Saat melihat kinerja kueri, ada banyak sumber informasi hebat di dalam SQL Server, dan salah satu favorit saya adalah paket kueri itu sendiri. Dalam beberapa rilis terakhir, terutama dimulai dengan SQL Server 2012, setiap versi baru telah menyertakan lebih banyak detail dalam rencana eksekusi. Sementara daftar penyempurnaan terus bertambah, berikut adalah beberapa atribut yang menurut saya berharga:
- NonParallelPlanReason (SQL Server 2012)
- Diagnostik penekanan predikat sisa (SQL Server 2012 SP3, SQL Server 2014 SP2, SQL Server 2016 SP1)
- diagnostik tumpahan tempdb (SQL Server 2012 SP3, SQL Server 2014 SP2, SQL Server 2016)
- Trace Flags Diaktifkan (SQL Server 2012 SP4, SQL Server 2014 SP2, SQL Server 2016 SP1)
- Statistik Eksekusi Kueri Operator (SQL Server 2014 SP2, SQL Server 2016)
- Memori maksimum diaktifkan untuk satu kueri (SQL Server 2014 SP2, SQL Server 2016 SP1)
Untuk melihat apa yang ada untuk setiap versi SQL Server, kunjungi halaman Showplan Schema, di mana Anda dapat menemukan skema untuk setiap versi sejak SQL Server 2005.
Meskipun saya menyukai semua data tambahan ini, penting untuk dicatat bahwa beberapa informasi lebih relevan untuk rencana eksekusi yang sebenarnya, dibandingkan dengan perkiraan (misalnya informasi tumpahan tempdb). Beberapa hari kami dapat menangkap dan menggunakan rencana aktual untuk pemecahan masalah, di lain waktu kami harus menggunakan rencana perkiraan. Sangat sering kita mendapatkan perkiraan rencana – rencana yang telah digunakan untuk kemungkinan eksekusi bermasalah – dari cache rencana SQL Server. Dan menarik paket individual sesuai saat menyetel kueri atau kumpulan atau kueri tertentu. Namun, bagaimana jika Anda menginginkan ide tentang di mana harus memfokuskan upaya penyetelan Anda dalam hal pola?
Cache paket SQL Server adalah sumber informasi yang luar biasa dalam hal penyetelan kinerja, dan maksud saya bukan sekadar pemecahan masalah dan mencoba memahami apa yang telah berjalan dalam suatu sistem. Dalam hal ini, saya berbicara tentang menambang informasi dari paket itu sendiri, yang ditemukan di sys.dm_exec_query_plan, disimpan sebagai XML di kolom query_plan.
Saat Anda menggabungkan data ini dengan informasi dari sys.dm_exec_sql_text (sehingga Anda dapat dengan mudah melihat teks kueri) dan sys.dm_exec_query_stats (statistik eksekusi), Anda dapat tiba-tiba mulai mencari tidak hanya kueri yang merupakan hitter berat atau mengeksekusi paling sering, tetapi paket yang berisi jenis gabungan tertentu, atau pemindaian indeks, atau yang memiliki biaya tertinggi. Ini biasanya disebut sebagai menambang cache rencana, dan ada beberapa posting blog yang berbicara tentang cara melakukan ini. Rekan saya, Jonathan Kehayias, mengatakan bahwa dia tidak suka menulis XML namun dia memiliki beberapa postingan dengan pertanyaan untuk menambang cache paket:
- Menyesuaikan 'ambang biaya untuk paralelisme' dari Cache Rencana
- Menemukan Konversi Kolom Implisit di Cache Rencana
- Menemukan kueri apa dalam cache paket yang menggunakan indeks tertentu
- Menggali Cache Rencana SQL:Menemukan Indeks yang Hilang
- Menemukan Pencarian Kunci di dalam Cache Rencana
Jika Anda belum pernah menjelajahi apa yang ada di cache paket Anda, pertanyaan dalam posting ini adalah awal yang baik. Namun, cache paket memang memiliki keterbatasan. Misalnya, adalah mungkin untuk menjalankan kueri dan tidak memasukkan rencana ke dalam cache. Jika Anda telah mengaktifkan opsi optimalisasi beban kerja adhoc, misalnya, maka pada eksekusi pertama, rintisan paket yang dikompilasi disimpan dalam cache paket, bukan paket yang dikompilasi penuh. Tetapi tantangan terbesar adalah bahwa cache paket bersifat sementara. Ada banyak kejadian di SQL Server yang dapat menghapus cache paket seluruhnya atau menghapusnya untuk database, dan paket dapat kehabisan cache jika tidak digunakan, atau dihapus setelah kompilasi ulang. Untuk mengatasi hal ini, biasanya Anda harus menanyakan cache paket secara teratur, atau memotret konten ke tabel secara terjadwal.
