IGNORE_DUP_KEY opsi untuk indeks unik menentukan bagaimana SQL Server merespons upaya untuk INSERT nilai duplikat:Ini hanya berlaku untuk tabel (bukan tampilan) dan hanya untuk sisipan. Setiap bagian sisipan dari MERGE pernyataan mengabaikan IGNORE_DUP_KEY pengaturan indeks.
Ketika IGNORE_DUP_KEY adalah OFF , duplikat pertama yang ditemukan menghasilkan kesalahan , dan tidak ada baris baru yang disisipkan.
Ketika IGNORE_DUP_KEY adalah ON , baris yang disisipkan yang akan melanggar keunikan akan dibuang. Baris yang tersisa berhasil dimasukkan. Peringatan pesan dipancarkan alih-alih kesalahan:
Ringkasan Artikel
IGNORE_DUP_KEY opsi indeks dapat ditentukan untuk indeks unik berkerumun dan tidak berkerumun. Menggunakannya pada indeks berkerumun dapat menghasilkan kinerja yang jauh lebih buruk daripada untuk indeks unik nonclustered.
Besar kecilnya perbedaan performa bergantung pada seberapa banyak pelanggaran keunikan yang ditemui selama INSERT operasi. Semakin banyak pelanggaran, semakin buruk kinerja indeks unik berkerumun sebagai perbandingan. Jika tidak ada pelanggaran sama sekali, penyisipan indeks berkerumun bahkan dapat bekerja lebih baik.
Sisipkan indeks unik yang dikelompokkan
Untuk indeks unik berkerumun dengan IGNORE_DUP_KEY diatur, duplikat ditangani oleh mesin penyimpanan .
Banyak pekerjaan yang terlibat dalam menyisipkan setiap baris dilakukan sebelum duplikat terdeteksi. Misalnya, Sisipkan Indeks Berkelompok operator menavigasi ke bawah indeks b-tree berkerumun ke titik di mana baris baru akan pergi, mengambil kait halaman dan hierarki kunci biasa, sebelum menemukan kunci duplikat.
Saat kondisi kunci duplikat terdeteksi, kesalahan dibangkitkan. Alih-alih membatalkan eksekusi dan mengembalikan kesalahan ke klien, kesalahan ditangani secara internal. Baris bermasalah tidak dimasukkan, dan eksekusi berlanjut, mencari baris berikutnya untuk disisipkan. Jika baris tersebut menemukan kunci duplikat, kesalahan lain akan muncul dan ditangani, dan seterusnya.
Pengecualian sangat mahal untuk melempar dan menangkap. Sejumlah besar duplikat akan sangat memperlambat eksekusi.
Insert indeks unik nonclustered
Untuk indeks unik nonclustered dengan IGNORE_DUP_KEY ditetapkan, duplikat ditangani oleh pemroses kueri . Duplikat terdeteksi, dan peringatan dikeluarkan, sebelum setiap penyisipan dicoba.
Pemroses kueri menghapus duplikat dari aliran penyisipan, memastikan bahwa tidak ada duplikat yang terlihat oleh mesin penyimpanan. Akibatnya, tidak ada kesalahan pelanggaran kunci unik yang muncul atau ditangani secara internal.
Trade-off
Ada trade-off antara biaya mendeteksi dan menghapus kunci duplikat dalam rencana eksekusi, versus biaya melakukan pekerjaan terkait penyisipan yang signifikan, dan membuang dan menangkap kesalahan saat duplikat ditemukan.
Jika duplikat diperkirakan sangat jarang , solusi mesin penyimpanan (indeks berkerumun) mungkin lebih efisien. Ketika duplikat kurang jarang, pendekatan prosesor kueri kemungkinan akan membayar dividen. Titik persilangan yang tepat akan bergantung pada faktor-faktor seperti efisiensi waktu proses dari komponen rencana eksekusi yang digunakan untuk mendeteksi dan menghapus duplikat.
Bagian selanjutnya dari artikel ini memberikan demo dan melihat lebih detail mengapa pendekatan mesin penyimpanan dapat berkinerja sangat buruk.
