Saya melihat banyak saran di luar sana yang mengatakan sesuatu seperti, "Ubah kursor Anda ke operasi berbasis set; itu akan membuatnya lebih cepat." Meskipun itu sering terjadi, itu tidak selalu benar. Satu kasus penggunaan yang saya lihat di mana kursor berulang kali mengungguli pendekatan berbasis set yang khas adalah perhitungan total yang berjalan. Ini karena pendekatan berbasis himpunan biasanya harus melihat beberapa bagian dari data yang mendasari lebih dari satu kali, yang dapat menjadi hal yang buruk secara eksponensial karena data menjadi lebih besar; sedangkan kursor – meskipun terdengar menyakitkan – dapat melewati setiap baris/nilai tepat satu kali.
Ini adalah opsi dasar kami di versi SQL Server yang paling umum. Namun, di SQL Server 2012, ada beberapa peningkatan yang dilakukan pada fungsi windowing dan klausa OVER, sebagian besar berasal dari beberapa saran bagus yang diajukan oleh sesama MVP Itzik Ben-Gan (ini salah satu sarannya). Faktanya Itzik memiliki buku MS-Press baru yang mencakup semua peningkatan ini secara lebih rinci, berjudul, "Microsoft SQL Server 2012 High-Performance T-SQL Using Window Functions."
Jadi tentu saja, saya penasaran; akankah fungsionalitas windowing baru membuat teknik kursor dan self-join menjadi usang? Apakah mereka akan lebih mudah untuk dikodekan? Apakah mereka akan lebih cepat dalam semua kasus (apalagi semua)? Pendekatan lain apa yang mungkin valid?
Penyiapan
Untuk melakukan beberapa pengujian, mari siapkan database:
USE [master];
GO
IF DB_ID('RunningTotals') IS NOT NULL
BEGIN
ALTER DATABASE RunningTotals SET SINGLE_USER WITH ROLLBACK IMMEDIATE;
DROP DATABASE RunningTotals;
END
GO
CREATE DATABASE RunningTotals;
GO
USE RunningTotals;
GO
SET NOCOUNT ON;
GO Dan kemudian isi tabel dengan 10.000 baris yang dapat kita gunakan untuk melakukan beberapa total berjalan terhadap. Tidak ada yang terlalu rumit, hanya tabel ringkasan dengan baris untuk setiap tanggal dan nomor yang menunjukkan berapa banyak tiket ngebut yang dikeluarkan. Saya belum pernah mengalami tilang selama beberapa tahun, jadi saya tidak tahu mengapa ini adalah pilihan bawah sadar saya untuk model data yang sederhana, tapi ini dia.
CREATE TABLE dbo.SpeedingTickets ( [Date] DATE NOT NULL, TicketCount INT ); GO ALTER TABLE dbo.SpeedingTickets ADD CONSTRAINT pk PRIMARY KEY CLUSTERED ([Date]); GO ;WITH x(d,h) AS ( SELECT TOP (250) ROW_NUMBER() OVER (ORDER BY [object_id]), CONVERT(INT, RIGHT([object_id], 2)) FROM sys.all_objects ORDER BY [object_id] ) INSERT dbo.SpeedingTickets([Date], TicketCount) SELECT TOP (10000) d = DATEADD(DAY, x2.d + ((x.d-1)*250), '19831231'), x2.h FROM x CROSS JOIN x AS x2 ORDER BY d; GO SELECT [Date], TicketCount FROM dbo.SpeedingTickets ORDER BY [Date]; GO
Hasil ringkasan:
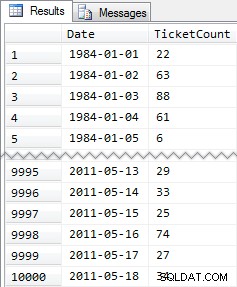
Jadi sekali lagi, 10.000 baris data yang cukup sederhana – nilai INT kecil dan serangkaian tanggal dari 1984 hingga Mei 2011.