Perubahan ini di SQL Server 2016 dengan Query Store.
Saat database pengguna mengaktifkan Penyimpanan Kueri, teks dan rencana kueri yang dijalankan terhadap database tersebut ditangkap dan disimpan dalam tabel internal. Daripada tampilan sementara dari apa yang sedang dijalankan, kami memiliki gambaran jangka panjang dari apa yang telah dieksekusi sebelumnya. Jumlah data yang disimpan ditentukan oleh setelan CLEANUP_POLICY, yang defaultnya adalah 30 hari. Dibandingkan dengan cache paket yang mungkin hanya mewakili beberapa jam eksekusi kueri, data Query Store adalah pengubah permainan.
Pertimbangkan skenario di mana Anda melakukan beberapa analisis indeks – Anda memiliki beberapa indeks yang tidak digunakan, dan Anda memiliki beberapa rekomendasi dari DMV indeks yang hilang. DMV indeks yang hilang tidak memberikan detail apa pun tentang kueri yang menghasilkan rekomendasi indeks yang hilang. Anda dapat menanyakan cache paket, menggunakan kueri dari posting Jonathan's Finding Missing Indexes. Jika saya menjalankannya terhadap instance SQL Server lokal saya, saya mendapatkan beberapa baris output yang terkait dengan beberapa kueri yang saya jalankan sebelumnya.

Saya dapat membuka paket di Plan Explorer, dan saya melihat ada peringatan di operator SELECT, yaitu untuk indeks yang hilang:
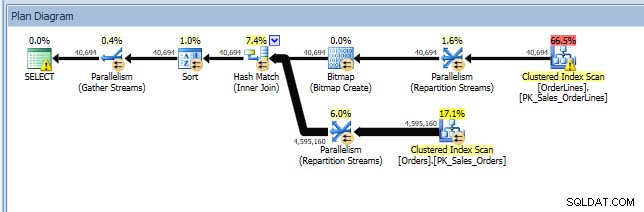
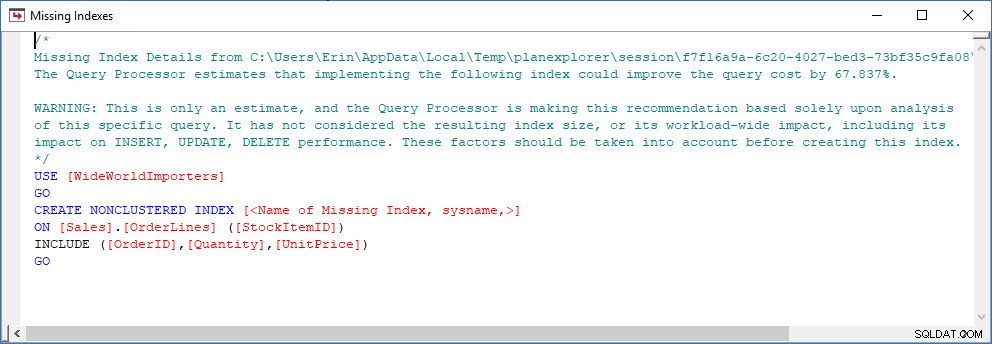
Ini adalah awal yang baik, tetapi sekali lagi, output saya bergantung pada apa pun yang ada di cache. Saya dapat mengambil kueri Jonathan dan memodifikasi untuk Query Store, lalu menjalankannya terhadap basis data demo WideWorldImporters saya:
USE WideWorldImporters;
GO
WITH XMLNAMESPACES
(DEFAULT 'https://schemas.microsoft.com/sqlserver/2004/07/showplan')
SELECT
