Artikel ini adalah bagian keempat dari rangkaian ekspresi tabel. Dalam Bagian 1 dan Bagian 2 saya membahas perlakuan konseptual dari tabel turunan. Di Bagian 3 saya mulai membahas pertimbangan optimasi tabel turunan. Bulan ini saya membahas aspek lebih lanjut dari optimasi tabel turunan; khusus, saya fokus pada substitusi/unnesting tabel turunan.
Dalam contoh saya, saya akan menggunakan database sampel yang disebut TSQLV5 dan PerformanceV5. Anda dapat menemukan skrip yang membuat dan mengisi TSQLV5 di sini, dan diagram ER-nya di sini. Anda dapat menemukan skrip yang membuat dan mengisi PerformanceV5 di sini.
Menghilangkan sarang/substitusi
Penghapusan/penggantian ekspresi tabel adalah proses mengambil kueri yang melibatkan penyarangan ekspresi tabel, dan seolah-olah menggantinya dengan kueri di mana logika bersarang dihilangkan. Saya harus menekankan bahwa dalam praktiknya, tidak ada proses aktual di mana SQL Server mengonversi string kueri asli dengan logika bersarang ke string kueri baru tanpa bersarang. Apa yang sebenarnya terjadi adalah bahwa proses parsing kueri menghasilkan pohon awal dari operator logika yang mencerminkan kueri asli. Kemudian, SQL Server menerapkan transformasi ke pohon kueri ini, menghilangkan beberapa langkah yang tidak perlu, menciutkan beberapa langkah menjadi langkah yang lebih sedikit, dan memindahkan operator. Dalam transformasinya, selama kondisi tertentu terpenuhi, SQL Server dapat mengubah hal-hal di sekitar apa yang semula merupakan batas ekspresi tabel—terkadang secara efektif seolah-olah menghilangkan unit bersarang. Semua ini dalam upaya untuk menemukan rencana yang optimal.
Dalam artikel ini saya membahas kedua kasus di mana unnesting tersebut terjadi, serta inhibitor unnesting. Artinya, saat Anda menggunakan elemen kueri tertentu, SQL Server tidak dapat memindahkan operator logis di pohon kueri, memaksanya untuk memproses operator berdasarkan batas ekspresi tabel yang digunakan dalam kueri asli.
Saya akan mulai dengan mendemonstrasikan contoh sederhana di mana tabel turunan menjadi tidak bersarang. Saya juga akan menunjukkan contoh untuk inhibitor yang tidak bersarang. Saya kemudian akan berbicara tentang kasus yang tidak biasa di mana unnesting dapat menjadi tidak diinginkan, yang mengakibatkan kesalahan atau penurunan kinerja, dan menunjukkan cara mencegah unnesting dalam kasus tersebut dengan menggunakan inhibitor unnesting.
Kueri berikut (kami akan menyebutnya Kueri 1) menggunakan beberapa lapisan tabel turunan, di mana setiap ekspresi tabel menerapkan logika pemfilteran dasar berdasarkan konstanta:
SELECT orderid, orderdateFROM ( SELECT * FROM ( SELECT * FROM ( SELECT * FROM Sales.Orders WHERE orderdate>='20180101' ) AS D1 WHERE orderdate>='20180201' ) AS D2 WHERE orderdate>='20180301' ) AS D3WHERE tanggal pemesanan>='20180401';
Seperti yang Anda lihat, setiap ekspresi tabel memfilter rentang tanggal pesanan yang dimulai dengan tanggal yang berbeda. SQL Server menghapus logika kueri berlapis-lapis ini, yang memungkinkannya untuk kemudian menggabungkan empat predikat penyaringan menjadi satu yang mewakili persimpangan keempat predikat.
Periksa rencana untuk Query 1 yang ditunjukkan pada Gambar 1.
