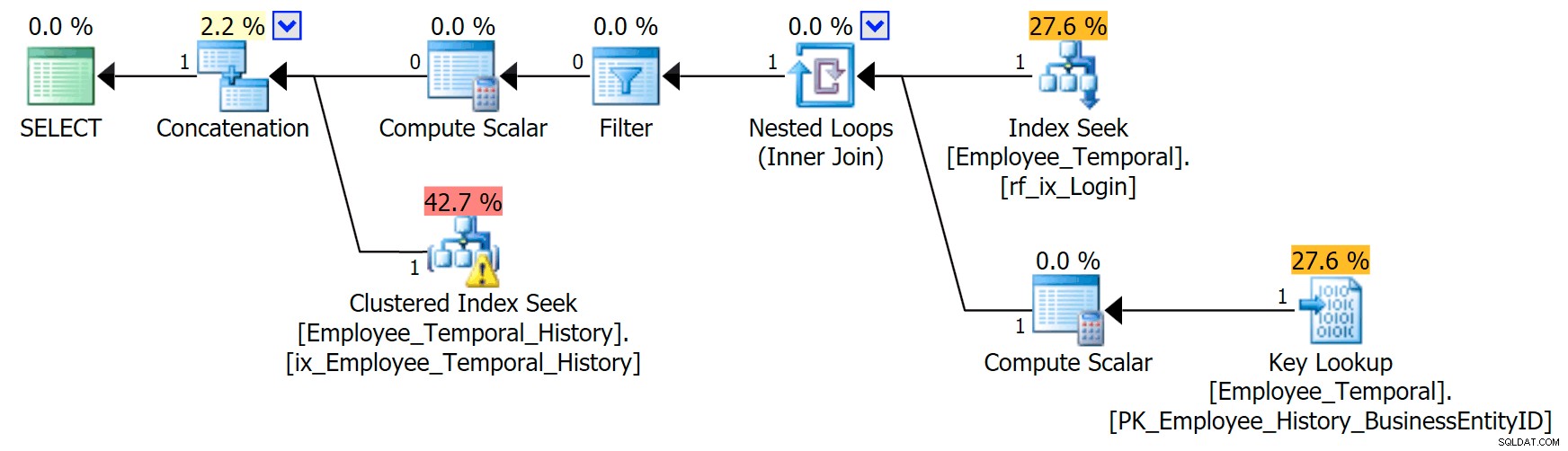
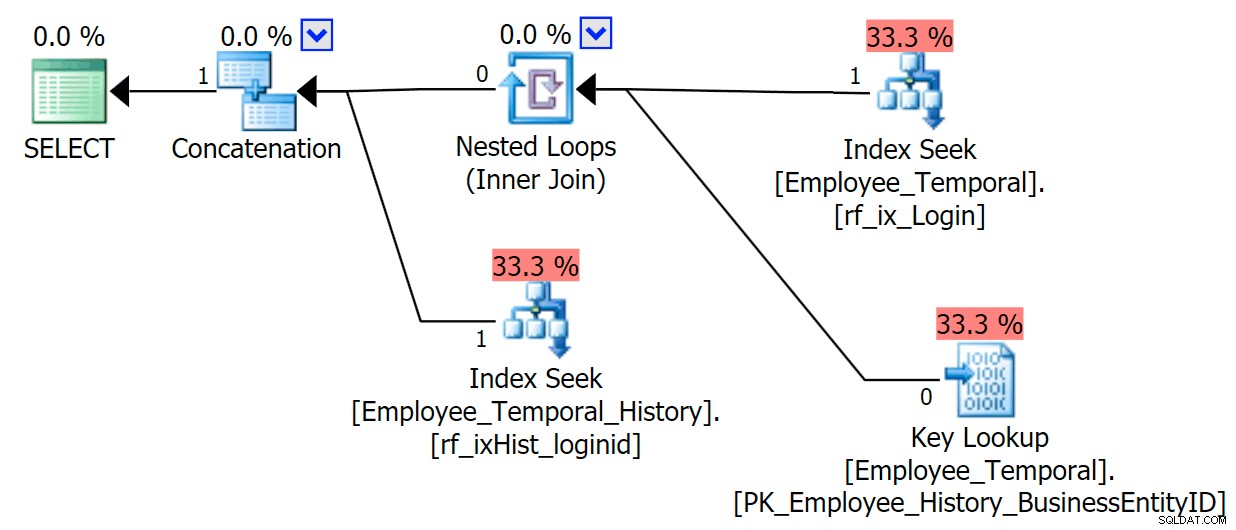
Cabang atas dari operator Penggabungan terlihat mirip dengan sebelumnya, meskipun operator Filter telah memasuki keributan untuk menghapus baris yang tidak valid, tetapi Pencarian Indeks Cluster di cabang bawah memiliki Peringatan. Ini adalah peringatan Predikat Residual, seperti contoh di posting saya sebelumnya. Itu dapat memfilter ke entri yang valid hingga beberapa titik setelah waktu yang kita pedulikan, tetapi Predikat Residual sekarang memfilter ke LoginID serta ValidFrom .
