Nah untuk menjawab pertanyaan Anda mengapa SQL Server melakukan ini, jawabannya adalah bahwa kueri tidak dikompilasi dalam urutan logis, setiap pernyataan dikompilasi berdasarkan kemampuannya sendiri, jadi ketika rencana kueri untuk pernyataan pilihan Anda sedang dibuat, pengoptimal tidak tahu bahwa @val1 dan @Val2 masing-masing akan menjadi 'val1' dan 'val2'.
Ketika SQL Server tidak mengetahui nilainya, ia harus membuat tebakan terbaik tentang berapa kali variabel itu akan muncul di tabel, yang terkadang dapat menyebabkan rencana yang kurang optimal. Poin utama saya adalah bahwa kueri yang sama dengan nilai yang berbeda dapat menghasilkan paket yang berbeda. Bayangkan contoh sederhana ini:
IF OBJECT_ID(N'tempdb..#T', 'U') IS NOT NULL
DROP TABLE #T;
CREATE TABLE #T (ID INT IDENTITY PRIMARY KEY, Val INT NOT NULL, Filler CHAR(1000) NULL);
INSERT #T (Val)
SELECT TOP 991 1
FROM sys.all_objects a
UNION ALL
SELECT TOP 9 ROW_NUMBER() OVER(ORDER BY a.object_id) + 1
FROM sys.all_objects a;
CREATE NONCLUSTERED INDEX IX_T__Val ON #T (Val);
Yang saya lakukan di sini adalah membuat tabel sederhana, dan menambahkan 1000 baris dengan nilai 1-10 untuk kolom val , namun 1 muncul 991 kali, dan 9 lainnya hanya muncul sekali. Premisnya adalah kueri ini:
SELECT COUNT(Filler)
FROM #T
WHERE Val = 1;
Akan lebih efisien untuk hanya memindai seluruh tabel, daripada menggunakan indeks untuk pencarian, lalu lakukan 991 pencarian bookmark untuk mendapatkan nilai Filler , namun dengan hanya 1 baris kueri berikut:
SELECT COUNT(Filler)
FROM #T
WHERE Val = 2;
akan lebih efisien untuk melakukan pencarian indeks, dan pencarian bookmark tunggal untuk mendapatkan nilai untuk Filler (dan menjalankan dua kueri ini akan meratifikasi ini)
Saya cukup yakin batas untuk pencarian dan pencarian bookmark sebenarnya bervariasi tergantung pada situasinya, tetapi cukup rendah. Menggunakan tabel contoh, dengan sedikit trial and error, saya menemukan bahwa saya membutuhkan Val kolom memiliki 38 baris dengan nilai 2 sebelum pengoptimal melakukan pemindaian tabel lengkap melalui pencarian indeks dan pencarian bookmark:
IF OBJECT_ID(N'tempdb..#T', 'U') IS NOT NULL
DROP TABLE #T;
DECLARE @I INT = 38;
CREATE TABLE #T (ID INT IDENTITY PRIMARY KEY, Val INT NOT NULL, Filler CHAR(1000) NULL);
INSERT #T (Val)
SELECT TOP (991 - @i) 1
FROM sys.all_objects a
UNION ALL
SELECT TOP (@i) 2
FROM sys.all_objects a
UNION ALL
SELECT TOP 8 ROW_NUMBER() OVER(ORDER BY a.object_id) + 2
FROM sys.all_objects a;
CREATE NONCLUSTERED INDEX IX_T__Val ON #T (Val);
SELECT COUNT(Filler), COUNT(*)
FROM #T
WHERE Val = 2;
Jadi untuk contoh ini batasnya adalah 3,7% dari baris yang cocok.
