[ Bagian 1 | Bagian 2 | Bagian 3 ]
Baru-baru ini seseorang di tempat kerja meminta lebih banyak ruang untuk mengakomodasi meja yang berkembang pesat. Pada saat itu memiliki 3,75 miliar baris, disajikan pada 143 juta halaman, dan menempati ~ 1,14 TB. Tentu saja kita selalu bisa melempar lebih banyak disk ke meja, tapi saya ingin melihat apakah kita bisa menskalakan ini lebih efisien daripada tren linier saat ini. Kedengarannya seperti pekerjaan yang bagus untuk kompresi, bukan? Tetapi saya juga ingin mencoba beberapa solusi lain, termasuk columnstore – yang secara mengejutkan enggan dicoba oleh orang-orang. Saya bukan Niko, tapi saya ingin berusaha melihat apa yang bisa dilakukan Niko bagi kita di sini.
Perhatikan bahwa saya tidak berfokus pada pelaporan beban kerja atau kinerja kueri baca lainnya saat ini – saya hanya ingin melihat dampak apa yang dapat saya berikan pada jejak penyimpanan (dan memori) data ini.
Ini tabel aslinya. Saya telah mengubah nama tabel dan kolom untuk melindungi yang tidak bersalah, tetapi yang lainnya relatif akurat.
CREATE TABLE dbo.tblOriginal
(
OID bigint IDENTITY(1,1) NOT NULL PRIMARY KEY, -- there are gaps!
IN1 int NOT NULL,
IN2 int NOT NULL,
VC1 varchar(3) NULL,
BI1 bigint NULL,
IN3 int NULL,
VC2 varchar(128) NOT NULL,
VC3 varchar(128) NOT NULL,
VC4 varchar(128) NULL,
NM1 numeric(24,12) NULL,
NM2 numeric(24,12) NULL,
NM3 numeric(24,12) NULL,
BI2 bigint NULL,
IN4 int NULL,
BI3 bigint NULL,
NM4 numeric(24,12) NULL,
IN5 int NULL,
NM5 numeric(24,12) NULL,
DT1 date NULL,
VC5 varchar(128) NULL,
BI4 bigint NULL,
BI5 bigint NULL,
BI6 bigint NULL,
BT1 bit NOT NULL,
NV1 nvarchar(512) NULL,
VB1 AS (HASHBYTES('MD5',VC2+VC3)),
IN6 int NULL,
IN7 int NULL,
IN8 int NULL
);
Ada beberapa hal kecil lain di sana yang lebih lebar dari yang seharusnya dan/atau kompresi baris yang mungkin dibersihkan, seperti numeric(24,12) dan bigint kolom yang mungkin terlalu besar sebelum waktunya, tetapi saya tidak akan kembali ke tim aplikasi dan mencari tahu apakah ada sedikit efisiensi di sana, dan saya akan melewatkan kompresi baris untuk latihan ini dan fokus pada kompresi halaman dan penyimpanan kolom.
Ini adalah salinan data, pada server yang tidak aktif (8 core, 64GB RAM), dengan banyak ruang disk (lebih dari 6TB). Jadi pertama, mari tambahkan beberapa grup file, satu untuk penyimpanan kolom terklaster standar, dan satu untuk versi tabel yang dipartisi (di mana semua kecuali partisi terbaru akan dikompresi dengan COLUMNSTORE_ARCHIVE , karena semua data lama itu sekarang "hanya baca dan jarang"):
ALTER DATABASE OCopy ADD FILEGROUP FG_CCI; ALTER DATABASE OCopy ADD FILEGROUP FG_CCI_PARTITIONED;
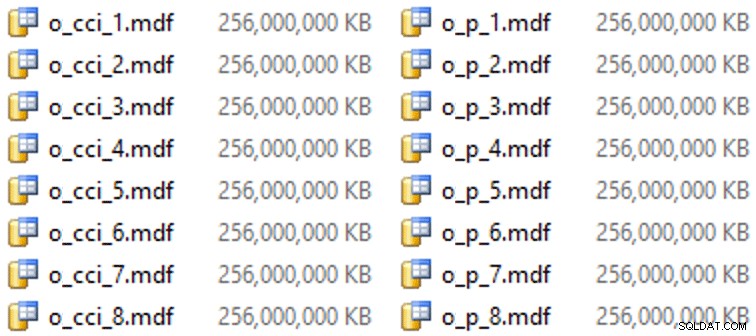