[HumanResources].[Employee_Temporal_History].[ValidFrom] <='2016-06-12 11:22:00.0000000' AND [HumanResources].[Employee_Temporal_History].[LoginID] =N'adventure-works\rob0'Perubahan pada baris rob0 akan menjadi sebagian kecil dari baris di History. Kolom ini tidak akan unik seperti di tabel utama, karena baris mungkin telah diubah beberapa kali, tetapi masih ada kandidat yang baik untuk pengindeksan.
BUAT INDEX rf_ixHist_loginidON HumanResources.Employee_Temporal_History(LoginID);Indeks baru ini memiliki efek penting pada rencana kami.
Sekarang telah mengubah Pencarian Indeks Berkelompok kami menjadi Pemindaian Indeks Berkelompok!!
Anda lihat, Pengoptimal Kueri sekarang menemukan bahwa hal terbaik yang harus dilakukan adalah menggunakan indeks baru. Tetapi juga memutuskan bahwa upaya untuk melakukan pencarian untuk mendapatkan semua kolom lainnya (karena saya meminta semua kolom) akan menjadi pekerjaan yang terlalu berat. Titik kritis tercapai (sayangnya asumsi yang salah dalam kasus ini), dan Clustered Index SCAN dipilih sebagai gantinya. Meskipun tanpa indeks non-cluster, opsi terbaik adalah menggunakan Clustered Index Seek, ketika indeks non-clustered telah dipertimbangkan dan ditolak karena alasan titik kritis, ia memilih untuk memindai.
Dengan frustrasi, saya baru saja membuat indeks ini dan statistiknya seharusnya bagus. Seharusnya tahu bahwa Pencarian yang membutuhkan tepat satu pencarian harus lebih baik daripada Pemindaian Indeks Cluster (hanya dengan statistik – jika Anda berpikir itu harus mengetahui ini karena
LoginIDunik di tabel utama, ingat bahwa itu mungkin tidak selalu). Jadi saya menduga bahwa pencarian harus dihindari dalam tabel riwayat, meskipun saya belum melakukan penelitian yang cukup tentang hal ini.Sekarang jika kita hanya menanyakan kolom yang muncul di indeks non-cluster, kita akan mendapatkan perilaku yang jauh lebih baik. Sekarang tidak ada pencarian yang diperlukan, indeks baru kami di tabel riwayat dengan senang hati digunakan. Masih perlu menerapkan Predikat Residual berdasarkan hanya dapat memfilter ke
LoginIDdanValidTo, tetapi berperilaku jauh lebih baik daripada melakukan Pemindaian Indeks Berkelompok.SELECT LoginID, ValidFrom, ValidToFROM HumanResources.Employee_TemporalFOR SYSTEM_TIME AS OF '20160612 11:22'WHERE LoginID =N'adventure-works\rob0'
Jadi, lakukan indeks tabel riwayat Anda dengan cara ekstra, dengan mempertimbangkan bagaimana Anda akan menanyakannya. Sertakan kolom yang diperlukan untuk menghindari pencarian, karena Anda benar-benar menghindari Pemindaian.
Tabel riwayat ini dapat bertambah besar jika data sering berubah. Jadi perhatikan bagaimana mereka ditangani. Situasi yang sama ini terjadi saat menggunakan
FOR SYSTEM_TIMElainnya konstruksi, jadi Anda harus (seperti biasa) meninjau rencana yang dihasilkan kueri Anda, dan mengindeks untuk memastikan bahwa Anda berada di posisi yang baik untuk memanfaatkan fitur yang sangat kuat dari SQL Server 2016.