PERBARUI:2 September 2021 (Awalnya diterbitkan 26 Juli 2012.)
Banyak hal berubah selama beberapa versi utama dari platform database favorit kami. SQL Server 2016 menghadirkan STRING_SPLIT, fungsi asli yang menghilangkan kebutuhan akan banyak solusi khusus yang kami perlukan sebelumnya. Ini juga cepat, tetapi tidak sempurna. Misalnya, ini hanya mendukung pembatas satu karakter, dan tidak mengembalikan apa pun untuk menunjukkan urutan elemen input. Saya telah menulis beberapa artikel tentang fungsi ini (dan STRING_AGG, yang tiba di SQL Server 2017) sejak posting ini ditulis:
- Kejutan dan Asumsi Kinerja :STRING_SPLIT()
- STRING_SPLIT() di SQL Server 2016 :Tindak Lanjut #1
- STRING_SPLIT() di SQL Server 2016 :Tindak Lanjut #2
- Kode Penggantian String Split SQL Server dengan STRING_SPLIT
- Membandingkan metode pemisahan string/penggabungan
- Memecahkan masalah lama dengan fungsi STRING_AGG dan STRING_SPLIT baru SQL Server
- Berurusan dengan pembatas satu karakter di fungsi STRING_SPLIT SQL Server
- Tolong bantu dengan peningkatan STRING_SPLIT
- Cara meningkatkan STRING_SPLIT di SQL Server – dan Anda dapat membantu
Saya akan meninggalkan konten di bawah ini di sini untuk anak cucu dan relevansi historis, dan juga karena beberapa metodologi pengujian relevan dengan masalah lain selain dari pemisahan string, tetapi silakan lihat beberapa referensi di atas untuk informasi tentang bagaimana Anda harus membelah string dalam versi SQL Server modern yang didukung – serta posting ini, yang menjelaskan mengapa pemisahan string mungkin bukan masalah yang Anda inginkan untuk diselesaikan oleh database, fungsi baru atau tidak.
- Memisahkan String :Sekarang dengan lebih sedikit T-SQL
Saya tahu banyak orang bosan dengan masalah "string split", tetapi tampaknya masih muncul hampir setiap hari di forum dan situs Tanya Jawab seperti Stack Overflow. Ini adalah masalah di mana orang ingin mengirimkan string seperti ini:
EXEC dbo.UpdateProfile @UserID = 1, @FavoriteTeams = N'Patriots,Red Sox,Bruins';
Di dalam prosedur, mereka ingin melakukan sesuatu seperti ini:
INSERT dbo.UserTeams(UserID, TeamID) SELECT @UserID, TeamID
FROM dbo.Teams WHERE TeamName IN (@FavoriteTeams); Ini tidak berfungsi karena @FavoriteTeams adalah string tunggal, dan di atas diterjemahkan menjadi:
INSERT dbo.UserTeams(UserID, TeamID) SELECT @UserID, TeamID
FROM dbo.Teams WHERE TeamName IN (N'Patriots,Red Sox,Bruins'); Oleh karena itu SQL Server akan mencoba menemukan tim bernama Patriots,Red Sox,Bruins , dan saya rasa tidak ada tim seperti itu. Apa yang sebenarnya mereka inginkan di sini setara dengan:
INSERT dbo.UserTeams(UserID, TeamID) SELECT @UserID, TeamID
FROM dbo.Teams WHERE TeamName IN (N'Patriots', N'Red Sox', N'Bruins'); Tetapi karena tidak ada tipe array di SQL Server, ini bukanlah cara variabel diinterpretasikan sama sekali – ini masih berupa string tunggal sederhana yang kebetulan mengandung beberapa koma. Selain desain skema yang dipertanyakan, dalam hal ini daftar yang dipisahkan koma perlu "dibagi" menjadi nilai-nilai individual – dan ini adalah pertanyaan yang sering memicu banyak perdebatan dan komentar "baru" tentang solusi terbaik untuk mencapai hal itu.
Jawabannya tampaknya, hampir selalu, bahwa Anda harus menggunakan CLR. Jika Anda tidak dapat menggunakan CLR – dan saya tahu ada banyak dari Anda di luar sana yang tidak bisa, karena kebijakan perusahaan, bos berambut runcing, atau keras kepala – maka Anda menggunakan salah satu dari banyak solusi yang ada. Dan ada banyak solusi.
Tapi yang mana yang harus Anda gunakan?
