Saat mengutak-atik postgresql.conf , Anda mungkin telah memperhatikan ada opsi yang disebut full_page_writes . Komentar di sebelahnya mengatakan sesuatu tentang penulisan halaman parsial, dan orang-orang biasanya membiarkannya disetel ke on – yang merupakan hal yang baik, seperti yang akan saya jelaskan nanti di posting ini. Akan tetapi, memahami apa yang dilakukan penulisan halaman penuh sangat berguna, karena dampaknya pada performa mungkin cukup signifikan.
Tidak seperti posting saya sebelumnya tentang penyetelan pos pemeriksaan, ini bukan panduan cara menyetel server. Sebenarnya tidak banyak yang dapat Anda sesuaikan, tetapi saya akan menunjukkan kepada Anda bagaimana beberapa keputusan tingkat aplikasi (misalnya pilihan tipe data) dapat berinteraksi dengan penulisan halaman penuh.
Tulisan Sebagian / Halaman Robek
Jadi apa yang ditulis halaman penuh? Seperti komentar di postgresql.conf mengatakan ini adalah cara untuk memulihkan dari sebagian penulisan halaman – PostgreSQL menggunakan halaman 8kB (secara default), tetapi bagian lain dari tumpukan menggunakan ukuran potongan yang berbeda. Sistem file Linux biasanya menggunakan halaman 4kB (mungkin untuk menggunakan halaman yang lebih kecil, tetapi 4kB adalah maksimal pada x86), dan pada tingkat perangkat keras drive lama menggunakan sektor 512B sementara perangkat baru sering menulis data dalam potongan yang lebih besar (seringkali 4kB atau bahkan 8kB) .
Jadi ketika PostgreSQL menulis halaman 8kB, lapisan lain dari tumpukan penyimpanan dapat memecahnya menjadi potongan yang lebih kecil, dikelola secara terpisah. Ini menyajikan masalah tentang menulis atom. Halaman PostgreSQL 8kB dapat dibagi menjadi dua halaman sistem file 4kB, dan kemudian menjadi sektor 512B. Sekarang, bagaimana jika server mogok (kegagalan daya, bug kernel, ...)?
Bahkan jika server menggunakan sistem penyimpanan yang dirancang untuk menangani kegagalan tersebut (SSD dengan kapasitor, pengontrol RAID dengan baterai, ...), kernel sudah membagi data menjadi halaman 4kB. Jadi mungkin saja database menulis halaman data 8kB, tetapi hanya sebagian yang berhasil masuk ke disk sebelum error.
Pada titik ini Anda sekarang mungkin berpikir bahwa inilah tepatnya mengapa kami memiliki log transaksi (WAL), dan Anda benar! Jadi setelah memulai server, database akan membaca WAL (sejak pos pemeriksaan terakhir selesai), dan menerapkan perubahan lagi untuk memastikan file data lengkap. Sederhana.
Tapi ada masalah – pemulihan tidak menerapkan perubahan secara membabi buta, sering kali perlu membaca halaman data, dll. Yang mengasumsikan bahwa halaman tersebut belum dibor dalam beberapa cara, misalnya karena penulisan sebagian. Yang tampaknya agak kontradiktif, karena untuk memperbaiki kerusakan data, kami menganggap tidak ada kerusakan data.
Penulisan halaman penuh adalah cara mengatasi teka-teki ini – saat memodifikasi halaman untuk pertama kalinya setelah pos pemeriksaan, seluruh halaman ditulis ke dalam WAL. Ini menjamin bahwa selama pemulihan, catatan WAL pertama yang menyentuh halaman berisi seluruh halaman, menghilangkan kebutuhan untuk membaca halaman – yang mungkin rusak – dari file data.
Menulis amplifikasi
Tentu saja, konsekuensi negatif dari ini adalah peningkatan ukuran WAL – mengubah satu byte pada halaman 8kB akan memasukkan keseluruhan ke dalam WAL. Penulisan satu halaman penuh hanya terjadi pada penulisan pertama setelah pos pemeriksaan, jadi membuat pos pemeriksaan lebih jarang adalah salah satu cara untuk memperbaiki situasi – biasanya, ada "semburan" singkat dari penulisan satu halaman penuh setelah pos pemeriksaan, dan kemudian relatif sedikit penulisan satu halaman penuh sampai akhir pos pemeriksaan.
