Salah satu aspek kunci ketersediaan tinggi adalah kemampuan untuk bereaksi cepat terhadap kegagalan. Tidak jarang mengelola database secara manual, dan memiliki perangkat lunak pemantauan yang mengawasi kesehatan database. Jika terjadi kegagalan, perangkat lunak pemantau mengirimkan peringatan kepada staf yang siap dipanggil. Ini berarti seseorang mungkin perlu bangun, masuk ke komputer dan masuk ke sistem dan melihat log - yaitu, ada beberapa waktu sebelum perbaikan dapat dimulai. Idealnya, seluruh proses harus otomatis.
Di blog ini, kita akan melihat cara menerapkan sistem yang sepenuhnya otomatis yang mendeteksi ketika database utama gagal, dan memulai prosedur failover dengan mempromosikan database sekunder. Kami akan menggunakan ClusterControl untuk melakukan failover otomatis dari database Moodle PostgreSQL.
Keuntungan dari Failover Otomatis
- Lebih sedikit waktu untuk memulihkan layanan basis data
- Waktu aktif sistem lebih tinggi
- Lebih sedikit ketergantungan pada DBA atau admin yang menyiapkan ketersediaan tinggi untuk database
Arsitektur
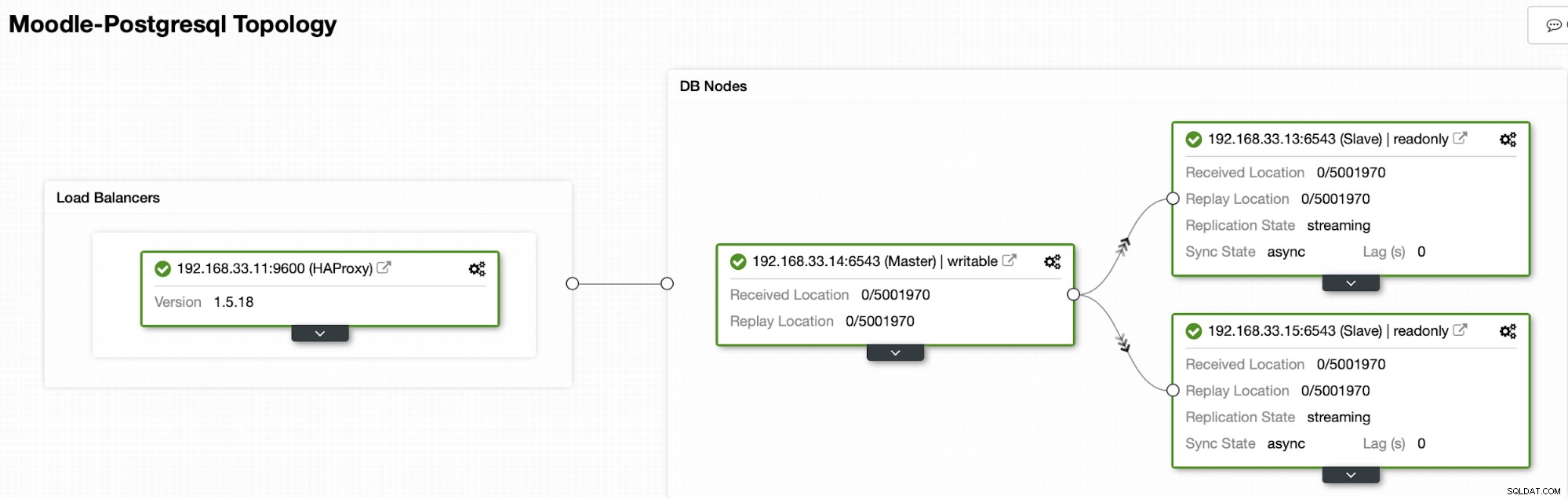
Saat ini kami memiliki satu server utama Postgres dan dua server sekunder di bawah HAProxy load balancer yang mengirimkan lalu lintas Moodle ke node PostgreSQL utama. Pemulihan cluster dan pemulihan otomatis node di ClusterControl adalah pengaturan penting untuk melakukan proses failover otomatis.

Mengontrol Server Yang Akan Di-Failover
ClusterControl menawarkan daftar putih dan daftar hitam sekumpulan server yang ingin Anda ikuti dalam failover, atau kecualikan sebagai kandidat.
Ada dua variabel yang dapat Anda atur dalam konfigurasi cmon,
- replication_failover_whitelist :berisi daftar IP atau nama host server sekunder yang harus digunakan sebagai calon utama potensial. Jika variabel ini disetel, hanya host tersebut yang akan dipertimbangkan.