Saya akan membandingkan kinerja beberapa solusi – dan fokus pada pertanyaan yang selalu ditanyakan semua orang:"Mana yang tercepat?" Saya tidak akan membahas lebih jauh tentang *semua* metode potensial, karena beberapa telah dihilangkan karena fakta bahwa mereka tidak berskala. Dan saya dapat mengunjunginya kembali di masa mendatang untuk memeriksa dampaknya pada metrik lainnya, tetapi untuk saat ini saya hanya akan fokus pada durasi. Berikut adalah pesaing yang akan saya bandingkan (menggunakan SQL Server 2012, 11.00.2316, pada Windows 7 VM dengan 4 CPU dan 8 GB RAM):
CLR
Jika Anda ingin menggunakan CLR, Anda harus meminjam kode dari sesama MVP Adam Machanic sebelum berpikir untuk menulis kode Anda sendiri (saya telah membuat blog sebelumnya tentang menemukan kembali roda, dan ini juga berlaku untuk potongan kode gratis seperti ini). Dia menghabiskan banyak waktu untuk menyempurnakan fungsi CLR ini untuk mengurai string secara efisien. Jika saat ini Anda menggunakan fungsi CLR dan ini bukan, saya sangat menyarankan Anda menerapkannya dan membandingkannya – saya mengujinya terhadap rutinitas CLR berbasis VB yang jauh lebih sederhana yang secara fungsional setara, tetapi pendekatan VB dilakukan sekitar tiga kali lebih buruk daripada Adam.
Jadi saya mengambil fungsi Adam, mengkompilasi kode ke DLL (menggunakan csc), dan hanya menyebarkan file itu ke server. Kemudian saya menambahkan Majelis dan fungsi berikut ke database saya:
CREATE ASSEMBLY CLRUtilities FROM 'c:\DLLs\CLRUtilities.dll' WITH PERMISSION_SET = SAFE; GO CREATE FUNCTION dbo.SplitStrings_CLR ( @List NVARCHAR(MAX), @Delimiter NVARCHAR(255) ) RETURNS TABLE ( Item NVARCHAR(4000) ) EXTERNAL NAME CLRUtilities.UserDefinedFunctions.SplitString_Multi; GO
XML
Ini adalah fungsi khas yang saya gunakan untuk skenario satu kali di mana saya tahu inputnya "aman", tetapi bukan yang saya rekomendasikan untuk lingkungan produksi (lebih lanjut tentang itu di bawah).
CREATE FUNCTION dbo.SplitStrings_XML
(
@List NVARCHAR(MAX),
@Delimiter NVARCHAR(255)
)
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN
(
SELECT Item = y.i.value('(./text())[1]', 'nvarchar(4000)')
FROM
(
SELECT x = CONVERT(XML, '<i>'
+ REPLACE(@List, @Delimiter, '</i><i>')
+ '</i>').query('.')
) AS a CROSS APPLY x.nodes('i') AS y(i)
);
GO Peringatan yang sangat kuat harus sejalan dengan pendekatan XML:ini hanya dapat digunakan jika Anda dapat menjamin bahwa string input Anda tidak mengandung karakter XML ilegal. Satu nama dengan <,> atau &dan fungsinya akan meledak. Jadi terlepas dari kinerjanya, jika Anda akan menggunakan pendekatan ini, perhatikan batasannya – ini tidak boleh dianggap sebagai opsi yang layak untuk pembagi string generik. Saya memasukkannya ke dalam ringkasan ini karena Anda mungkin memiliki kasus di mana Anda bisa mempercayai input – misalnya dimungkinkan untuk digunakan untuk daftar bilangan bulat atau GUID yang dipisahkan koma.
Tabel angka
Solusi ini menggunakan tabel Numbers, yang harus Anda buat dan isi sendiri. (Kami telah meminta versi bawaan sejak lama.) Tabel Numbers harus berisi baris yang cukup untuk melebihi panjang string terpanjang yang akan Anda pisahkan. Dalam hal ini kita akan menggunakan 1.000.000 baris:
SET NOCOUNT ON;
DECLARE @UpperLimit INT = 1000000;
WITH n AS
(
SELECT
x = ROW_NUMBER() OVER (ORDER BY s1.[object_id])
FROM sys.all_objects AS s1
CROSS JOIN sys.all_objects AS s2
CROSS JOIN sys.all_objects AS s3
)
SELECT Number = x
INTO dbo.Numbers
FROM n
WHERE x BETWEEN 1 AND @UpperLimit;
GO
CREATE UNIQUE CLUSTERED INDEX n ON dbo.Numbers(Number)
WITH (DATA_COMPRESSION = PAGE);
GO (Menggunakan kompresi data akan secara drastis mengurangi jumlah halaman yang diperlukan, tetapi jelas Anda hanya boleh menggunakan opsi ini jika Anda menjalankan Edisi Perusahaan. Dalam hal ini, data terkompresi membutuhkan 1.360 halaman, dibandingkan 2.102 halaman tanpa kompresi – penghematan sekitar 35%. )
CREATE FUNCTION dbo.SplitStrings_Numbers
(
@List NVARCHAR(MAX),
@Delimiter NVARCHAR(255)
)
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN
(
SELECT Item = SUBSTRING(@List, Number,
CHARINDEX(@Delimiter, @List + @Delimiter, Number) - Number)
FROM dbo.Numbers
WHERE Number <= CONVERT(INT, LEN(@List))
AND SUBSTRING(@Delimiter + @List, Number, LEN(@Delimiter)) = @Delimiter
);
GO
Ekspresi Tabel Umum
Solusi ini menggunakan CTE rekursif untuk mengekstrak setiap bagian dari string dari "sisa" dari bagian sebelumnya. Sebagai CTE rekursif dengan variabel lokal, Anda akan mencatat bahwa ini harus menjadi fungsi bernilai tabel multi-pernyataan, tidak seperti yang lain yang semuanya sebaris.