Kunci UUID vs. BIGSERIAL
Tetapi ada beberapa interaksi tak terduga dengan keputusan desain yang dibuat di tingkat aplikasi. Mari kita asumsikan kita memiliki tabel sederhana dengan kunci utama, baik BIGSERIAL atau UUID , dan kami memasukkan data ke dalamnya. Apakah akan ada perbedaan jumlah WAL yang dihasilkan (dengan asumsi kita memasukkan jumlah baris yang sama)?
Tampaknya masuk akal untuk mengharapkan kedua kasus menghasilkan jumlah WAL yang hampir sama, tetapi seperti yang diilustrasikan oleh bagan berikut, ada perbedaan besar dalam praktiknya.
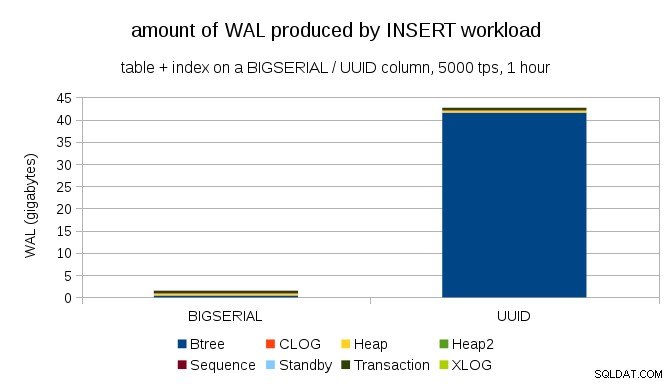
Ini menunjukkan jumlah WAL yang dihasilkan selama benchmark 1 jam, dibatasi hingga 5000 insert per detik. Dengan BIGSERIAL kunci utama ini menghasilkan ~2GB WAL, sedangkan dengan UUID ini lebih dari 40GB. Itu perbedaan yang cukup signifikan, dan cukup jelas sebagian besar WAL dikaitkan dengan indeks yang mendukung kunci utama. Mari kita lihat sebagai jenis catatan WAL.
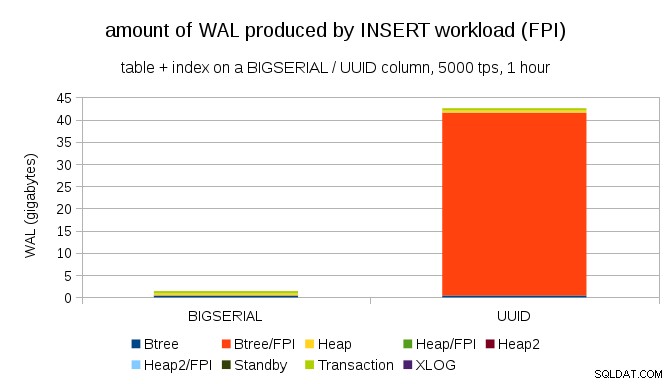
Jelas, sebagian besar catatan adalah gambar satu halaman penuh (FPI), yaitu hasil penulisan satu halaman penuh. Tapi mengapa ini terjadi?
Tentu saja, ini karena UUID yang melekat keserampangan. Dengan BIGSERIAL baru berurutan, dan karenanya dimasukkan ke halaman daun yang sama di indeks btree. Karena hanya modifikasi pertama pada halaman yang memicu penulisan satu halaman penuh, hanya sebagian kecil dari catatan WAL yang merupakan FPI. Dengan UUID ini kasus yang sama sekali berbeda, tentu saja – nilainya tidak berurutan sama sekali, bahkan setiap sisipan cenderung menyentuh halaman daun indeks daun yang sama sekali baru (dengan asumsi indeks cukup besar).
Tidak banyak yang dapat dilakukan database – beban kerjanya hanya bersifat acak, memicu banyak penulisan halaman penuh.