query_plan,
n.value('(@StatementText)[1]', 'VARCHAR(4000)') AS sql_text,
n.value('(//MissingIndexGroup/@Impact)[1]', 'FLOAT') AS impact,
DB_ID(PARSENAME(n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)'),1)) AS database_id,
OBJECT_ID(n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Schema)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Table)[1]', 'VARCHAR(128)')) AS OBJECT_ID,
n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Schema)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Table)[1]', 'VARCHAR(128)')
AS object,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'EQUALITY'
FOR XML PATH('')
) AS equality_columns,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'INEQUALITY'
FOR XML PATH('')
) AS inequality_columns,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'INCLUDE'
FOR XML PATH('')
) AS include_columns
FROM (
SELECT query_plan
FROM
(
SELECT TRY_CONVERT(XML, [qsp].[query_plan]) AS [query_plan]
FROM sys.query_store_plan [qsp]) tp
WHERE tp.query_plan.exist('//MissingIndex')=1
) AS tab (query_plan)
CROSS APPLY query_plan.nodes('//StmtSimple') AS q(n)
WHERE n.exist('QueryPlan/MissingIndexes') = 1;
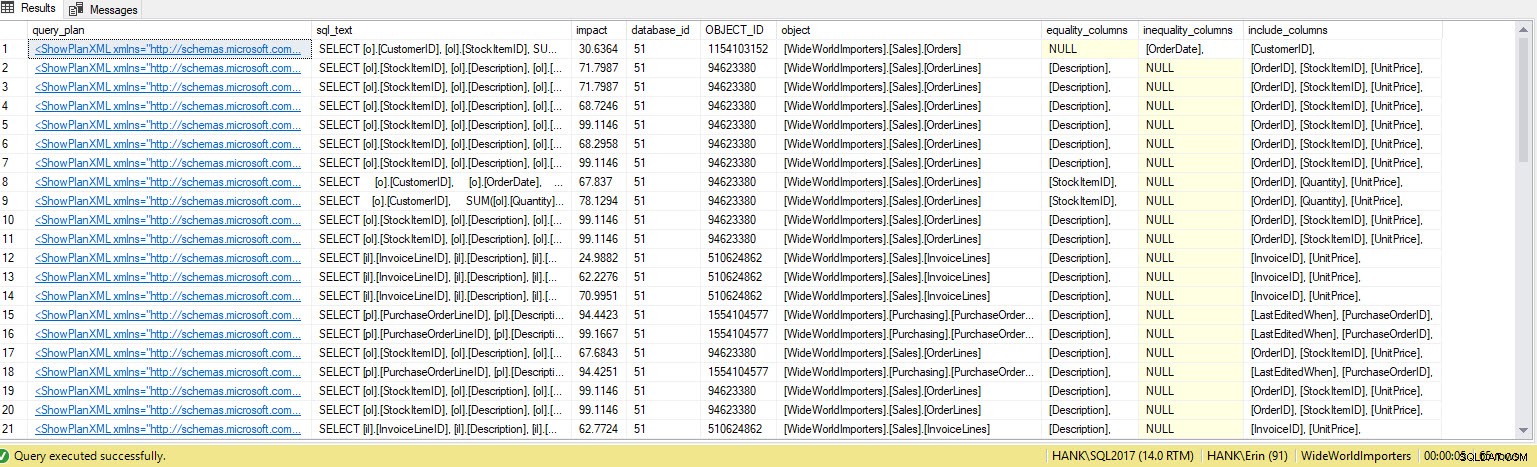
Saya mendapatkan lebih banyak baris di output. Sekali lagi, data Penyimpanan Kueri mewakili tampilan kueri yang lebih besar yang dijalankan terhadap sistem, dan menggunakan data ini memberi kami metode komprehensif untuk menentukan tidak hanya indeks apa yang hilang, tetapi kueri apa yang akan didukung oleh indeks tersebut. Dari sini, kita dapat menggali lebih dalam Penyimpanan Kueri dan melihat metrik kinerja dan frekuensi eksekusi untuk memahami dampak pembuatan indeks dan memutuskan apakah kueri dijalankan cukup sering untuk menjamin indeks.
