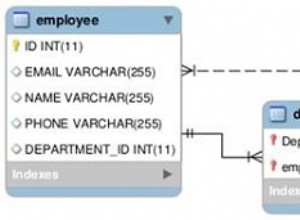
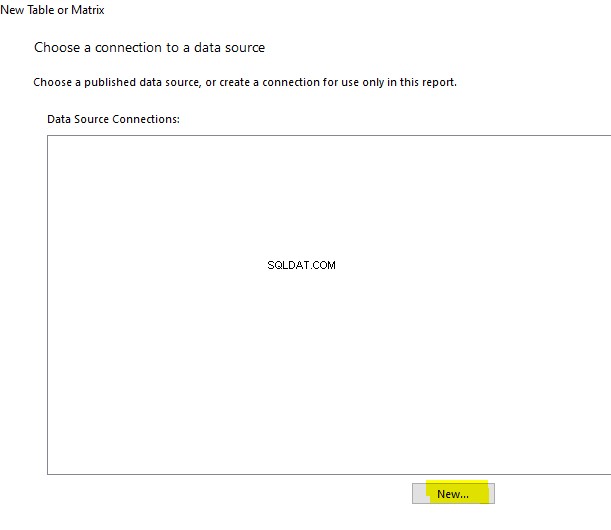
Ini adalah bagian kedua dari materi yang didedikasikan untuk Pencarian Semantik SQL Server . Dalam artikel sebelumnya, kami menjelajahi dasar-dasarnya. Sekarang, kita akan fokus membandingkan dokumen yang disimpan di Sistem File Windows dan analisis komparatif dengan Pencarian Semantik di SQL Server.
Melakukan Analisis Perbandingan Dokumen Berbasis Nama
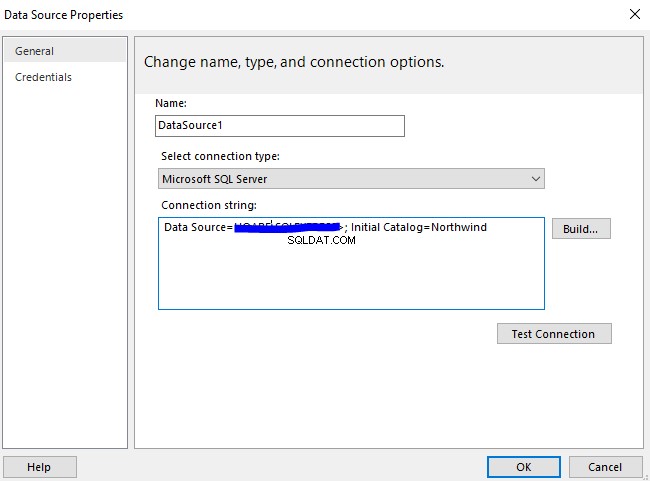
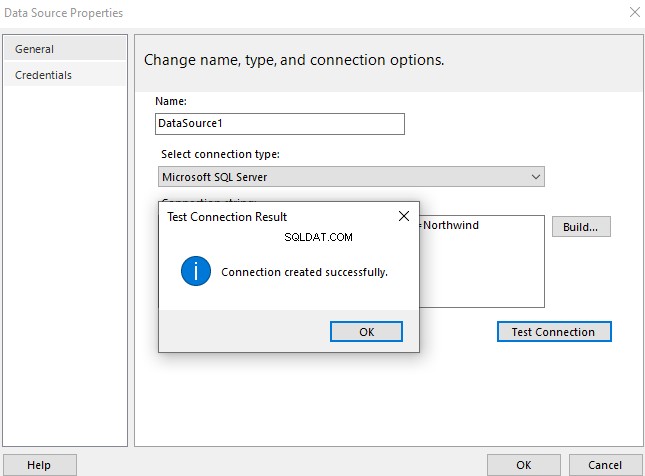
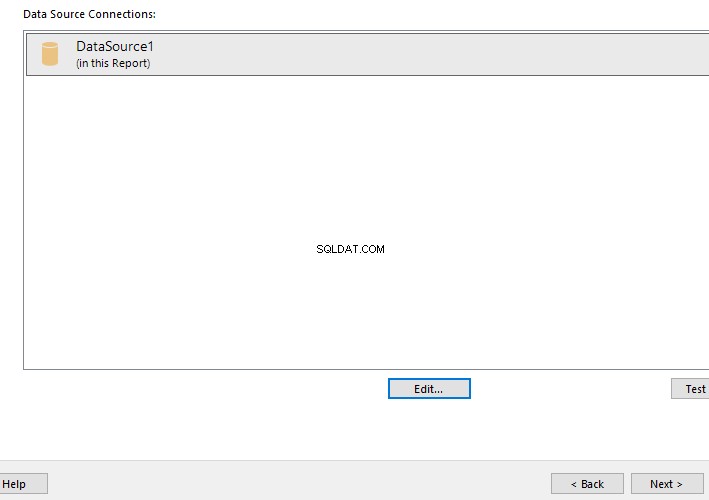
Kami akan melakukan analisis komparatif dokumen berdasarkan penamaan standar mereka. Pada titik ini, mari kita lakukan pemeriksaan cepat dengan menanyakan EmployeesFilestreamSample database yang kita siapkan sebelumnya:
-- Lihat dokumen tersimpan yang dikelola oleh Tabel File untuk diperiksa SELECT stream_id ,[name] ,file_type ,creation_timeFROM EmployeeFilestreamSample.dbo.EmployeesDocumentStore Hasilnya harus menunjukkan kepada kami dokumen yang disimpan:
Daftar Periksa Pencarian Semantik
