Katakanlah Anda ingin mencari semua pasien yang belum pernah mendapat suntikan flu. Atau, di AdventureWorks2012 , pertanyaan serupa mungkin, "tunjukkan semua pelanggan yang belum pernah memesan." Dinyatakan menggunakan NOT IN , pola yang terlalu sering saya lihat, yang akan terlihat seperti ini (saya menggunakan header yang diperbesar dan tabel detail dari skrip ini oleh Jonathan Kehayias (@SQLPoolBoy)):
SELECT CustomerID FROM Sales.Customer WHERE CustomerID NOT IN ( SELECT CustomerID FROM Sales.SalesOrderHeaderEnlarged );
Ketika saya melihat pola ini, saya merasa ngeri. Tapi bukan karena alasan kinerja – bagaimanapun, ini menciptakan rencana yang cukup layak dalam hal ini:
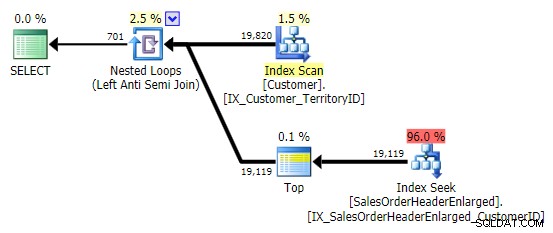
Masalah utama adalah bahwa hasilnya bisa mengejutkan jika kolom target NULLable (SQL Server memproses ini sebagai anti semi join kiri, tetapi tidak dapat memberi tahu Anda jika NULL di sisi kanan sama dengan – atau tidak sama dengan – referensi di sisi kiri). Selain itu, pengoptimalan dapat berperilaku berbeda jika kolomnya NULLable, meskipun sebenarnya tidak mengandung nilai NULL (Gail Shaw membicarakan hal ini pada tahun 2010).
Dalam hal ini, kolom target tidak dapat dibatalkan, tetapi saya ingin menyebutkan potensi masalah tersebut dengan NOT IN – Saya dapat menyelidiki masalah ini lebih teliti di postingan mendatang.
TL;DR versi
Alih-alih NOT IN , gunakan NOT EXISTS . yang berkorelasi untuk pola kueri ini. Selalu. Metode lain mungkin menyaingi dalam hal kinerja, ketika semua variabel lainnya sama, tetapi semua metode lain menimbulkan masalah kinerja atau tantangan lain.
Alternatif
Jadi cara lain apa yang bisa kita lakukan untuk menulis kueri ini?
BERLAKU LUAR
Salah satu cara kita dapat mengekspresikan hasil ini adalah menggunakan OUTER APPLY yang berkorelasi .
SELECT c.CustomerID FROM Sales.Customer AS c OUTER APPLY ( SELECT CustomerID FROM Sales.SalesOrderHeaderEnlarged WHERE CustomerID = c.CustomerID ) AS h WHERE h.CustomerID IS NULL;
Logikanya, ini juga merupakan anti semi join kiri, tetapi rencana yang dihasilkan tidak memiliki operator anti semi join kiri, dan tampaknya sedikit lebih mahal daripada NOT IN setara. Ini karena bukan lagi anti semi join kiri; itu sebenarnya diproses dengan cara yang berbeda:gabungan luar membawa semua baris yang cocok dan tidak cocok, dan *kemudian* filter diterapkan untuk menghilangkan kecocokan:
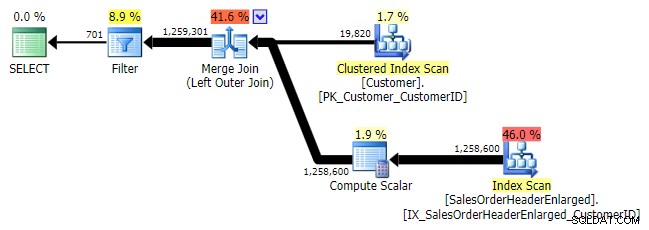
KIRI LUAR GABUNG
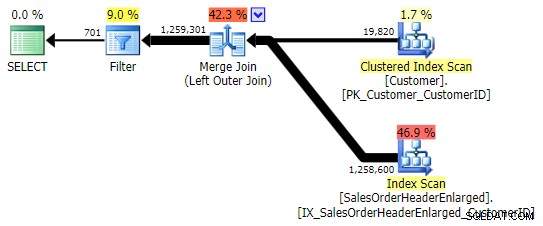