Karena kueri tidak mengetahui berapa banyak baris yang akan cocok ketika Anda menggunakan variabel yang harus ditebak, dan cara paling sederhana adalah dengan mencari tahu jumlah baris total, dan membaginya dengan jumlah total nilai yang berbeda dalam kolom, jadi dalam contoh ini perkiraan jumlah baris untuk WHERE val = @Val adalah 1000 / 10 =100, Algoritme sebenarnya lebih kompleks dari ini, tetapi ini akan berhasil. Jadi ketika kita melihat rencana eksekusi untuk:
DECLARE @i INT = 2;
SELECT COUNT(Filler)
FROM #T
WHERE Val = @i;
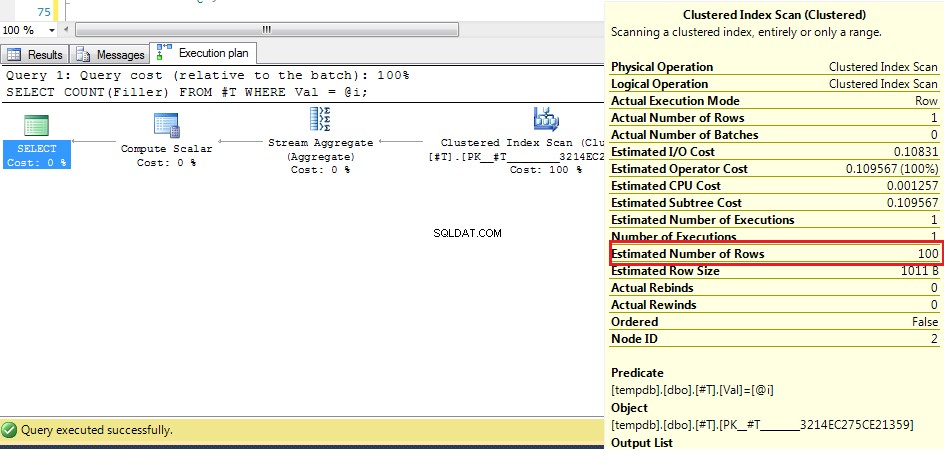
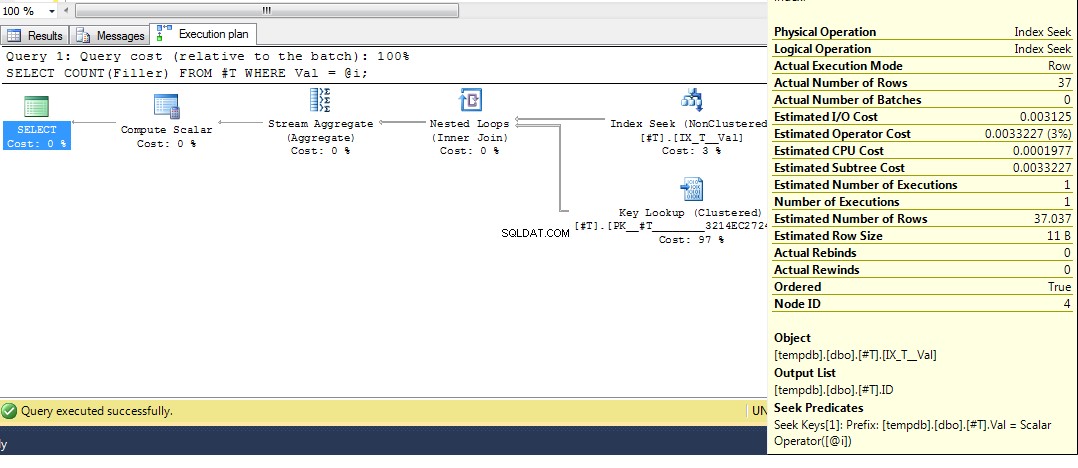
Kita dapat melihat di sini (dengan data asli) bahwa perkiraan jumlah baris adalah 100, tetapi baris sebenarnya adalah 1. Dari langkah sebelumnya, kita tahu bahwa dengan lebih dari 38 baris, pengoptimal akan memilih pemindaian indeks berkerumun di atas indeks cari, jadi karena tebakan terbaik untuk jumlah baris lebih tinggi dari ini, rencana untuk variabel yang tidak diketahui adalah pemindaian indeks berkerumun.
