Apakah Anda masih berpegang pada desain induk/anak, atau ingin mencoba sesuatu yang baru, seperti SQL Server hierarkiID? Yah, ini benar-benar baru karena hierarkiID telah menjadi bagian dari SQL Server sejak 2008. Tentu saja, kebaruan itu sendiri bukanlah argumen yang meyakinkan. Namun perhatikan bahwa Microsoft menambahkan fitur ini untuk mewakili hubungan satu-ke-banyak dengan berbagai level dengan cara yang lebih baik.
Anda mungkin bertanya-tanya apa perbedaannya dan manfaat apa yang Anda dapatkan dari menggunakan hierarkiID alih-alih hubungan orang tua/anak yang biasa. Jika Anda belum pernah menjelajahi opsi ini, mungkin Anda akan terkejut.
Sebenarnya, saya tidak menjelajahi opsi ini sejak dirilis. Namun, ketika saya akhirnya melakukannya, saya menemukan inovasi yang hebat. Ini adalah kode yang terlihat lebih baik, tetapi memiliki lebih banyak di dalamnya. Dalam artikel ini, kita akan mencari tahu tentang semua peluang bagus itu.
Namun, sebelum kita menyelami kekhasan menggunakan SQL Server hierarkiID, mari kita perjelas makna dan cakupannya.
Apa itu SQL Server HierarchyID?
HirarkiID SQL Server adalah tipe data bawaan yang dirancang untuk mewakili pohon, yang merupakan tipe data hierarkis yang paling umum. Setiap item dalam pohon disebut node. Dalam format tabel, ini adalah baris dengan kolom tipe data hierarkiID.
Biasanya, kami mendemonstrasikan hierarki menggunakan desain tabel. Kolom ID mewakili simpul, dan kolom lain mewakili induk. Dengan SQL Server HierarchyID, kita hanya membutuhkan satu kolom dengan tipe data dari HierarchyID.
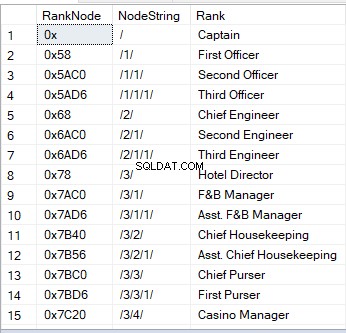
Saat Anda membuat kueri tabel dengan kolom hierarkiID, Anda melihat nilai heksadesimal. Ini adalah salah satu gambar visual dari sebuah node. Cara lain adalah string:
‘/’ adalah singkatan dari simpul akar;
‘/1/’, ‘/2/’, ‘/3/’ atau ‘/n/’ mewakili anak – keturunan langsung 1 hingga n;
'/1/1/' atau '/1/2/' adalah "anak-anak dari anak-anak - "cucu." String seperti '/1/2/' berarti bahwa anak pertama dari akar memiliki dua anak, yang pada gilirannya menjadi dua cucu dari akar.
Berikut ini contoh tampilannya:
Tidak seperti tipe data lainnya, kolom hierarkiID dapat memanfaatkan metode bawaan. Misalnya, jika Anda memiliki kolom hierarkiID bernama RankNode , Anda dapat memiliki sintaks berikut:
PeringkatNode.
Metode SQL Server HierarchyID
Salah satu metode yang tersedia adalah IsDescendantOf . Ini mengembalikan 1 jika node saat ini adalah turunan dari nilai hirarkiID.
Anda dapat menulis kode dengan metode ini mirip dengan yang di bawah ini:
SELECT
r.RankNode
,r.Rank
FROM dbo.Ranks r
WHERE r.RankNode.IsDescendantOf(0x58) = 1Metode lain yang digunakan dengan hierarkiID adalah sebagai berikut:
- GetRoot – metode statis yang mengembalikan akar pohon.
- GetDescendant – mengembalikan simpul anak dari induk.
- GetAncestor – mengembalikan hierarkiID yang mewakili leluhur ke-n dari simpul yang diberikan.
- GetLevel – mengembalikan bilangan bulat yang mewakili kedalaman node.
- ToString – mengembalikan string dengan representasi logis dari sebuah node. ToString dipanggil secara implisit ketika konversi dari hierarkiID ke tipe string terjadi.
- GetReparentedValue – memindahkan node dari induk lama ke induk baru.
- Parse – bertindak sebagai kebalikan dari ToString . Ini mengubah tampilan string dari hierarchyID nilai ke heksadesimal.