- replication_failover_blacklist :berisi daftar host yang tidak akan pernah dianggap sebagai kandidat utama. Anda dapat menggunakannya untuk membuat daftar server sekunder yang digunakan untuk pencadangan atau kueri analitis. Jika perangkat keras bervariasi antar server sekunder, Anda mungkin ingin meletakkan di sini server yang menggunakan perangkat keras yang lebih lambat.
Proses Kegagalan Otomatis
Langkah 1
Kami telah memulai pemuatan data di server utama (192.168.33.14) menggunakan alat sysbench.
[example@sqldat.com sysbench]# /bin/sysbench --db-driver=pgsql --oltp-table-size=100000 --oltp-tables-count=24 --threads=2 --pgsql-host=****** --pgsql-port=6543 --pgsql-user=sbtest --pgsql-password=***** --pgsql-db=sbtest /usr/share/sysbench/tests/include/oltp_legacy/parallel_prepare.lua run
sysbench 1.0.20 (using bundled LuaJIT 2.1.0-beta2)
Running the test with following options:
Number of threads: 2
Initializing random number generator from current time
Initializing worker threads...
Threads started!
thread prepare0
Creating table 'sbtest1'...
Inserting 100000 records into 'sbtest1'
Creating secondary indexes on 'sbtest1'...
Creating table 'sbtest2'...
Langkah 2
Kami akan menghentikan server utama Postgres (192.168.33.14). Di ClusterControl, parameter (enable_cluster_autorecovery) diaktifkan sehingga akan mempromosikan primer yang sesuai berikutnya.
# service postgresql-12 stopLangkah 3
ClusterControl mendeteksi kegagalan di primer dan mempromosikan sekunder dengan data terkini sebagai primer baru. Ini juga berfungsi di server sekunder lainnya agar dapat direplikasi dari server utama baru.

Dalam kasus kami (192.168.33.13) adalah server utama baru dan server sekunder sekarang mereplikasi dari server utama baru ini. Sekarang HAProxy merutekan lalu lintas database dari server Moodle ke server utama terbaru.