Alternatif yang lebih umum adalah LEFT OUTER JOIN di mana sisi kanan adalah NULL . Dalam hal ini kuerinya adalah:
SELECT c.CustomerID FROM Sales.Customer AS c LEFT OUTER JOIN Sales.SalesOrderHeaderEnlarged AS h ON c.CustomerID = h.CustomerID WHERE h.CustomerID IS NULL;
Ini mengembalikan hasil yang sama; namun, seperti OUTER APPLY, ia menggunakan teknik yang sama untuk menggabungkan semua baris, dan hanya kemudian menghilangkan kecocokan:
Anda harus berhati-hati, tentang kolom apa yang Anda periksa untuk NULL . Dalam hal ini CustomerID adalah pilihan logis karena merupakan kolom penghubung; itu juga kebetulan diindeks. Saya bisa memilih SalesOrderID , yang merupakan kunci pengelompokan, sehingga juga ada dalam indeks di CustomerID . Tapi saya bisa memilih kolom lain yang tidak ada di (atau yang kemudian dihapus dari) indeks yang digunakan untuk bergabung, yang mengarah ke rencana yang berbeda. Atau bahkan kolom NULLable, yang mengarah ke hasil yang salah (atau setidaknya tidak terduga), karena tidak ada cara untuk membedakan antara baris yang tidak ada dan baris yang memang ada tetapi kolomnya NULL . Dan mungkin tidak jelas bagi pembaca / pengembang / pemecah masalah bahwa ini masalahnya. Jadi saya juga akan menguji ketiga WHERE klausa:
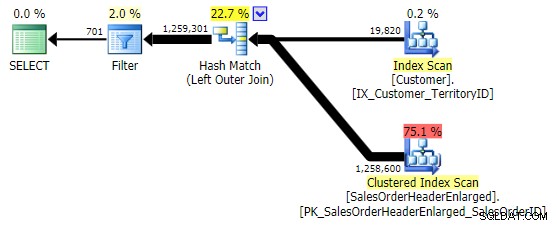
WHERE h.SalesOrderID IS NULL; -- clustered, so part of index WHERE h.SubTotal IS NULL; -- not nullable, not part of the index WHERE h.Comment IS NULL; -- nullable, not part of the index
Variasi pertama menghasilkan rencana yang sama seperti di atas. Dua lainnya memilih hash join daripada merge join, dan indeks yang lebih sempit di Customer tabel, meskipun kueri akhirnya membaca jumlah halaman dan jumlah data yang sama persis. Namun, sementara h.SubTotal variasi menghasilkan hasil yang benar:
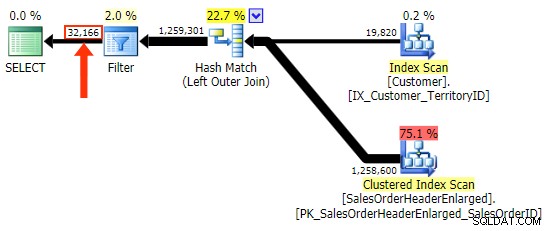
h.Comment variasi tidak, karena mencakup semua baris di mana h.Comment IS NULL , serta semua baris yang tidak ada untuk pelanggan mana pun. Saya telah menyoroti perbedaan halus dalam jumlah baris dalam output setelah filter diterapkan:
Selain perlu berhati-hati tentang pemilihan kolom di filter, masalah lain yang saya miliki dengan LEFT OUTER JOIN bentuk adalah bahwa itu tidak mendokumentasikan diri, dengan cara yang sama seperti gabungan dalam dalam bentuk "gaya lama" dari FROM dbo.table_a, dbo.table_b WHERE ... tidak mendokumentasikan diri sendiri. Maksud saya, mudah untuk melupakan kriteria bergabung ketika didorong ke WHERE klausa, atau untuk dicampur dengan kriteria filter lainnya. Saya menyadari ini cukup subjektif, tapi memang begitu.