Strategi Pengindeksan SQL Server HierarchyID
Untuk memastikan bahwa kueri untuk tabel yang menggunakan hierarkiID berjalan secepat mungkin, Anda perlu mengindeks kolom. Ada dua strategi pengindeksan:
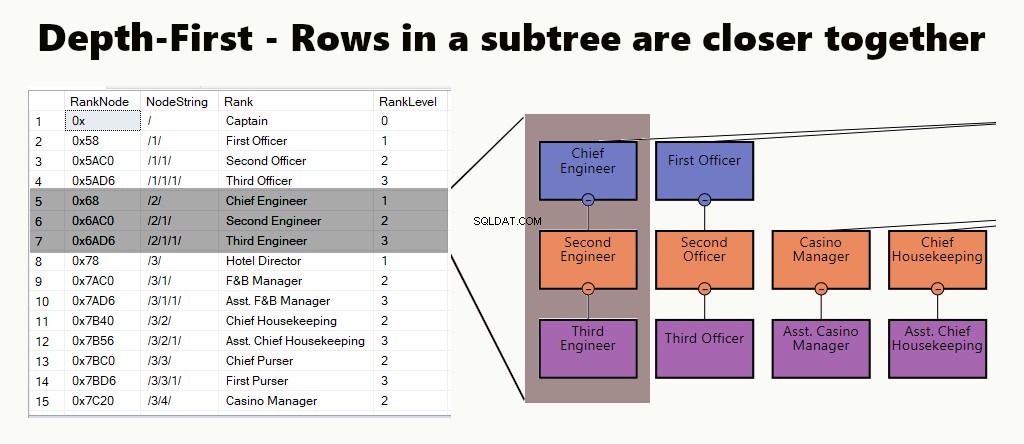
DEPTH-FIRST
Dalam indeks kedalaman-pertama, baris subpohon lebih dekat satu sama lain. Ini sesuai dengan pertanyaan seperti menemukan departemen, subunitnya, dan karyawannya. Contoh lain adalah manajer dan karyawannya disimpan lebih dekat.
Dalam sebuah tabel, Anda dapat menerapkan indeks kedalaman-pertama dengan membuat indeks berkerumun untuk node. Selanjutnya, kami melakukan salah satu contoh kami, begitu saja.
LUAS-PERTAMA
Dalam indeks luas-pertama, baris tingkat yang sama lebih dekat satu sama lain. Ini sesuai dengan pertanyaan seperti menemukan semua karyawan yang melapor langsung ke manajer. Jika sebagian besar kueri serupa dengan ini, buat indeks berkerumun berdasarkan (1) level dan (2) node.
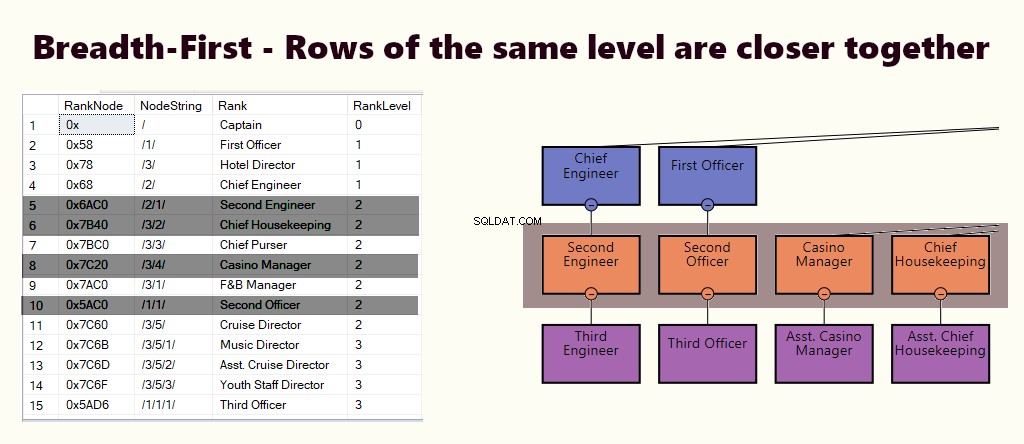
Itu tergantung pada kebutuhan Anda jika Anda memerlukan indeks kedalaman-pertama, luas-pertama, atau keduanya. Anda perlu menyeimbangkan antara pentingnya jenis kueri dan pernyataan DML yang Anda jalankan di tabel.
Keterbatasan HierarchyID SQL Server
Sayangnya, menggunakan hierarkiID tidak dapat menyelesaikan semua masalah:
- SQL Server tidak dapat menebak apa anak dari orang tua. Anda harus mendefinisikan pohon dalam tabel.
- Jika Anda tidak menggunakan batasan unik, nilai hierarkiID yang dihasilkan tidak akan unik. Penanganan masalah ini adalah tanggung jawab pengembang.
- Hubungan node induk dan anak tidak diterapkan seperti hubungan kunci asing. Oleh karena itu, sebelum menghapus sebuah simpul, buat kueri untuk turunan apa pun yang ada.
Memvisualisasikan Hirarki
Sebelum kita melanjutkan, pertimbangkan satu pertanyaan lagi. Melihat hasil yang ditetapkan dengan string simpul, apakah menurut Anda hierarki sulit divisualisasikan?
Bagi saya, itu adalah ya yang besar karena saya tidak semakin muda.
Untuk alasan ini, kita akan menggunakan Power BI dan Hierarchy Chart dari Akvelon bersama dengan tabel database kita. Mereka akan membantu menampilkan hierarki dalam bagan organisasi. Saya berharap itu akan membuat pekerjaan lebih mudah.
Sekarang, mari kita mulai berbisnis.
Penggunaan SQL Server HierarchyID
Anda dapat menggunakan HierarchyID dengan skenario bisnis berikut:
- Struktur organisasi
- Folder, subfolder, dan file
- Tugas dan subtugas dalam sebuah proyek
- Halaman dan subhalaman situs web
- Data geografis dengan negara, wilayah, dan kota
Meskipun skenario bisnis Anda mirip dengan yang di atas, dan Anda jarang melakukan kueri di seluruh bagian hierarki, Anda tidak memerlukan ID hierarki.