Jika Anda tidak menggunakan Query Store, tetapi Anda menggunakan SentryOne, Anda dapat menambang informasi yang sama dari database SentryOne. Rencana kueri disimpan di tabel dbo.PerformanceAnalysisPlan dalam format terkompresi, jadi kueri yang kami gunakan adalah variasi yang mirip dengan yang di atas, tetapi Anda akan melihat fungsi DECOMPRESS juga digunakan:
USE SentryOne;
GO
WITH XMLNAMESPACES
(DEFAULT 'https://schemas.microsoft.com/sqlserver/2004/07/showplan')
SELECT
query_plan,
n.value('(@StatementText)[1]', 'VARCHAR(4000)') AS sql_text,
n.value('(//MissingIndexGroup/@Impact)[1]', 'FLOAT') AS impact,
DB_ID(PARSENAME(n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)'),1)) AS database_id,
OBJECT_ID(n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Schema)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Table)[1]', 'VARCHAR(128)')) AS OBJECT_ID,
n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Schema)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Table)[1]', 'VARCHAR(128)')
AS object,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'EQUALITY'
FOR XML PATH('')
) AS equality_columns,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'INEQUALITY'
FOR XML PATH('')
) AS inequality_columns,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'INCLUDE'
FOR XML PATH('')
) AS include_columns
FROM (
SELECT query_plan
FROM
(
SELECT -- need to decompress the gzipped xml here:
CONVERT(xml, CONVERT(nvarchar(max), CONVERT(varchar(max), DECOMPRESS(PlanTextGZ)))) AS [query_plan]
FROM dbo.PerformanceAnalysisPlan) tp
WHERE tp.query_plan.exist('//MissingIndex')=1
) AS tab (query_plan)
CROSS APPLY query_plan.nodes('//StmtSimple') AS q(n)
WHERE n.exist('QueryPlan/MissingIndexes') = 1; Pada satu sistem SentryOne saya memiliki output berikut (dan tentu saja mengklik salah satu nilai query_plan akan membuka paket grafis):

Beberapa keuntungan yang ditawarkan SentryOne dibandingkan Query Store adalah Anda tidak perlu mengaktifkan jenis koleksi ini per database, dan database yang dipantau tidak harus mendukung persyaratan penyimpanan, karena semua data disimpan dalam repositori. Anda juga dapat menangkap informasi ini di semua versi SQL Server yang didukung, bukan hanya versi yang mendukung Query Store. Perhatikan bahwa SentryOne hanya mengumpulkan kueri yang melebihi ambang batas seperti durasi dan pembacaan. Anda dapat mengubah ambang default ini, tetapi ini adalah satu item yang harus diperhatikan saat menambang database SentryOne:tidak semua kueri dapat dikumpulkan. Selain itu, fungsi DECOMPRESS tidak tersedia hingga SQL Server 2016; untuk versi SQL Server yang lebih lama, Anda mungkin ingin:
- Cadangkan database SentryOne dan pulihkan di SQL Server 2016 atau lebih tinggi untuk menjalankan kueri;
- bcp data keluar dari tabel dbo.PerformanceAnalysisPlan dan impor ke tabel baru pada contoh SQL Server 2016;
- meminta database SentryOne melalui server tertaut dari instans SQL Server 2016; atau,
- meminta database dari kode aplikasi yang dapat menguraikan hal-hal tertentu setelah dekompresi.
Dengan SentryOne, Anda memiliki kemampuan untuk menambang tidak hanya cache paket, tetapi juga data yang disimpan dalam repositori SentryOne. Jika Anda menjalankan SQL Server 2016 atau lebih tinggi, dan Anda telah mengaktifkan Query Store, Anda juga dapat menemukan informasi ini di sys.query_store_plan . Anda tidak terbatas hanya pada contoh menemukan indeks yang hilang ini; semua kueri dari pos cache rencana Jonathan lainnya dapat dimodifikasi untuk digunakan untuk menambang data dari SentryOne atau dari Query Store. Lebih lanjut, jika Anda cukup familiar dengan XQuery (atau ingin belajar), Anda dapat menggunakan Skema Showplan untuk mengetahui cara mengurai rencana untuk menemukan informasi yang Anda inginkan. Ini memberi Anda kemampuan untuk menemukan pola, dan anti-pola, dalam rencana kueri yang dapat diperbaiki oleh tim Anda sebelum menjadi masalah.