KECUALI
Jika semua yang kita minati adalah kolom gabungan (yang menurut definisi ada di kedua tabel), kita dapat menggunakan EXCEPT – alternatif yang tampaknya tidak banyak muncul dalam percakapan ini (mungkin karena – biasanya – Anda perlu memperluas kueri untuk menyertakan kolom yang tidak Anda bandingkan):
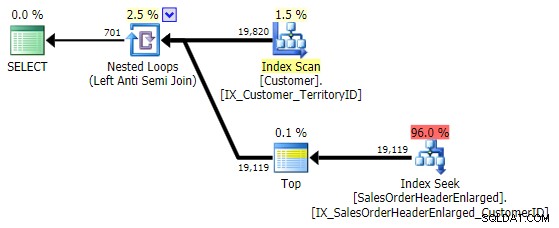
SELECT CustomerID FROM Sales.Customer AS c EXCEPT SELECT CustomerID FROM Sales.SalesOrderHeaderEnlarged;
Ini muncul dengan paket yang sama persis dengan NOT IN variasi di atas:
Satu hal yang perlu diingat adalah EXCEPT menyertakan DISTINCT implicit implisit – jadi jika Anda memiliki kasus di mana Anda ingin beberapa baris memiliki nilai yang sama di tabel "kiri", formulir ini akan menghilangkan duplikat tersebut. Bukan masalah dalam kasus khusus ini, hanya sesuatu yang perlu diingat – seperti UNION versus UNION ALL .
TIDAK ADA
Preferensi saya untuk pola ini pasti NOT EXISTS :
SELECT CustomerID
FROM Sales.Customer AS c
WHERE NOT EXISTS
(
SELECT 1
FROM Sales.SalesOrderHeaderEnlarged
WHERE CustomerID = c.CustomerID
);
(Dan ya, saya menggunakan SELECT 1 alih-alih SELECT * … bukan karena alasan kinerja, karena SQL Server tidak peduli kolom apa yang Anda gunakan di dalam EXISTS dan mengoptimalkannya, tetapi hanya untuk memperjelas maksud:ini mengingatkan saya bahwa "subquery" ini sebenarnya tidak mengembalikan data apa pun.)
Performanya mirip dengan NOT IN dan EXCEPT , dan menghasilkan rencana yang identik, tetapi tidak rentan terhadap potensi masalah yang disebabkan oleh NULL atau duplikat:
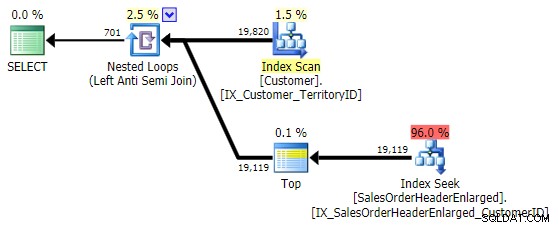
Uji Kinerja
