Seperti bahasa pemrograman lainnya, T-SQL memiliki bug dan perangkap umum, beberapa di antaranya menyebabkan hasil yang salah dan yang lainnya menyebabkan masalah kinerja. Dalam banyak kasus tersebut, ada praktik terbaik yang dapat membantu Anda menghindari masalah. Saya menyurvei sesama MVP Platform Data Microsoft menanyakan tentang bug dan jebakan yang sering mereka lihat atau yang menurut mereka sangat menarik, dan praktik terbaik yang mereka terapkan untuk menghindarinya. Saya mendapat banyak kasus menarik.
Terima kasih banyak kepada Erland Sommarskog, Aaron Bertrand, Alejandro Mesa, Umachandar Jayachandran (UC), Fabiano Neves Amorim, Milos Radivojevic, Simon Sabin, Adam Machanic, Thomas Grohser, dan Chan Ming Man untuk berbagi pengetahuan dan pengalaman Anda!
Artikel ini adalah yang pertama dalam seri tentang topik tersebut. Setiap artikel berfokus pada tema tertentu. Bulan ini saya fokus pada bug, jebakan, dan praktik terbaik yang terkait dengan determinisme. Perhitungan deterministik adalah perhitungan yang dijamin menghasilkan hasil yang dapat diulang dengan input yang sama. Ada banyak bug dan perangkap yang dihasilkan dari penggunaan perhitungan nondeterministik. Dalam artikel ini saya membahas implikasi penggunaan urutan nondeterministik, fungsi nondeterministik, referensi ganda ke ekspresi tabel dengan perhitungan nondeterministik, dan penggunaan ekspresi CASE dan fungsi NULLIF dengan perhitungan nondeterministik.
Saya menggunakan database sampel TSQLV5 di banyak contoh dalam seri ini.
Urutan nondeterministik
Salah satu sumber umum untuk bug di T-SQL adalah penggunaan urutan nondeterministik. Artinya, ketika pesanan Anda berdasarkan daftar tidak secara unik mengidentifikasi sebuah baris. Bisa berupa pemesanan presentasi, pemesanan TOP/OFFSET-FETCH atau pemesanan jendela.
Ambil contoh skenario paging klasik menggunakan filter OFFSET-FETCH. Anda perlu mengkueri tabel Sales.Orders yang menampilkan satu halaman berisi 10 baris sekaligus, diurutkan berdasarkan tanggal pemesanan, menurun (terbaru lebih dulu). Saya akan menggunakan konstanta untuk elemen offset dan fetch untuk kesederhanaan, tetapi biasanya mereka adalah ekspresi yang didasarkan pada parameter input.
Kueri berikut (sebut saja Kueri 1) mengembalikan halaman pertama dari 10 pesanan terbaru:
GUNAKAN TSQLV5; PILIH orderid, orderdate, custid FROM Sales.Orders ORDER BY orderdate DESC OFFSET 0 ROWS FETCH NEXT 10 ROWS ONLY;
Rencana untuk Query 1 ditunjukkan pada Gambar 1.