Dan kemudian beberapa file untuk grup file ini (satu file per inti, bagus dan berukuran seragam pada 256GB):
ALTER DATABASE OCopy ADD FILE (name = N'CCI_1', size = 250000, filename = 'K:\Data\o_cci_1.mdf') TO FILEGROUP FG_CCI; -- ... 6 more ... ALTER DATABASE OCopy ADD FILE (name = N'CCI_8', size = 250000, filename = 'K:\Data\o_cci_8.mdf') TO FILEGROUP FG_CCI; ALTER DATABASE OCopy ADD FILE (name = N'CCI_P_1', size = 250000, filename = 'K:\Data\o_p_1.mdf') TO FILEGROUP FG_CCI_PARTITIONED; -- ... 6 more ... ALTER DATABASE OCopy ADD FILE (name = N'CCI_P_8', size = 250000, filename = 'K:\Data\o_p_8.mdf') TO FILEGROUP FG_CCI_PARTITIONED;
Pada perangkat keras khusus ini (YMMV!), ini membutuhkan waktu sekitar 10 detik per file, dan menghasilkan yang berikut:
Untuk menghasilkan partisi, saya secara naif membagi data menjadi "merata" – atau begitulah menurut saya. Saya baru saja mengambil 3,75 miliar baris dan mempartisi menjadi sesuatu yang saya pikir dapat dikelola:38 partisi dengan 100 juta baris di 37 partisi pertama, dan sisanya di yang terakhir. (Ingat, ini hanya bagian 1! Ada asumsi yang melekat di sini tentang pemerataan nilai di tabel sumber, dan juga seputar apa yang optimal untuk populasi grup baris di tabel tujuan.) Membuat skema dan fungsi partisi untuk ini adalah sebagai berikut:
CREATE PARTITION FUNCTION PF_OID([bigint]) AS RANGE LEFT FOR VALUES (100000000, 200000000, /* ... 33 more ... */ , 3600000000, 3700000000); CREATE PARTITION SCHEME PS_OID AS PARTITION PF_OID ALL TO (FG_CCI_PARTITIONED);
Saya menggunakan RANGE LEFT karena, seperti yang terus diingatkan Cathrine Wilhelmsen kepada saya, ini berarti nilai batas adalah bagian dari partisi di sebelah kirinya. Dengan kata lain, nilai yang saya tentukan adalah nilai maksimal di setiap partisi (dengan tanggal, Anda biasanya ingin RANGE RIGHT ).
Saya kemudian membuat dua salinan tabel, satu di setiap filegroup. Yang pertama memiliki indeks penyimpanan kolom berkerumun standar, satu-satunya perbedaan adalah OID kolom bukan IDENTITY dan kolom yang dihitung hanyalah varbinary(8000) :
CREATE TABLE dbo.tblCCI ( OID bigint NOT NULL, -- ... other columns ... ) ON FG_CCI; GO CREATE CLUSTERED COLUMNSTORE INDEX CCI_IX ON dbo.tblCCI;
Yang kedua dibangun di atas skema partisi, jadi diperlukan PK bernama terlebih dahulu, yang kemudian harus diganti dengan indeks penyimpanan kolom berkerumun (meskipun Brent Ozar menunjukkan dalam posting singkat ini bahwa ada beberapa sintaks yang tidak intuitif yang akan menyelesaikan ini dalam langkah yang lebih sedikit ):
CREATE TABLE dbo.tblCCI_Partitioned ( OID bigint NOT NULL, -- ... other columns ..., CONSTRAINT PK_CCI_Part PRIMARY KEY CLUSTERED (OID) ON PS_OID (OID) ); GO ALTER TABLE dbo.tblCCI_Partitioned DROP CONSTRAINT PK_CCI_Part; GO CREATE CLUSTERED COLUMNSTORE INDEX CCI_Part ON dbo.tblCCI_Partitioned ON PS_OID (OID);