Pendekatan
Sekarang tugas saya relatif sederhana dan tipikal dari banyak aplikasi:mengembalikan hasil yang memiliki 10.000 tanggal, bersama dengan total kumulatif semua tiket ngebut hingga dan termasuk tanggal tersebut. Kebanyakan orang pertama-tama akan mencoba sesuatu seperti ini (kami akan menyebutnya "gabungan dalam " metode):
SELECT st1.[Date], st1.TicketCount, RunningTotal = SUM(st2.TicketCount) FROM dbo.SpeedingTickets AS st1 INNER JOIN dbo.SpeedingTickets AS st2 ON st2.[Date] <= st1.[Date] GROUP BY st1.[Date], st1.TicketCount ORDER BY st1.[Date];
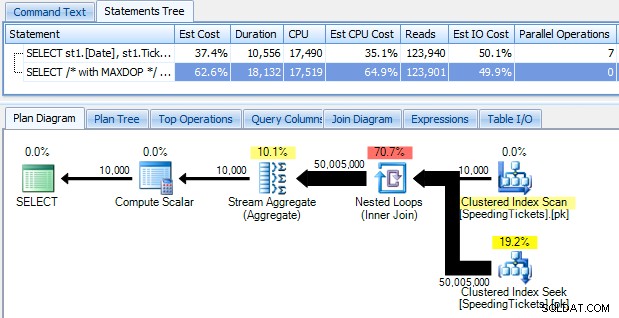
…dan terkejut mengetahui bahwa dibutuhkan hampir 10 detik untuk berlari. Mari kita periksa alasannya dengan melihat rencana eksekusi grafis, menggunakan SQL Sentry Plan Explorer:

Panah gemuk besar harus memberikan indikasi langsung tentang apa yang sedang terjadi:loop bersarang membaca satu baris untuk agregasi pertama, dua baris untuk yang kedua, tiga baris untuk yang ketiga, dan terus dan terus melalui seluruh rangkaian 10.000 baris. Ini berarti kita akan melihat kira-kira ((10000 * (10000 + 1)) / 2) baris yang diproses setelah seluruh rangkaian dilintasi, dan itu tampaknya cocok dengan jumlah baris yang ditampilkan dalam rencana.
Perhatikan bahwa menjalankan kueri tanpa paralelisme (menggunakan petunjuk kueri OPTION (MAXDOP 1)) membuat bentuk rencana sedikit lebih sederhana, tetapi tidak membantu sama sekali baik dalam waktu eksekusi atau I/O; seperti yang ditunjukkan dalam rencana, durasi sebenarnya hampir dua kali lipat, dan pembacaan hanya berkurang dengan persentase yang sangat kecil. Dibandingkan dengan rencana sebelumnya:
Ada banyak pendekatan lain yang telah dicoba orang untuk mendapatkan total lari yang efisien. Salah satu contohnya adalah "metode subkueri " yang hanya menggunakan subkueri berkorelasi dengan cara yang sama seperti metode gabungan dalam yang dijelaskan di atas:
SELECT [Date], TicketCount, RunningTotal = TicketCount + COALESCE( ( SELECT SUM(TicketCount) FROM dbo.SpeedingTickets AS s WHERE s.[Date] < o.[Date]), 0 ) FROM dbo.SpeedingTickets AS o ORDER BY [Date];
Membandingkan kedua paket tersebut:
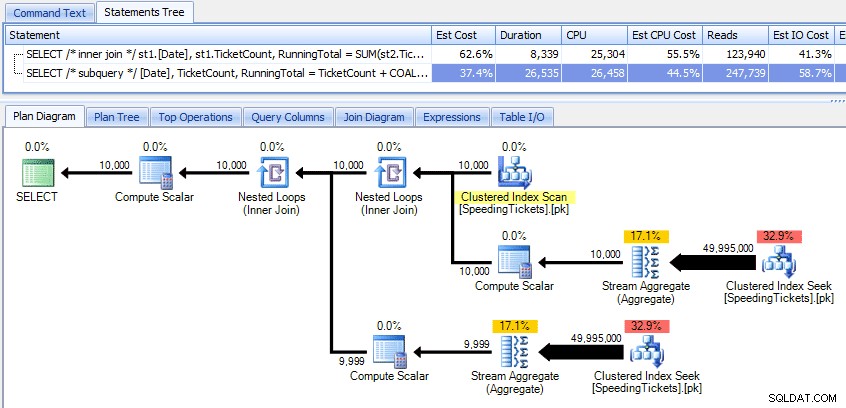