Demo
Skrip berikut membuat tabel sementara dengan sejuta baris. Ini memiliki 1.000 nilai unik dan 1.000 baris untuk setiap nilai unik. Kumpulan data ini akan digunakan sebagai sumber data untuk disisipkan ke dalam tabel dengan konfigurasi indeks yang berbeda.
DROP TABLE IF EXISTS #Data;
GO
CREATE TABLE #Data (c1 integer NOT NULL);
GO
SET NOCOUNT ON;
SET STATISTICS XML OFF;
DECLARE
@Loop integer = 1,
@N integer = 1;
WHILE @N <= 1000
BEGIN
SET @Loop = 1;
BEGIN TRANSACTION;
-- Add 1,000 copies of the current loop value
WHILE @Loop <= 50
BEGIN
INSERT #Data
(c1)
VALUES
(@N), (@N), (@N), (@N), (@N),
(@N), (@N), (@N), (@N), (@N),
(@N), (@N), (@N), (@N), (@N),
(@N), (@N), (@N), (@N), (@N);
SET @Loop += 1;
END;
COMMIT TRANSACTION;
SET @N += 1;
END;
CREATE CLUSTERED INDEX cx
ON #Data (c1)
WITH (MAXDOP = 1); Dasar
Penyisipan berikut ke dalam variabel tabel dengan indeks berkerumun non-unik membutuhkan waktu sekitar 900 md :
DECLARE @T table
(
c1 integer NOT NULL
INDEX cuq CLUSTERED (c1)
);
INSERT @T
(c1)
SELECT
D.c1
FROM #Data AS D;
Perhatikan kurangnya IGNORE_DUP_KEY pada variabel tabel target.
Indeks unik yang dikelompokkan
Memasukkan data yang sama ke berkelompok yang unik indeks dengan IGNORE_DUP_KEY atur ON membutuhkan waktu sekitar 15.900 md — hampir 18 kali lebih buruk:
DECLARE @T table
(
c1 integer NOT NULL
UNIQUE CLUSTERED
WITH (IGNORE_DUP_KEY = ON)
);
INSERT @T
(c1)
SELECT
D.c1
FROM #Data AS D; Indeks unik nonclustered
Memasukkan data ke nonclustered unique yang unik indeks dengan IGNORE_DUP_KEY atur ON membutuhkan waktu sekitar 700 md :
DECLARE @T table
(
c1 integer NOT NULL
UNIQUE NONCLUSTERED
WITH (IGNORE_DUP_KEY = ON)
);
INSERT @T
(c1)
SELECT
D.c1
FROM #Data AS D; Ringkasan kinerja
Tes dasar membutuhkan waktu 900 md untuk menyisipkan semua satu juta baris. Pengujian indeks nonclustered membutuhkan waktu 700 md untuk memasukkan hanya 1.000 kunci yang berbeda. Pengujian indeks berkerumun membutuhkan waktu 15.900 md untuk menyisipkan 1.000 baris unik yang sama.
Pengujian ini sengaja dibuat untuk menyoroti kinerja buruk dari implementasi mesin penyimpanan, dengan menghasilkan 999 unit kerja yang terbuang (latches, locks, error handling) untuk setiap baris yang berhasil.
Pesan yang dimaksud bukanlah IGNORE_DUP_KEY akan selalu berkinerja buruk pada indeks berkerumun, hanya saja mungkin, dan mungkin ada perbedaan besar antara indeks berkerumun dan tidak berkerumun.
Rencana Eksekusi Indeks Tergugus
Tidak banyak yang bisa dilihat dalam rencana penyisipan indeks berkerumun:
Ada 1.000.000 baris yang diteruskan ke Sisipkan Indeks Berkelompok operator, yang ditampilkan sebagai 'mengembalikan' 1.000 baris. Menggali detail rencana, kita dapat melihat:
- 1.244.008 pembacaan logika pada operator penyisipan.
- Sebagian besar waktu eksekusi dihabiskan di Sisipkan operator.
- 11 md dari
SOS_SCHEDULER_YIELDmenunggu (yaitu tidak ada yang lain menunggu).
Tidak ada yang benar-benar menjelaskan 15.900 md waktu yang telah berlalu.