Kemudian, untuk menempatkan kompresi arsip pada semua kecuali partisi terakhir, saya menjalankan yang berikut:
ALTER TABLE dbo.tblCCI_Part
REBUILD PARTITION = ALL WITH
(
DATA_COMPRESSION = COLUMNSTORE ON PARTITIONS (38),
DATA_COMPRESSION = COLUMNSTORE_ARCHIVE ON PARTITIONS (1 TO 37)
); Sekarang, saya sudah siap untuk mengisi tabel ini dengan data, mengukur waktu yang dibutuhkan dan ukuran yang dihasilkan, dan membandingkan. Saya memodifikasi skrip batching yang bermanfaat dari Andy Mallon, dan memasukkan baris ke dalam kedua tabel secara berurutan, dengan ukuran batch 10 juta baris. Ada lebih banyak dari ini di skrip asli (termasuk memperbarui tabel antrian dengan kemajuan), tetapi pada dasarnya:
DECLARE @BatchSize int = 10000000, @MaxID bigint, @LastID bigint = 0;
SELECT @MaxID = MAX(OID) FROM dbo.tblOriginal;
WHILE @LastID < @MaxID
BEGIN
INSERT dbo.tblCCI
(
-- all columns except the computed column
)
SELECT -- all columns except the computed column
FROM dbo.tblOriginal AS o
WHERE o.CostID >= @LastID
AND o.CostID < @LastID + @BatchSize;
SET @LastID += @BatchSize;
END Setelah saya mengisi kedua tabel columnstore dari sumber asli (tidak terkompresi), saya membangun kembali partisi-partisi itu lagi untuk membersihkan kekacauan grup baris dan kamus. Akhirnya, saya menerapkan kompresi halaman, di tempat, ke tabel sumber. Berikut adalah timing dan hasil kompresi dari masing-masing tipe:
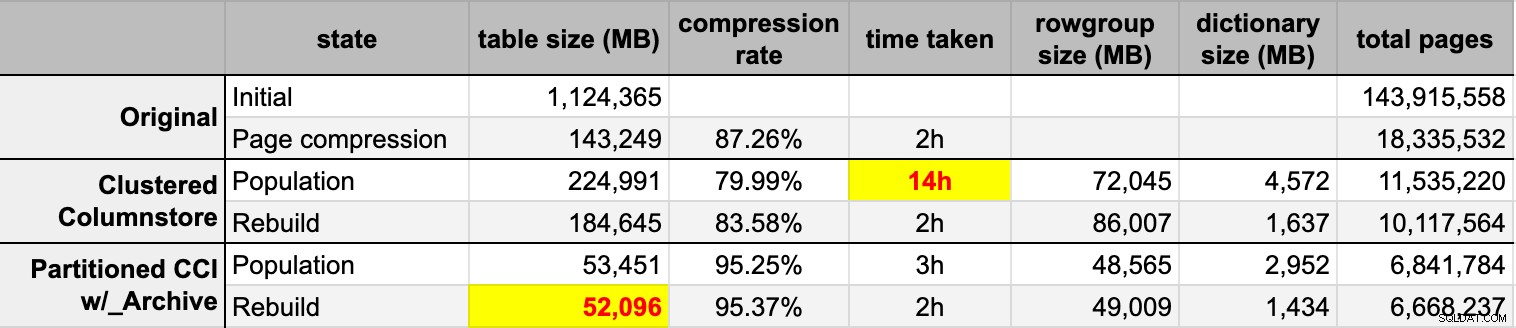
Saya terkesan sekaligus kecewa. Terkesan karena data ini dikompres sangat baik – mengecilkan jejak penyimpanan hingga 5% dari 1TB asli adalah hal yang luar biasa. Kecewa karena:
- Saya membuat file data itu cara terlalu besar.
- Saya tidak mengerti apa yang terjadi dengan kompresi penyimpanan kolom awal 14 jam:
- Saya tidak mengamati memori atau tekanan log apa pun.
- Tidak ada peristiwa pertumbuhan file.
- Sayangnya, saya tidak berpikir untuk melacak waktu tunggu. Tidak, saya tidak akan mencobanya lagi. :-)
- Kompresi halaman mengungguli kompresi penyimpanan kolom biasa – mungkin karena data.
- Membangun kembali partisi arsip columnstore menghabiskan banyak waktu CPU dengan perolehan hampir nol.
Dalam posting yang akan datang, dan setelah meninjau catatan saya dari presentasi columnstore yang luar biasa oleh Joe Obbish di PASS Summit (yang akan saya tautkan secara langsung, jika saja PASS tahu cara UI), saya akan berbicara sedikit tentang perubahan yang akan saya lakukan. buat konfigurasi server dan skrip populasi saya untuk melihat apakah saya bisa mendapatkan kinerja yang lebih baik dari populasi toko kolom.
[ Bagian 1 | Bagian 2 | Bagian 3 ]