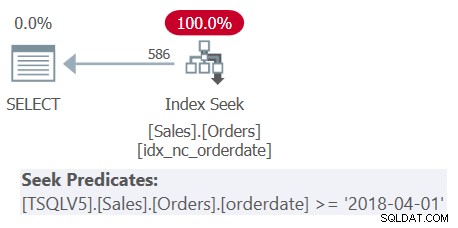 Gambar 1:Rencana untuk Kueri 1
Gambar 1:Rencana untuk Kueri 1
Amati bahwa keempat predikat penyaringan digabungkan menjadi satu predikat yang mewakili perpotongan keempatnya. Rencana tersebut menerapkan pencarian di indeks idx_nc_orderdate berdasarkan predikat gabungan tunggal sebagai predikat pencarian. Indeks ini didefinisikan pada orderdate (secara eksplisit), orderid (secara implisit karena adanya indeks berkerumun pada orderid) sebagai kunci indeks.
Perhatikan juga bahwa meskipun semua ekspresi tabel menggunakan SELECT * dan hanya kueri terluar yang memproyeksikan dua kolom yang diminati:orderdate dan orderid, indeks yang disebutkan di atas dianggap mencakup. Seperti yang saya jelaskan di Bagian 3, untuk tujuan pengoptimalan seperti pemilihan indeks, SQL Server mengabaikan kolom dari ekspresi tabel yang pada akhirnya tidak relevan. Namun ingat bahwa Anda perlu memiliki izin untuk menanyakan kolom tersebut.
Seperti yang disebutkan, SQL Server akan mencoba untuk menghapus ekspresi tabel, tetapi akan menghindari unnesting jika tersandung ke inhibitor yang tidak bersarang. Dengan pengecualian tertentu yang akan saya jelaskan nanti, penggunaan TOP atau OFFSET FETCH akan menghambat unnesting. Alasannya karena mencoba untuk menghapus ekspresi tabel dengan TOP atau OFFSET FETCH dapat mengakibatkan perubahan pada makna kueri asli.
Sebagai contoh, perhatikan kueri berikut (kami akan menyebutnya Kueri 2):
SELECT orderid, orderdateFROM ( SELECT TOP (9223372036854775807) * FROM ( SELECT TOP (9223372036854775807) * FROM ( SELECT TOP (9223372036854775807) * FROM Sales.Orders WHERE orderdate>='20180101' ) AS D1 WHERE orderdate>='20180201 ' ) AS D2 WHERE orderdate>='20180301' ) AS D3WHERE orderdate>='20180401';
Jumlah baris input ke filter TOP adalah nilai yang diketik BIGINT. Dalam contoh ini saya menggunakan nilai BIGINT maksimum (2^63 – 1, hitung dalam T-SQL menggunakan SELECT POWER(2., 63) – 1). Meskipun Anda dan saya tahu bahwa tabel Pesanan kami tidak akan pernah memiliki banyak baris, dan oleh karena itu filter TOP benar-benar tidak berarti, SQL Server harus memperhitungkan kemungkinan teoretis agar filter menjadi bermakna. Akibatnya, SQL Server tidak menghapus ekspresi tabel dalam kueri ini. Rencana untuk Query 2 ditunjukkan pada Gambar 2.
 Gambar 2:Rencana untuk Kueri 2
Gambar 2:Rencana untuk Kueri 2
Inhibitor yang tidak bersarang mencegah SQL Server untuk dapat menggabungkan predikat penyaringan, menyebabkan bentuk rencana lebih mirip dengan kueri konseptual. Namun, menarik untuk mengamati bahwa SQL Server masih mengabaikan kolom yang pada akhirnya tidak relevan dengan kueri terluar, dan oleh karena itu dapat menggunakan indeks penutup pada tanggal pesanan, pesanan.
Untuk mengilustrasikan mengapa TOP dan OFFSET-FETCH adalah inhibitor yang tidak bersarang, mari kita ambil teknik optimasi pushdown predikat sederhana. Predikat pushdown berarti pengoptimal mendorong predikat filter ke titik sebelumnya dibandingkan dengan titik asli yang muncul dalam pemrosesan kueri logis. Misalnya, Anda memiliki kueri dengan gabungan dalam dan filter WHERE berdasarkan kolom dari salah satu sisi gabungan. Dalam hal pemrosesan kueri logis, filter WHERE seharusnya dievaluasi setelah bergabung. Namun seringkali pengoptimal akan mendorong predikat filter ke langkah sebelum penggabungan, karena ini membuat gabungan dengan lebih sedikit baris untuk dikerjakan, biasanya menghasilkan rencana yang lebih optimal. Ingatlah bahwa transformasi semacam itu hanya diperbolehkan dalam kasus di mana makna kueri asli dipertahankan, dalam arti bahwa Anda dijamin mendapatkan kumpulan hasil yang benar.