CREATE FUNCTION dbo.SplitStrings_CTE
(
@List NVARCHAR(MAX),
@Delimiter NVARCHAR(255)
)
RETURNS @Items TABLE (Item NVARCHAR(4000))
WITH SCHEMABINDING
AS
BEGIN
DECLARE @ll INT = LEN(@List) + 1, @ld INT = LEN(@Delimiter);
WITH a AS
(
SELECT
[start] = 1,
[end] = COALESCE(NULLIF(CHARINDEX(@Delimiter,
@List, 1), 0), @ll),
[value] = SUBSTRING(@List, 1,
COALESCE(NULLIF(CHARINDEX(@Delimiter,
@List, 1), 0), @ll) - 1)
UNION ALL
SELECT
[start] = CONVERT(INT, [end]) + @ld,
[end] = COALESCE(NULLIF(CHARINDEX(@Delimiter,
@List, [end] + @ld), 0), @ll),
[value] = SUBSTRING(@List, [end] + @ld,
COALESCE(NULLIF(CHARINDEX(@Delimiter,
@List, [end] + @ld), 0), @ll)-[end]-@ld)
FROM a
WHERE [end] < @ll ) INSERT @Items SELECT [value] FROM a WHERE LEN([value]) > 0
OPTION (MAXRECURSION 0);
RETURN;
END
GO
Pemisah Jeff Moden Sebuah fungsi berdasarkan splitter Jeff Moden dengan sedikit perubahan untuk mendukung string yang lebih panjang
Di SQLServerCentral, Jeff Moden menyajikan fungsi splitter yang menyaingi kinerja CLR, jadi saya pikir cukup adil untuk memasukkan variasi menggunakan pendekatan serupa dalam ringkasan ini. Saya harus membuat beberapa perubahan kecil pada fungsinya untuk menangani string terpanjang kami (500.000 karakter), dan juga membuat konvensi penamaan serupa:
CREATE FUNCTION dbo.SplitStrings_Moden
(
@List NVARCHAR(MAX),
@Delimiter NVARCHAR(255)
)
RETURNS TABLE
WITH SCHEMABINDING AS
RETURN
WITH E1(N) AS ( SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1),
E2(N) AS (SELECT 1 FROM E1 a, E1 b),
E4(N) AS (SELECT 1 FROM E2 a, E2 b),
E42(N) AS (SELECT 1 FROM E4 a, E2 b),
cteTally(N) AS (SELECT 0 UNION ALL SELECT TOP (DATALENGTH(ISNULL(@List,1)))
ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) FROM E42),
cteStart(N1) AS (SELECT t.N+1 FROM cteTally t
WHERE (SUBSTRING(@List,t.N,1) = @Delimiter OR t.N = 0))
SELECT Item = SUBSTRING(@List, s.N1, ISNULL(NULLIF(CHARINDEX(@Delimiter,@List,s.N1),0)-s.N1,8000))
FROM cteStart s; Selain itu, bagi mereka yang menggunakan solusi Jeff Moden, Anda dapat mempertimbangkan untuk menggunakan tabel Numbers seperti di atas, dan bereksperimen dengan sedikit variasi pada fungsi Jeff:
CREATE FUNCTION dbo.SplitStrings_Moden2
(
@List NVARCHAR(MAX),
@Delimiter NVARCHAR(255)
)
RETURNS TABLE
WITH SCHEMABINDING AS
RETURN
WITH cteTally(N) AS
(
SELECT TOP (DATALENGTH(ISNULL(@List,1))+1) Number-1
FROM dbo.Numbers ORDER BY Number
),
cteStart(N1) AS
(
SELECT t.N+1
FROM cteTally t
WHERE (SUBSTRING(@List,t.N,1) = @Delimiter OR t.N = 0)
)
SELECT Item = SUBSTRING(@List, s.N1,
ISNULL(NULLIF(CHARINDEX(@Delimiter, @List, s.N1), 0) - s.N1, 8000))
FROM cteStart AS s; (Ini akan menukar pembacaan yang sedikit lebih tinggi untuk CPU yang sedikit lebih rendah, jadi mungkin lebih baik tergantung pada apakah sistem Anda sudah terikat dengan CPU atau I/O.)