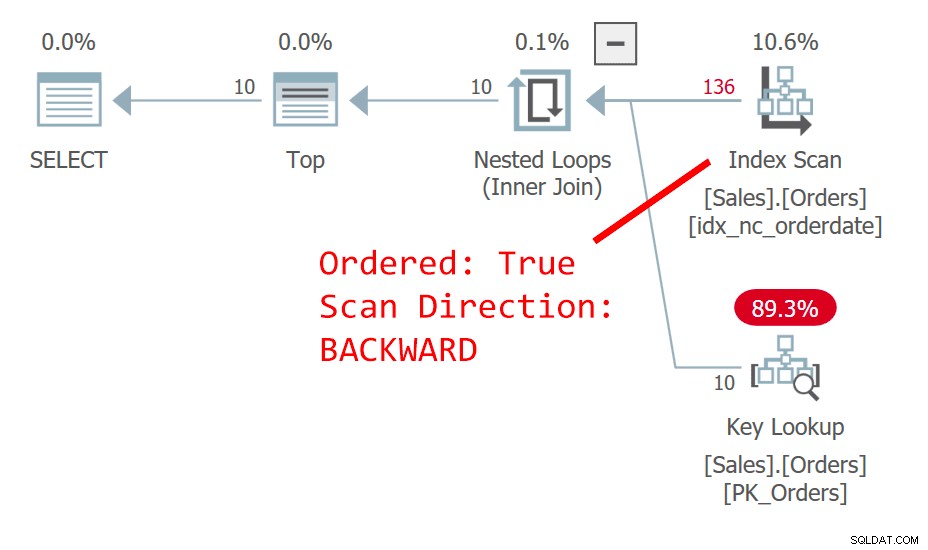 Gambar 1:Rencanakan kueri 1
Gambar 1:Rencanakan kueri 1
Kueri mengurutkan baris berdasarkan tanggal pemesanan, menurun. Kolom orderdate tidak secara unik mengidentifikasi sebuah baris. Urutan nondeterministik ini berarti bahwa secara konseptual, tidak ada preferensi antara baris dengan tanggal yang sama. Dalam hal ikatan, yang menentukan baris mana yang akan disukai SQL Server adalah hal-hal seperti pilihan paket dan tata letak data fisik—bukan sesuatu yang dapat Anda andalkan sebagai pengulangan. Rencana pada Gambar 1 memindai indeks pada tanggal pemesanan yang diurutkan mundur. Kebetulan tabel ini memiliki indeks berkerumun pada orderid, dan dalam tabel berkerumun kunci indeks berkerumun digunakan sebagai pencari baris dalam indeks noncluster. Itu benar-benar secara implisit diposisikan sebagai elemen kunci terakhir di semua indeks nonclustered meskipun secara teoritis SQL Server dapat menempatkannya dalam indeks sebagai kolom yang disertakan. Jadi, secara implisit, indeks nonclustered pada orderdate sebenarnya didefinisikan pada (orderdate, orderid). Akibatnya, dalam pemindaian indeks mundur terurut kami, antara baris terikat berdasarkan tanggal pesanan, baris dengan nilai urut lebih tinggi diakses sebelum baris dengan nilai urut lebih rendah. Kueri ini menghasilkan keluaran berikut:
orderid orderdate custid ----------- ---------- ----------- 11077 2019-05-06 65 11076 2019-05- 06 9 11075 2019-05-06 68 11074 2019-05-06 73 11073 2019-05-05 58 11072 2019-05-05 20 11071 2019-05-05 46 11070 2019-05-05 44 11069 2019-05-04 80 *** 11068 05-04-2019 62
Selanjutnya, gunakan query berikut (sebut saja Query 2) untuk mendapatkan halaman kedua dari 10 baris:
PILIH orderid, orderdate, custid FROM Sales.Orders ORDER BY orderdate DESC OFFSET 10 ROWS FETCH NEXT 10 ROWS ONLY;
Rencana untuk Query ditunjukkan pada Gambar 2.
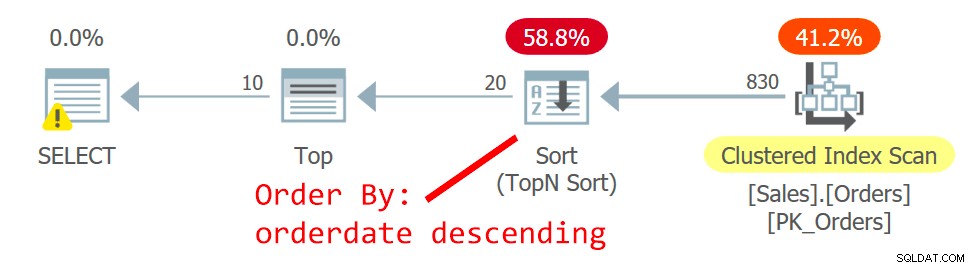
Gambar 2:Rencana kueri 2
Pengoptimal memilih paket yang berbeda—satu paket memindai indeks berkerumun secara tidak berurutan, dan menggunakan Pengurutan TopN untuk mendukung permintaan operator Top untuk menangani filter pengambilan offset. Alasan untuk perubahan tersebut adalah bahwa rencana pada Gambar 1 menggunakan indeks noncovering nonclustered, dan semakin jauh halaman yang Anda cari, semakin banyak pencarian yang diperlukan. Dengan permintaan halaman kedua, Anda melewati titik kritis yang membenarkan penggunaan indeks noncovering.