Tidak sulit untuk mendapatkan amplifikasi penulisan serupa bahkan dengan BIGSERIAL kunci, tentu saja. Ini hanya membutuhkan beban kerja yang berbeda – misalnya dengan UPDATE beban kerja, memperbarui catatan secara acak dengan distribusi seragam, bagan terlihat seperti ini:
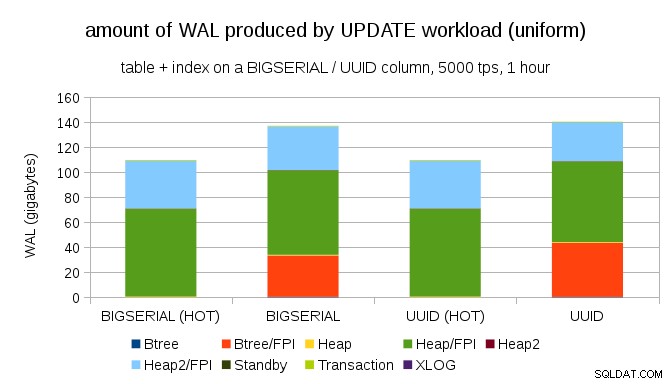
Tiba-tiba, perbedaan antara tipe data hilang – aksesnya acak dalam kedua kasus, menghasilkan jumlah WAL yang hampir sama persis. Perbedaan lain adalah bahwa sebagian besar WAL dikaitkan dengan "heap", yaitu tabel, dan bukan indeks. Kasing "PANAS" dirancang untuk memungkinkan pengoptimalan PEMBARUAN PANAS (yaitu pembaruan tanpa harus menyentuh indeks), yang cukup banyak menghilangkan semua lalu lintas WAL terkait indeks.
Tetapi Anda mungkin berpendapat bahwa sebagian besar aplikasi tidak memperbarui seluruh kumpulan data. Biasanya, hanya sebagian kecil data yang “aktif” – orang hanya mengakses posting dari beberapa hari terakhir di forum diskusi, pesanan yang belum terselesaikan di e-shop, dll. Bagaimana hal itu mengubah hasil?
Untungnya, pgbench mendukung distribusi yang tidak seragam, dan misalnya dengan distribusi eksponensial menyentuh 1% subset data ~25% dari waktu, bagan terlihat seperti ini:
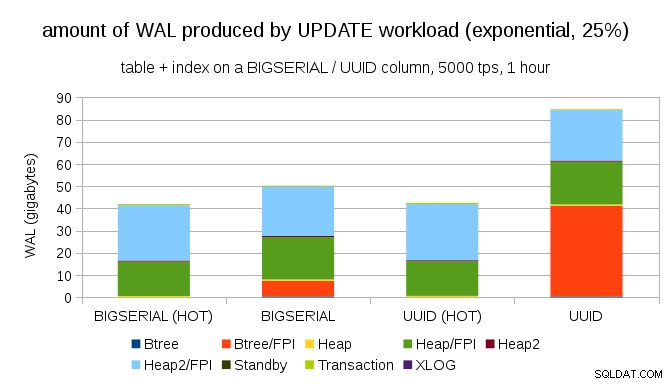
Dan setelah membuat distribusi lebih miring, menyentuh bagian 1% ~75% dari waktu:
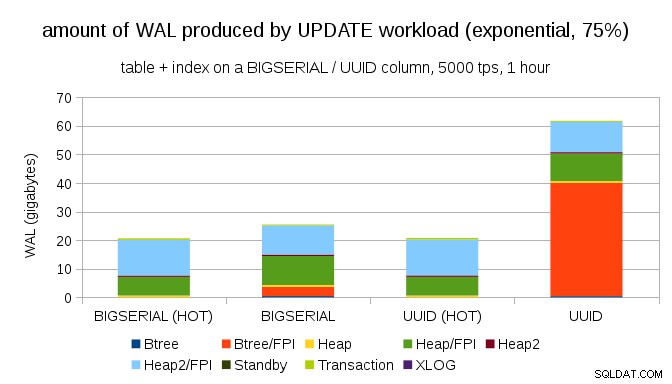
Ini sekali lagi menunjukkan betapa besar perbedaan yang mungkin terjadi pada pilihan tipe data, dan juga pentingnya menyetel pembaruan PANAS.