Dari (192.168.33.13)
postgres=# select pg_is_in_recovery();
pg_is_in_recovery
-------------------
f
(1 row)Dari (192.168.33.15)
postgres=# select pg_is_in_recovery();
pg_is_in_recovery
-------------------
t
(1 row)
Topologi Saat Ini
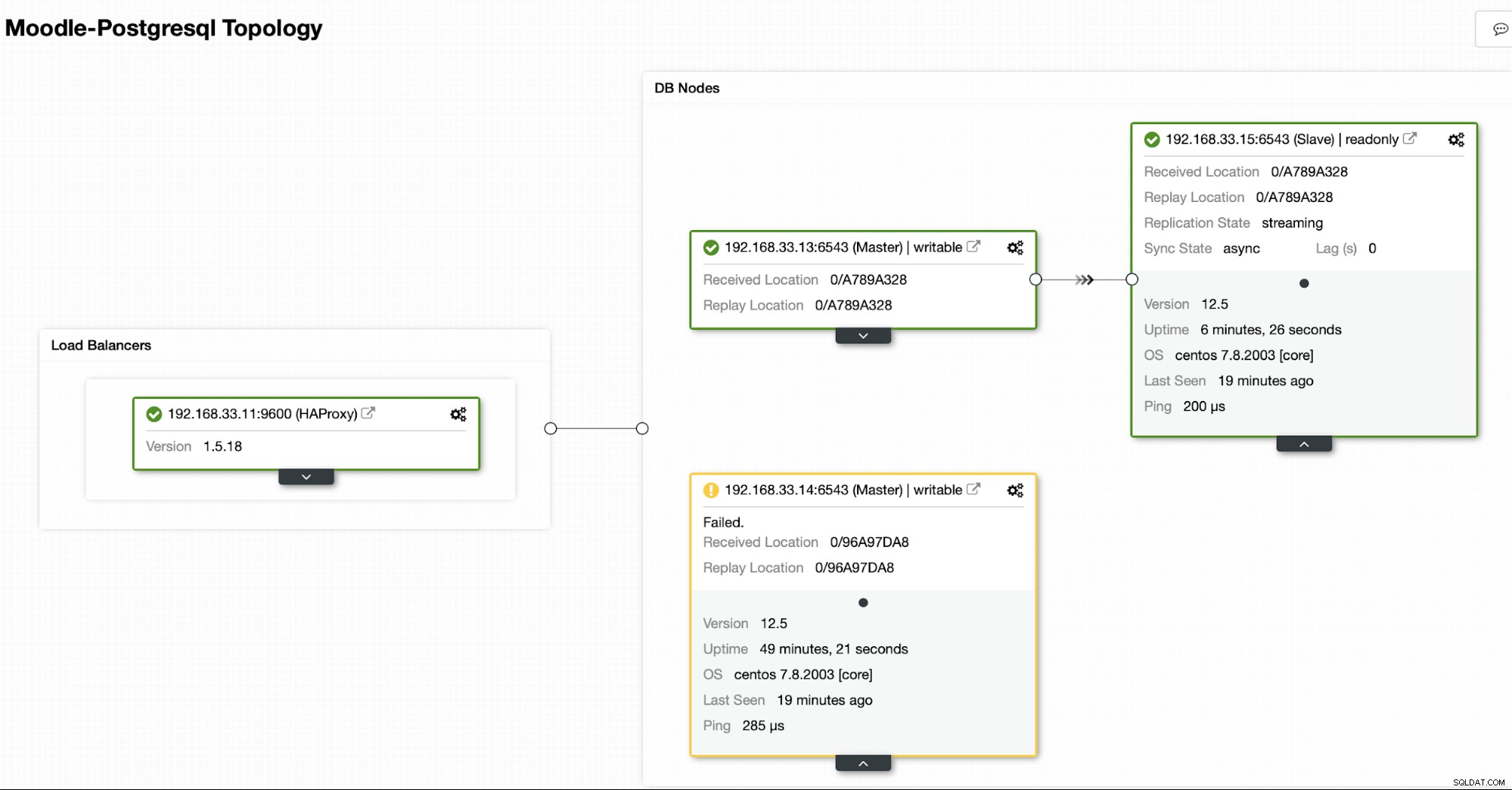
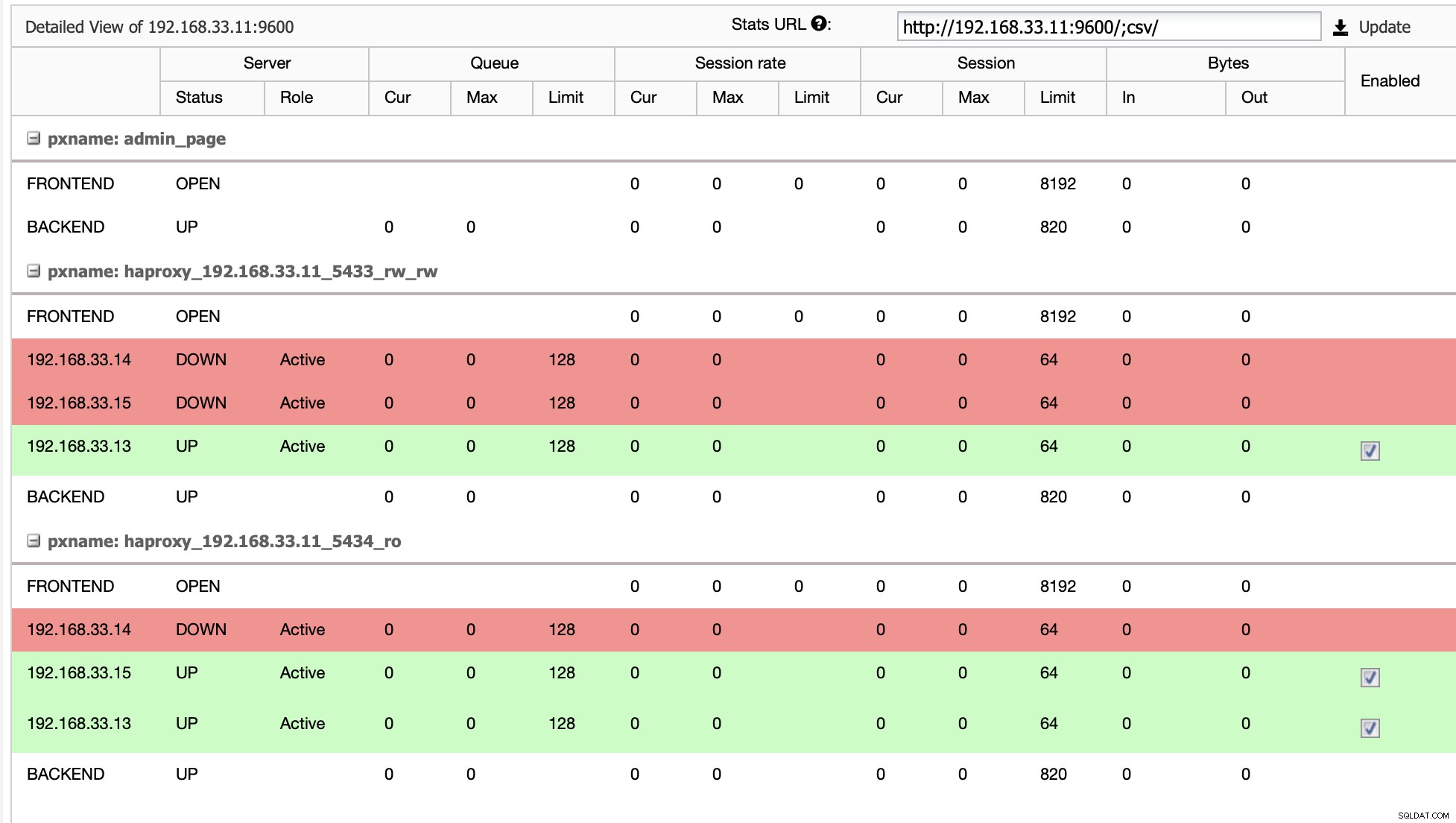
Ketika HAProxy mendeteksi bahwa salah satu node kita, baik primer atau replika, adalah tidak dapat diakses, secara otomatis menandainya sebagai offline. HAProxy tidak akan mengirimkan lalu lintas apa pun dari aplikasi Moodle ke sana. Pemeriksaan ini dilakukan oleh skrip health check yang dikonfigurasi oleh ClusterControl pada saat penerapan.
Setelah ClusterControl mempromosikan server replika ke server utama, HAProxy kami menandai server utama lama sebagai offline dan menempatkan node yang dipromosikan online.