Sekadar membuktikan teori lebih lanjut, jika kita membuat tabel dengan 1000 baris angka 1-27 yang terdistribusi secara merata (jadi perkiraan jumlah baris akan menjadi sekitar 1000 / 27 =37,037)
IF OBJECT_ID(N'tempdb..#T', 'U') IS NOT NULL
DROP TABLE #T;
CREATE TABLE #T (ID INT IDENTITY PRIMARY KEY, Val INT NOT NULL, Filler CHAR(1000) NULL);
INSERT #T (Val)
SELECT TOP 27 ROW_NUMBER() OVER(ORDER BY a.object_id)
FROM sys.all_objects a;
INSERT #T (val)
SELECT TOP 973 t1.Val
FROM #T AS t1
CROSS JOIN #T AS t2
CROSS JOIN #T AS t3
ORDER BY t2.Val, t3.Val;
CREATE NONCLUSTERED INDEX IX_T__Val ON #T (Val);
Kemudian jalankan kueri lagi, kami mendapatkan rencana dengan pencarian indeks:
DECLARE @i INT = 2;
SELECT COUNT(Filler)
FROM #T
WHERE Val = @i;
Jadi mudah-mudahan itu cukup komprehensif mencakup mengapa Anda mendapatkan rencana itu. Sekarang saya kira pertanyaan berikutnya adalah bagaimana Anda memaksakan rencana yang berbeda, dan jawabannya adalah, menggunakan petunjuk kueri OPTION (RECOMPILE) , untuk memaksa kueri dikompilasi pada waktu eksekusi ketika nilai parameter diketahui. Mengembalikan ke data asli, di mana rencana terbaik untuk Val = 2 adalah pencarian, tetapi menggunakan variabel menghasilkan rencana dengan pemindaian indeks, kita dapat menjalankan:
DECLARE @i INT = 2;
SELECT COUNT(Filler)
FROM #T
WHERE Val = @i;
GO
DECLARE @i INT = 2;
SELECT COUNT(Filler)
FROM #T
WHERE Val = @i
OPTION (RECOMPILE);
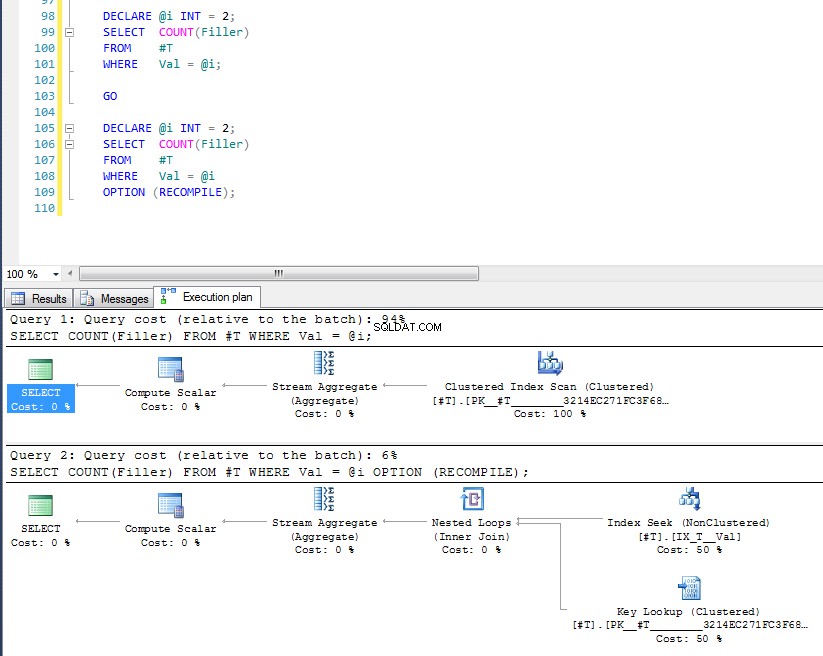
Kita dapat melihat bahwa yang terakhir menggunakan pencarian indeks dan pencarian kunci karena telah memeriksa nilai variabel pada waktu eksekusi, dan rencana yang paling tepat untuk nilai spesifik itu dipilih. Masalah dengan OPTION (RECOMPILE) artinya Anda tidak dapat memanfaatkan paket kueri yang di-cache, sehingga ada biaya tambahan untuk mengompilasi kueri setiap kali.