Halaman 8kB dan 4kB
Pertanyaan yang menarik adalah berapa banyak lalu lintas WAL yang dapat kita hemat dengan menggunakan halaman yang lebih kecil di PostgreSQL (yang memerlukan kompilasi paket khusus). Dalam kasus terbaik, mungkin menghemat hingga 50% WAL, berkat logging hanya 4kB, bukan halaman 8kB. Untuk beban kerja dengan UPDATE yang terdistribusi secara merata, tampilannya seperti ini:
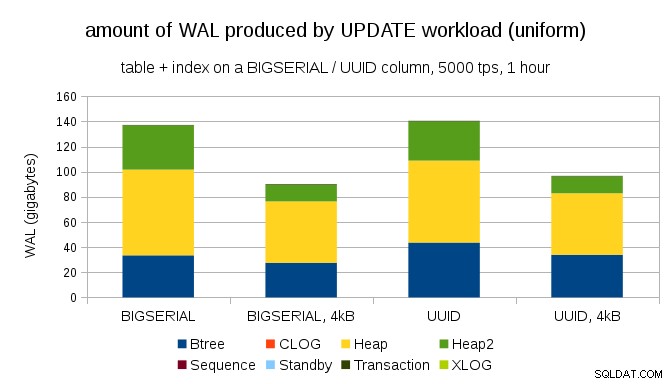
Jadi penghematannya tidak tepat 50%, tapi pengurangan dari ~140GB menjadi ~90GB masih cukup signifikan.
Apakah kita masih membutuhkan penulisan satu halaman penuh?
Mungkin tampak konyol setelah menjelaskan bahaya penulisan sebagian, tetapi mungkin menonaktifkan penulisan halaman penuh mungkin merupakan opsi yang layak, setidaknya dalam beberapa kasus.
Pertama, saya bertanya-tanya apakah sistem file Linux modern masih rentan terhadap penulisan parsial? Parameter tersebut diperkenalkan di PostgreSQL 8.1 yang dirilis pada tahun 2005, jadi mungkin beberapa dari banyak peningkatan sistem file yang diperkenalkan sejak saat itu menjadikan ini bukan masalah. Mungkin tidak secara universal untuk beban kerja yang sewenang-wenang, tetapi mungkin dengan asumsi beberapa kondisi tambahan (misalnya menggunakan ukuran halaman 4kB di PostgreSQL) akan cukup? Selain itu, PostgreSQL tidak pernah menimpa hanya sebagian dari halaman 8kB – seluruh halaman selalu ditulis.
Saya telah melakukan banyak tes baru-baru ini mencoba memicu penulisan parsial, dan saya belum berhasil menyebabkan satu kasus pun. Tentu saja, itu tidak benar-benar membuktikan bahwa masalah itu tidak ada. Namun meskipun masih menjadi masalah, pemeriksaan data mungkin merupakan perlindungan yang cukup (tidak akan memperbaiki masalah, tetapi setidaknya akan memberi tahu Anda bahwa ada halaman yang rusak).
Kedua, banyak sistem saat ini mengandalkan replika replikasi streaming – alih-alih menunggu server melakukan boot ulang setelah masalah perangkat keras (yang dapat memakan waktu cukup lama) dan kemudian menghabiskan lebih banyak waktu untuk melakukan pemulihan, sistem hanya beralih ke siaga panas. Jika database pada database utama yang gagal dihapus (dan kemudian dikloning dari database utama yang baru), penulisan sebagian tidak menjadi masalah.
Tapi saya kira jika kami mulai merekomendasikan itu, maka "Saya tidak tahu bagaimana data menjadi rusak, saya baru saja mengatur full_page_writes=off pada sistem!" akan menjadi salah satu kalimat paling umum tepat sebelum kematian untuk DBA (bersama dengan "Saya telah melihat ular ini di reddit, itu tidak beracun.").
Ringkasan
Tidak banyak yang dapat Anda lakukan untuk menyetel penulisan satu halaman penuh secara langsung. Untuk sebagian besar beban kerja, sebagian besar penulisan halaman penuh terjadi tepat setelah pos pemeriksaan, lalu menghilang hingga pos pemeriksaan berikutnya. Jadi, penting untuk menyetel pos pemeriksaan agar tidak terlalu sering terjadi.
Beberapa keputusan tingkat aplikasi dapat meningkatkan keacakan penulisan ke tabel dan indeks – misalnya nilai UUID secara inheren acak, bahkan mengubah beban kerja INSERT sederhana menjadi pembaruan indeks acak. Skema yang digunakan dalam contoh agak sepele – dalam praktiknya akan ada indeks sekunder, kunci asing, dll. Tetapi menggunakan kunci utama BIGSERIAL secara internal (dan menjaga UUID sebagai kunci pengganti) setidaknya akan mengurangi amplifikasi penulisan.
Saya sangat tertarik dengan diskusi tentang perlunya penulisan satu halaman penuh pada kernel / sistem file saat ini. Sayangnya saya belum menemukan banyak sumber, jadi jika Anda memiliki info yang relevan, beri tahu saya.