Misalnya, organisasi Anda memproses penggajian untuk karyawan. Apakah Anda perlu mengakses subpohon untuk memproses penggajian seseorang? Tidak semuanya. Namun, jika Anda memproses komisi orang dalam sistem multi-level marketing, itu bisa berbeda.
Pada postingan kali ini, kami menggunakan porsi struktur organisasi dan rantai komando di kapal pesiar. Strukturnya diadaptasi dari bagan organisasi dari sini. Perhatikan pada Gambar 4 di bawah ini:

Sekarang Anda dapat memvisualisasikan hierarki yang dimaksud. Kami menggunakan tabel di bawah ini di seluruh posting ini:
- Kapal – adalah tabel yang menunjukkan daftar kapal pesiar.
- Peringkat – adalah tabel peringkat kru. Di sana kami membuat hierarki menggunakan ID hierarki.
- Kru – adalah daftar awak setiap kapal dan jajarannya.
Struktur tabel setiap kasus adalah sebagai berikut:
CREATE TABLE [dbo].[Vessel](
[VesselId] [int] IDENTITY(1,1) NOT NULL,
[VesselName] [varchar](20) NOT NULL,
CONSTRAINT [PK_Vessel] PRIMARY KEY CLUSTERED
(
[VesselId] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
CREATE TABLE [dbo].[Ranks](
[RankId] [int] IDENTITY(1,1) NOT NULL,
[Rank] [varchar](50) NOT NULL,
[RankNode] [hierarchyid] NOT NULL,
[RankLevel] [smallint] NOT NULL,
[ParentRankId] [int] -- this is redundant but we will use this to compare
-- with parent/child
) ON [PRIMARY]
GO
CREATE UNIQUE NONCLUSTERED INDEX [IX_RankId] ON [dbo].[Ranks]
(
[RankId] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO
CREATE UNIQUE CLUSTERED INDEX [IX_RankNode] ON [dbo].[Ranks]
(
[RankNode] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO
CREATE TABLE [dbo].[Crew](
[CrewId] [int] IDENTITY(1,1) NOT NULL,
[CrewName] [varchar](50) NOT NULL,
[DateHired] [date] NOT NULL,
[RankId] [int] NOT NULL,
[VesselId] [int] NOT NULL,
CONSTRAINT [PK_Crew] PRIMARY KEY CLUSTERED
(
[CrewId] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
ALTER TABLE [dbo].[Crew] WITH CHECK ADD CONSTRAINT [FK_Crew_Ranks] FOREIGN KEY([RankId])
REFERENCES [dbo].[Ranks] ([RankId])
GO
ALTER TABLE [dbo].[Crew] CHECK CONSTRAINT [FK_Crew_Ranks]
GO
ALTER TABLE [dbo].[Crew] WITH CHECK ADD CONSTRAINT [FK_Crew_Vessel] FOREIGN KEY([VesselId])
REFERENCES [dbo].[Vessel] ([VesselId])
GO
ALTER TABLE [dbo].[Crew] CHECK CONSTRAINT [FK_Crew_Vessel]
GOMemasukkan Data Tabel dengan SQL Server HierarchyID
Tugas pertama dalam menggunakan hierarkiID secara menyeluruh adalah menambahkan catatan ke dalam tabel denganhirerarkiID kolom. Ada dua cara untuk melakukannya.
Menggunakan String
Cara tercepat untuk menyisipkan data dengan hierarkiID adalah dengan menggunakan string. Untuk melihat ini beraksi, mari tambahkan beberapa catatan ke Peringkat tabel.
INSERT INTO dbo.Ranks
([Rank], RankNode, RankLevel)
VALUES
('Captain', '/',0)
,('First Officer','/1/',1)
,('Chief Engineer','/2/',1)
,('Hotel Director','/3/',1)
,('Second Officer','/1/1/',2)
,('Second Engineer','/2/1/',2)
,('F&B Manager','/3/1/',2)
,('Chief Housekeeping','/3/2/',2)
,('Chief Purser','/3/3/',2)
,('Casino Manager','/3/4/',2)
,('Cruise Director','/3/5/',2)
,('Third Officer','/1/1/1/',3)
,('Third Engineer','/2/1/1/',3)
,('Asst. F&B Manager','/3/1/1/',3)
,('Asst. Chief Housekeeping','/3/2/1/',3)
,('First Purser','/3/3/1/',3)
,('Asst. Casino Manager','/3/4/1/',3)
,('Music Director','/3/5/1/',3)
,('Asst. Cruise Director','/3/5/2/',3)
,('Youth Staff Director','/3/5/3/',3)Kode di atas menambahkan 20 record ke tabel Ranks.
Seperti yang Anda lihat, struktur pohon telah didefinisikan di INSERT pernyataan di atas. Hal ini terlihat dengan mudah ketika kita menggunakan string. Selain itu, SQL Server mengonversinya ke nilai heksadesimal yang sesuai.
Menggunakan Max(), GetAncestor(), dan GetDescendant()
Menggunakan string sesuai dengan tugas mengisi data awal. Dalam jangka panjang, Anda memerlukan kode untuk menangani penyisipan tanpa memberikan string.