Meskipun pemindaian indeks berkerumun, yang didefinisikan dengan orderid sebagai kuncinya, adalah yang tidak berurutan, mesin penyimpanan menggunakan pemindaian urutan indeks secara internal. Ini ada hubungannya dengan ukuran indeks. Hingga 64 halaman, mesin penyimpanan umumnya lebih menyukai pemindaian urutan indeks daripada pemindaian urutan alokasi. Bahkan jika indeks lebih besar, di bawah tingkat isolasi berkomitmen baca dan data yang tidak ditandai sebagai hanya baca, mesin penyimpanan menggunakan pemindaian urutan indeks untuk menghindari pembacaan ganda dan melewatkan baris sebagai akibat dari pemisahan halaman yang terjadi selama memindai. Di bawah kondisi yang diberikan, dalam praktiknya, antara baris dengan tanggal yang sama, paket ini mengakses baris dengan orderid yang lebih rendah sebelum baris dengan orderid yang lebih tinggi.
Kueri ini menghasilkan keluaran berikut:
orderid orderdate custid ----------- ---------- ----------- 11069 2019-05-04 80 *** 11064 2019 -05-01 71 11065 2019-05-01 46 11066 2019-05-01 89 11060 2019-04-30 27 11061 2019-04-30 32 11062 2019-04-30 66 11063 2019-04-30 37 11057 2019- 29-04 53 11058 29-04-2019 6
Perhatikan bahwa meskipun data pokok tidak berubah, Anda mendapatkan pesanan yang sama (dengan ID pesanan 11069) yang dikembalikan di halaman pertama dan kedua!
Semoga, praktik terbaik di sini jelas. Tambahkan tiebreak ke pesanan Anda berdasarkan daftar untuk mendapatkan pesanan deterministik. Misalnya, urutkan berdasarkan tanggal pesanan turun, urutkan turun.
Coba lagi tanyakan halaman pertama, kali ini dengan urutan deterministik:
PILIH orderid, orderdate, custid FROM Sales.Orders ORDER BY orderdate DESC, orderid DESC OFFSET 0 ROWS FETCH NEXT 10 ROWS ONLY;
Anda mendapatkan output berikut, dijamin:
orderid orderdate custid ----------- ---------- ----------- 11077 2019-05-06 65 11076 2019-05- 06 9 11075 2019-05-06 68 11074 2019-05-06 73 11073 2019-05-05 58 11072 2019-05-05 20 11071 2019-05-05 46 11070 2019-05-05 44 11069 2019-05-04 80 11068 05-04-2019 62
Minta halaman kedua:
PILIH orderid, orderdate, custid FROM Sales.Orders ORDER BY orderdate DESC, orderid DESC OFFSET 10 ROWS FETCH NEXT 10 ROWS ONLY;
Anda mendapatkan output berikut, dijamin:
orderid orderdate custid ----------- ---------- ----------- 11067 2019-05-04 17 11066 2019-05- 01 89 11065 2019-05-01 46 11064 2019-05-01 71 11063 2019-04-30 37 11062 2019-04-30 66 11061 2019-04-30 32 11060 2019-04-30 27 11059 2019-04-29 67 11058 29-04-2019 6
Selama tidak ada perubahan pada data pokok, Anda dijamin mendapatkan halaman berurutan tanpa pengulangan atau lompatan baris antar halaman.