Pertimbangkan kode berikut, yang memiliki kueri luar dengan filter WHERE terhadap tabel turunan, yang pada gilirannya didasarkan pada ekspresi tabel dengan filter TOP:
SELECT orderid, orderdateFROM ( SELECT TOP (3) * FROM Sales.Orders ) AS DWHERE orderdate>='20180101';
Kueri ini tentu saja nondeterministik karena kurangnya klausa ORDER BY dalam ekspresi tabel. Ketika saya menjalankannya, SQL Server kebetulan mengakses tiga baris pertama dengan tanggal pemesanan lebih awal dari 2018, jadi saya mendapat satu set kosong sebagai output:
orderid orderdate----------- ----------(0 baris terpengaruh)
Seperti disebutkan, penggunaan TOP dalam ekspresi tabel mencegah unnesting/substitusi dari ekspresi tabel di sini. Seandainya SQL Server menghapus ekspresi tabel, proses substitusi akan menghasilkan yang setara dengan kueri berikut:
SELECT TOP (3) orderid, orderdateFROM Sales.OrdersWHERE orderdate>='20180101';
Kueri ini juga nondeterministik karena kurangnya klausa ORDER BY, tetapi jelas memiliki arti yang berbeda dari kueri aslinya. Jika tabel Sales.Orders memiliki setidaknya tiga pesanan yang dilakukan pada tahun 2018 atau lebih baru—dan memang demikian—kueri ini tentu akan mengembalikan tiga baris, tidak seperti kueri asli. Inilah hasil yang saya dapatkan ketika menjalankan kueri ini:
orderid orderdate----------- ----------10400 2018-01-0110401 2018-01-010402 2018-01-02(3 baris terpengaruh)
Jika sifat nondeterministik dari dua kueri di atas membingungkan Anda, berikut adalah contoh dengan kueri deterministik:
SELECT orderid, orderdateFROM ( SELECT TOP (3) * FROM Sales.Orders ORDER BY orderid ) AS DWHERE orderdate>='20170708'ORDER BY orderid;
Ekspresi tabel memfilter tiga pesanan dengan ID pesanan terendah. Kueri luar kemudian memfilter dari ketiga pesanan tersebut hanya yang ditempatkan pada atau setelah 8 Juli 2017. Ternyata hanya ada satu pesanan yang memenuhi syarat. Kueri ini menghasilkan keluaran berikut:
orderid orderdate----------- ----------10250 2017-07-08(1 baris terpengaruh)
Misalkan SQL Server menghapus ekspresi tabel dalam kueri asli, dengan proses substitusi yang menghasilkan setara kueri berikut:
SELECT TOP (3) orderid, orderdateFROM Sales.OrdersWHERE orderdate>='20170708'ORDER BY orderid;
Arti dari kueri ini berbeda dari kueri aslinya. Kueri ini pertama-tama memfilter pesanan yang dilakukan pada atau setelah 8 Juli 2017, lalu memfilter tiga teratas di antara pesanan yang memiliki ID pesanan terendah. Kueri ini menghasilkan keluaran berikut:
orderid orderdate----------- ----------10250 2017-07-0810251 2017-07-0810252 2017-07-09(3 baris terpengaruh)
Untuk menghindari perubahan arti dari kueri asli, SQL Server tidak menerapkan unnesting/substitusi di sini.