Untuk melakukan tugas ini, dapatkan simpul terakhir yang digunakan oleh orang tua atau leluhur. Kami melakukannya dengan menggunakan fungsi MAX() dan GetAncestor() . Lihat contoh kode di bawah ini:
-- add a bartender rank reporting to the Asst. F&B Manager
DECLARE @MaxNode HIERARCHYID
DECLARE @ImmediateSuperior HIERARCHYID = 0x7AD6
SELECT @MaxNode = MAX(RankNode) FROM dbo.Ranks r
WHERE r.RankNode.GetAncestor(1) = @ImmediateSuperior
INSERT INTO dbo.Ranks
([Rank], RankNode, RankLevel)
VALUES
('Bartender', @ImmediateSuperior.GetDescendant(@MaxNode,NULL),
@ImmediateSuperior.GetDescendant(@MaxNode, NULL).GetLevel())Berikut poin-poin yang diambil dari kode di atas:
- Pertama, Anda memerlukan variabel untuk simpul terakhir dan atasan langsung.
- Node terakhir dapat diperoleh menggunakan MAX() melawan RankNode untuk orang tua tertentu atau atasan langsung. Dalam kasus kami, ini adalah Asisten Manajer F&B dengan nilai node 0x7AD6.
- Selanjutnya, untuk memastikan tidak ada anak duplikat yang muncul, gunakan @ImmediateSuperior.GetDescendant(@MaxNode, NULL) . Nilai di @MaxNode adalah anak terakhir. Jika bukan NULL , GetDescendant() mengembalikan kemungkinan nilai simpul berikutnya.
- Terakhir, GetLevel() mengembalikan level dari simpul baru yang dibuat.
Meminta Data
Setelah menambahkan catatan ke tabel kami, saatnya untuk menanyakannya. Tersedia 2 cara untuk mengkueri data:
Kueri untuk Keturunan Langsung
Saat kita mencari karyawan yang langsung melapor ke manajer, kita perlu mengetahui dua hal:
- Nilai simpul dari pengelola atau induk
- Tingkat karyawan di bawah manajer
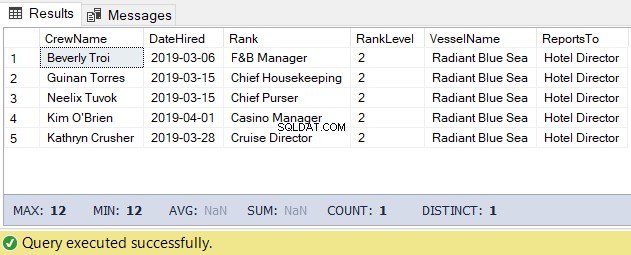
Untuk tugas ini, kita dapat menggunakan kode di bawah ini. Outputnya adalah daftar kru di bawah Direktur Hotel.
-- Get the list of crew directly reporting to the Hotel Director
DECLARE @Node HIERARCHYID = 0x78 -- the Hotel Director's node/hierarchyid
DECLARE @Level SMALLINT = @Node.GetLevel()
SELECT
a.CrewName
,a.DateHired
,b.Rank
,b.RankLevel
,c.VesselName
,(SELECT Rank FROM dbo.Ranks WHERE RankNode = b.RankNode.GetAncestor(1)) AS ReportsTo
FROM dbo.Crew a
INNER JOIN dbo.Ranks b ON a.RankId = b.RankId
INNER JOIN dbo.Vessel c ON a.VesselId = c.VesselId
WHERE b.RankNode.IsDescendantOf(@Node)=1
AND b.RankLevel = @Level + 1 -- add 1 for the level of the crew under the
-- Hotel DirectorHasil dari kode di atas adalah sebagai berikut pada Gambar 5:
Kueri untuk Subpohon
Terkadang, Anda juga perlu membuat daftar anak-anak dan anak-anak dari anak-anak hingga ke bawah. Untuk melakukan ini, Anda harus memiliki hierarkiID dari induknya.
Kueri akan mirip dengan kode sebelumnya tetapi tanpa perlu mendapatkan level. Lihat contoh kode:
-- Get the list of the crew under the Hotel Director down to the lowest level
DECLARE @Node HIERARCHYID = 0x78 -- the Hotel Director's node/hierarchyid
SELECT
a.CrewName
,a.DateHired
,b.Rank
,b.RankLevel
,c.VesselName
,(SELECT Rank FROM dbo.Ranks WHERE RankNode = b.RankNode.GetAncestor(1)) AS ReportsTo
FROM dbo.Crew a
INNER JOIN dbo.Ranks b ON a.RankId = b.RankId
INNER JOIN dbo.Vessel c ON a.VesselId = c.VesselId
WHERE b.RankNode.IsDescendantOf(@Node)=1Hasil dari kode di atas:
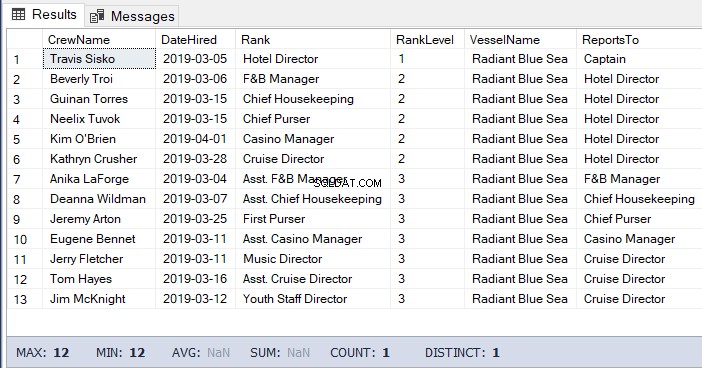
Memindahkan Node dengan SQL Server HierarchyID
Operasi standar lain dengan data hierarkis adalah memindahkan anak atau seluruh subpohon ke induk lain. Namun, sebelum kita melanjutkan, harap perhatikan satu masalah potensial:
Potensi Masalah
- Pertama, node yang bergerak melibatkan I/O. Seberapa sering Anda memindahkan node dapat menjadi faktor penentu jika Anda menggunakan hierarkiID atau induk/anak biasa.