Dengan cara yang sama, menggunakan fungsi jendela seperti ROW_NUMBER dengan urutan nondeterministik, Anda bisa mendapatkan hasil yang berbeda untuk kueri yang sama bergantung pada bentuk rencana dan urutan akses aktual di antara ikatan. Pertimbangkan kueri berikut (sebut saja Kueri 3), menerapkan permintaan halaman pertama menggunakan nomor baris (memaksa penggunaan indeks pada tanggal pemesanan untuk tujuan ilustrasi):
WITH C AS ( SELECT orderid, orderdate, custid, ROW_NUMBER() OVER(ORDER BY orderdate DESC) AS n FROM Sales.Orders WITH (INDEX(idx_nc_orderdate)) ) SELECT orderid, orderdate, custid FROM C WHERE n BETWEEN 1 DAN 10;
Rencana untuk kueri ini ditunjukkan pada Gambar 3:
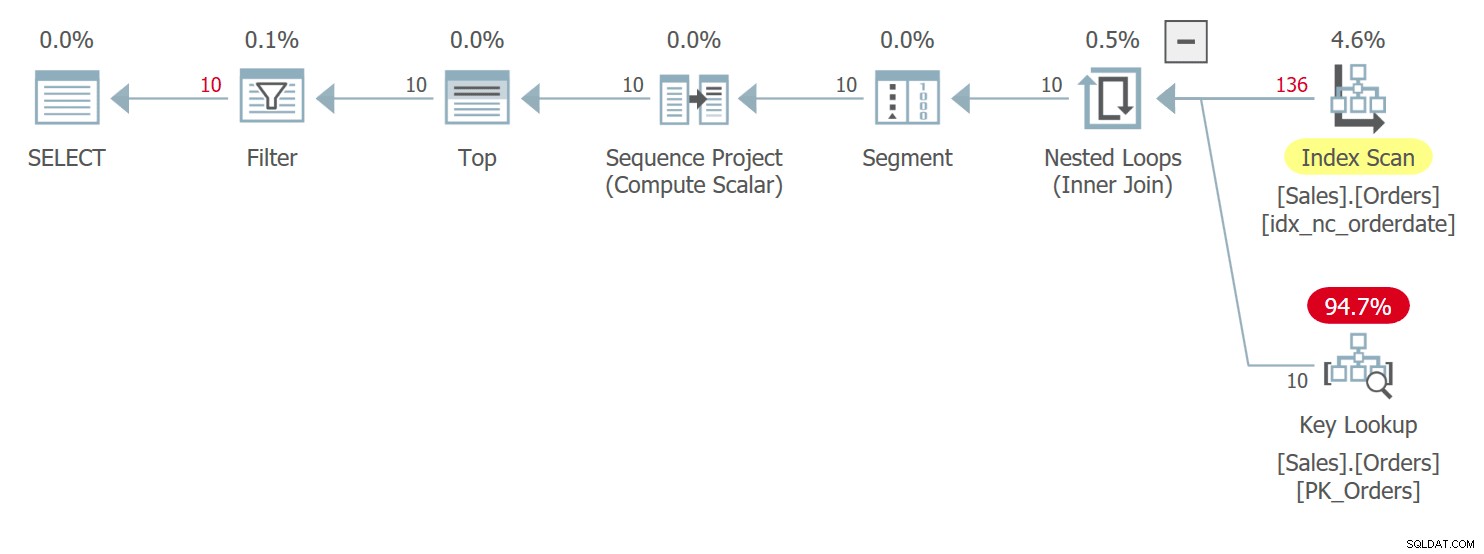
Gambar 3:Rencana kueri 3
Anda memiliki kondisi yang sangat mirip di sini dengan yang saya jelaskan sebelumnya untuk Kueri 1 dengan rencananya yang ditunjukkan sebelumnya pada Gambar 1. Di antara baris dengan ikatan dalam nilai tanggal pesanan, paket ini mengakses baris dengan nilai urutan yang lebih tinggi sebelum baris dengan nilai yang lebih rendah nilai urutan. Kueri ini menghasilkan keluaran berikut:
orderid orderdate custid ----------- ---------- ----------- 11077 2019-05-06 65 11076 2019-05- 06 9 11075 2019-05-06 68 11074 2019-05-06 73 11073 2019-05-05 58 11072 2019-05-05 20 11071 2019-05-05 46 11070 2019-05-05 44 11069 2019-05-04 80 *** 11068 05-04-2019 62
Selanjutnya jalankan query lagi (sebut saja Query 4), request halaman pertama, baru kali ini memaksa penggunaan clustered index PK_Orders:
WITH C AS ( SELECT orderid, orderdate, custid, ROW_NUMBER() OVER(ORDER BY orderdate DESC) AS n FROM Sales.Orders WITH (INDEX(PK_Orders)) ) SELECT orderid, orderdate, custid FROM C WHERE n BETWEEN 1 DAN 10;
Rencana untuk kueri ini ditunjukkan pada Gambar 4.

Gambar 4:Rencanakan kueri 4
Kali ini Anda memiliki kondisi yang sangat mirip dengan yang saya jelaskan sebelumnya untuk Kueri 2 dengan rencananya yang ditunjukkan sebelumnya pada Gambar 2. Di antara baris dengan ikatan dalam nilai tanggal pesanan, paket ini mengakses baris dengan nilai orderid yang lebih rendah sebelum baris dengan nilai nilai orderid yang lebih tinggi. Kueri ini menghasilkan keluaran berikut:
orderid orderdate custid ----------- ---------- ----------- 11074 2019-05-06 73 11075 2019-05- 06 68 11076 2019-05-06 9 11077 2019-05-06 65 11070 2019-05-05 44 11071 2019-05-05 46 11072 2019-05-05 20 11073 2019-05-05 58 11067 2019-05-04 17 *** 11068 2019-05-04 62
Amati bahwa kedua eksekusi menghasilkan hasil yang berbeda meskipun tidak ada perubahan pada data yang mendasarinya.