Pemeriksaan kewarasan
Untuk memastikan kami berada di jalur yang benar, kami dapat memverifikasi bahwa kelima fungsi mengembalikan hasil yang diharapkan:
DECLARE @s NVARCHAR(MAX) = N'Patriots,Red Sox,Bruins'; SELECT Item FROM dbo.SplitStrings_CLR (@s, N','); SELECT Item FROM dbo.SplitStrings_XML (@s, N','); SELECT Item FROM dbo.SplitStrings_Numbers (@s, N','); SELECT Item FROM dbo.SplitStrings_CTE (@s, N','); SELECT Item FROM dbo.SplitStrings_Moden (@s, N',');
Dan faktanya, inilah hasil yang kami lihat di kelima kasus…

Data Uji
Sekarang kita tahu fungsi berperilaku seperti yang diharapkan, kita bisa sampai ke bagian yang menyenangkan:menguji kinerja terhadap berbagai jumlah string yang bervariasi panjangnya. Tapi pertama-tama kita membutuhkan meja. Saya membuat objek sederhana berikut:
CREATE TABLE dbo.strings ( string_type TINYINT, string_value NVARCHAR(MAX) ); CREATE CLUSTERED INDEX st ON dbo.strings(string_type);
Saya mengisi tabel ini dengan sekumpulan string dengan panjang yang bervariasi, memastikan bahwa kumpulan data yang kira-kira sama akan digunakan untuk setiap pengujian – 10.000 baris pertama dengan panjang string 50 karakter, kemudian 1.000 baris dengan panjang string 500 karakter , 100 baris dengan panjang string 5.000 karakter, 10 baris dengan panjang string 50.000 karakter, dan seterusnya hingga 1 baris berisi 500.000 karakter. Saya melakukan ini untuk membandingkan jumlah keseluruhan data yang sama yang sedang diproses oleh fungsi, serta mencoba menjaga waktu pengujian saya agak dapat diprediksi.
Saya menggunakan tabel #temp sehingga saya cukup menggunakan GO
SET NOCOUNT ON; GO CREATE TABLE #x(s NVARCHAR(MAX)); INSERT #x SELECT N'a,id,xyz,abcd,abcde,sa,foo,bar,mort,splunge,bacon,'; GO INSERT dbo.strings SELECT 1, s FROM #x; GO 10000 INSERT dbo.strings SELECT 2, REPLICATE(s,10) FROM #x; GO 1000 INSERT dbo.strings SELECT 3, REPLICATE(s,100) FROM #x; GO 100 INSERT dbo.strings SELECT 4, REPLICATE(s,1000) FROM #x; GO 10 INSERT dbo.strings SELECT 5, REPLICATE(s,10000) FROM #x; GO DROP TABLE #x; GO -- then to clean up the trailing comma, since some approaches treat a trailing empty string as a valid element: UPDATE dbo.strings SET string_value = SUBSTRING(string_value, 1, LEN(string_value)-1) + 'x';
Membuat dan mengisi tabel ini membutuhkan waktu sekitar 20 detik di mesin saya, dan tabel tersebut mewakili data senilai sekitar 6 MB (sekitar 500.000 karakter kali 2 byte, atau 1 MB per string_type, ditambah baris dan indeks overhead). Bukan tabel yang besar, tetapi harus cukup besar untuk menyoroti perbedaan kinerja antar fungsi.
Ujian
Dengan fungsi di tempat, dan tabel diisi dengan benar dengan string besar untuk dikunyah, kami akhirnya dapat menjalankan beberapa tes aktual untuk melihat bagaimana kinerja berbagai fungsi terhadap data nyata. Untuk mengukur kinerja tanpa memperhitungkan overhead jaringan, saya menggunakan SQL Sentry Plan Explorer, menjalankan setiap rangkaian pengujian 10 kali, mengumpulkan metrik durasi, dan membuat rata-rata.