Kami telah memiliki database dan dua contoh dokumen MS Word di Sistem File menggunakan Tabel File (Anda dapat merujuk ke Bagian 1 untuk menyegarkan pengetahuan jika diperlukan). Namun, tidak otomatis memenuhi syarat dokumen kami untuk skenario Pencarian Semantik.
Pencarian Semantik dapat diaktifkan dengan salah satu cara berikut:
- Jika Anda telah menyiapkan Penelusuran Teks Lengkap , Anda dapat mengaktifkan Pencarian Semantik dalam satu langkah.
- Anda dapat mengatur Pencarian Semantik secara langsung, tetapi sebelumnya Anda juga harus menyiapkan Pencarian Teks Lengkap.
Tes Pencarian Teks Lengkap Sebelum Pengaturan Pencarian Semantik
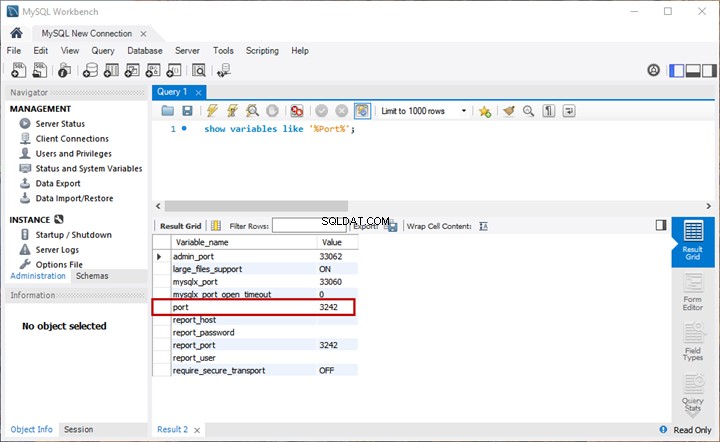
Jika kueri Teks Lengkap berfungsi, kita hanya perlu mengaktifkan Pencarian Semantik. Untuk memeriksanya, jalankan kueri Teks Lengkap terhadap tabel yang diinginkan:
-- Mencari kata Employee menggunakan Pencarian Teks Lengkap terhadap EmployeeDocumentStore File TableSELECT [name] FROM [EmployeesFilestreamSample].[dbo].[EmployeesDocumentStore] WHERE CONTAINS(name,'Employee') Keluaran:
Jadi, pertama-tama kita harus memenuhi persyaratan Pencarian Teks Lengkap dan kemudian mengaktifkan Pencarian Semantik.