Dua contoh terakhir melibatkan campuran sederhana dari pemfilteran WHERE dan TOP, tetapi mungkin ada elemen konflik tambahan yang dihasilkan dari unnesting. Misalnya, bagaimana jika Anda memiliki spesifikasi pengurutan yang berbeda dalam ekspresi tabel dan kueri luar, seperti pada contoh berikut:
SELECT orderid, orderdateFROM ( SELECT TOP (3) * FROM Sales.Orders ORDER BY orderdate DESC, orderid DESC ) AS DORDER BY orderid;
Anda menyadari bahwa jika SQL Server menghapus ekspresi tabel, menciutkan dua spesifikasi pengurutan yang berbeda menjadi satu, kueri yang dihasilkan akan memiliki arti yang berbeda dari kueri asli. Itu akan memfilter baris yang salah atau menyajikan baris hasil dalam urutan presentasi yang salah. Singkatnya, Anda menyadari mengapa hal yang aman untuk dilakukan SQL Server adalah menghindari penghapusan/substitusi ekspresi tabel yang didasarkan pada kueri TOP dan OFFSET-FETCH.
Saya sebutkan sebelumnya bahwa ada pengecualian aturan bahwa penggunaan TOP dan OFFSET-FETCH mencegah unnesting. Saat itulah Anda menggunakan TOP (100) PERCENT dalam ekspresi tabel bersarang, dengan atau tanpa klausa ORDER BY. SQL Server menyadari bahwa tidak ada penyaringan nyata yang terjadi dan mengoptimalkan opsi keluar. Berikut ini contoh yang menunjukkan hal ini:
SELECT orderid, orderdateFROM ( SELECT TOP (100) PERCENT * FROM ( SELECT TOP (100) PERCENT * FROM ( SELECT TOP (100) PERCENT * FROM Sales.Orders WHERE orderdate>='20180101' ) AS D1 WHERE orderdate> ='20180201' ) AS D2 WHERE tanggal pemesanan>='20180301' ) AS D3WHERE tanggal pemesanan>='20180401';
Filter TOP diabaikan, unnesting terjadi, dan Anda mendapatkan rencana yang sama seperti yang ditunjukkan sebelumnya untuk Kueri 1 pada Gambar 1.
Saat menggunakan OFFSET 0 ROWS tanpa klausa FETCH dalam ekspresi tabel bersarang, tidak ada pemfilteran nyata yang terjadi. Jadi, secara teoritis SQL Server dapat mengoptimalkan opsi ini juga dan mengaktifkan unnesting, tetapi pada tanggal penulisan ini tidak. Berikut ini contoh yang menunjukkan hal ini:
SELECT orderid, orderdateFROM ( SELECT * FROM ( SELECT * FROM ( SELECT * FROM Sales.Orders WHERE orderdate>='20180101' ORDER BY (SELECT NULL) OFFSET 0 ROWS ) AS D1 WHERE orderdate>='20180201' ORDER BY (SELECT NULL) OFFSET 0 ROWS ) AS D2 WHERE orderdate>='20180301' ORDER BY (SELECT NULL) OFFSET 0 ROWS ) AS D3WHERE orderdate>='20180401';
Anda mendapatkan paket yang sama seperti yang ditunjukkan sebelumnya untuk Kueri 2 pada Gambar 2, yang menunjukkan bahwa tidak ada unnesting yang terjadi.
Sebelumnya saya menjelaskan bahwa proses unnesting/substitusi tidak benar-benar menghasilkan string kueri baru yang kemudian dioptimalkan, melainkan berkaitan dengan transformasi yang diterapkan SQL Server ke pohon operator logika. Ada perbedaan antara cara SQL Server mengoptimalkan kueri dengan ekspresi tabel bersarang versus kueri yang sebenarnya setara secara logis tanpa bersarang. Penggunaan ekspresi tabel seperti tabel turunan, serta subkueri mencegah parameterisasi sederhana. Ingat Kueri 1 yang ditampilkan sebelumnya di artikel:
SELECT orderid, orderdateFROM ( SELECT * FROM ( SELECT * FROM ( SELECT * FROM Sales.Orders WHERE orderdate>='20180101' ) AS D1 WHERE orderdate>='20180201' ) AS D2 WHERE orderdate>='20180301' ) AS D3WHERE tanggal pemesanan>='20180401';
Karena kueri menggunakan tabel turunan, parameterisasi sederhana tidak terjadi. Artinya, SQL Server tidak mengganti konstanta dengan parameter dan kemudian mengoptimalkan kueri, melainkan mengoptimalkan kueri dengan konstanta. Dengan predikat berdasarkan konstanta, SQL Server dapat menggabungkan periode berpotongan, yang dalam kasus kami menghasilkan predikat tunggal dalam rencana, seperti yang ditunjukkan sebelumnya pada Gambar 1.
