Database dirancang dengan cara yang berbeda. Sebagian besar waktu kita dapat menggunakan "contoh sekolah":menormalkan database dan semuanya akan bekerja dengan baik. Tetapi ada situasi yang membutuhkan pendekatan lain. Kami dapat menghapus referensi untuk mendapatkan lebih banyak fleksibilitas. Tetapi bagaimana jika kita harus meningkatkan kinerja ketika semuanya dilakukan oleh buku? Dalam hal ini, denormalisasi adalah teknik yang harus kita pertimbangkan. Dalam artikel ini, kita akan membahas keuntungan dan kerugian dari denormalisasi dan situasi apa yang memungkinkannya.
Apa itu Denormalisasi?
Denormalisasi adalah strategi yang digunakan pada database yang sebelumnya dinormalisasi untuk meningkatkan kinerja. Ide di baliknya adalah untuk menambahkan data yang berlebihan yang menurut kami akan sangat membantu kami. Kita dapat menggunakan atribut tambahan di tabel yang ada, menambahkan tabel baru, atau bahkan membuat instance dari tabel yang sudah ada. Tujuan biasanya adalah untuk mengurangi waktu berjalan kueri pemilihan dengan membuat data lebih mudah diakses oleh kueri atau dengan membuat laporan yang diringkas dalam tabel terpisah. Proses ini dapat membawa beberapa masalah baru, dan kami akan membahasnya nanti.
Database yang dinormalisasi adalah titik awal untuk proses denormalisasi. Penting untuk membedakan dari database yang belum dinormalisasi dan database yang dinormalisasi terlebih dahulu dan kemudian didenormalisasi kemudian. Yang kedua baik-baik saja; yang pertama sering kali disebabkan oleh desain database yang buruk atau kurangnya pengetahuan.
Contoh:Model Normalisasi untuk CRM Sangat Sederhana
Model di bawah ini akan menjadi contoh kita:
Mari kita lihat tabelnya:
user_accounttabel menyimpan data tentang pengguna yang masuk ke aplikasi kami (menyederhanakan model, peran, dan hak pengguna dikecualikan darinya).clienttabel berisi beberapa data dasar tentang klien kami.producttabel mencantumkan produk yang ditawarkan kepada klien kami.tasktabel berisi semua tugas yang telah kita buat. Anda dapat menganggap setiap tugas sebagai serangkaian tindakan terkait terhadap klien. Setiap tugas memiliki panggilan, rapat, dan daftar produk yang ditawarkan dan dijual.calldanmeetingtabel menyimpan data tentang semua panggilan dan rapat serta menghubungkannya dengan tugas dan pengguna.- Kamus
task_outcome,meeting_outcomedancall_outcomeberisi semua opsi yang memungkinkan untuk status akhir tugas, rapat, atau panggilan. product_offeredmenyimpan daftar semua produk yang ditawarkan kepada klien pada tugas tertentu saatproduct_soldberisi daftar semua produk yang benar-benar dibeli klien.supply_ordertabel menyimpan data tentang semua pesanan yang telah kami lakukan danproducts_on_ordertabel mencantumkan produk dan jumlahnya untuk pesanan tertentu.- Penghapusan
writeofftabel adalah daftar produk yang dihapus karena kecelakaan atau sejenisnya (mis. kaca spion pecah).
Basis data disederhanakan tetapi dinormalisasi dengan sempurna. Anda tidak akan menemukan redundansi dan itu harus melakukan pekerjaan. Kami seharusnya tidak mengalami masalah kinerja dalam hal apa pun, selama kami bekerja dengan jumlah data yang relatif kecil.
Kapan dan Mengapa Menggunakan Denormalisasi
Seperti hampir semua hal, Anda harus yakin mengapa Anda ingin menerapkan denormalisasi. Anda juga harus yakin bahwa keuntungan dari menggunakannya lebih besar daripada kerugiannya. Ada beberapa situasi ketika Anda benar-benar harus memikirkan denormalisasi:
- Mempertahankan riwayat: Data dapat berubah seiring waktu, dan kita perlu menyimpan nilai yang valid saat record dibuat. Perubahan seperti apa yang kami maksud? Nah, nama depan dan belakang seseorang bisa berubah; klien juga dapat mengubah nama bisnis mereka atau data lainnya. Detail tugas harus berisi nilai yang sebenarnya pada saat tugas dibuat. Kami tidak akan dapat membuat ulang data masa lalu dengan benar jika ini tidak terjadi. Kita dapat mengatasi masalah ini dengan menambahkan tabel yang berisi riwayat perubahan ini. Dalam hal ini, kueri pemilihan yang mengembalikan tugas dan nama klien yang valid akan menjadi lebih rumit. Mungkin meja tambahan bukanlah solusi terbaik.