Mengaktifkan Penelusuran Semantik untuk Penggunaan
Setidaknya dua dari poin berikut diperlukan untuk menggunakan Pencarian Semantik:
- Indeks Unik
- Katalog Teks Lengkap
- Indeks Teks Lengkap
Jalankan skrip T-SQL berikut untuk membuat indeks unik:
-- Buat indeks unik yang diperlukan untuk Pencarian SemantikCREATE UNIQUE INDEX UQ_Stream_Id ON EmployeeDocumentStore(stream_id) GO Buat katalog Teks Lengkap berdasarkan indeks unik yang baru dibuat. Dan kemudian, buat indeks Teks Lengkap seperti yang ditunjukkan di bawah ini:
-- Mempersiapkan Pencarian Semantik untuk digunakan dengan Tabel FileCREATE FULLTEXT CATALOG EmployeeFileTableCatalog WITH ACCENT_SENSITIVITY =ON;CREATE FULLTEXT INDEX ON EmployeeDocumentStore(nama LANGUAGE 1033 STATISTICAL_SEMANTICS,file_typestream_type LANGUAGE_SEMANTICS_33 STEMANTICSfile STEMANTICS, file COGUAGE 1033 STEMANTICS INDEKS KUNCI UQ_Stream_IdON EmployeeFileTableCatalog WITH CHANGE_TRACKING AUTO, STOPLIST=SYSTEM; Hasilnya:
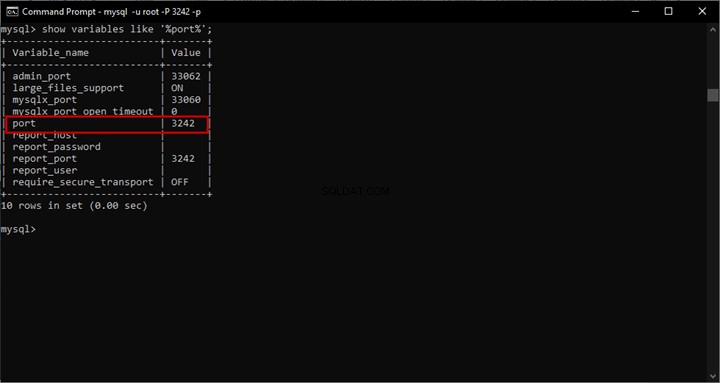
Tes Pencarian Teks Lengkap Setelah Pengaturan Pencarian Semantik
Mari kita jalankan kueri Teks Lengkap yang sama untuk mencari kata Karyawan dalam dokumen yang disimpan:
-- Mencari (setelah pengaturan Pencarian Semantik) kata Karyawan menggunakan pencarian Teks Lengkap terhadap File EmployeeDocumentStore TableSELECT [name] FROM [EmployeesFilestreamSample].[dbo].[EmployeesDocumentStore] WHERE CONTAINS(name,'Employee') Keluaran:
Tidak masalah jika kueri Teks Lengkap bekerja dengan Tabel File sementara kami menyiapkannya untuk Penelusuran Semantik.
Tambahkan Lebih Banyak Dokumen MS Word
Kami pergi ke EmployeesDocumentStore Tabel File dan klik Jelajahi Direktori FileTable :
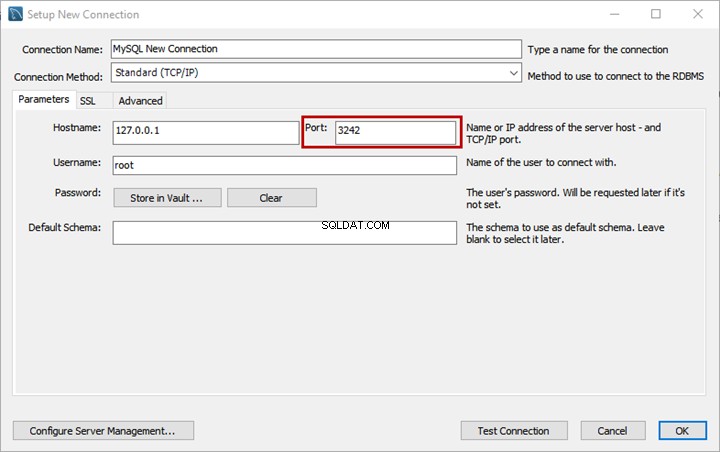
Buat dan simpan dokumen baru bernama Karyawan Kontrak Sadaf :
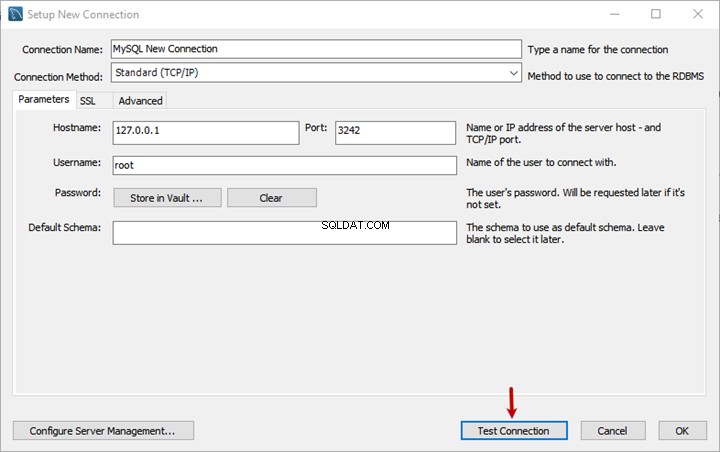
Selanjutnya, tambahkan teks berikut ke dokumen yang baru dibuat. Baris pertama harus berupa judul dokumen!