Selanjutnya, pertimbangkan kueri berikut (kami akan menyebutnya Kueri 3), yang secara logis setara dengan Kueri 1, tetapi di mana Anda menerapkan unnesting sendiri:
SELECT orderid, orderdateFROM Sales.OrdersWHERE orderdate>='20180101' AND orderdate>='20180201' AND orderdate>='20180301' AND orderdate>='20180401';
Rencana untuk kueri ini ditunjukkan pada Gambar 3.
 Gambar 3:Rencana untuk Kueri 3
Gambar 3:Rencana untuk Kueri 3
Rencana ini dianggap aman untuk parameterisasi sederhana, sehingga konstanta diganti dengan parameter, dan akibatnya, predikat tidak digabungkan. Motivasi untuk parameterisasi tentu saja meningkatkan kemungkinan penggunaan kembali rencana saat menjalankan kueri serupa yang hanya berbeda dalam konstanta yang mereka gunakan.
Seperti disebutkan, penggunaan tabel turunan dalam Kueri 1 mencegah parameterisasi sederhana. Demikian pula, penggunaan subquery akan mencegah parameterisasi sederhana. Misalnya, inilah Kueri 3 kami sebelumnya dengan predikat tidak berarti berdasarkan subkueri yang ditambahkan ke klausa WHERE:
SELECT orderid, orderdateFROM Sales.OrdersWHERE orderdate>='20180101' AND orderdate>='20180201' AND orderdate>='20180301' AND orderdate>='20180401' AND (SELECT 42) =42;
Kali ini parameterisasi sederhana tidak terjadi, memungkinkan SQL Server untuk menggabungkan periode berpotongan yang diwakili oleh predikat dengan konstanta, menghasilkan rencana yang sama seperti yang ditunjukkan sebelumnya pada Gambar 1.
Jika Anda memiliki kueri dengan ekspresi tabel yang menggunakan konstanta, dan penting bagi Anda bahwa SQL Server membuat parameter kode, dan untuk alasan apa pun Anda tidak dapat membuat parameter sendiri, ingatlah bahwa Anda memiliki opsi untuk menggunakan parameterisasi paksa dengan panduan rencana. Sebagai contoh, kode berikut membuat panduan rencana seperti itu untuk Kueri 3:
MENNYATAKAN @stmt SEBAGAI NVARCHAR(MAX), @params SEBAGAI NVARCHAR(MAX); EXEC sys.sp_get_query_template @querytext =N'SELECT orderid, orderdateFROM ( SELECT * FROM ( SELECT * FROM ( SELECT * FROM Sales.Orders WHERE orderdate>=''20180101'' ) AS D1 WHERE orderdate>=''20180201'' ) AS D2 WHERE orderdate>=''20180301'' ) AS D3WHERE orderdate>=''20180401'';', @templatetext =@stmt OUTPUT, @parameters =@params OUTPUT; EXEC sys.sp_create_plan_guide @name =N'TG1', @stmt =@stmt, @type =N'TEMPLATE', @module_or_batch =NULL, @params =@params, @hints =N'OPTION(PARAMETERIZATION FORCED)';Jalankan Query 3 lagi setelah membuat panduan rencana:
SELECT orderid, orderdateFROM ( SELECT * FROM ( SELECT * FROM ( SELECT * FROM Sales.Orders WHERE orderdate>='20180101' ) AS D1 WHERE orderdate>='20180201' ) AS D2 WHERE orderdate>='20180301' ) AS D3WHERE tanggal pemesanan>='20180401';Anda mendapatkan rencana yang sama seperti yang ditunjukkan sebelumnya pada Gambar 3 dengan predikat parameter.