Mengapa performa sangat buruk
Jelas bahwa rencana ini harus melakukan banyak pekerjaan untuk setiap baris:
- Menavigasi tingkat indeks b-tree berkerumun, mengunci dan mengunci saat berjalan, untuk menemukan titik penyisipan untuk record baru.
- Jika salah satu halaman indeks yang diperlukan tidak ada dalam memori, halaman tersebut perlu diambil dari disk.
- Buat baris b-tree baru di memori.
- Siapkan catatan log.
- Jika duplikat kunci ditemukan (bukan catatan hantu), angkat kesalahan, tangani kesalahan itu secara internal, lepaskan baris saat ini, dan lanjutkan pada titik yang sesuai dalam kode untuk memproses baris kandidat berikutnya.
Itu semua cukup banyak pekerjaan, dan ingat itu semua terjadi untuk setiap baris .
Bagian yang ingin saya fokuskan adalah peningkatan dan penanganan kesalahan, karena ini sangat mahal. Aspek lainnya yang disebutkan di atas sudah dibuat semurah mungkin dengan menggunakan variabel tabel dan tabel sementara dalam demo.
Pengecualian
Hal pertama yang ingin saya lakukan adalah menunjukkan bahwa Sisipkan Indeks Berkelompok operator benar-benar memunculkan pengecualian ketika menemukan kunci duplikat.
Salah satu cara untuk menunjukkan ini secara langsung adalah dengan melampirkan debugger dan menangkap jejak tumpukan pada titik pengecualian dilemparkan:
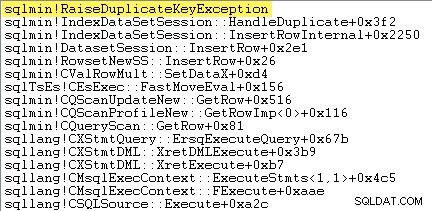
Poin penting di sini adalah melempar dan menangkap pengecualian sangat mahal.
Memantau SQL Server menggunakan Windows Performance Recorder saat pengujian berjalan, dan menganalisis hasilnya di Windows Performance Analyzer menunjukkan:
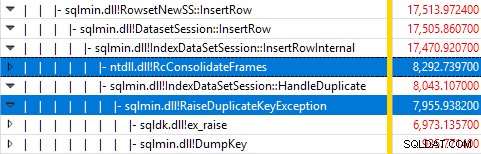
Hampir semua waktu eksekusi kueri dihabiskan di sqlmin!IndexDataSetSession::InsertRowInternal seperti yang diharapkan untuk kueri yang tidak melakukan banyak hal lain kecuali menyisipkan baris.
Kejutannya adalah bahwa 45% dari waktu tersebut dihabiskan untuk memunculkan pengecualian melalui sqlmin!RaiseDuplicateKeyException dan 47% lainnya dihabiskan di blok tangkap pengecualian terkait (ntdll!RcConsolidateFrames hierarki) .
Ringkasnya:Menaikkan dan menangkap pengecualian merupakan 92% dari waktu eksekusi dari kueri penyisipan indeks berkerumun pengujian kami.
Masalah pengumpulan data
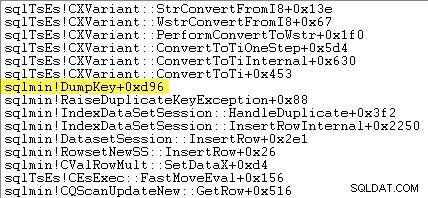
Pembaca yang jeli mungkin melihat jumlah yang signifikan – sekitar 12% – pengecualian meningkatkan waktu yang dihabiskan di sqlmin!DumpKey dalam grafik Windows Performance Analyzer. Ini perlu ditelusuri dengan cepat, bersama dengan beberapa item terkait.
Sebagai bagian dari memunculkan pengecualian, SQL Server harus mengumpulkan beberapa data yang hanya tersedia pada saat kesalahan terjadi. Nomor kesalahan yang terkait dengan pengecualian kunci duplikat adalah 2627. Teks pesan di sys.messages untuk nomor kesalahan itu adalah:
Informasi untuk mengisi penanda tempat itu perlu dikumpulkan pada saat kesalahan muncul — itu tidak akan tersedia nanti! Itu berarti mencari dan memformat jenis batasan, namanya, nama lengkap objek target, dan nilai kunci spesifik. Semua itu membutuhkan waktu.