- Kedua, memindahkan node dalam desain induk/anak akan memperbarui satu baris. Pada saat yang sama, ketika Anda memindahkan node dengan hierarkiID, itu memperbarui satu atau beberapa baris. Jumlah baris yang terpengaruh bergantung pada kedalaman level hierarki. Ini dapat berubah menjadi masalah kinerja yang signifikan.
Solusi
Anda dapat menangani masalah ini dengan desain database Anda.
Mari kita pertimbangkan desain yang kita gunakan di sini.
Alih-alih mendefinisikan hierarki pada Kru tabel, kami mendefinisikannya di Peringkat meja. Pendekatan ini berbeda dari Karyawan tabel di AdventureWorks database sampel, dan menawarkan keuntungan sebagai berikut:
- Anggota awak bergerak lebih sering daripada barisan di kapal. Desain ini akan mengurangi pergerakan node dalam hierarki. Hasilnya, meminimalkan masalah yang dijelaskan di atas.
- Mendefinisikan lebih dari satu hierarki dalam Kru meja lebih rumit, karena dua kapal membutuhkan dua kapten. Hasilnya adalah dua simpul akar.
- Jika Anda perlu menampilkan semua peringkat dengan anggota kru yang sesuai, Anda dapat menggunakan LEFT JOIN. Jika tidak ada yang menduduki peringkat tersebut, ini menunjukkan slot kosong untuk posisi tersebut.
Sekarang, mari kita beralih ke tujuan bagian ini. Tambahkan node anak di bawah orang tua yang salah.
Untuk memvisualisasikan apa yang akan kita lakukan, bayangkan hierarki seperti di bawah ini. Perhatikan simpul kuning.

Memindahkan Node Tanpa Anak
Memindahkan simpul anak memerlukan hal berikut:
- Tentukan ID hierarki dari simpul anak yang akan dipindahkan.
- Tentukan ID hierarki induk lama.
- Tentukan ID hierarki induk baru.
- Gunakan PERBARUI dengan GetReparentedValue() untuk memindahkan node secara fisik.
Mulailah dengan memindahkan simpul tanpa anak. Pada contoh di bawah, kami memindahkan Staf Kapal Pesiar dari bawah Direktur Pelayaran ke bawah Asst. Direktur Pelayaran.
-- Moving a node with no child node
DECLARE @NodeToMove HIERARCHYID
DECLARE @OldParent HIERARCHYID
DECLARE @NewParent HIERARCHYID
SELECT @NodeToMove = r.RankNode
FROM dbo.Ranks r
WHERE r.RankId = 24 -- the cruise staff
SELECT @OldParent = @NodeToMove.GetAncestor(1)
SELECT @NewParent = r.RankNode
FROM dbo.Ranks r
WHERE r.RankId = 19 -- the assistant cruise director
UPDATE dbo.Ranks
SET RankNode = @NodeToMove.GetReparentedValue(@OldParent,@NewParent)
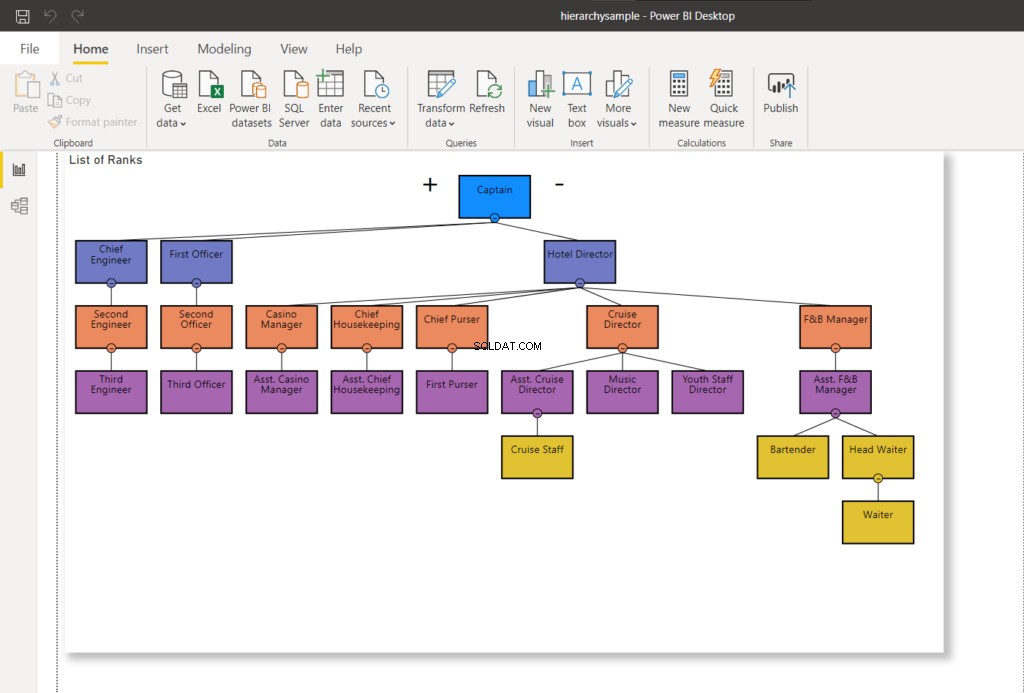
WHERE RankNode = @NodeToMoveSetelah node diperbarui, nilai hex baru akan digunakan untuk node. Menyegarkan koneksi Power BI saya ke SQL Server – ini akan mengubah bagan hierarki seperti yang ditunjukkan di bawah ini:
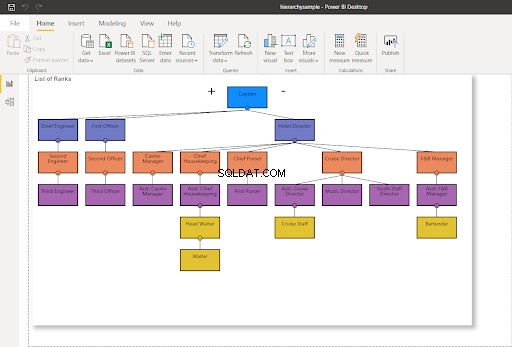