Pegawai Kontrak Sadaf (jabatan)
Sadaf adalah analis bisnis yang sangat efisien yang melakukan pekerjaan berbasis kontak. Dia sepenuhnya mampu menangani persyaratan bisnis dan mengubahnya menjadi spesifikasi teknis untuk dikerjakan oleh pengembang. Dia adalah seorang analis bisnis yang sangat berpengalaman.
Tambahkan dokumen lain yang disebut Karyawan Tetap Mike :
Perbarui dokumen dengan teks berikut:
Mike Karyawan Tetap (Judul dokumen)
Mike adalah programmer baru yang keahliannya mencakup pengembangan web. Dia cepat belajar dan senang mengerjakan proyek apa pun. Dia memiliki keterampilan pemecahan masalah yang kuat tetapi dia memiliki pengetahuan bisnis yang lebih sedikit. Dia membutuhkan bantuan dari pengembang atau analis bisnis lain untuk memahami masalah dan memenuhi persyaratan.
Dia baik saat mengerjakan proyek kecil tapi dia kesulitan jika diberi proyek besar atau rumit.
Kami memiliki empat dokumen yang disimpan di Sistem File Windows yang dikelola oleh Tabel File. Dokumen-dokumen ini harus digunakan oleh Pencarian Semantik (termasuk Pencarian Teks Lengkap).
Penting:Meskipun kami baru saja menyimpan empat dokumen MS Word di folder sebagai sampel, Anda dapat membayangkan pentingnya menggunakan Pencarian Semantik ketika ratusan dokumen tersebut dikelola oleh database SQL Server, dan Anda perlu menanyakan dokumen tersebut untuk menemukan informasi berharga.
Penamaan standar dokumen sangat penting untuk keberhasilan penerapan pendekatan ini.
Penghitungan Dokumen Sederhana
Kami dapat membandingkan dokumen-dokumen ini dan menentukan perbedaan dan persamaan berdasarkan penamaan standar mereka menggunakan Pencarian Semantik. Misalnya, kueri sederhana dapat memberi tahu kami jumlah total dokumen yang disimpan di Folder Windows:
-- Mendapatkan jumlah total dokumen yang disimpanSELECT COUNT(*) AS Total_Documents FROM EmployeeDocumentStore 
Perbandingan Karyawan Tetap vs Karyawan Berbasis Kontrak
Kali ini, kami menggunakan Penelusuran Semantik untuk membandingkan jumlah karyawan tetap dan karyawan kontrak di organisasi kami:
-- Membuat variabel tabel ringkasanDECLARE @Documents TABLE(DocumentType VARCHAR(100),DocumentsCount INT)INSERT INTO @Documents -- Menyimpan jumlah total dokumen yang disimpan ke dalam tabel ringkasanSELECT 'Total Documents',COUNT(*) AS Total_Documents FROM EmployeeDocumentStoreINSERT INTO @Documents -- Menyimpan jumlah total dokumen karyawan tetap yang disimpan ke dalam tabel ringkasanSELECT 'Total Permanent Employee',COUNT(*) FROM semantickeyphrasetable (EmployeesDocumentStore, *)WHERE keyphrase ='Permanen' INSERT INTO @Documents jumlah total dokumen karyawan tetap yang disimpanSELECT 'Total Contract Employee',COUNT(*) FROM semantickeyphrasetable (EmployeesDocumentStore, *)WHERE keyphrase ='Contract'SELECT DocumentType,DocumentsCount FROM @Documents Keluaran:
Mari kita jalankan kueri Penelusuran Semantik sederhana (berbasis nama dokumen) untuk melihat frasa kunci dan skor relatifnya untuk setiap dokumen:
-- Mendapatkan keyphrase dan skor relatif untuk semua dokumenSELECT * FROM semantickeyphrasetable(EmployeesDocumentStore, NAME) ORDER BY score Keluaran:
Mari kita tambahkan lebih banyak detail ke nama dokumen. Kami akan mengganti namanya sebagai berikut:
- Karyawan Tetap Asif – Manajer Proyek Berpengalaman
- Karyawan Tetap Mike – Programmer Baru
- Pekerja Tetap Peter – Manajer Proyek Baru
- Karyawan Kontrak Sadaf – Analis Bisnis Berpengalaman
Menemukan Karyawan Baru (Dokumen)
Temukan dokumen yang terkait dengan karyawan baru berdasarkan jabatan mereka (penamaan standar):
-- Mendapatkan penilaian berbasis nama dokumen untuk menemukan karyawan baru untuk proyek baruSELECT (PILIH nama dari EmployeeDocumentStore di mana path_locator=document_key) sebagai DocumentName,keyphrase,score FROM semantickeyphrasetable(EmployeesDocumentStore, NAME) di mana keyphrase='segar 'pesan berdasarkan DocumentName desc Hasilnya:
Menemukan Karyawan Berpengalaman (Dokumen)
Misalkan kita ingin dengan cepat meninjau semua detail karyawan yang berpengalaman untuk proyek yang kompleks di depan. Gunakan kueri Penelusuran Semantik berikut:
-- Mendapatkan penilaian berbasis nama dokumen untuk menemukan semua karyawan yang berpengalamanSELECT (PILIH nama dari EmployeeDocumentStore di mana path_locator=document_key) sebagai DocumentName ,keyphrase,score FROM semantickeyphrasetable(EmployeesDocumentStore, NAME) di mana keyphrase='berpengalaman' dipesan oleh NamaDokumen Keluaran:
Menemukan semua Manajer Proyek (Dokumen)
Terakhir, jika kita ingin menelusuri dokumen untuk semua manajer proyek dengan cepat, kita memerlukan kueri Penelusuran Semantik berikut:
-- Mendapatkan penilaian berbasis nama dokumen untuk menemukan semua manajer proyekSELECT (PILIH nama dari EmployeeDocumentStore di mana path_locator=document_key) sebagai DocumentName ,keyphrase,score FROM semantickeyphrasetable(EmployeesDocumentStore, NAME)where keyphrase='Project' Hasilnya:
Setelah menerapkan panduan, Anda dapat berhasil menyimpan data tidak terstruktur, seperti dokumen MS Word, di Folder Windows menggunakan Tabel File.
Tinjauan Analisis Berbasis Nama
Sejauh ini, kita telah belajar bagaimana melakukan analisis berbasis nama dari dokumen yang disimpan dalam Tabel File menggunakan Pencarian Semantik. Namun, kita perlu memenuhi kondisi berikut:
- Penamaan standar harus ada.
- Nama harus memberikan informasi yang diperlukan untuk analisis.
Kondisi ini juga merupakan keterbatasan analisis berbasis nama. Tapi ini tidak berarti kita tidak bisa berbuat banyak dengannya.
Fokus kami tetap pada pendekatan Pencarian Semantik berbasis nama/kolom.