- Meningkatkan kinerja kueri: Beberapa kueri mungkin menggunakan beberapa tabel untuk mengakses data yang sering kita butuhkan. Pikirkan situasi di mana kita perlu menggabungkan 10 tabel untuk mengembalikan nama klien dan produk yang dijual kepada mereka. Beberapa tabel di sepanjang jalur juga dapat berisi data dalam jumlah besar. Dalam hal ini, mungkin akan lebih bijaksana untuk menambahkan
client_idatribut langsung keproducts_soldmeja. - Mempercepat pelaporan: Kami sangat sering membutuhkan statistik tertentu. Membuatnya dari data langsung cukup memakan waktu dan dapat memengaruhi kinerja sistem secara keseluruhan. Katakanlah kita ingin melacak penjualan klien selama tahun-tahun tertentu untuk beberapa atau semua klien. Menghasilkan laporan seperti itu dari data langsung akan "menggali" hampir di seluruh basis data dan sangat memperlambatnya. Dan apa yang terjadi jika kita sering menggunakan statistik itu?
- Menghitung nilai yang biasanya dibutuhkan di awal: Kami ingin memiliki beberapa nilai yang siap dihitung sehingga kami tidak perlu membuatnya secara real time.
Penting untuk diperhatikan bahwa Anda tidak perlu menggunakan denormalisasi jika tidak ada masalah kinerja dalam aplikasi. Tetapi jika Anda melihat sistem melambat – atau jika Anda sadar bahwa ini bisa terjadi – maka Anda harus mempertimbangkan untuk menerapkan teknik ini. Namun, sebelum melakukannya, pertimbangkan opsi lain, seperti pengoptimalan kueri dan pengindeksan yang tepat. Anda juga dapat menggunakan denormalisasi jika Anda sudah dalam produksi tetapi lebih baik untuk menyelesaikan masalah dalam tahap pengembangan.
Apa Kerugian Denormalisasi?
Jelas, keuntungan terbesar dari proses denormalisasi adalah peningkatan kinerja. Tapi kita harus membayar harga untuk itu, dan harga itu bisa terdiri dari:
- Ruang disk: Hal ini diharapkan, karena kami akan memiliki data duplikat.
- Anomali data: Kita harus sangat menyadari fakta bahwa data sekarang dapat diubah di lebih dari satu tempat. Kita harus menyesuaikan setiap bagian dari data duplikat yang sesuai. Itu juga berlaku untuk nilai dan laporan yang dihitung. Kita dapat mencapainya dengan menggunakan pemicu, transaksi, dan/atau prosedur untuk semua operasi yang harus diselesaikan bersama.
- Dokumentasi: Kita harus mendokumentasikan dengan baik setiap aturan denormalisasi yang telah kita terapkan. Jika nanti kita memodifikasi desain database, kita harus melihat semua pengecualian kita dan mempertimbangkannya sekali lagi. Mungkin kami tidak membutuhkannya lagi karena kami telah menyelesaikan masalah. Atau mungkin kita perlu menambahkan aturan denormalisasi yang sudah ada. (Misalnya:Kami menambahkan atribut baru ke tabel klien dan kami ingin menyimpan nilai riwayatnya bersama dengan semua yang telah kami simpan. Kami harus mengubah aturan denormalisasi yang ada untuk mencapainya).
- Memperlambat operasi lain: Kami dapat berharap bahwa kami akan memperlambat operasi penyisipan, modifikasi, dan penghapusan data. Jika operasi ini terjadi relatif jarang, ini bisa menjadi keuntungan. Pada dasarnya, kami akan membagi satu pilihan lambat menjadi lebih banyak kueri penyisipan/pembaruan/penghapusan yang lebih lambat. Meskipun kueri pemilihan yang sangat kompleks secara teknis dapat secara nyata memperlambat seluruh sistem, memperlambat beberapa operasi "lebih kecil" seharusnya tidak merusak kegunaan aplikasi kita.
- Pengkodean lainnya: Aturan 2 dan 3 akan memerlukan pengkodean tambahan, tetapi pada saat yang sama mereka akan sangat menyederhanakan beberapa kueri pemilihan. Jika kami mendenormalisasi database yang ada, kami harus memodifikasi kueri pemilihan ini untuk mendapatkan manfaat dari pekerjaan kami. Kami juga harus memperbarui nilai dalam atribut yang baru ditambahkan untuk catatan yang ada. Ini juga akan membutuhkan sedikit lebih banyak pengkodean.
Model Contoh, Didenormalisasi
Dalam model di bawah ini, saya menerapkan beberapa aturan denormalisasi yang disebutkan di atas. Tabel merah muda telah dimodifikasi, sedangkan tabel biru muda benar-benar baru.