Pada Gambar 8, staf Kapal Pesiar tidak lagi melapor ke Direktur Pelayaran – berubah menjadi Asisten Direktur Pelayaran. Bandingkan dengan Gambar 7 di atas.
Sekarang, mari kita lanjutkan ke tahap berikutnya dan pindahkan Head Waiter ke Assistant F&B Manager.
Memindahkan Node dengan Anak-anak
Ada tantangan di bagian ini.
Masalahnya, kode sebelumnya tidak akan berfungsi dengan simpul bahkan dengan satu anak. Kami ingat bahwa memindahkan node memerlukan pembaruan satu atau lebih node turunan.
Selanjutnya, itu tidak berakhir di sana. Jika induk baru memiliki anak yang sudah ada, kami mungkin bertemu dengan nilai simpul duplikat.
Dalam contoh ini, kita harus menghadapi masalah itu:Asst. Manajer F&B memiliki simpul anak Bartender.
Siap? Ini kodenya:
-- Move a node with at least one child
DECLARE @NodeToMove HIERARCHYID
DECLARE @OldParent HIERARCHYID
DECLARE @NewParent HIERARCHYID
SELECT @NodeToMove = r.RankNode
FROM dbo.Ranks r
WHERE r.RankId = 22 -- the head waiter
SELECT @OldParent = @NodeToMove.GetAncestor(1) -- head waiter's old parent
--> asst chief housekeeping
SELECT @NewParent = r.RankNode
FROM dbo.Ranks r
WHERE r.RankId = 14 -- the assistant f&b manager
DECLARE children_cursor CURSOR FOR
SELECT RankNode FROM dbo.Ranks r
WHERE RankNode.GetAncestor(1) = @OldParent;
DECLARE @ChildId hierarchyid;
OPEN children_cursor
FETCH NEXT FROM children_cursor INTO @ChildId;
WHILE @@FETCH_STATUS = 0
BEGIN
START:
DECLARE @NewId hierarchyid;
SELECT @NewId = @NewParent.GetDescendant(MAX(RankNode), NULL)
FROM dbo.Ranks r WHERE RankNode.GetAncestor(1) = @NewParent; -- ensure
--to get a new id in case there's a
--sibling
UPDATE dbo.Ranks
SET RankNode = RankNode.GetReparentedValue(@ChildId, @NewId)
WHERE RankNode.IsDescendantOf(@ChildId) = 1;
IF @@error <> 0 GOTO START -- On error, retry
FETCH NEXT FROM children_cursor INTO @ChildId;
END
CLOSE children_cursor;
DEALLOCATE children_cursor;Dalam contoh kode di atas, iterasi dimulai sebagai kebutuhan untuk mentransfer node ke anak di tingkat terakhir.
Setelah Anda menjalankannya, Peringkat tabel akan diperbarui. Dan lagi, jika Anda ingin melihat perubahan secara visual, segarkan laporan Power BI. Anda akan melihat perubahan seperti di bawah ini:
Manfaat Menggunakan SQL Server HierarchyID vs. Parent/Child
Untuk meyakinkan siapa pun agar menggunakan suatu fitur, kita perlu mengetahui manfaatnya.
Jadi, di bagian ini, kita akan membandingkan pernyataan menggunakan tabel yang sama seperti yang ada di awal. Satu akan menggunakan hierarkiID, dan yang lainnya akan menggunakan pendekatan induk/anak. Hasil set akan sama untuk kedua pendekatan. Kami mengharapkannya untuk latihan ini seperti yang dari Gambar 6 di atas.
Sekarang setelah persyaratannya tepat, mari kita periksa manfaatnya secara menyeluruh.