Jejak tumpukan berikut menunjukkan server memformat nilai kunci duplikat sebagai string Unicode selama DumpKey hubungi:
Penanganan pengecualian juga melibatkan pengambilan jejak tumpukan:
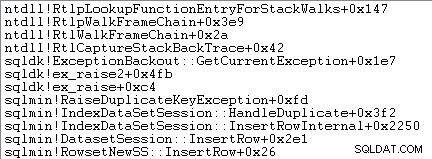
SQL Server juga merekam informasi tentang pengecualian (termasuk bingkai tumpukan) dalam buffer cincin kecil, seperti yang ditunjukkan berikut ini:
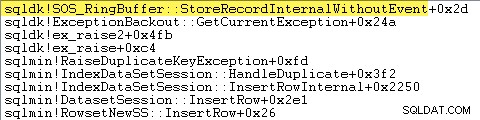
Anda dapat melihat entri buffer cincin tersebut menggunakan perintah seperti:
SELECT TOP (10)
date_time =
DATEADD
(
MILLISECOND,
DORB.[timestamp] - DOSI.ms_ticks,
SYSDATETIME()
),
record = CONVERT(xml, DORB.record)
FROM sys.dm_os_ring_buffers AS DORB
CROSS JOIN sys.dm_os_sys_info AS DOSI
WHERE
DORB.ring_buffer_type = N'RING_BUFFER_EXCEPTION'
ORDER BY
DORB.[timestamp] DESC; Contoh rekaman xml untuk pengecualian kunci duplikat berikut. Perhatikan bingkai tumpukan:
<Record id="4611442" type="RING_BUFFER_EXCEPTION" time="93079430">
<Exception>
<Task address="0x00000245B5E1FC28" />
<Error>2627</Error>
<Severity>14</Severity>
<State>1</State>
<UserDefined>0</UserDefined>
<Origin>0</Origin>
</Exception>
<Stack>
<frame id="0">0X00007FFAC659E80A</frame>
<frame id="1">0X00007FFACBAC0EFD</frame>
<frame id="2">0X00007FFACBAA1252</frame>
<frame id="3">0X00007FFACBA9E040</frame>
<frame id="4">0X00007FFACAB55D53</frame>
<frame id="5">0X00007FFACAB55C06</frame>
<frame id="6">0X00007FFACB3E3D0B</frame>
<frame id="7">0X00007FFAC92020EC</frame>
<frame id="8">0X00007FFACAB5B2FA</frame>
<frame id="9">0X00007FFACABA3B9B</frame>
<frame id="10">0X00007FFACAB3D89F</frame>
<frame id="11">0X00007FFAC6A9D108</frame>
<frame id="12">0X00007FFAC6AB2BBF</frame>
<frame id="13">0X00007FFAC6AB296F</frame>
<frame id="14">0X00007FFAC6A9B7D0</frame>
<frame id="15">0X00007FFAC6A9B233</frame>
</Stack>
</Record> Semua pekerjaan latar belakang ini terjadi untuk setiap pengecualian. Dalam pengujian kami, itu berarti terjadi 999.000 kali — sekali untuk setiap baris yang menemukan pelanggaran kunci duplikat.
Ada banyak cara untuk melihatnya, misalnya dengan menjalankan pelacakan Profiler menggunakan Pengecualian acara di Kesalahan dan Peringatan kelas. Dalam kasus pengujian kami, ini akan akhirnya menghasilkan 999.000 baris dengan TextData elemen seperti ini:
Pelanggaran batasan KUNCI UNIK 'UQ__#AC166DE__3213663B8B6E2E0E'Tidak dapat menyisipkan kunci duplikat di objek 'dbo.@T'.
Nilai kunci duplikat adalah (173).
Melampirkan Profiler berarti bahwa setiap kejadian penanganan pengecualian memperoleh banyak overhead tambahan, karena data tambahan yang dibutuhkan dikumpulkan dan diformat. Data default yang disebutkan sebelumnya selalu dikumpulkan, meskipun tidak ada yang secara aktif menggunakan informasi tersebut.