Setelah server utama yang lama kembali online, server tersebut tidak akan secara otomatis disinkronkan ke server utama yang baru. Kita perlu membiarkannya kembali ke topologi, dan itu bisa dilakukan melalui antarmuka ClusterControl. Ini akan menghindari kemungkinan kehilangan atau inkonsistensi data, jika kami ingin menyelidiki mengapa server tersebut gagal.
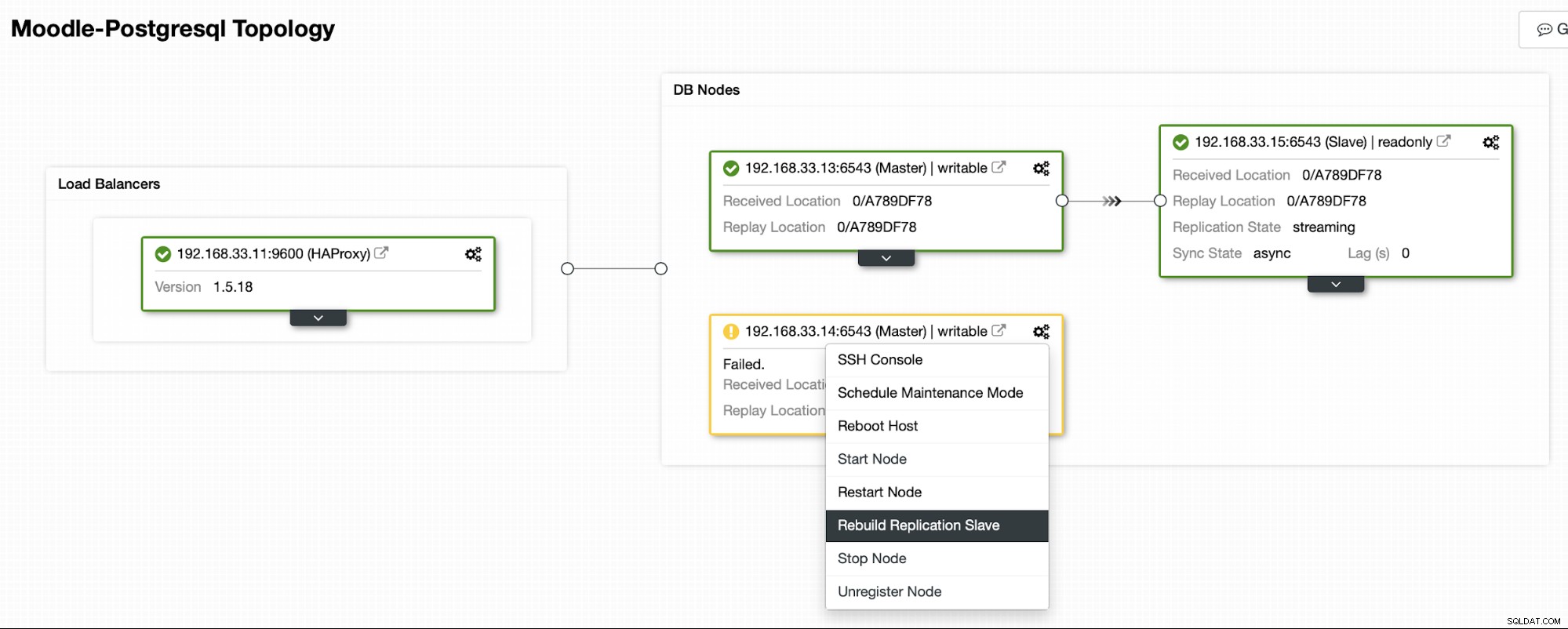
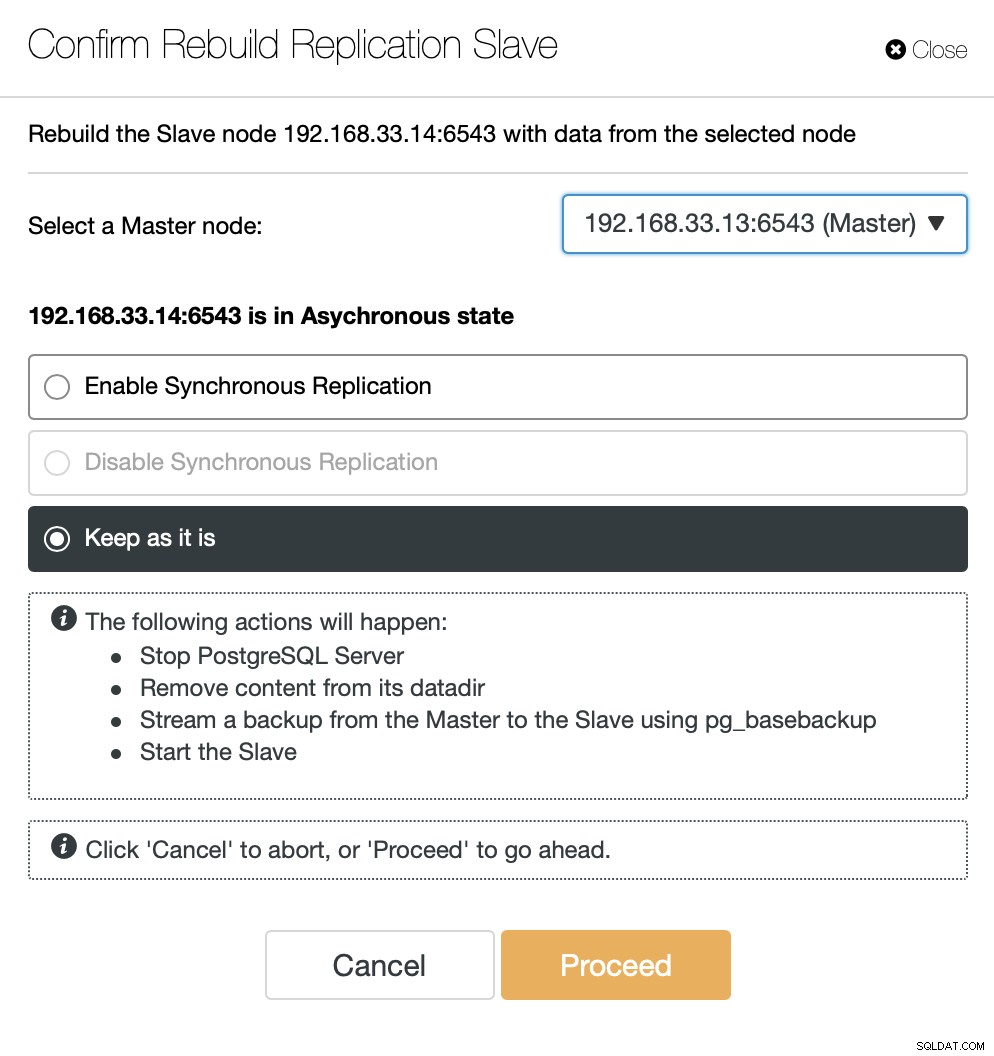
ClusterControl akan mengalirkan cadangan dari server utama baru dan mengonfigurasi replikasi.
Kesimpulan
Kegagalan otomatis adalah bagian penting dari basis data produksi Moodle. Ini dapat mengurangi waktu henti saat server mati, tetapi juga saat melakukan tugas pemeliharaan umum atau migrasi. Penting untuk melakukannya dengan benar, karena penting bagi perangkat lunak failover untuk mengambil keputusan yang tepat.