Setelah selesai, jalankan kode berikut untuk menghapus panduan paket:
EXEC sys.sp_control_plan_guide @operation =N'DROP', @name =N'TG1';Mencegah tidak bersarang
Ingat bahwa SQL Server menghapus ekspresi tabel untuk alasan pengoptimalan. Tujuannya adalah untuk meningkatkan kemungkinan menemukan rencana dengan biaya lebih rendah dibandingkan tanpa unnesting. Itu berlaku untuk sebagian besar aturan transformasi yang diterapkan oleh pengoptimal. Namun, mungkin ada beberapa kasus yang tidak biasa di mana Anda ingin mencegah unnesting. Ini bisa untuk menghindari kesalahan (ya dalam beberapa kasus yang tidak biasa unnesting dapat mengakibatkan kesalahan) atau untuk alasan kinerja untuk memaksa bentuk rencana tertentu, mirip dengan menggunakan petunjuk kinerja lainnya. Ingat, kamu punya cara sederhana untuk menghambat unnesting menggunakan TOP dengan jumlah yang sangat besar.
Contoh untuk menghindari kesalahan
Saya akan mulai dengan kasus di mana penggabungan ekspresi tabel dapat menyebabkan kesalahan.
Pertimbangkan kueri berikut (kami akan menyebutnya Kueri 4):
PILIH orderid, productid, discountFROM Sales.OrderDetailsWHERE discount> (SELECT MIN(discount) FROM Sales.OrderDetails) AND 1.0 / discount> 10.0;Contoh ini agak dibuat-buat dalam arti mudah untuk menulis ulang predikat filter kedua sehingga tidak akan pernah menghasilkan kesalahan (diskon <0,1), tetapi ini adalah contoh yang nyaman bagi saya untuk menggambarkan poin saya. Diskon tidak negatif. Jadi bahkan jika ada baris pesanan dengan diskon nol, kueri seharusnya memfilternya (predikat filter pertama mengatakan bahwa diskon harus lebih besar dari diskon minimum dalam tabel). Namun, tidak ada jaminan bahwa SQL Server akan mengevaluasi predikat secara tertulis, jadi Anda tidak dapat mengandalkan korsleting.
Periksa rencana untuk Query 4 yang ditunjukkan pada Gambar 4.
Gambar 4:Rencana untuk Kueri 4
Perhatikan bahwa dalam rencana, predikat 1.0 / diskon> 10.0 (kedua dalam klausa WHERE) dievaluasi sebelum diskon predikat>
(pertama dalam klausa WHERE). Akibatnya, kueri ini menghasilkan kesalahan pembagian dengan nol: Msg 8134, Level 16, Status 1Ditemukan kesalahan pembagian dengan nol.Mungkin Anda berpikir bahwa Anda dapat menghindari kesalahan dengan menggunakan tabel turunan, memisahkan tugas pemfilteran ke tugas dalam dan tugas luar, seperti:
SELECT orderid, productid, discountFROM ( SELECT * FROM Sales.OrderDetails WHERE discount> (SELECT MIN(discount) FROM Sales.OrderDetails) ) AS DWHERE 1.0 / discount> 10.0;Namun, SQL Server menerapkan unnesting dari tabel turunan, menghasilkan rencana yang sama yang ditunjukkan sebelumnya pada Gambar 4, dan akibatnya, kode ini juga gagal dengan kesalahan bagi dengan nol:
Msg 8134, Level 16, Status 1Ditemukan kesalahan pembagian dengan nol.Perbaikan sederhana di sini adalah memperkenalkan inhibitor yang tidak bersarang, seperti (kami akan menyebut solusi ini Kueri 5):
SELECT orderid, productid, discountFROM ( SELECT TOP (9223372036854775807) * FROM Sales.OrderDetails WHERE discount> (SELECT MIN(discount) FROM Sales.OrderDetails) ) AS DWHERE 1.0 / discount> 10.0;Rencana untuk Query 5 ditunjukkan pada Gambar 5.
Gambar 5:Rencana untuk Kueri 5
Jangan bingung dengan fakta bahwa ekspresi 1.0 / diskon muncul di bagian dalam operator Nested Loops, seolah-olah dievaluasi terlebih dahulu. Ini hanya definisi anggota Expr1006. Evaluasi sebenarnya dari predikat Expr1006> 10.0 diterapkan oleh operator Filter sebagai langkah terakhir dalam rencana setelah baris dengan diskon minimum disaring oleh operator Nested Loops sebelumnya. Solusi ini berjalan dengan sukses tanpa kesalahan.
