Prinsip "Jangan Ulangi Diri Sendiri" menyarankan agar Anda mengurangi pengulangan. Minggu ini saya menemukan kasus di mana KERING harus dibuang ke luar jendela. Ada kasus lain juga (misalnya, fungsi skalar), tetapi yang ini menarik yang melibatkan logika Bitwise.
Mari kita bayangkan tabel berikut:
CREATE TABLE dbo.CarOrders
(
OrderID INT PRIMARY KEY,
WheelFlag TINYINT,
OrderDate DATE
--, ... other columns ...
);
CREATE INDEX IX_WheelFlag ON dbo.CarOrders(WheelFlag); Bit "WheelFlag" mewakili opsi berikut:
0 = stock wheels 1 = 17" wheels 2 = 18" wheels 4 = upgraded tires
Jadi kemungkinan kombinasinya adalah:
0 = no upgrade 1 = upgrade to 17" wheels only 2 = upgrade to 18" wheels only 4 = upgrade tires only 5 = 1 + 4 = upgrade to 17" wheels and better tires 6 = 2 + 4 = upgrade to 18" wheels and better tires
Mari kita kesampingkan argumen, setidaknya untuk saat ini, tentang apakah ini harus dikemas ke dalam satu TINYINT di tempat pertama, atau disimpan sebagai kolom terpisah, atau menggunakan model EAV… memperbaiki desain adalah masalah terpisah. Ini tentang bekerja dengan apa yang Anda miliki.
Untuk membuat contoh berguna, mari isi tabel ini dengan sekumpulan data acak. (Dan kami akan berasumsi, untuk kesederhanaan, bahwa tabel ini hanya berisi pesanan yang belum dikirim.) Ini akan memasukkan 50.000 baris dengan distribusi yang kira-kira sama antara enam kombinasi opsi:
;WITH n AS
(
SELECT n,Flag FROM (VALUES(1,0),(2,1),(3,2),(4,4),(5,5),(6,6)) AS n(n,Flag)
)
INSERT dbo.CarOrders
(
OrderID,
WheelFlag,
OrderDate
)
SELECT x.rn, n.Flag, DATEADD(DAY, x.rn/100, '20100101')
FROM n
INNER JOIN
(
SELECT TOP (50000)
n = (ABS(s1.[object_id]) % 6) + 1,
rn = ROW_NUMBER() OVER (ORDER BY s2.[object_id])
FROM sys.all_objects AS s1
CROSS JOIN sys.all_objects AS s2
) AS x
ON n.n = x.n; Jika kita melihat breakdown, kita bisa melihat distribusi ini. Perhatikan bahwa hasil Anda mungkin sedikit berbeda dari hasil saya tergantung pada objek di sistem Anda:
SELECT WheelFlag, [Count] = COUNT(*) FROM dbo.CarOrders GROUP BY WheelFlag;
Hasil:
WheelFlag Count --------- ----- 0 7654 1 8061 2 8757 4 8682 5 8305 6 8541
Sekarang katakanlah hari Selasa, dan kami baru saja menerima pengiriman velg 18", yang sebelumnya kehabisan stok. Artinya, kami dapat memenuhi semua pesanan yang membutuhkan velg 18" – baik yang mengupgrade ban (6), dan yang tidak (2). Jadi kita *bisa* menulis query seperti berikut:
SELECT OrderID
FROM dbo.CarOrders
WHERE WheelFlag IN (2,6); Dalam kehidupan nyata, tentu saja, Anda tidak bisa melakukan itu; bagaimana jika lebih banyak opsi ditambahkan nanti, seperti kunci roda, garansi roda seumur hidup, atau beberapa opsi ban? Anda tidak ingin harus menulis serangkaian nilai IN() untuk setiap kemungkinan kombinasi. Sebagai gantinya kita dapat menulis operasi BITWISE AND, untuk menemukan semua baris di mana bit ke-2 disetel, seperti:
DECLARE @Flag TINYINT = 2;
SELECT OrderID
FROM dbo.CarOrders
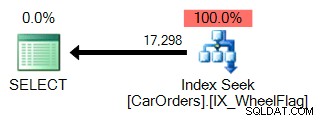
WHERE WheelFlag & @Flag = @Flag; Ini memberi saya hasil yang sama dengan kueri IN(), tetapi jika saya membandingkannya menggunakan SQL Sentry Plan Explorer, kinerjanya sangat berbeda:

Sangat mudah untuk melihat mengapa. Yang pertama menggunakan pencarian indeks untuk mengisolasi baris yang memenuhi kueri, dengan filter pada kolom WheelFlag:

Yang kedua menggunakan pemindaian, ditambah dengan konversi implisit, dan statistik yang sangat tidak akurat. Semua karena operator BITWISE AND:
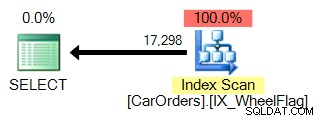


Jadi apa artinya ini? Pada intinya, ini memberi tahu kita bahwa operasi BITWISE AND tidak dapat dibesar-besarkan .
Tapi semua harapan tidak hilang.
Jika kita mengabaikan prinsip KERING sejenak, kita dapat menulis kueri yang sedikit lebih efisien dengan menjadi sedikit berlebihan untuk memanfaatkan indeks pada kolom WheelFlag. Dengan asumsi bahwa kita mencari opsi WheelFlag di atas 0 (tidak ada peningkatan sama sekali), kita dapat menulis ulang kueri dengan cara ini, memberi tahu SQL Server bahwa nilai WheelFlag setidaknya harus sama dengan nilai flag (yang menghilangkan 0 dan 1 ), lalu menambahkan informasi tambahan yang juga harus berisi tanda itu (sehingga menghilangkan 5).
SELECT OrderID FROM dbo.CarOrders WHERE WheelFlag >= @Flag AND WheelFlag & @Flag = @Flag;
Bagian>=dari klausa ini jelas dicakup oleh bagian BITWISE, jadi di sinilah kita melanggar DRY. Tetapi karena klausa yang telah kami tambahkan ini dapat dibesar-besarkan, menurunkan operasi BITWISE AND ke kondisi pencarian sekunder masih menghasilkan hasil yang sama, dan kueri keseluruhan menghasilkan kinerja yang lebih baik. Kami melihat indeks serupa mencari versi hard-code dari kueri di atas, dan sementara perkiraannya bahkan lebih jauh (sesuatu yang dapat diatasi sebagai masalah terpisah), pembacaan masih lebih rendah daripada dengan operasi BITWISE AND saja:

Kita juga dapat melihat bahwa filter digunakan untuk melawan indeks, yang tidak kita lihat saat menggunakan operasi BITWISE AND saja:

Kesimpulan
Jangan takut untuk mengulanginya sendiri. Ada kalanya informasi ini dapat membantu pengoptimal; meskipun mungkin tidak sepenuhnya intuitif untuk *menambahkan* kriteria untuk meningkatkan kinerja, penting untuk dipahami ketika klausa tambahan membantu mengurangi data untuk hasil akhir daripada membuatnya "mudah" bagi pengoptimal untuk menemukan baris yang tepat sendiri.