Tes pertama cukup menarik item dari setiap string sebagai satu set:
DBCC DROPCLEANBUFFERS; DBCC FREEPROCCACHE; DECLARE @string_type TINYINT = ; -- 1-5 from above SELECT t.Item FROM dbo.strings AS s CROSS APPLY dbo.SplitStrings_(s.string_value, ',') AS t WHERE s.string_type = @string_type;
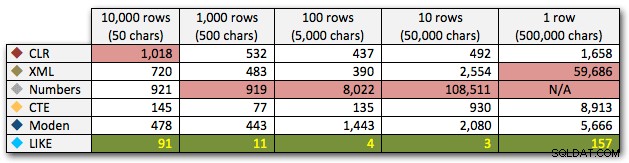
Hasilnya menunjukkan bahwa semakin besar senar, keunggulan CLR semakin bersinar. Di ujung bawah, hasilnya beragam, tetapi sekali lagi metode XML harus memiliki tanda bintang di sebelahnya, karena penggunaannya bergantung pada mengandalkan input aman-XML. Untuk kasus penggunaan khusus ini, tabel Numbers secara konsisten melakukan yang terburuk:
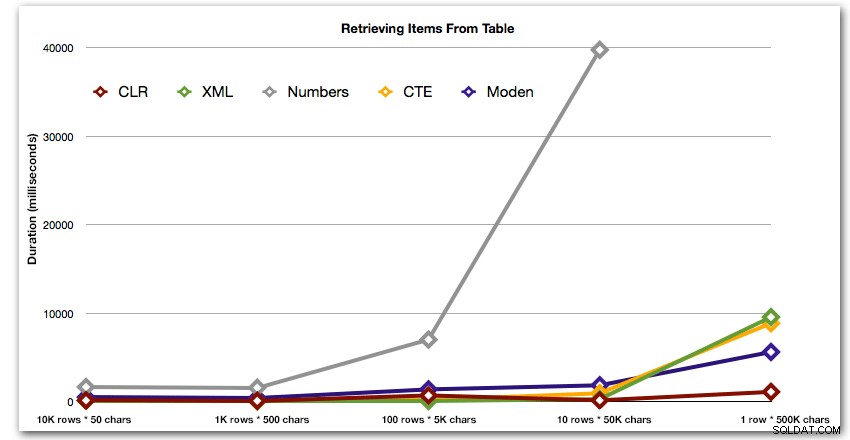
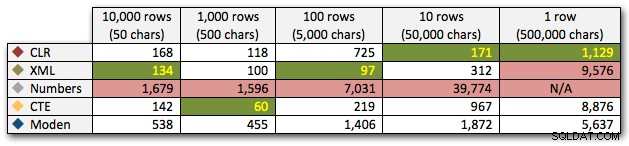
Durasi, dalam milidetik
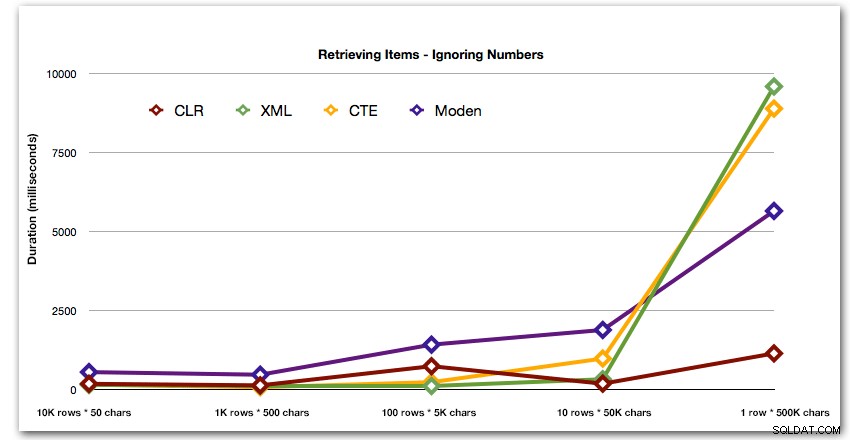
Setelah penampilan hiperbolik 40 detik untuk tabel angka melawan 10 baris 50.000 karakter, saya membatalkannya dari menjalankan untuk tes terakhir. Untuk menunjukkan kinerja relatif dari empat metode terbaik dalam pengujian ini dengan lebih baik, saya telah menghapus semua hasil Numbers dari grafik:
Selanjutnya, mari kita bandingkan saat kita melakukan pencarian terhadap nilai yang dipisahkan koma (misalnya mengembalikan baris di mana salah satu string adalah 'foo'). Sekali lagi kita akan menggunakan lima fungsi di atas, tetapi kita juga akan membandingkan hasilnya dengan pencarian yang dilakukan saat runtime menggunakan LIKE alih-alih repot dengan pemisahan.