Contoh untuk alasan kinerja
Saya akan melanjutkan dengan kasus di mana penggabungan ekspresi tabel dapat merusak kinerja.
Mulailah dengan menjalankan kode berikut untuk mengalihkan konteks ke database PerformanceV5 dan mengaktifkan STATISTICS IO dan TIME:
GUNAKAN PerformaV5; SET STATISTIK IO, WAKTU AKTIF;Pertimbangkan kueri berikut (kami akan menyebutnya Kueri 6):
SELECT shipperid, MAX(orderdate) AS maxodFROM dbo.OrdersGROUP BY shipperid;Pengoptimal mengidentifikasi indeks penutup pendukung dengan shipperid dan orderdate sebagai kunci utama. Jadi itu membuat rencana dengan pemindaian indeks yang berurutan diikuti oleh operator Stream Aggregate berbasis pesanan, seperti yang ditunjukkan dalam rencana untuk Query 6 pada Gambar 6.
Gambar 6:Rencana untuk Kueri 6
Tabel Pesanan memiliki 1.000.000 baris, dan kolom pengelompokan pengirim sangat padat—hanya ada 5 ID pengirim yang berbeda, menghasilkan kepadatan 20% (persen rata-rata per nilai yang berbeda). Menerapkan pemindaian penuh daun indeks melibatkan membaca beberapa ribu halaman, menghasilkan waktu berjalan sekitar sepertiga detik di sistem saya. Berikut adalah statistik kinerja yang saya dapatkan untuk eksekusi kueri ini:
Waktu CPU =344 md, waktu berlalu =346 md, pembacaan logis =3854Pohon indeks saat ini memiliki kedalaman tiga tingkat.
Mari kita tingkatkan jumlah pesanan dengan faktor 1.000 hingga 1.000.000.000, tetapi masih dengan hanya 5 pengirim yang berbeda. Jumlah halaman di daun indeks akan bertambah dengan faktor 1.000, dan pohon indeks mungkin akan menghasilkan satu tingkat tambahan (kedalaman empat tingkat). Rencana ini memiliki skala linier. Anda akan mendapatkan hampir 4.000.000 pembacaan logis, dan waktu berjalan beberapa menit.
Saat Anda perlu menghitung agregat MIN atau MAX terhadap tabel besar, dengan kepadatan sangat tinggi di kolom pengelompokan (penting!), dan indeks B-tree pendukung yang dikunci pada kolom pengelompokan dan kolom agregasi, ada cara yang jauh lebih optimal bentuk rencana daripada yang ada di Gambar 6. Bayangkan bentuk rencana yang memindai set kecil ID pengirim dari beberapa indeks pada tabel Pengirim, dan dalam satu lingkaran berlaku untuk setiap pengirim pencarian terhadap indeks pendukung pada Pesanan untuk mendapatkan agregat. Dengan 1.000.000 baris dalam tabel, 5 pencarian akan melibatkan 15 pembacaan. Dengan 1.000.000.000 baris, 5 pencarian akan melibatkan 20 pembacaan. Dengan satu triliun baris, total 25 bacaan. Jelas, rencana jauh lebih optimal. Anda benar-benar dapat mencapai rencana seperti itu dengan menanyakan tabel Pengirim, dan memperoleh agregat menggunakan subkueri agregat skalar terhadap Pesanan, seperti ini (kami akan menyebut solusi ini Kueri 7):
SELECT S.shipperid, (SELECT MAX(O.orderdate) FROM dbo.Orders AS O WHERE O.shipperid =S.shipperid) AS maxodFROM dbo.Shippers AS S;Rencana untuk kueri ini ditunjukkan pada Gambar 7.
Gambar 7:Rencana untuk Kueri 7
Bentuk rencana yang diinginkan tercapai, dan angka kinerja untuk eksekusi kueri ini dapat diabaikan seperti yang diharapkan:
Waktu CPU =0 md, waktu berlalu =0 md, pembacaan logis =15Selama kolom pengelompokan sangat padat, ukuran tabel Pesanan menjadi hampir tidak signifikan.
