PostgreSQL dikenal sebagai database opensource tercanggih, dan membantu Anda mengelola data tidak peduli seberapa besar, kecil, atau berbeda kumpulan data tersebut, sehingga Anda dapat menggunakannya untuk mengelola atau menganalisis data besar Anda, dan tentu saja, ada beberapa cara untuk memungkinkan hal ini, misalnya Apache Spark. Di blog ini, kita akan melihat apa itu Apache Spark dan bagaimana kita dapat menggunakannya untuk bekerja dengan database PostgreSQL kita.
Untuk analitik data besar, kami memiliki dua jenis analitik yang berbeda:
- Analisis batch:Berdasarkan data yang dikumpulkan selama periode waktu tertentu.
- Analisis (aliran) waktu-nyata:Berdasarkan data langsung untuk hasil instan.
Apa itu Apache Spark?
Apache Spark adalah mesin analitik terpadu untuk pemrosesan data skala besar yang dapat bekerja pada analitik batch dan real-time dengan cara yang lebih cepat dan mudah.
Ini menyediakan API tingkat tinggi di Java, Scala, Python dan R, dan mesin yang dioptimalkan yang mendukung grafik eksekusi umum.
 Komponen Apache Spark
Komponen Apache Spark Perpustakaan Apache Spark
Apache Spark menyertakan pustaka yang berbeda:
- Spark SQL:Ini adalah modul untuk bekerja dengan data terstruktur menggunakan SQL atau DataFrame API. Ini menyediakan cara umum untuk mengakses berbagai sumber data, termasuk Hive, Avro, Parket, ORC, JSON, dan JDBC. Anda bahkan dapat menggabungkan data di seluruh sumber ini.
- Spark Streaming:Membuat aplikasi streaming yang toleran terhadap kesalahan yang dapat diskalakan menggunakan API terintegrasi bahasa untuk memproses streaming menjadi mudah, memungkinkan Anda menulis tugas streaming dengan cara yang sama seperti Anda menulis tugas batch. Ini mendukung Java, Scala dan Python. Spark Streaming memulihkan pekerjaan yang hilang dan status operator di luar kotak, tanpa kode tambahan apa pun dari Anda. Ini memungkinkan Anda menggunakan kembali kode yang sama untuk pemrosesan batch, menggabungkan aliran terhadap data historis, atau menjalankan kueri ad-hoc pada status aliran.
- MLib (Pembelajaran Mesin):Ini adalah perpustakaan pembelajaran mesin yang skalabel. MLlib berisi algoritme berkualitas tinggi yang memanfaatkan iterasi dan dapat menghasilkan hasil yang lebih baik daripada perkiraan satu arah yang terkadang digunakan di MapReduce.
- GraphX:Ini adalah API untuk grafik dan komputasi paralel grafik. GraphX menyatukan ETL, analisis eksplorasi, dan komputasi grafik iteratif dalam satu sistem. Anda dapat melihat data yang sama baik sebagai grafik maupun kumpulan, mengubah dan menggabungkan grafik dengan RDD secara efisien, dan menulis algoritme grafik iteratif khusus menggunakan Pregel API.
Keunggulan Apache Spark
Menurut dokumentasi resmi, beberapa keunggulan Apache Spark adalah:
- Kecepatan:Menjalankan beban kerja 100x lebih cepat. Apache Spark mencapai performa tinggi untuk data batch dan streaming, menggunakan penjadwal DAG (Direct Acyclic Graph) yang canggih, pengoptimal kueri, dan mesin eksekusi fisik.
- Kemudahan Penggunaan:Tulis aplikasi dengan cepat di Java, Scala, Python, R, dan SQL. Spark menawarkan lebih dari 80 operator tingkat tinggi yang memudahkan pembuatan aplikasi paralel. Anda dapat menggunakannya secara interaktif dari shell Scala, Python, R, dan SQL.
- Umum:Menggabungkan SQL, streaming, dan analitik kompleks. Spark mendukung setumpuk pustaka termasuk SQL dan DataFrames, MLlib untuk pembelajaran mesin, GraphX, dan Spark Streaming. Anda dapat menggabungkan pustaka ini dengan mulus dalam aplikasi yang sama.
- Berjalan Di Mana Saja:Spark berjalan di Hadoop, Apache Mesos, Kubernetes, mandiri, atau di cloud. Itu dapat mengakses beragam sumber data. Anda dapat menjalankan Spark menggunakan mode cluster mandiri, di EC2, di Hadoop YARN, di Mesos, atau di Kubernetes. Akses data di HDFS, Alluxio, Apache Cassandra, Apache HBase, Apache Hive, dan ratusan sumber data lainnya.
Sekarang, mari kita lihat bagaimana kita dapat mengintegrasikan ini dengan database PostgreSQL kita.
Cara Menggunakan Apache Spark dengan PostgreSQL
Kami akan menganggap Anda telah mengaktifkan dan menjalankan cluster PostgreSQL. Untuk tugas ini, kami akan menggunakan server PostgreSQL 11 yang berjalan di CentOS7.