Melihat Kolom Nama Dokumen
Mari kita lihat beberapa kolom utama tabel Dokumen termasuk Nama kolom:
GUNAKAN EmployeeFilestreamSample-- Lihat kolom nama dengan jenis file dari dokumen yang disimpan di Tabel File untuk analisisSELECT name,file_type FROM dbo.EmployeesDocumentStore Keluaran:
Memahami Fungsi SEMANTICKEYPHRASETABLE
SQL Server menawarkan SEMANTICKEYPHRASETABLE berfungsi untuk menganalisa dokumen dengan Semantic Search. Sintaksnya adalah sebagai berikut:
SEMANTICKEYPHRASETABLE ( tabel, { kolom | (daftar_kolom) | * } [ , kunci_sumber ] ) Fungsi ini memberi kita frase kunci yang terkait dengan dokumen. Kita dapat menggunakannya untuk menganalisis dokumen berdasarkan nama atau isinya. Dalam kasus kami, kami tidak hanya perlu menggunakan fungsi ini tetapi juga memahami cara menggunakannya dengan benar.
Fungsi ini membutuhkan data berikut:
- Nama Tabel File yang akan digunakan untuk analisis Penelusuran Semantik.
- Nama kolom yang akan digunakan untuk analisis Penelusuran Semantik.
Kemudian ia mengembalikan data berikut:
- Column_id – nomor kolom
- Document_Key – kunci utama default untuk dokumen Tabel File
- Frasa Kunci – adalah frasa yang Semantic Search putuskan untuk diindeks untuk analisis. Ini berlaku untuk nama dan konten dokumen tergantung pada kolom mana kita ingin melihat frasa kunci untuk
- Skor – menentukan kekuatan frase kunci yang terkait dengan dokumen, seperti bagaimana sebuah dokumen dikenali dengan baik oleh frase kuncinya. Skornya bisa antara 0,0 hingga 1,0.
Menganalisis Semua Dokumen Menggunakan Fungsi SEMANTICKEYPHRASETABLE
Kami menggunakan SEMANTICKEYPHRASETABLE fungsi untuk analisis berbasis nama dari dokumen yang disimpan dalam folder Windows yang dikelola oleh Tabel File.
Jalankan skrip T-SQL berikut:
GUNAKAN EmployeeFilestreamSample-- Lihat frasa kunci dan skornya untuk kolom namaSELECT * FROM SEMANTICKEYPHRASETABLE(EmployeesDocumentStore,nama)urutkan berdasarkan skor desc Keluaran:
Kami memiliki daftar semua frasa kunci yang dilampirkan pada semua dokumen dan skornya. id_kolom 3 di baris atas adalah nama kolom. Plus, kami juga memanggil fungsi dengan menyediakan kolom ini (nama):
Anda dapat menemukan kunci_dokumen : 0xFD89E1811D4F3B2FEB1012DF0C8016F9ACEB2F3260 menjalankan skrip berikut (walaupun jelas bahwa dokumen ini adalah dokumen yang namanya berisi frasa kunci sadaf ):
GUNAKAN EmployeeFilestreamSample-- Menemukan nama dokumen dengan kuncinya (path_locator)SELECT name,path_locator FROM dbo.EmployeesDocumentStoreWHERE path_locator=0xFD89E1811D4F3B2FEB1012DF0C8016F9ACEB2F3260 Keluaran:
Frasa kunci sadaf telah diberi skor terbaik :1.0 .
Jadi, dalam kasus penamaan dokumen standar dengan informasi yang cukup untuk analisis Penelusuran Semantik, frasa kunci kami sadaf adalah yang paling cocok untuk nama dokumen tersebut.
Menganalisis Dokumen Tertentu Menggunakan Fungsi SEMANTICKEYPHRASETABLE
Kami dapat mempersempit analisis Penelusuran Semantik kami berdasarkan nama kolom. Misalnya, kita hanya perlu melihat kolom nama- frase kunci berdasarkan dokumen tertentu. Kita dapat menentukan kunci dokumen di SEMANTICKEYPHRASETABLE Fungsi.
Pertama, kami mengidentifikasi kunci dokumen untuk dokumen itu di mana kami ingin melihat semua frasa kunci. Jalankan skrip T-SQL berikut:
-- Temukan document_key dari dokumen yang namanya berisi nama PeterSELECT,path_locator sebagai document_key Dari Nama EmployeeDocumentStoreWHERE seperti '%Peter%' Kunci dokumen adalah 0xFF6A92952500812FF013376870181CFA6D7C070220
Sekarang, mari kita lihat dokumen ini mengenai semua frase kunci yang dapat menentukan nama dokumen:
-- Lihat semua frasa kunci dan skornya untuk dokumen yang terkait dengan karyawan tetap PeterSELECT column_id,name,keyphrase,score FROM SEMANTICKEYPHRASETABLE(EmployeesDocumentStore,name,0xFF6A92952500812FF013376870181CFA6D7C070220)INNER_JOIN JOIN dbo skor desc Hasilnya:
Frasa kunci karyawan mendapatkan skor tertinggi dalam dokumen ini. Kita dapat melihat bahwa semua kata dalam kolom adalah frase kunci yang menentukan makna dokumen.