Tapi tunggu sebentar sebelum Anda pergi merayakannya. Ada persyaratan untuk hanya menyimpan pengirim yang tanggal pesanan terkait maksimumnya di tabel Pesanan pada atau setelah 2018. Kedengarannya seperti tambahan yang cukup sederhana. Tentukan tabel turunan berdasarkan Kueri 7, dan terapkan filter di kueri luar, seperti ini (kami akan menyebut solusi ini Kueri 8):
SELECT shipperid, maxodFROM ( SELECT S.shipperid, (SELECT MAX(O.orderdate) FROM dbo.Orders AS O WHERE O.shipperid =S.shipperid) AS maxod FROM dbo.Shippers AS S ) AS DWHERE maxod>='20180101';Sayangnya, SQL Server menghapus sarang kueri tabel turunan, serta subkueri, mengubah logika agregasi menjadi setara dengan logika kueri yang dikelompokkan, dengan shipperid sebagai kolom pengelompokan. Dan cara SQL Server mengetahui untuk mengoptimalkan kueri yang dikelompokkan didasarkan pada satu lintasan di atas data input, menghasilkan rencana yang sangat mirip dengan yang ditunjukkan sebelumnya pada Gambar 6, hanya dengan filter tambahan. Rencana untuk Query 8 ditunjukkan pada Gambar 8.
Gambar 8:Rencanakan Kueri 8
Akibatnya, penskalaan bersifat linier, dan angka performa serupa dengan yang untuk Kueri 6:
Waktu CPU =328 md, waktu berlalu =325 md, pembacaan logis =3854Cara mengatasinya adalah dengan memperkenalkan inhibitor yang tidak bersarang. Ini dapat dilakukan dengan menambahkan filter TOP ke ekspresi tabel yang menjadi dasar tabel turunan, seperti ini (kami akan menyebut solusi ini Query 9):
SELECT shipperid, maxodFROM ( SELECT TOP (9223372036854775807) S.shipperid, (SELECT MAX(O.orderdate) FROM dbo.Orders AS O WHERE O.shipperid =S.shipperid) AS maxod FROM dbo.Shippers AS S ) AS DWHERE maxod>='20180101';Rencana untuk kueri ini ditunjukkan pada Gambar 9 dan memiliki bentuk rencana yang diinginkan dengan pencarian:
Gambar 9:Rencana untuk Kueri 9
Angka performa untuk eksekusi ini tentu saja dapat diabaikan:
Waktu CPU =0 md, waktu berlalu =0 md, pembacaan logis =15Namun opsi lain adalah mencegah unnesting subquery, dengan mengganti agregat MAX dengan filter TOP (1) yang setara, seperti ini (kami akan menyebut solusi ini Kueri 10):
SELECT shipperid, maxodFROM ( SELECT S.shipperid, (SELECT TOP (1) O.orderdate FROM dbo.Orders AS O WHERE O.shipperid =S.shipperid ORDER BY O.orderdate DESC) AS maxod FROM dbo.Shippers AS S ) AS DWHERE maxod>='20180101';Rencana untuk kueri ini ditunjukkan pada Gambar 10 dan lagi, memiliki bentuk yang diinginkan dengan pencarian.
Gambar 10:Rencana untuk Query 10
Saya mendapatkan angka kinerja yang dapat diabaikan untuk eksekusi ini:
Waktu CPU =0 md, waktu berlalu =0 md, pembacaan logis =15Setelah selesai, jalankan kode berikut untuk berhenti melaporkan statistik kinerja:
SET STATISTIK IO, WAKTU MATI;Ringkasan
Pada artikel ini saya melanjutkan diskusi yang saya mulai bulan lalu tentang optimasi tabel turunan. Bulan ini saya fokus pada unnesting tabel turunan. Saya menjelaskan bahwa biasanya unnesting menghasilkan rencana yang lebih optimal dibandingkan tanpa unnesting, tetapi juga mencakup contoh di mana itu tidak diinginkan. Saya menunjukkan contoh di mana unnesting mengakibatkan kesalahan serta contoh yang mengakibatkan penurunan kinerja. Saya mendemonstrasikan cara mencegah unnesting dengan menerapkan inhibitor unnesting seperti TOP.
Bulan depan saya akan melanjutkan eksplorasi ekspresi tabel bernama, mengalihkan fokus ke CTE.