Saya menjalankan banyak tes, dengan cache dingin dan hangat, untuk memvalidasi bahwa persepsi lama saya tentang NOT EXISTS menjadi pilihan yang tepat tetap benar. Output khasnya terlihat seperti ini:
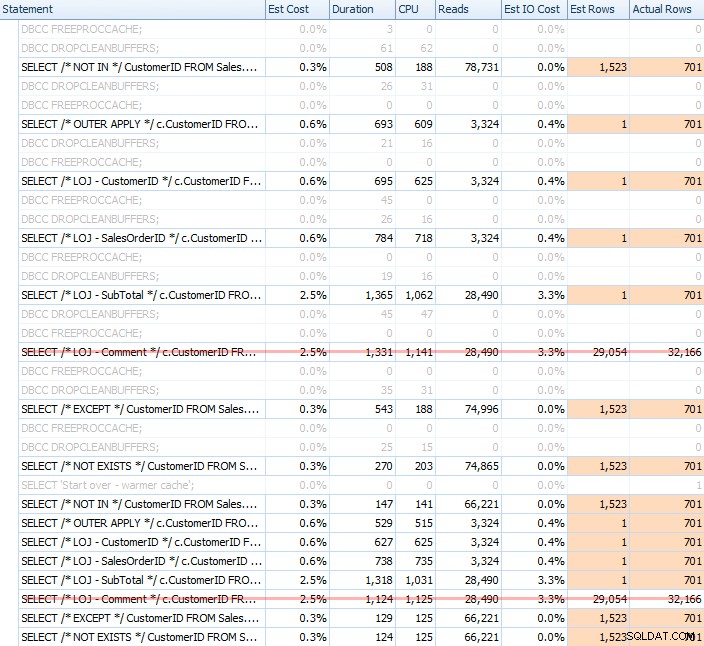
Saya akan mengeluarkan hasil yang salah dari campuran ketika menunjukkan kinerja rata-rata 20 kali berjalan pada grafik (saya hanya menyertakannya untuk menunjukkan betapa salahnya hasilnya), dan saya memang menjalankan kueri dalam urutan yang berbeda di seluruh pengujian untuk memastikan bahwa satu kueri tidak secara konsisten mendapat manfaat dari pekerjaan kueri sebelumnya. Berfokus pada durasi, inilah hasilnya:
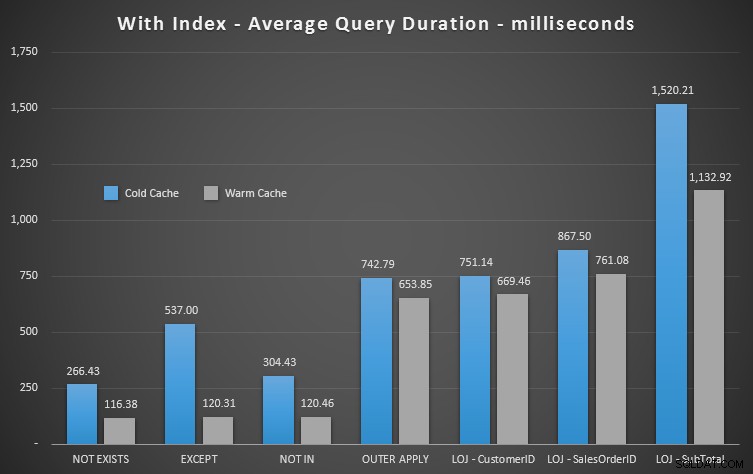
Jika kita melihat durasi dan mengabaikan bacaan, NOT EXISTS adalah pemenangnya, tetapi tidak banyak. KECUALI dan NOT IN tidak jauh di belakang, tetapi sekali lagi Anda perlu melihat lebih dari sekadar kinerja untuk menentukan apakah opsi ini valid, dan uji dalam skenario Anda.
Bagaimana jika tidak ada indeks pendukung?
Kueri di atas menguntungkan, tentu saja, dari indeks di Sales.SalesOrderHeaderEnlarged.CustomerID . Bagaimana hasil ini berubah jika kita menjatuhkan indeks ini? Saya menjalankan serangkaian tes yang sama lagi, setelah menjatuhkan indeks:
DROP INDEX [IX_SalesOrderHeaderEnlarged_CustomerID] ON [Sales].[SalesOrderHeaderEnlarged];
Kali ini ada jauh lebih sedikit penyimpangan dalam hal kinerja antara metode yang berbeda. Pertama saya akan menunjukkan rencana untuk setiap metode (yang sebagian besar, tidak mengherankan, menunjukkan kegunaan dari indeks yang hilang yang baru saja kita jatuhkan). Kemudian saya akan menampilkan grafik baru yang menggambarkan profil kinerja baik dengan cache dingin maupun cache hangat.