Untuk lebih jelasnya:Angka kinerja yang dilaporkan dalam artikel ini semuanya diperoleh tanpa debugger terpasang, dan tidak ada pemantauan lain yang aktif.
Rencana Eksekusi Indeks Nonclustered
Meskipun jauh lebih cepat, rencana penyisipan indeks nonclustered sedikit lebih rumit, jadi saya akan membaginya menjadi dua bagian.
Tema umumnya adalah bahwa rencana ini lebih cepat karena menghilangkan duplikat sebelum mencoba memasukkannya ke dalam tabel target.
Bagian 1
Pertama, sisi kanan dari rencana indeks nonclustered:
Bagian rencana ini menolak setiap baris yang memiliki kecocokan kunci di tabel target untuk indeks unik dengan IGNORE_DUP_KEY atur ON .
Anda mungkin mengharapkan untuk melihat Anti Semi Join di sini, tetapi SQL Server tidak memiliki infrastruktur yang diperlukan untuk mengeluarkan peringatan kunci duplikat yang diperlukan dengan Anti Semi Join operator. (Jika itu belum masuk akal, itu akan segera terjadi.)
Sebagai gantinya, kami mendapatkan paket dengan sejumlah fitur menarik:
- Pemindaian Indeks Berkelompok adalah
Ordered:Trueuntuk memberikan masukan ke Merge Left Semi Join diurutkan berdasarkan kolomc1di#Datameja. - Pemindaian Indeks dari variabel tabel adalah
Ordered:False - Urutkan mengurutkan baris demi kolom
c1dalam variabel tabel. Pesanan ini bisa saja disediakan oleh dipesan scan indeks variabel tabel padac1, tetapi pengoptimal memutuskan Urutkan adalah cara termurah untuk memberikan tingkat Perlindungan Halloween yang diperlukan. - Variabel tabel Pemindaian Indeks memiliki
UPDLOCKinternal internal danSERIALIZABLEpetunjuk diterapkan untuk memastikan stabilitas target selama eksekusi rencana. - The Merge Left Semi Join memeriksa kecocokan dalam variabel tabel untuk setiap nilai
c1dikembalikan dari#Datameja. Tidak seperti semi join biasa, ia memancarkan setiap baris yang diterima pada input atasnya. Ini menetapkan bendera di kolom penyelidikan untuk menunjukkan apakah baris saat ini menemukan kecocokan atau tidak. Kolom probe dipancarkan dari Merge Left Semi Join sebagai ekspresi bernamaExpr1012. - Pernyataan operator memeriksa nilai kolom probe
Expr1012. Saat pertama kali melihat baris dengan nilai kolom probe non-null (menunjukkan bahwa ditemukan kecocokan kunci indeks), ia mengeluarkan “Kunci duplikat diabaikan” pesan. - Pernyataan hanya melewati baris di mana kolom probe nol. Ini menghilangkan baris masuk yang akan menghasilkan kesalahan kunci duplikat.
Itu semua mungkin tampak rumit, tetapi pada dasarnya sesederhana menetapkan bendera jika kecocokan ditemukan, mengeluarkan peringatan saat pertama kali bendera ditetapkan, dan hanya meneruskan baris ke sisipan yang belum ada di tabel target .
Bagian 2
Bagian kedua dari rencana mengikuti Menegaskan operator:
Bagian rencana sebelumnya menghapus baris yang cocok dengan tabel target. Bagian rencana ini menghapus duplikat dalam set sisipan .
Misalnya, bayangkan tidak ada baris dalam tabel target di mana c1 = 1 . Kami mungkin masih menyebabkan kesalahan kunci duplikat jika kami mencoba menyisipkan dua baris dengan c1 = 1 dari tabel sumber. Kita perlu menghindarinya untuk menghormati semantik IGNORE_DUP_KEY = ON .
Aspek ini ditangani oleh Segmen dan Atas operator.
Segmen operator menetapkan tanda baru (berlabel Segment1015 ) ketika menemukan baris dengan nilai baru untuk c1 . Karena baris disajikan dalam c1 pesanan (terima kasih kepada Gabungkan yang mempertahankan pesanan ), paket dapat mengandalkan semua baris dengan c1 yang sama nilai tiba dalam aliran yang berdekatan.