Pengodean Lebih Sederhana
Lihat kode di bawah ini:
-- List down all the crew under the Hotel Director using hierarchyID
SELECT
a.CrewName
,a.DateHired
,b.Rank
,b.RankLevel
,c.VesselName
,d.RANK AS ReportsTo
FROM dbo.Crew a
INNER JOIN dbo.Vessel c ON a.VesselId = c.VesselId
INNER JOIN dbo.Ranks b ON a.RankId = b.RankId
INNER JOIN dbo.Ranks d ON d.RankNode = b.RankNode.GetAncestor(1)
WHERE a.VesselId = 1
AND b.RankNode.IsDescendantOf(0x78)=1Sampel ini hanya membutuhkan nilai hierarkiID. Anda dapat mengubah nilai sesuka hati tanpa mengubah kueri.
Sekarang, bandingkan pernyataan untuk pendekatan parent/child yang menghasilkan kumpulan hasil yang sama:
-- List down all the crew under the Hotel Director using parent/child
SELECT
a.CrewName
,a.DateHired
,b.Rank
,b.RankLevel
,c.VesselName
,d.Rank AS ReportsTo
FROM dbo.Crew a
INNER JOIN dbo.Vessel c ON a.VesselId = c.VesselId
INNER JOIN dbo.Ranks b ON a.RankId = b.RankId
INNER JOIN dbo.Ranks d ON b.RankParentId = d.RankId
WHERE a.VesselId = 1
AND (b.RankID = 4) OR (b.RankParentID = 4 OR b.RankParentId >= 7)Bagaimana menurutmu? Contoh kodenya hampir sama kecuali satu poin.
DI MANA klausa dalam kueri kedua tidak akan fleksibel untuk beradaptasi jika subpohon yang berbeda diperlukan.
Buat kueri kedua cukup umum, dan kodenya akan lebih panjang. Astaga!
Eksekusi Lebih Cepat
Menurut Microsoft, "kueri subpohon secara signifikan lebih cepat dengan hierarkiID" dibandingkan dengan induk/anak. Mari kita lihat apakah itu benar.
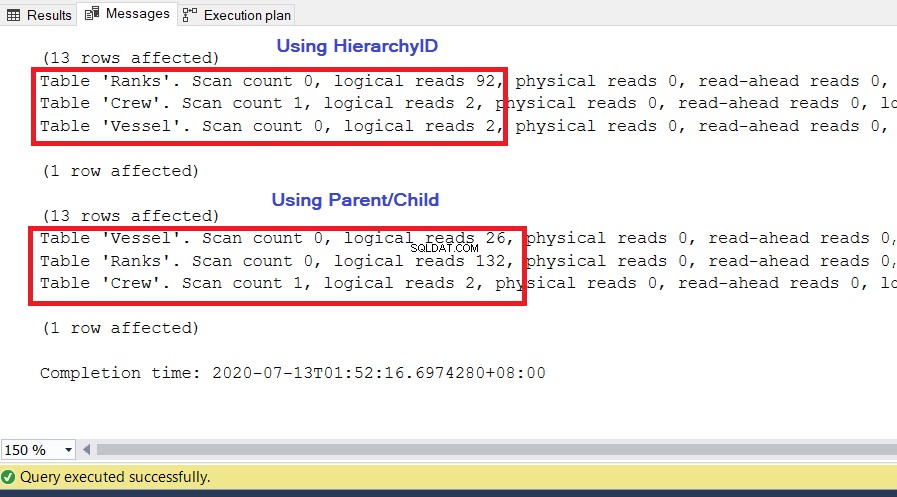
Kami menggunakan kueri yang sama seperti sebelumnya. Satu metrik penting yang digunakan untuk kinerja adalah pembacaan logis dari SET STATISTICS IO . Ini memberi tahu berapa banyak halaman 8KB yang dibutuhkan SQL Server untuk mendapatkan hasil yang kita inginkan. Semakin tinggi nilainya, semakin besar jumlah halaman yang diakses dan dibaca SQL Server, dan semakin lambat kueri berjalan. Jalankan SET STATISTICS IO ON dan jalankan kembali dua kueri di atas. Nilai pembacaan logis yang lebih rendah akan menjadi pemenangnya.
ANALISIS
Seperti yang Anda lihat pada Gambar 10, statistik I/O untuk kueri dengan hierarkiID memiliki pembacaan logis yang lebih rendah daripada rekan induk/anak mereka. Perhatikan poin-poin berikut dalam hasil ini:
- Kapal tabel adalah yang paling menonjol dari tiga tabel. Menggunakan hierarkiID hanya membutuhkan 2 * 8KB =16KB halaman untuk dibaca oleh SQL Server dari cache (memori). Sementara itu, menggunakan induk/anak membutuhkan 26 * 8KB =208KB halaman – jauh lebih tinggi daripada menggunakan hirarkiID.
- Peringkat tabel, yang mencakup definisi hierarki kami, membutuhkan 92 * 8KB =736KB. Di sisi lain, menggunakan induk/anak membutuhkan 132 * 8KB =1056KB.
- The Kru tabel membutuhkan 2 * 8KB =16KB, yang sama untuk kedua pendekatan.
Kilobyte halaman mungkin merupakan nilai yang kecil untuk saat ini, tetapi kami hanya memiliki beberapa catatan. Namun, ini memberi kami gambaran tentang bagaimana membebani kueri kami di server mana pun. Untuk meningkatkan kinerja, Anda dapat melakukan satu atau beberapa tindakan berikut:
- Tambahkan indeks yang sesuai
- Restrukturisasi kueri
- Perbarui statistik
Jika Anda melakukan hal di atas, dan pembacaan logis berkurang tanpa menambahkan lebih banyak catatan, kinerjanya akan meningkat. Selama Anda membuat pembacaan logis lebih rendah daripada yang menggunakan hierarkiID, itu akan menjadi kabar baik.
