Ini adalah bagian dari seri Operator Bermasalah Internal SQL Server. Untuk membaca postingan pertama, klik di sini.
SQL Server telah ada selama lebih dari 30 tahun, dan saya telah bekerja dengan SQL Server hampir selama itu. Saya telah melihat banyak perubahan selama bertahun-tahun (dan beberapa dekade!) Dan versi produk luar biasa ini. Dalam posting ini, saya akan berbagi dengan Anda bagaimana saya melihat beberapa fitur atau aspek SQL Server, terkadang bersama dengan sedikit perspektif historis.
Terakhir kali, saya berbicara tentang operasi pemindaian dalam rencana kueri SQL Server sebagai operator yang berpotensi bermasalah dalam diagnosis SQL Server. Meskipun pemindaian sering digunakan hanya karena tidak ada indeks yang berguna, ada kalanya pemindaian sebenarnya merupakan pilihan yang lebih baik daripada operasi pencarian indeks.
Dalam artikel ini, saya akan memberi tahu Anda tentang keluarga operator lain yang terkadang dianggap bermasalah:hashing. Hashing adalah algoritma pemrosesan data yang sangat terkenal yang telah ada selama beberapa dekade. Saya mempelajarinya di kelas struktur data saya ketika saya pertama kali belajar ilmu komputer di Universitas. Jika Anda menginginkan informasi latar belakang tentang fungsi hashing dan hash, Anda dapat melihat artikel ini di Wikipedia. Namun, SQL Server tidak menambahkan hashing ke daftar opsi pemrosesan kueri hingga SQL Server 7. (Sebagai tambahan, saya akan menyebutkan bahwa SQL Server memang menggunakan hashing di beberapa algoritme pencarian internalnya sendiri. Seperti yang disebutkan dalam artikel Wikipedia , hashing menggunakan fungsi khusus untuk memetakan data dari ukuran arbitrer ke data dengan ukuran tetap. SQL menggunakan hashing sebagai teknik pencarian untuk memetakan setiap halaman dari database ukuran arbitrer ke buffer di memori, yang merupakan ukuran tetap. Bahkan , dulu ada opsi untuk sp_configure disebut 'hash buckets', yang memungkinkan Anda mengontrol jumlah bucket yang digunakan untuk hashing halaman database ke buffer memori.)
Apa itu Hashing?
Hashing adalah teknik pencarian yang tidak memerlukan data untuk dipesan. SQL Server dapat menggunakannya untuk operasi GABUNG, operasi agregasi (DISTINCT atau GROUP BY) atau operasi UNION. Kesamaan dari ketiga operasi ini adalah selama eksekusi, mesin kueri mencari nilai yang cocok. Dalam JOIN, kami ingin menemukan baris dalam satu tabel (atau rowset) yang memiliki nilai yang cocok dengan baris di tabel lain. (Dan ya, saya mengetahui gabungan yang tidak membandingkan baris berdasarkan kesetaraan, tetapi non-ekuijoin tersebut tidak relevan untuk diskusi ini.) Untuk GROUP BY, kami menemukan nilai yang cocok untuk disertakan dalam grup yang sama, dan untuk UNION dan DISTINCT, kami mencari nilai yang cocok untuk mengecualikannya. (Ya, saya tahu UNION ALL adalah pengecualian.)
Sebelum SQL Server 7, satu-satunya cara operasi ini dapat menemukan nilai yang cocok dengan mudah adalah jika data diurutkan. Jadi, jika tidak ada indeks yang mempertahankan data dalam urutan terurut, rencana kueri akan menambahkan operasi SORT ke rencana. Hashing mengatur data Anda untuk pencarian yang efisien dengan meletakkan semua baris yang memiliki hasil yang sama dari fungsi hash internal ke dalam 'hash bucket' yang sama.
Untuk penjelasan lebih rinci tentang operasi JOIN hash SQL Server, termasuk diagram, lihat posting blog ini dari SQL Shack.