TIDAK DI, KECUALI, TIDAK ADA (ketiganya identik)
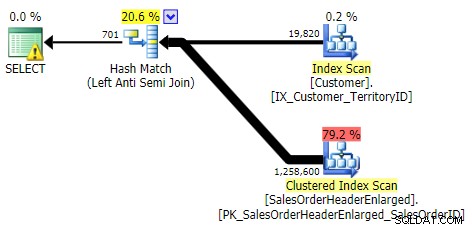
BERLAKU LUAR
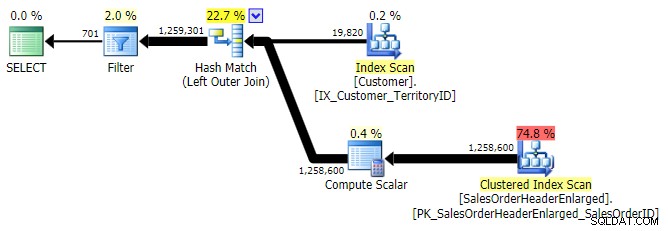
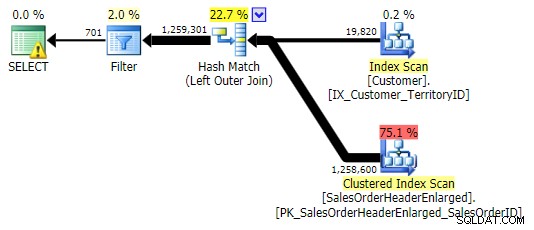
LEFT OUTER JOIN (ketiganya identik kecuali jumlah barisnya)
Hasil Kinerja
Kita bisa langsung melihat betapa bergunanya indeks saat kita melihat hasil baru ini. Dalam semua kecuali satu kasus (gabungan luar kiri yang tetap berada di luar indeks), hasilnya jelas lebih buruk ketika kita menjatuhkan indeks:
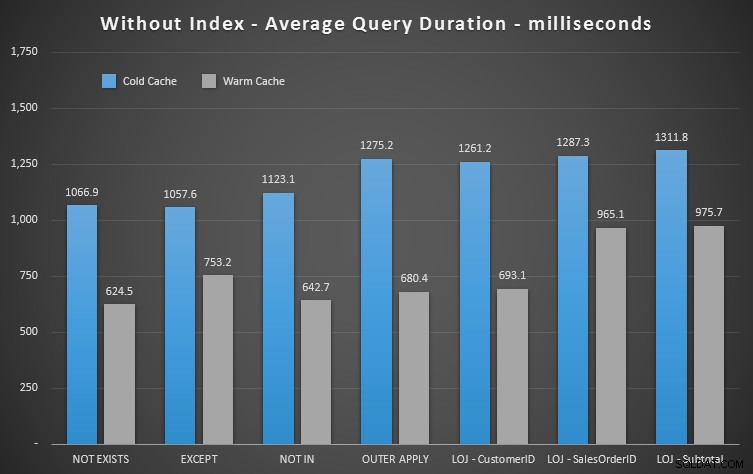
Jadi kita dapat melihat bahwa, meskipun ada dampak yang kurang terlihat, NOT EXISTS masih merupakan pemenang marjinal Anda dalam hal durasi. Dan dalam situasi di mana pendekatan lain rentan terhadap volatilitas skema, itu juga merupakan pilihan teraman Anda.
Kesimpulan
Ini hanyalah cara yang sangat bertele-tele untuk memberi tahu Anda bahwa, untuk pola menemukan semua baris dalam tabel A di mana beberapa kondisi tidak ada di tabel B, NOT EXISTS biasanya akan menjadi pilihan terbaik Anda. Namun, seperti biasa, Anda perlu menguji pola ini di lingkungan Anda sendiri, menggunakan skema, data, dan perangkat keras Anda, serta menggabungkannya dengan beban kerja Anda sendiri.