Memahami Fungsi SEMANTICSIMILARITYTABLE
Fungsi ini membantu kita membandingkan satu dokumen dengan semua dokumen lain berdasarkan frase kunci. Sintaks dari fungsi ini adalah sebagai berikut:
SEMANTICSIMILARITYTABLE ( tabel, { kolom | (daftar_kolom) | * }, kunci_sumber ) Ini membutuhkan nama tabel, kolom, dan kunci dokumen untuk mencocokkan dokumen lain. Misalnya, kita dapat menyatakan bahwa dua dokumen serupa jika memiliki skor pencocokan frasa kunci yang baik.
Membandingkan Dokumen Menggunakan Fungsi SEMANTICSIMILARITYTABLE
Mari kita bandingkan dokumen dengan dokumen lain menggunakan SEMANTIKSIMILARITYTABLE Fungsi.
Membandingkan Semua Dokumen Manajer Proyek
Kita perlu melihat semua dokumen yang berhubungan dengan manajer proyek. Dari contoh di atas, kita tahu bahwa kunci dokumen untuk dokumen yang ditentukan adalah 0xFF6A92952500812FF013376870181CFA6D7C070220 . Oleh karena itu, kita dapat menggunakan kunci ini untuk menemukan kecocokan lain termasuk manajer proyek:
Epre>Gunakan EmployeeFilestreamSample-- Lihat semua dokumen yang terkait erat dengan manajer proyek PeterSELECT SST.source_column_id,SST.matched_column_id,EDS.name,SCORE FROM SEMANTICSIMILARITYTABLE(EmployeesDocumentStore,nama,0xFF6A92952500812FF0133768701 .path_locator=SST.matched_document_keyurutkan berdasarkan desc skor Keluaran:
Dokumen yang paling dekat hubungannya adalah Karyawan Tetap Asif – Manajer Proyek Berpengalaman.docx
Membandingkan Dokumen Analis Bisnis Berpengalaman
Sekarang, kita akan membandingkan dokumen yang terkait dengan analis bisnis berpengalaman s dan temukan kecocokan terdekat menggunakan Pencarian Semantik. Kami terbatas pada analisis berbasis nama dokumen:
GUNAKAN EmployeeFilestreamSample-- Menemukan document_key untuk analis bisnis berpengalamanpilih nama,path_locator sebagai document_key dari EmployeeDocumentStore di mana nama seperti '%analis bisnis berpengalaman%'-- Lihat semua dokumen yang terkait erat dengan analis bisnis berpengalamanSELECT SST.source_column_id,SST. matched_column_id,EDS.name,SCORE FROM SEMANTICSIMILARITYTABLE(EmployeesDocumentStore,name,0xFD89E1811D4F3B2FEB1012DF0C8016F9ACEB2F3260) SSTINNER BERGABUNG dengan dbo.Employeesscore_locator pada EDSCumentStore_locator diurutkan kode EDS. Keluaran:
Seperti yang dapat kita lihat dari hasil di atas, kecocokan terdekat untuk dokumen yang terkait dengan analis bisnis berpengalaman adalah dokumen dari manajer proyek yang berpengalaman karena keduanya berpengalaman . Namun demikian, skor 0,3 menunjukkan bahwa tidak banyak kesamaan antara kedua dokumen ini.
Kesimpulan
Selamat! Kami telah berhasil mempelajari cara menyimpan dokumen di folder Windows dan menganalisisnya menggunakan Pencarian Semantik. Kami juga mengeksplorasi fungsi untuk digunakan dalam praktik. Sekarang Anda dapat menerapkan pengetahuan baru dan mencoba latihan berikut untuk
Nantikan materi selanjutnya!