Setelah hashing menjadi pilihan, SQL Server tidak sepenuhnya mengabaikan kemungkinan pengurutan data sebelum bergabung atau agregasi, tetapi hanya menjadi kemungkinan untuk mempertimbangkan pengoptimal. Namun, secara umum, jika Anda mencoba menggabungkan, menggabungkan, atau melakukan UNION pada data yang tidak disortir, pengoptimal biasanya akan memilih operasi hash. Begitu banyak orang berasumsi bahwa HASH JOIN (atau operasi HASH lainnya) dalam sebuah rencana berarti Anda tidak memiliki indeks yang sesuai dan Anda harus membuat indeks yang sesuai untuk menghindari operasi hash.
Mari kita lihat sebuah contoh. Pertama-tama saya akan membuat dua tabel yang tidak diindeks.
USE AdventureWorks2016 GO DROP TABLE IF EXISTS Details;
GO
SELECT * INTO Details FROM Sales.SalesOrderDetail;
GO
DROP TABLE IF EXISTS Headers;
GO
SELECT * INTO Headers FROM Sales.SalesOrderHeader;
GO
Now, I’ll join these two tables together and filter the rows in the Details table:
SELECT *
FROM Details d JOIN Headers h
ON d.SalesOrderID = h.SalesOrderID
WHERE SalesOrderDetailID < 100;
Quest Spotlight Tuning Pack tampaknya tidak menunjukkan hash join sebagai masalah. Ini hanya menyoroti dua pemindaian tabel.

Saran merekomendasikan membangun indeks pada setiap tabel yang menyertakan setiap kolom non-kunci sebagai kolom TERMASUK. Saya jarang mengambil rekomendasi itu (seperti yang saya sebutkan di posting saya sebelumnya). Saya hanya akan membuat indeks di Detail tabel, pada kolom gabungan, dan tidak memiliki kolom yang disertakan.
CREATE INDEX Header_index on Headers(SalesOrderID);
Setelah indeks itu dibangun, HASH JOIN hilang. Indeks mengurutkan data di Header tabel dan memungkinkan SQL Server untuk menemukan baris yang cocok di tabel bagian dalam menggunakan urutan pengurutan indeks. Sekarang, bagian paling mahal dari paket tersebut adalah pemindaian di tabel luar (Rincian ) yang dapat dikurangi dengan membuat indeks pada SalesOrderID kolom dalam tabel itu. Saya akan meninggalkan itu sebagai latihan untuk pembaca.
Namun, rencana dengan HASH JOIN tidak selalu merupakan hal yang buruk. Operator alternatif (kecuali dalam kasus khusus) adalah NESTED LOOPS JOIN, dan itu biasanya pilihan ketika indeks yang baik hadir. Namun, operasi loop NESTED membutuhkan beberapa pencarian dari tabel bagian dalam. Pseudocode berikut menunjukkan algoritma nested loop join:
for each row R1 in the outer table
for each row R2 in the inner table
if R1 joins with R2
return (R1, R2)
Seperti namanya, NESTED LOOP JOIN dilakukan sebagai nested loop. Pencarian meja bagian dalam biasanya akan dilakukan beberapa kali, satu kali untuk setiap baris kualifikasi di meja bagian luar. Bahkan jika hanya ada beberapa persen dari baris yang memenuhi syarat, jika tabelnya sangat besar (mungkin ratusan juta, atau miliaran, atau baris) itu akan menjadi banyak baris untuk dibaca. Dalam sistem yang terikat I/O, jutaan atau miliaran pembacaan ini bisa menjadi hambatan nyata.