DBCC DROPCLEANBUFFERS;
DBCC FREEPROCCACHE;
DECLARE @i INT = , @search NVARCHAR(32) = N'foo';
;WITH s(st, sv) AS
(
SELECT string_type, string_value
FROM dbo.strings AS s
WHERE string_type = @i
)
SELECT s.string_type, s.string_value FROM s
CROSS APPLY dbo.SplitStrings_(s.sv, ',') AS t
WHERE t.Item = @search;
SELECT s.string_type
FROM dbo.strings
WHERE string_type = @i
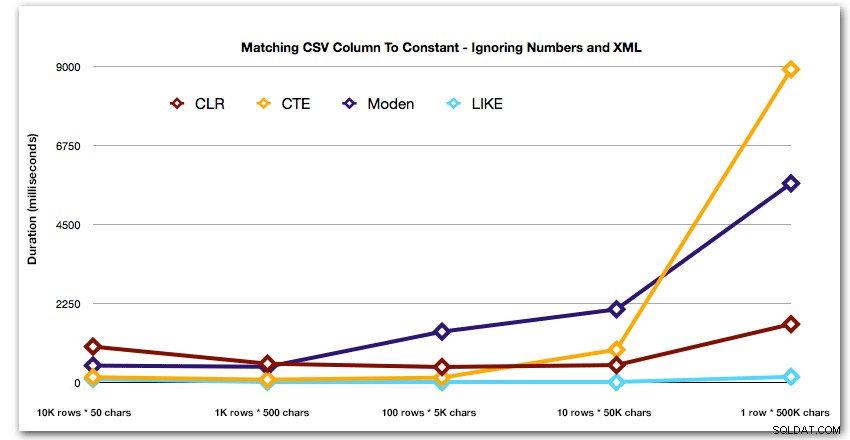
AND ',' + string_value + ',' LIKE '%,' + @search + ',%'; Hasil ini menunjukkan bahwa, untuk string kecil, CLR sebenarnya yang paling lambat, dan solusi terbaik adalah melakukan pemindaian menggunakan LIKE, tanpa repot-repot membagi data sama sekali. Sekali lagi saya menjatuhkan solusi tabel Numbers dari pendekatan ke-5, ketika jelas bahwa durasinya akan meningkat secara eksponensial saat ukuran string naik:
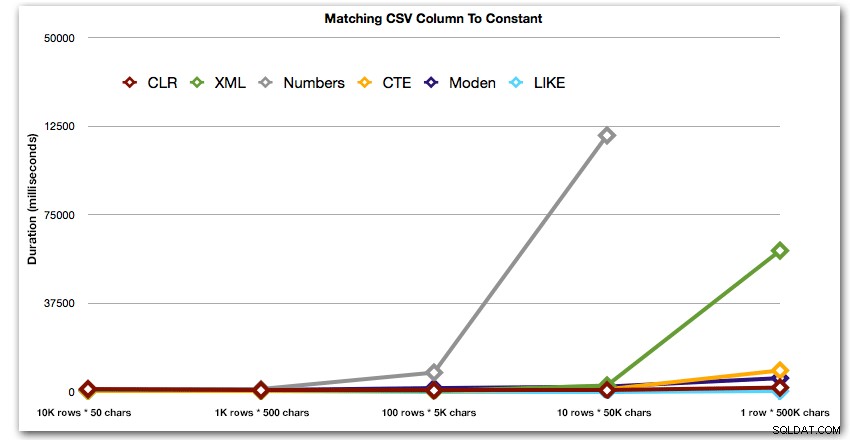
Durasi, dalam milidetik
Dan untuk mendemonstrasikan pola untuk 4 hasil teratas dengan lebih baik, saya telah menghilangkan solusi Numbers dan XML dari grafik:
Selanjutnya, mari kita lihat mereplikasi use case dari awal posting ini, di mana kita mencoba untuk menemukan semua baris dalam satu tabel yang ada dalam daftar yang dilewati. Seperti halnya data pada tabel yang kita buat di atas, kita 'akan membuat string dengan panjang bervariasi dari 50 hingga 500.000 karakter, menyimpannya dalam variabel, lalu memeriksa tampilan katalog umum untuk mengetahui apakah ada dalam daftar.
DECLARE
@i INT = , -- value 1-5, yielding strings 50 - 500,000 characters
@x NVARCHAR(MAX) = N'a,id,xyz,abcd,abcde,sa,foo,bar,mort,splunge,bacon,';
SET @x = REPLICATE(@x, POWER(10, @i-1));
SET @x = SUBSTRING(@x, 1, LEN(@x)-1) + 'x';
SELECT c.[object_id]
FROM sys.all_columns AS c
WHERE EXISTS
(
SELECT 1 FROM dbo.SplitStrings_(@x, N',') AS x
WHERE Item = c.name
)
ORDER BY c.[object_id];
SELECT [object_id]
FROM sys.all_columns
WHERE N',' + @x + ',' LIKE N'%,' + name + ',%'
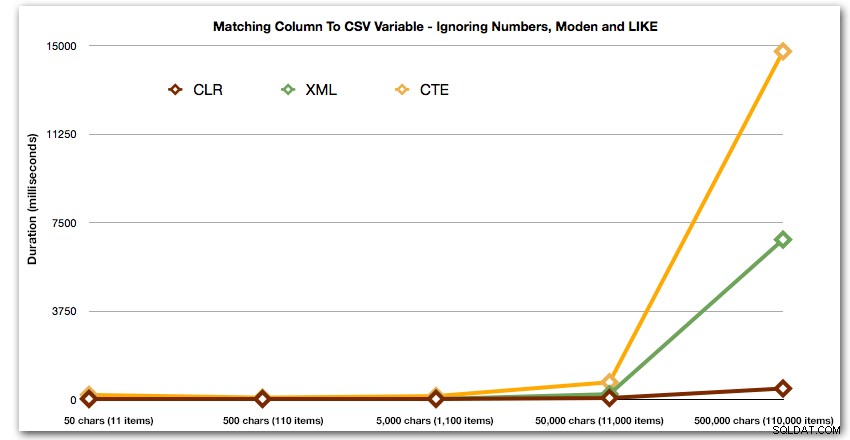
ORDER BY [object_id]; Hasil ini menunjukkan bahwa, untuk pola ini, beberapa metode melihat durasinya meningkat secara eksponensial seiring dengan bertambahnya ukuran string. Di ujung bawah, XML menjaga kecepatan yang baik dengan CLR, tetapi ini juga cepat memburuk. CLR secara konsisten adalah pemenang yang jelas di sini:
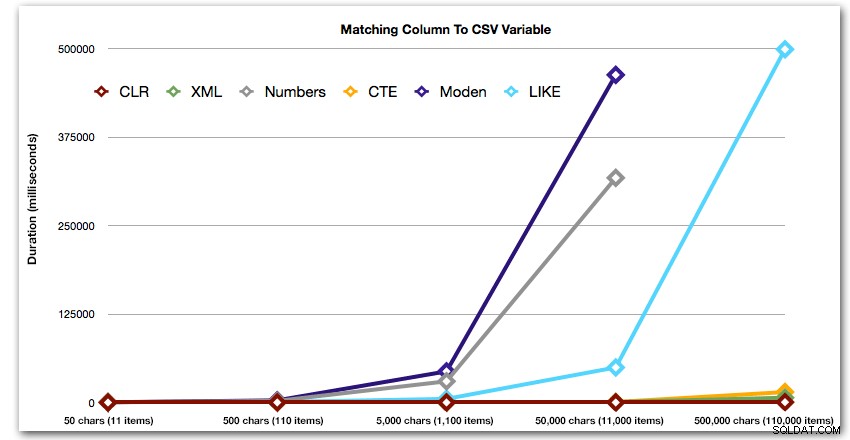
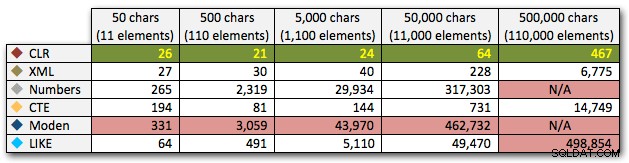
Durasi, dalam milidetik
Dan lagi tanpa metode yang meledak ke atas dalam hal durasi:
Terakhir, mari kita bandingkan biaya pengambilan data dari satu variabel dengan panjang yang bervariasi, dengan mengabaikan biaya membaca data dari tabel. Sekali lagi kami akan membuat string dengan panjang yang bervariasi, dari 50 – 500.000 karakter, dan kemudian hanya mengembalikan nilai sebagai satu set:
DECLARE @i INT = , -- value 1-5, yielding strings 50 - 500,000 characters @x NVARCHAR(MAX) = N'a,id,xyz,abcd,abcde,sa,foo,bar,mort,splunge,bacon,'; SET @x = REPLICATE(@x, POWER(10, @i-1)); SET @x = SUBSTRING(@x, 1, LEN(@x)-1) + 'x'; SELECT Item FROM dbo.SplitStrings_(@x, N',');
Hasil ini juga menunjukkan bahwa CLR cukup datar dalam hal durasi, hingga 110.000 item dalam set, sementara metode lain mempertahankan kecepatan yang layak hingga beberapa saat setelah 11.000 item:
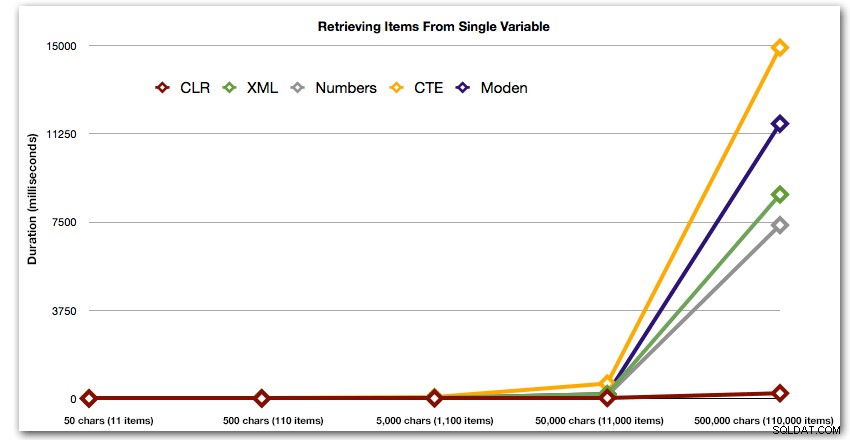
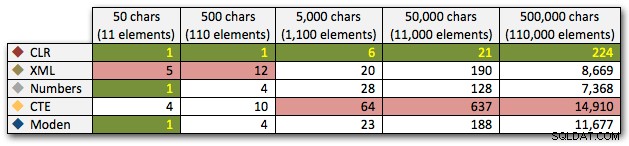
Durasi, dalam milidetik
Kesimpulan
Di hampir semua kasus, solusi CLR jelas mengungguli pendekatan lain – dalam beberapa kasus ini adalah kemenangan telak, terutama karena ukuran string meningkat; di beberapa lainnya, itu adalah hasil akhir foto yang bisa jatuh dengan cara apa pun. Pada pengujian pertama, kami melihat bahwa XML dan CTE mengungguli CLR di bagian bawah, jadi jika ini adalah kasus penggunaan tipikal *dan* Anda yakin bahwa string Anda berada dalam rentang 1 – 10.000 karakter, salah satu pendekatan tersebut mungkin menjadi pilihan yang lebih baik. Jika ukuran string Anda kurang dapat diprediksi dari itu, CLR mungkin masih merupakan taruhan terbaik Anda secara keseluruhan – Anda kehilangan beberapa milidetik di low end, tetapi Anda mendapatkan banyak di high end. Berikut adalah pilihan yang akan saya buat, tergantung pada tugas, dengan tempat kedua disorot untuk kasus di mana CLR bukan merupakan pilihan. Perhatikan bahwa XML adalah metode pilihan saya hanya jika saya tahu inputnya aman untuk XML; ini mungkin belum tentu menjadi alternatif terbaik Anda jika Anda kurang yakin dengan masukan Anda.