Perubahan apa yang diterapkan dan mengapa?

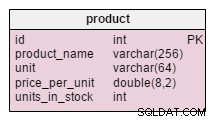
Satu-satunya perubahan di product tabel adalah penambahan units_in_stock atribut. Dalam model yang dinormalisasi, kita dapat menghitung data ini sebagai unit yang dipesan – unit yang terjual – (unit yang ditawarkan) – unit yang dihapuskan . Kami akan mengulangi perhitungan setiap kali klien meminta produk itu, yang akan sangat memakan waktu. Sebagai gantinya, kami akan menghitung nilai di muka; ketika pelanggan bertanya kepada kami, kami akan menyiapkannya. Tentu saja, ini sangat menyederhanakan kueri pemilihan. Sebaliknya, units_in_stock atribut harus disesuaikan setelah setiap menyisipkan, memperbarui, atau menghapus di products_on_order , writeoff , product_offered dan product_sold tabel.
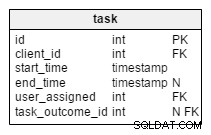
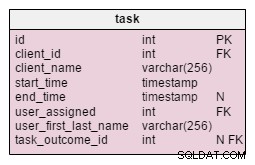
Dalam task tabel, kami menemukan dua atribut baru:client_name dan user_first_last_name . Keduanya menyimpan nilai saat tugas dibuat. Pasalnya, kedua nilai tersebut dapat berubah seiring waktu. Kami juga akan menyimpan kunci asing yang menghubungkannya dengan klien asli dan ID pengguna. Ada lebih banyak nilai yang ingin kami simpan, seperti alamat klien, ID PPN, dll.




product_offered tabel memiliki dua atribut baru, price_per_unit dan price . price_per_unit atribut disimpan karena kita perlu menyimpan harga sebenarnya saat produk ditawarkan . Model yang dinormalisasi hanya akan menunjukkan statusnya saat ini, jadi ketika harga produk berubah, harga 'riwayat' kami juga akan berubah. Perubahan kami tidak hanya membuat database berjalan lebih cepat:tetapi juga membuatnya bekerja lebih baik. price atribut adalah nilai yang dihitung units_sold * price_per_unit . Saya menambahkannya di sini untuk menghindari membuat perhitungan itu setiap kali kita ingin melihat daftar produk yang ditawarkan. Ini biaya kecil, tetapi meningkatkan kinerja.
Perubahan yang dilakukan pada product_sold tabel sangat mirip. Struktur tabelnya sama, tetapi menyimpan daftar barang yang terjual.
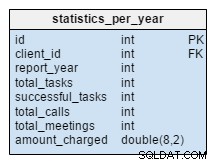
statistics_per_year tabel benar-benar baru untuk model kami. Kita harus melihatnya sebagai tabel yang didenormalisasi karena semua datanya dapat dihitung dari tabel lain. Gagasan di balik tabel ini adalah untuk menyimpan jumlah tugas, tugas yang berhasil, rapat, dan panggilan yang terkait dengan klien tertentu. Ini juga menangani jumlah total yang dibebankan per setiap tahun. Setelah menyisipkan, memperbarui, atau menghapus apa pun di task , meeting , call dan product_sold tabel, kami harus menghitung ulang data tabel ini untuk klien itu dan tahun yang sesuai. Kita dapat berharap bahwa kita sebagian besar akan memiliki perubahan hanya untuk tahun ini. Laporan untuk tahun-tahun sebelumnya tidak perlu diubah.
Nilai dalam tabel ini dihitung di awal, jadi kita akan menghabiskan lebih sedikit waktu dan sumber daya saat kita membutuhkan hasil perhitungan. Pikirkan tentang nilai-nilai yang akan sering Anda butuhkan. Mungkin Anda tidak akan membutuhkan semuanya secara teratur dan dapat mengambil risiko menghitung beberapa di antaranya secara langsung.
Denormalisasi adalah konsep yang sangat menarik dan kuat. Meskipun ini bukan yang pertama yang harus Anda pikirkan untuk meningkatkan kinerja, dalam beberapa situasi ini bisa menjadi yang terbaik atau bahkan satu-satunya solusi.
Sebelum Anda memilih untuk menggunakan denormalisasi, pastikan Anda menginginkannya. Lakukan beberapa analisis dan lacak kinerjanya. Anda mungkin akan memutuskan untuk melakukan denormalisasi setelah Anda ditayangkan. Jangan takut untuk menggunakannya, tetapi lacak perubahannya dan Anda tidak akan mengalami masalah apa pun (mis., anomali data yang ditakuti).