Jadi sementara metode subquery tampaknya memiliki rencana keseluruhan yang lebih efisien, itu lebih buruk di mana itu penting:durasi dan I/O. Kita dapat melihat apa yang berkontribusi terhadap hal ini dengan menggali rencana sedikit lebih dalam. Dengan berpindah ke tab Top Operations, kita dapat melihat bahwa pada metode inner join, pencarian indeks berkerumun dieksekusi 10.000 kali, dan semua operasi lainnya hanya dieksekusi beberapa kali. Namun, beberapa operasi dieksekusi 9.999 atau 10.000 kali dalam metode subquery:
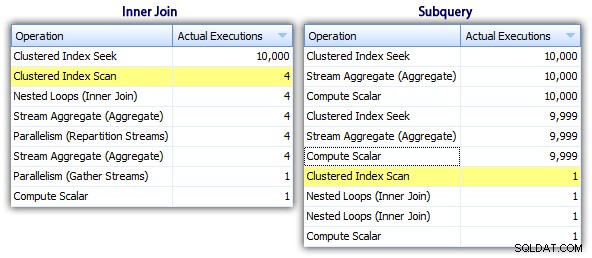
Jadi, pendekatan subquery tampaknya lebih buruk, bukan lebih baik. Metode berikutnya yang akan kita coba, saya akan memanggil "pembaruan unik ". Ini tidak sepenuhnya dijamin berfungsi, dan saya tidak akan pernah merekomendasikannya untuk kode produksi, tetapi saya menyertakannya untuk kelengkapan. Pada dasarnya pembaruan unik memanfaatkan fakta bahwa selama pembaruan Anda dapat mengalihkan tugas dan matematika jadi bahwa variabel bertambah di belakang layar saat setiap baris diperbarui.
DECLARE @st TABLE ( [Date] DATE PRIMARY KEY, TicketCount INT, RunningTotal INT ); DECLARE @RunningTotal INT = 0; INSERT @st([Date], TicketCount, RunningTotal) SELECT [Date], TicketCount, RunningTotal = 0 FROM dbo.SpeedingTickets ORDER BY [Date]; UPDATE @st SET @RunningTotal = RunningTotal = @RunningTotal + TicketCount FROM @st; SELECT [Date], TicketCount, RunningTotal FROM @st ORDER BY [Date];
Saya akan menyatakan kembali bahwa saya tidak percaya pendekatan ini aman untuk produksi, terlepas dari kesaksian yang akan Anda dengar dari orang-orang yang menunjukkan bahwa itu "tidak pernah gagal." Kecuali perilaku didokumentasikan dan dijamin, saya mencoba untuk menjauh dari asumsi berdasarkan perilaku yang diamati. Anda tidak pernah tahu kapan beberapa perubahan pada jalur keputusan pengoptimal (berdasarkan perubahan statistik, perubahan data, paket layanan, tanda jejak, petunjuk kueri, apa yang Anda miliki) akan secara drastis mengubah rencana dan berpotensi mengarah ke urutan yang berbeda. Jika Anda benar-benar menyukai pendekatan yang tidak intuitif ini, Anda dapat membuat diri Anda merasa sedikit lebih baik dengan menggunakan opsi kueri FORCE ORDER (dan ini akan mencoba menggunakan pemindaian berurutan PK, karena itulah satu-satunya indeks yang memenuhi syarat pada variabel tabel):
UPDATE @st SET @RunningTotal = RunningTotal = @RunningTotal + TicketCount FROM @st OPTION (FORCE ORDER);
Untuk sedikit lebih percaya diri dengan biaya I/O yang sedikit lebih tinggi, Anda dapat memainkan kembali tabel asli, dan memastikan bahwa PK pada tabel dasar digunakan:
UPDATE st SET @RunningTotal = st.RunningTotal = @RunningTotal + t.TicketCount FROM dbo.SpeedingTickets AS t WITH (INDEX = pk) INNER JOIN @st AS st ON t.[Date] = st.[Date] OPTION (FORCE ORDER);
Secara pribadi saya tidak berpikir itu jauh lebih terjamin, karena bagian SET dari operasi berpotensi mempengaruhi pengoptimal yang terlepas dari sisa kueri. Sekali lagi, saya tidak merekomendasikan pendekatan ini, saya hanya menyertakan perbandingan kelengkapan. Berikut adalah rencana dari kueri ini:
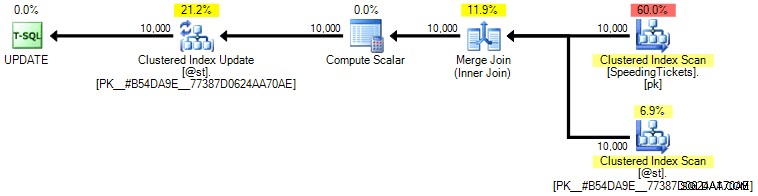
Berdasarkan jumlah eksekusi yang kita lihat di tab Operasi Teratas (saya akan memberikan cuplikan layarnya; ini adalah 1 untuk setiap operasi), jelas bahwa bahkan jika kita melakukan gabungan untuk merasa lebih baik tentang pemesanan, yang unik pembaruan memungkinkan total yang berjalan dihitung dalam satu lintasan data. Dibandingkan dengan kueri sebelumnya, ini jauh lebih efisien, meskipun pertama kali membuang data ke dalam variabel tabel dan dipisahkan menjadi beberapa operasi:

Ini membawa kita ke "CTE rekursif ". Metode ini menggunakan nilai tanggal, dan bergantung pada asumsi bahwa tidak ada celah. Karena kami mengisi data ini di atas, kami tahu bahwa ini adalah rangkaian yang sepenuhnya bersebelahan, tetapi dalam banyak skenario Anda tidak dapat membuatnya asumsi. Jadi, sementara saya memasukkannya untuk kelengkapan, pendekatan ini tidak selalu valid. Bagaimanapun, ini menggunakan CTE rekursif dengan tanggal pertama (dikenal) dalam tabel sebagai jangkar, dan rekursif porsi ditentukan dengan menambahkan satu hari (menambahkan opsi MAXRECURSION karena kita tahu persis berapa banyak baris yang kita miliki):
;WITH x AS ( SELECT [Date], TicketCount, RunningTotal = TicketCount FROM dbo.SpeedingTickets WHERE [Date] = '19840101' UNION ALL SELECT y.[Date], y.TicketCount, x.RunningTotal + y.TicketCount FROM x INNER JOIN dbo.SpeedingTickets AS y ON y.[Date] = DATEADD(DAY, 1, x.[Date]) ) SELECT [Date], TicketCount, RunningTotal FROM x ORDER BY [Date] OPTION (MAXRECURSION 10000);
Kueri ini bekerja seefisien metode pembaruan yang unik. Kita dapat membandingkannya dengan metode subquery dan inner join:

Seperti metode pembaruan yang unik, saya tidak akan merekomendasikan pendekatan CTE ini dalam produksi kecuali Anda benar-benar dapat menjamin bahwa kolom kunci Anda tidak memiliki celah. Jika Anda mungkin memiliki celah dalam data Anda, Anda dapat membuat sesuatu yang serupa menggunakan ROW_NUMBER(), tetapi itu tidak akan lebih efisien daripada metode self-join di atas.