Pertama, mari buat database pengujian kami di server PostgreSQL kami:
postgres=# CREATE DATABASE testing;
CREATE DATABASE
postgres=# \c testing
You are now connected to database "testing" as user "postgres".Sekarang, kita akan membuat tabel bernama t1:
testing=# CREATE TABLE t1 (id int, name text);
CREATE TABLEDan masukkan beberapa data di sana:
testing=# INSERT INTO t1 VALUES (1,'name1');
INSERT 0 1
testing=# INSERT INTO t1 VALUES (2,'name2');
INSERT 0 1Periksa data yang dibuat:
testing=# SELECT * FROM t1;
id | name
----+-------
1 | name1
2 | name2
(2 rows)Untuk menghubungkan Apache Spark ke database PostgreSQL kami, kami akan menggunakan konektor JDBC. Anda dapat mengunduhnya dari sini.
$ wget https://jdbc.postgresql.org/download/postgresql-42.2.6.jarSekarang, mari kita instal Apache Spark. Untuk ini, kita perlu mengunduh paket percikan dari sini.
$ wget https://us.mirrors.quenda.co/apache/spark/spark-2.4.3/spark-2.4.3-bin-hadoop2.7.tgz
$ tar zxvf spark-2.4.3-bin-hadoop2.7.tgz
$ cd spark-2.4.3-bin-hadoop2.7/Untuk menjalankan shell Spark, kami membutuhkan JAVA yang diinstal di server kami:
$ yum install javaJadi sekarang, kita bisa menjalankan Spark Shell kita:
$ ./bin/spark-shell
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at https://ApacheSpark1:4040
Spark context available as 'sc' (master = local[*], app id = local-1563907528854).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.4.3
/_/
Using Scala version 2.11.12 (OpenJDK 64-Bit Server VM, Java 1.8.0_212)
Type in expressions to have them evaluated.
Type :help for more information.
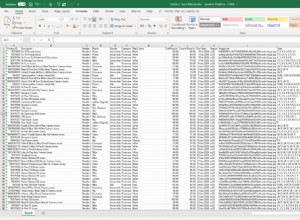
scala>Kami dapat mengakses UI Web konteks Spark kami yang tersedia di port 4040 di server kami:
 Apache Spark UI
Apache Spark UI Ke dalam shell Spark, kita perlu menambahkan driver PostgreSQL JDBC:
scala> :require /path/to/postgresql-42.2.6.jar
Added '/path/to/postgresql-42.2.6.jar' to classpath.
scala> import java.util.Properties
import java.util.PropertiesDan tambahkan informasi JDBC untuk digunakan oleh Spark:
scala> val url = "jdbc:postgresql://localhost:5432/testing"
url: String = jdbc:postgresql://localhost:5432/testing
scala> val connectionProperties = new Properties()
connectionProperties: java.util.Properties = {}
scala> connectionProperties.setProperty("Driver", "org.postgresql.Driver")
res6: Object = nullSekarang, kita dapat mengeksekusi query SQL. Pertama, mari kita definisikan query1 sebagai SELECT * FROM t1, tabel pengujian kita.
scala> val query1 = "(SELECT * FROM t1) as q1"
query1: String = (SELECT * FROM t1) as q1Dan buat DataFrame:
scala> val query1df = spark.read.jdbc(url, query1, connectionProperties)
query1df: org.apache.spark.sql.DataFrame = [id: int, name: string]
Jadi sekarang, kita dapat melakukan tindakan pada DataFrame ini:
scala> query1df.show()
+---+-----+
| id| name|
+---+-----+
| 1|name1|
| 2|name2|
+---+-----+scala> query1df.explain
== Physical Plan ==
*(1) Scan JDBCRelation((SELECT * FROM t1) as q1) [numPartitions=1] [id#19,name#20] PushedFilters: [], ReadSchema: struct<id:int,name:string>Kami dapat menambahkan lebih banyak nilai dan menjalankannya lagi hanya untuk mengonfirmasi bahwa itu mengembalikan nilai saat ini.
PostgreSQL
testing=# INSERT INTO t1 VALUES (10,'name10'), (11,'name11'), (12,'name12'), (13,'name13'), (14,'name14'), (15,'name15');
INSERT 0 6
testing=# SELECT * FROM t1;
id | name
----+--------
1 | name1
2 | name2
10 | name10
11 | name11
12 | name12
13 | name13
14 | name14
15 | name15
(8 rows)Percikan
scala> query1df.show()
+---+------+
| id| name|
+---+------+
| 1| name1|
| 2| name2|
| 10|name10|
| 11|name11|
| 12|name12|
| 13|name13|
| 14|name14|
| 15|name15|
+---+------+Dalam contoh kami, kami hanya menunjukkan bagaimana Apache Spark bekerja dengan database PostgreSQL kami, bukan bagaimana mengelola informasi Big Data kami.
Kesimpulan
Saat ini, tantangan untuk mengelola big data di sebuah perusahaan adalah hal yang biasa, dan seperti yang dapat kita lihat, kita dapat menggunakan Apache Spark untuk mengatasinya dan memanfaatkan semua fitur yang telah disebutkan sebelumnya. Data besar adalah dunia yang sangat besar, sehingga Anda dapat memeriksa dokumentasi resmi untuk informasi lebih lanjut tentang penggunaan Apache Spark dan PostgreSQL dan menyesuaikannya dengan kebutuhan Anda.