Tetapi mengapa merujuk pada pembacaan logis alih-alih waktu yang telah berlalu?
Memeriksa waktu yang telah berlalu untuk kedua kueri menggunakan SET STATISTICS TIME ON mengungkapkan sejumlah kecil perbedaan milidetik untuk kumpulan kecil data kami. Selain itu, server pengembangan Anda mungkin memiliki konfigurasi perangkat keras, pengaturan SQL Server, dan beban kerja yang berbeda. Waktu yang berlalu kurang dari satu milidetik dapat menipu Anda jika kinerja kueri Anda secepat yang Anda harapkan atau tidak.
MENGELAJAHI LEBIH LANJUT
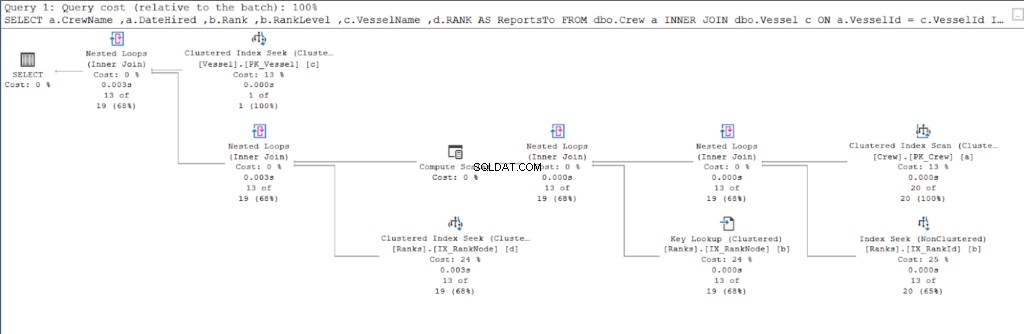
SET STATISTIK IO AKTIF tidak mengungkapkan hal-hal yang terjadi "di belakang layar." Di bagian ini, kami mencari tahu mengapa SQL Server datang dengan angka-angka itu dengan melihat rencana eksekusi.
Mari kita mulai dengan rencana eksekusi kueri pertama.
Sekarang, lihat rencana eksekusi kueri kedua.
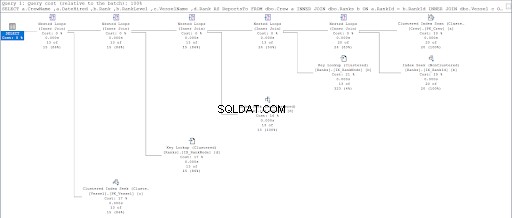
Membandingkan Gambar 11 dan 12, kita melihat bahwa SQL Server membutuhkan upaya tambahan untuk menghasilkan set hasil jika Anda menggunakan pendekatan induk/anak. DI MANA klausa bertanggung jawab atas komplikasi ini.
Namun, kesalahannya mungkin juga pada desain tabel. Kami menggunakan tabel yang sama untuk kedua pendekatan:Peringkat meja. Jadi, saya mencoba menduplikasi Peringkat tabel tetapi menggunakan indeks berkerumun berbeda yang sesuai untuk setiap prosedur.
Akibatnya, menggunakan hierarkiID masih memiliki pembacaan yang kurang logis dibandingkan dengan rekan induk/anak. Akhirnya, kami membuktikan bahwa Microsoft benar mengklaimnya.
Kesimpulan
Di sini momen aha sentral untuk hierarkiID adalah:
- HierarchyID adalah tipe data bawaan yang dirancang untuk representasi pohon yang lebih optimal, yang merupakan tipe data hierarkis yang paling umum.
- Setiap item dalam hierarki adalah simpul, dan nilai-nilai hierarkiID bisa dalam format heksadesimal atau string.
- HierarchyID berlaku untuk data struktur organisasi, tugas proyek, data geografis, dan sejenisnya.
- Ada metode untuk melintasi dan memanipulasi data hierarkis, seperti GetAncestor (), Dapatkan Keturunan (). Dapatkan Level (), GetReparentedValue (), dan banyak lagi.
- Cara konvensional untuk mengkueri data hierarkis adalah dengan mendapatkan turunan langsung dari sebuah simpul atau mendapatkan subpohon di bawah sebuah simpul.
- Penggunaan hierarkiID untuk membuat kueri subpohon tidak hanya lebih mudah dikodekan. Performanya juga lebih baik daripada orang tua/anak.
Desain orang tua/anak tidak buruk sama sekali, dan posting ini tidak untuk menguranginya. Namun, memperluas opsi dan memperkenalkan ide-ide baru selalu merupakan keuntungan besar bagi pengembang.
Anda dapat mencoba sendiri contoh yang kami tawarkan di sini. Terima efeknya dan lihat bagaimana Anda dapat menerapkannya untuk proyek berikutnya yang melibatkan hierarki.
Jika Anda menyukai postingan dan ide-idenya, Anda dapat menyebarkan berita dengan mengklik tombol berbagi untuk media sosial pilihan.