Dan kemudian kita memiliki "kursor " pendekatan:
DECLARE @st TABLE
(
[Date] DATE PRIMARY KEY,
TicketCount INT,
RunningTotal INT
);
DECLARE
@Date DATE,
@TicketCount INT,
@RunningTotal INT = 0;
DECLARE c CURSOR
LOCAL STATIC FORWARD_ONLY READ_ONLY
FOR
SELECT [Date], TicketCount
FROM dbo.SpeedingTickets
ORDER BY [Date];
OPEN c;
FETCH NEXT FROM c INTO @Date, @TicketCount;
WHILE @@FETCH_STATUS = 0
BEGIN
SET @RunningTotal = @RunningTotal + @TicketCount;
INSERT @st([Date], TicketCount, RunningTotal)
SELECT @Date, @TicketCount, @RunningTotal;
FETCH NEXT FROM c INTO @Date, @TicketCount;
END
CLOSE c;
DEALLOCATE c;
SELECT [Date], TicketCount, RunningTotal
FROM @st
ORDER BY [Date]; …yang merupakan lebih banyak kode, tetapi bertentangan dengan pendapat umum yang mungkin menyarankan, kembali dalam 1 detik. Kita dapat melihat mengapa dari beberapa detail rencana di atas:sebagian besar pendekatan lain akhirnya membaca data yang sama berulang-ulang, sedangkan pendekatan kursor membaca setiap baris satu kali dan menyimpan total yang berjalan dalam variabel alih-alih menghitung jumlahnya dan lagi. Kita dapat melihat ini dengan melihat pernyataan yang ditangkap dengan membuat rencana aktual di Plan Explorer:
Kita dapat melihat bahwa lebih dari 20.000 pernyataan telah dikumpulkan, tetapi jika kita mengurutkan berdasarkan Perkiraan atau Baris Aktual menurun, kita menemukan bahwa hanya ada dua operasi yang menangani lebih dari satu baris. Yang jauh dari beberapa metode di atas yang menyebabkan pembacaan eksponensial karena membaca baris sebelumnya yang sama berulang-ulang untuk setiap baris baru.
Sekarang, mari kita lihat peningkatan windowing baru di SQL Server 2012. Secara khusus, kita sekarang dapat menghitung SUM OVER() dan menentukan satu set baris relatif terhadap baris saat ini. Jadi, misalnya:
SELECT [Date], TicketCount, SUM(TicketCount) OVER (ORDER BY [Date] RANGE UNBOUNDED PRECEDING) FROM dbo.SpeedingTickets ORDER BY [Date]; SELECT [Date], TicketCount, SUM(TicketCount) OVER (ORDER BY [Date] ROWS UNBOUNDED PRECEDING) FROM dbo.SpeedingTickets ORDER BY [Date];
Kedua kueri ini memberikan jawaban yang sama, dengan total berjalan yang benar. Tetapi apakah mereka bekerja persis sama? Rencana menunjukkan bahwa mereka tidak. Versi dengan ROWS memiliki operator tambahan, proyek urutan 10.000 baris:
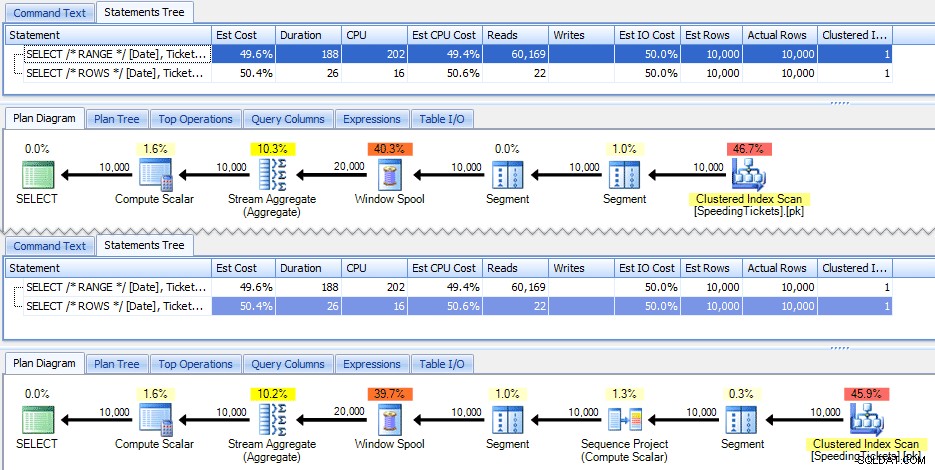
Dan itu tentang sejauh mana perbedaan dalam rencana grafis. Tetapi jika Anda melihat sedikit lebih dekat pada metrik runtime yang sebenarnya, Anda melihat perbedaan kecil dalam durasi dan CPU, dan perbedaan besar dalam pembacaan. Kenapa ini? Nah, ini karena RANGE menggunakan spool di disk, sedangkan ROWS menggunakan spool di memori. Dengan set kecil perbedaannya mungkin dapat diabaikan, tetapi biaya spool on-disk pasti bisa menjadi lebih jelas saat set menjadi lebih besar. Saya tidak ingin merusak bagian akhir, tetapi Anda mungkin curiga bahwa salah satu solusi ini akan berkinerja lebih baik daripada yang lain dalam pengujian yang lebih menyeluruh.
Selain itu, versi kueri berikut memberikan hasil yang sama, tetapi berfungsi seperti versi RANGE yang lebih lambat di atas:
SELECT [Date], TicketCount, SUM(TicketCount) OVER (ORDER BY [Date]) FROM dbo.SpeedingTickets ORDER BY [Date];
Jadi saat Anda bermain dengan fungsi windowing yang baru, Anda perlu mengingat hal-hal kecil seperti ini:versi kueri yang disingkat, atau kueri yang Anda tulis terlebih dahulu, belum tentu yang Anda inginkan. untuk mendorong ke produksi.
Tes Sebenarnya
Untuk melakukan pengujian yang adil, saya membuat prosedur tersimpan untuk setiap pendekatan, dan mengukur hasilnya dengan menangkap pernyataan di server tempat saya sudah memantau dengan SQL Sentry (jika Anda tidak menggunakan alat kami, Anda dapat mengumpulkan peristiwa SQL:BatchCompleted dengan cara yang sama menggunakan SQL Server Profiler).
Dengan "tes yang adil" maksud saya, misalnya, metode pembaruan yang unik memerlukan pembaruan aktual ke data statis, yang berarti mengubah skema yang mendasarinya atau menggunakan variabel tabel/tabel temp. Jadi saya menyusun prosedur tersimpan untuk masing-masing membuat variabel tabel mereka sendiri, dan menyimpan hasilnya di sana, atau menyimpan data mentah di sana dan kemudian memperbarui hasilnya. Masalah lain yang ingin saya hilangkan adalah mengembalikan data ke klien – jadi masing-masing prosedur memiliki parameter debug yang menentukan apakah tidak akan mengembalikan hasil (default), 5 atas/bawah, atau semuanya. Dalam pengujian kinerja, saya menyetelnya untuk tidak memberikan hasil, tetapi tentu saja memvalidasi masing-masing untuk memastikan bahwa mereka mengembalikan hasil yang benar.