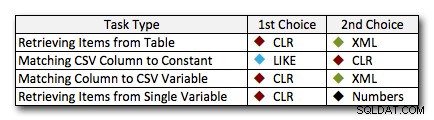
Satu-satunya pengecualian nyata di mana CLR bukan pilihan saya di seluruh papan adalah kasus di mana Anda benar-benar menyimpan daftar yang dipisahkan koma dalam sebuah tabel, dan kemudian menemukan baris di mana entitas yang ditentukan ada dalam daftar itu. Dalam kasus khusus itu, pertama-tama saya mungkin akan merekomendasikan mendesain ulang dan menormalkan skema dengan benar, sehingga nilai-nilai tersebut disimpan secara terpisah, daripada menggunakannya sebagai alasan untuk tidak menggunakan CLR untuk pemisahan.
Jika Anda tidak dapat menggunakan CLR karena alasan lain, tidak ada "tempat kedua" yang jelas yang diungkapkan oleh tes ini; jawaban saya di atas didasarkan pada skala keseluruhan dan bukan pada ukuran string tertentu. Setiap solusi di sini adalah runner up dalam setidaknya satu skenario – jadi sementara CLR jelas merupakan pilihan ketika Anda dapat menggunakannya, apa yang harus Anda gunakan ketika Anda tidak dapat lebih merupakan jawaban "itu tergantung" – Anda harus menilai berdasarkan kasus penggunaan Anda dan pengujian di atas (atau dengan membuat pengujian Anda sendiri) alternatif mana yang lebih baik untuk Anda.
Addendum :Alternatif untuk pemisahan di tempat pertama
Pendekatan di atas tidak memerlukan perubahan pada aplikasi Anda yang ada, dengan asumsi mereka sudah merakit string yang dipisahkan koma dan melemparkannya ke database untuk ditangani. Salah satu opsi yang harus Anda pertimbangkan, jika CLR bukan merupakan opsi dan/atau Anda dapat memodifikasi aplikasi, adalah menggunakan Table-Valued Parameters (TVPs). Berikut adalah contoh singkat bagaimana memanfaatkan TVP dalam konteks di atas. Pertama, buat tipe tabel dengan kolom string tunggal:
CREATE TYPE dbo.Items AS TABLE ( Item NVARCHAR(4000) );
Kemudian prosedur tersimpan dapat mengambil TVP ini sebagai input, dan bergabung dengan konten (atau menggunakannya dengan cara lain – ini hanya satu contoh):
CREATE PROCEDURE dbo.UpdateProfile
@UserID INT,
@TeamNames dbo.Items READONLY
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.UserTeams(UserID, TeamID) SELECT @UserID, t.TeamID
FROM dbo.Teams AS t
INNER JOIN @TeamNames AS tn
ON t.Name = tn.Item;
END
GO Sekarang dalam kode C# Anda, misalnya, alih-alih membuat string yang dipisahkan koma, isi DataTable (atau gunakan koleksi apa pun yang kompatibel yang mungkin sudah menampung kumpulan nilai Anda):
DataTable tvp = new DataTable();
tvp.Columns.Add(new DataColumn("Item"));
// in a loop from a collection, presumably:
tvp.Rows.Add(someThing.someValue);
using (connectionObject)
{
SqlCommand cmd = new SqlCommand("dbo.UpdateProfile", connectionObject);
cmd.CommandType = CommandType.StoredProcedure;
SqlParameter tvparam = cmd.Parameters.AddWithValue("@TeamNames", tvp);
tvparam.SqlDbType = SqlDbType.Structured;
// other parameters, e.g. userId
cmd.ExecuteNonQuery();
} Anda mungkin menganggap ini sebagai prekuel dari postingan lanjutan.
Tentu saja ini tidak cocok dengan JSON dan API lainnya – cukup sering alasan string yang dipisahkan koma diteruskan ke SQL Server.