Atas operator meneruskan satu baris untuk setiap grup duplikat, seperti yang ditunjukkan oleh Segmen bendera. Jika Atas operator menemukan lebih dari satu baris untuk Segmen yang sama grup (c1 nilai), itu memancarkan “Kunci duplikat diabaikan” peringatan, jika itu adalah pertama kalinya rencana mengalami kondisi itu.
Efek bersih dari semua ini adalah hanya satu baris yang diteruskan ke operator penyisipan untuk setiap nilai unik c1 , dan peringatan dibuat jika diperlukan.
Rencana eksekusi sekarang telah menghilangkan semua potensi pelanggaran kunci duplikat, jadi Sisipkan Tabel yang tersisa dan Indeks Sisipan operator dapat dengan aman menyisipkan baris ke heap dan indeks nonclustered tanpa takut kesalahan kunci duplikat.
Ingat bahwa UPDLOCK dan SERIALIZABLE petunjuk yang diterapkan ke tabel target memastikan bahwa set tidak dapat berubah selama eksekusi. Dengan kata lain, pernyataan bersamaan tidak dapat mengubah tabel target sehingga kesalahan kunci duplikat akan terjadi di Sisipkan operator. Itu bukan masalah di sini karena kami menggunakan variabel tabel pribadi, tetapi SQL Server masih menambahkan petunjuk sebagai ukuran keamanan umum.
Tanpa petunjuk tersebut, proses bersamaan dapat menambahkan baris ke tabel target yang akan menghasilkan pelanggaran kunci duplikat, meskipun pemeriksaan dilakukan oleh bagian 1 dari rencana. SQL Server perlu memastikan bahwa hasil pemeriksaan keberadaan tetap valid.
Pembaca yang penasaran dapat melihat beberapa fitur yang dijelaskan di atas dengan mengaktifkan tanda pelacakan 3604 dan 8607 untuk melihat pohon keluaran pengoptimal:
PhyOp_RestrRemap
PhyOp_StreamUpdate(INS TBL: @T, iid 0x2 as IDX, Sort(QCOL: .c1, )), {
- COL: Bmk10001013 = COL: Bmk1000
- COL: c11014 = QCOL: .c1}
PhyOp_StreamUpdate(INS TBL: @T, iid 0x0 as TBLInsLocator(COL: Bmk1000 ) REPORT-COUNT), {
- QCOL: .c1= QCOL: [D].c1}
PhyOp_GbTop Group(QCOL: [D].c1,) WARN-DUP
PhyOp_StreamCheck (WarnIgnoreDuplicate TABLE)
PhyOp_MergeJoin x_jtLeftSemi M-M, Probe COL: Expr1012 ( QCOL: [D].c1) = ( QCOL: .c1)
PhyOp_Range TBL: #Data(alias TBL: D)(1) ASC
PhyOp_Sort +s -d QCOL: .c1
PhyOp_Range TBL: @T(2) ASC Hints( UPDLOCK SERIALIZABLE FORCEDINDEX )
ScaOp_Comp x_cmpIs
ScaOp_Identifier QCOL: [D].c1
ScaOp_Identifier QCOL: .c1
ScaOp_Logical x_lopIsNotNull
ScaOp_Identifier COL: Expr1012
Pemikiran Terakhir
IGNORE_DUP_KEY opsi indeks bukanlah sesuatu yang akan sering digunakan kebanyakan orang. Namun, menarik untuk melihat bagaimana fungsi ini diterapkan, dan mengapa ada perbedaan kinerja yang besar antara IGNORE_DUP_KEY pada indeks berkerumun dan tidak berkerumun.
Dalam banyak kasus, itu akan membayar untuk mengikuti jejak prosesor kueri dan mencari untuk menulis kueri yang menghilangkan duplikat secara eksplisit, daripada mengandalkan IGNORE_DUP_KEY . Dalam contoh kita, itu berarti menulis:
DECLARE @T table
(
c1 integer NOT NULL
UNIQUE CLUSTERED -- no IGNORE_DUP_KEY!
);
INSERT @T
(c1)
SELECT DISTINCT -- Remove duplicates
D.c1
FROM #Data AS D; Ini dijalankan dalam waktu sekitar 400 md , sebagai catatan saja.