Semua prosedur tersimpan dimodelkan dengan cara ini (saya telah melampirkan skrip yang membuat database dan prosedur tersimpan, jadi saya hanya menyertakan template di sini untuk singkatnya):
CREATE PROCEDURE [dbo].[RunningTotals_]
@debug TINYINT = 0
-- @debug = 1 : show top/bottom 3
-- @debug = 2 : show all 50k
AS
BEGIN
SET NOCOUNT ON;
DECLARE @st TABLE
(
[Date] DATE PRIMARY KEY,
TicketCount INT,
RunningTotal INT
);
INSERT @st([Date], TicketCount, RunningTotal)
-- one of seven approaches used to populate @t
IF @debug = 1 -- show top 3 and last 3 to verify results
BEGIN
;WITH d AS
(
SELECT [Date], TicketCount, RunningTotal,
rn = ROW_NUMBER() OVER (ORDER BY [Date])
FROM @st
)
SELECT [Date], TicketCount, RunningTotal
FROM d
WHERE rn < 4 OR rn > 9997
ORDER BY [Date];
END
IF @debug = 2 -- show all
BEGIN
SELECT [Date], TicketCount, RunningTotal
FROM @st
ORDER BY [Date];
END
END
GO Dan saya memanggil mereka secara berkelompok sebagai berikut:
EXEC dbo.RunningTotals_DateCTE @debug = 0; GO EXEC dbo.RunningTotals_Cursor @debug = 0; GO EXEC dbo.RunningTotals_Subquery @debug = 0; GO EXEC dbo.RunningTotals_InnerJoin @debug = 0; GO EXEC dbo.RunningTotals_QuirkyUpdate @debug = 0; GO EXEC dbo.RunningTotals_Windowed_Range @debug = 0; GO EXEC dbo.RunningTotals_Windowed_Rows @debug = 0; GO
Saya segera menyadari bahwa beberapa panggilan ini tidak muncul di Top SQL karena ambang batas default adalah 5 detik. Saya mengubahnya menjadi 100 milidetik (sesuatu yang tidak ingin Anda lakukan pada sistem produksi!) sebagai berikut:
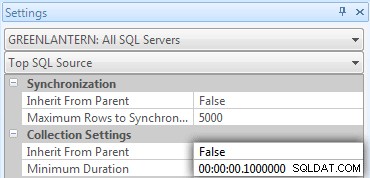
Saya akan ulangi:perilaku ini tidak dibenarkan untuk sistem produksi!
Saya masih menemukan bahwa salah satu perintah di atas tidak tertangkap oleh ambang SQL Top; itu adalah versi Windowed_Rows. Jadi saya menambahkan yang berikut ke kumpulan itu saja:
EXEC dbo.RunningTotals_Windowed_Rows @debug = 0; WAITFOR DELAY '00:00:01'; GO
Dan sekarang saya mendapatkan semua 7 baris dikembalikan di Top SQL. Di sini mereka diurutkan berdasarkan penggunaan CPU menurun:
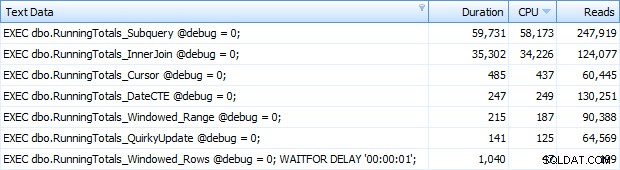
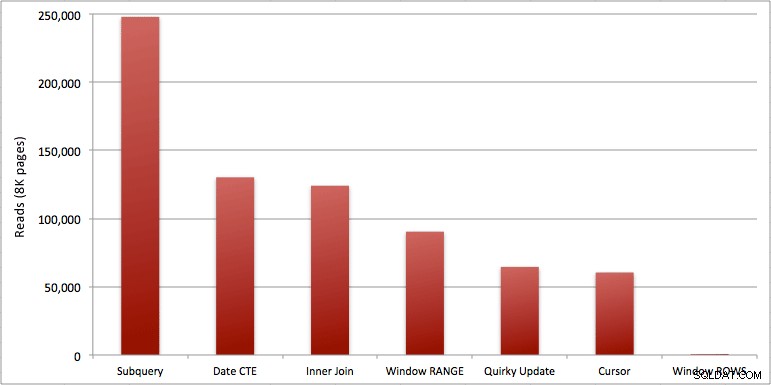
Anda dapat melihat detik ekstra yang saya tambahkan ke kumpulan Windowed_Rows; itu tidak tertangkap oleh ambang SQL Top karena selesai hanya dalam 40 milidetik! Ini jelas merupakan kinerja terbaik kami dan, jika kami memiliki SQL Server 2012, itu harus menjadi metode yang kami gunakan. Kursor juga tidak terlalu buruk, mengingat kinerja atau masalah lain dengan solusi yang tersisa. Memplot durasi pada grafik sangat tidak berarti – dua poin tinggi dan lima poin rendah yang tidak dapat dibedakan. Tetapi jika I/O adalah hambatan Anda, visualisasi bacaan mungkin akan menarik bagi Anda:
Kesimpulan
Dari hasil tersebut kita dapat menarik beberapa kesimpulan:
- Agregat berjendela di SQL Server 2012 membuat masalah kinerja dengan menjalankan perhitungan total (dan banyak masalah baris berikutnya / baris sebelumnya) menjadi lebih efisien. Ketika saya melihat jumlah bacaan yang rendah, saya pikir pasti ada semacam kesalahan, bahwa saya pasti lupa untuk benar-benar melakukan pekerjaan apa pun. Tapi tidak, Anda mendapatkan jumlah pembacaan yang sama jika prosedur tersimpan Anda hanya melakukan SELECT biasa dari tabel SpeedingTickets. (Jangan ragu untuk mengujinya sendiri dengan STATISTICS IO.)
- Masalah yang saya tunjukkan sebelumnya tentang RANGE vs. ROWS menghasilkan runtime yang sedikit berbeda (perbedaan durasi sekitar 6x – ingat untuk mengabaikan detik yang saya tambahkan dengan WAITFOR), tetapi perbedaan pembacaan sangat besar karena spool pada disk. Jika agregat berjendela Anda dapat diselesaikan menggunakan ROWS, hindari RANGE, tetapi Anda harus menguji bahwa keduanya memberikan hasil yang sama (atau setidaknya ROWS memberikan jawaban yang benar). Anda juga harus memperhatikan bahwa jika Anda menggunakan kueri serupa dan Anda tidak menentukan RANGE atau BARIS, paket akan beroperasi seolah-olah Anda telah menentukan RANGE).
- Metode subquery dan inner join relatif buruk. 35 detik hingga satu menit untuk menghasilkan total berjalan ini? Dan ini ada di satu meja kurus tanpa mengembalikan hasil ke klien. Perbandingan ini dapat digunakan untuk menunjukkan kepada orang-orang mengapa solusi berbasis himpunan murni tidak selalu merupakan jawaban terbaik.
- Dari pendekatan yang lebih cepat, dengan asumsi Anda belum siap untuk SQL Server 2012, dan dengan asumsi Anda membuang metode pembaruan yang unik (tidak didukung) dan metode tanggal CTE (tidak dapat menjamin urutan yang berurutan), hanya kursor yang berfungsi diterima. Ini memiliki durasi tertinggi dari solusi "lebih cepat", tetapi jumlah pembacaan paling sedikit.
Saya harap tes ini membantu memberikan apresiasi yang lebih baik untuk peningkatan windowing yang telah ditambahkan Microsoft ke SQL Server 2012. Pastikan untuk berterima kasih kepada Itzik jika Anda melihatnya online atau secara langsung, karena dia adalah kekuatan pendorong di balik perubahan ini. Selain itu, saya harap ini membantu membuka pikiran di luar sana bahwa kursor mungkin tidak selalu menjadi solusi jahat dan menakutkan yang sering digambarkan.
(Sebagai tambahan, saya menguji fungsi CLR yang ditawarkan oleh Pavel Pawlowski, dan karakteristik kinerjanya hampir identik dengan solusi SQL Server 2012 menggunakan ROWS. Pembacaan identik, CPU adalah 78 vs. 47, dan durasi keseluruhan adalah 73, bukan 40. Jadi, jika Anda tidak akan pindah ke SQL Server 2012 dalam waktu dekat, Anda mungkin ingin menambahkan solusi Pavel ke pengujian Anda.)
Lampiran:RunningTotals_Demo.sql.zip (2kb)