A HASH JOIN, di sisi lain, tidak melakukan banyak pembacaan dari kedua tabel. Ia membaca tabel luar sekali untuk membuat ember hash, dan kemudian membaca tabel dalam sekali, memeriksa ember hash untuk melihat apakah ada baris yang cocok. Kami memiliki batas atas satu pass melalui setiap tabel. Ya, ada sumber daya CPU yang diperlukan untuk menghitung fungsi hash dan mengelola konten bucket. Ada sumber daya memori yang dibutuhkan untuk menyimpan informasi hash. Namun, jika Anda memiliki sistem terikat I/O, Anda mungkin memiliki memori dan sumber daya CPU yang tersisa. HASH JOIN dapat menjadi pilihan yang masuk akal untuk pengoptimal dalam situasi ini di mana sumber daya I/O Anda terbatas dan Anda bergabung dengan tabel yang sangat besar.
Berikut adalah pseudocode untuk algoritma hash join:
for each row R1 in the build table
begin
calculate hash value on R1 join key(s)
insert R1 into the appropriate hash bucket
end
for each row R2 in the probe table
begin
calculate hash value on R2 join key(s)
for each row R1 in the corresponding hash bucket
if R1 joins with R2
output (R1, R2)
end
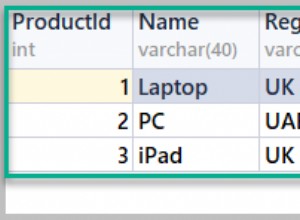
Seperti disebutkan sebelumnya, hashing juga dapat digunakan untuk operasi agregasi (serta UNION). Sekali lagi, jika ada indeks berguna yang sudah memiliki data yang diurutkan, pengelompokan data dapat dilakukan dengan sangat efisien. Namun, ada juga banyak situasi di mana hashing bukanlah operator yang buruk sama sekali. Pertimbangkan kueri seperti berikut, yang mengelompokkan data dalam Detail tabel (dibuat di atas) oleh ProductID kolom. Ada 121.317 baris dalam tabel dan hanya 266 ProductID different yang berbeda nilai.
SELECT ProductID, count(*)
FROM Details
GROUP BY ProductID;
GO
Menggunakan Operasi Hashing
Untuk menggunakan hashing, SQL Server hanya perlu membuat dan memelihara 266 ember, yang tidak banyak. Faktanya, Quest Spotlight Tuning Pack tidak menunjukkan bahwa ada masalah dengan kueri ini. 
Ya, itu harus melakukan pemindaian tabel, tetapi itu karena kami perlu memeriksa setiap baris dalam tabel, dan kami tahu bahwa pemindaian tidak selalu merupakan hal yang buruk. Indeks hanya akan membantu dengan pengurutan data sebelumnya, tetapi menggunakan agregasi hash untuk sejumlah kecil grup biasanya masih akan memberikan kinerja yang wajar bahkan tanpa indeks berguna yang tersedia.
Seperti pemindaian tabel, operasi hashing sering dianggap sebagai operator yang 'buruk' dalam sebuah rencana. Ada kasus di mana Anda dapat sangat meningkatkan kinerja dengan menambahkan indeks yang berguna untuk menghapus operasi hash, tetapi itu tidak selalu benar. Dan jika Anda mencoba membatasi jumlah indeks pada tabel yang sangat diperbarui, Anda harus menyadari bahwa operasi hash tidak selalu sesuatu yang harus 'diperbaiki', jadi membiarkan kueri menggunakan hash bisa menjadi hal yang masuk akal. melakukan. Selain itu, untuk kueri tertentu pada tabel besar yang berjalan pada sistem terikat I/O, hashing sebenarnya dapat memberikan kinerja yang lebih baik daripada algoritme alternatif karena terbatasnya jumlah pembacaan yang perlu dilakukan. Satu-satunya cara untuk mengetahui dengan pasti adalah dengan menguji berbagai kemungkinan di sistem Anda, dengan kueri dan data Anda.
Dalam posting berikut dalam seri ini, saya akan memberi tahu Anda tentang operator bermasalah lainnya yang mungkin muncul dalam rencana kueri Anda, jadi segera periksa kembali!