Sekali lagi, praktik terbaik di sini sederhana—gunakan urutan deterministik dengan menambahkan tiebreak, seperti:
WITH C AS ( SELECT orderid, orderdate, custid, ROW_NUMBER() OVER(ORDER BY orderdate DESC, orderid DESC) AS n FROM Sales.Orders ) SELECT orderid, orderdate, custid FROM C WHERE n BETWEEN 1 AND 10;Kueri ini menghasilkan keluaran berikut:
orderid orderdate custid ----------- ---------- ----------- 11077 2019-05-06 65 11076 2019-05- 06 9 11075 2019-05-06 68 11074 2019-05-06 73 11073 2019-05-05 58 11072 2019-05-05 20 11071 2019-05-05 46 11070 2019-05-05 44 11069 2019-05-04 80 11068 05-04-2019 62Set yang dikembalikan dijamin dapat diulang terlepas dari bentuk denahnya.
Mungkin perlu disebutkan bahwa karena kueri ini tidak memiliki urutan presentasi berdasarkan klausa di kueri luar, tidak ada urutan presentasi yang dijamin di sini. Jika Anda membutuhkan jaminan seperti itu, Anda harus menambahkan urutan presentasi dengan klausa, seperti:
WITH C AS ( SELECT orderid, orderdate, custid, ROW_NUMBER() OVER(ORDER BY orderdate DESC, orderid DESC) AS n FROM Sales.Orders ) SELECT orderid, orderdate, custid FROM C WHERE n BETWEEN 1 AND 10 ORDER BY n;Fungsi nondeterministik
Fungsi nondeterministik adalah fungsi yang diberi input yang sama, dapat mengembalikan hasil yang berbeda dalam eksekusi fungsi yang berbeda. Contoh klasik adalah SYSDATETIME, NEWID, dan RAND (ketika dipanggil tanpa seed input). Perilaku fungsi nondeterministik dalam T-SQL dapat mengejutkan bagi sebagian orang, dan dalam beberapa kasus dapat mengakibatkan bug dan perangkap.
Banyak orang berasumsi bahwa ketika Anda memanggil fungsi nondeterministik sebagai bagian dari kueri, fungsi tersebut dievaluasi secara terpisah per baris. Dalam praktiknya, sebagian besar fungsi nondeterministik dievaluasi satu kali per referensi dalam kueri. Pertimbangkan kueri berikut sebagai contoh:
SELECT orderid, SYSDATETIME() AS dt, RAND() AS rnd FROM Sales.Orders;Karena hanya ada satu referensi untuk masing-masing fungsi nondeterministik SYSDATETIME dan RAND dalam kueri, masing-masing fungsi ini dievaluasi hanya sekali, dan hasilnya diulang di semua baris hasil. Saya mendapatkan output berikut saat menjalankan kueri ini:
orderid dt rnd ----------- --------------------------- ------ ---------------- 11008 02-2019 17:03:07.9229177 0.962042872007464 11019 2019-02-04 17:03:07.9229177 0.962042872007464 11039 02-04-2017 17:03:07.9229177 0.962042872007464 11040 2019-02-04 17:03:07.9229177 0.962042872007464 11045 2019-02-04 17:03:07.9229177 0.962042872007464 11051 2019-02-04 17:03:07.9229177 0,962042874607464 11054 11058 2019-02-04 17:03:07.9229177 0.962042872007464 11059 2019-02-04 17:03:07.9229177 0.962042872007464 11061 2019-02-04 17:03:07.9229177 0.962042872007464 ...Sebagai contoh di mana tidak memahami perilaku ini dapat mengakibatkan bug, misalkan Anda perlu menulis kueri yang mengembalikan tiga pesanan acak dari tabel Sales.Orders. Upaya awal yang umum adalah menggunakan kueri TOP dengan pengurutan berdasarkan fungsi RAND, berpikir bahwa fungsi tersebut akan dievaluasi secara terpisah per baris, seperti:
SELECT TOP (3) orderid FROM Sales.Orders ORDER BY RAND();Dalam praktiknya, fungsi dievaluasi hanya sekali untuk seluruh kueri; oleh karena itu, semua baris mendapatkan hasil yang sama, dan pemesanan sama sekali tidak terpengaruh. Sebenarnya, jika Anda memeriksa paket untuk kueri ini, Anda tidak akan melihat operator Sortir. Ketika saya menjalankan kueri ini beberapa kali, saya terus mendapatkan hasil yang sama:
orderid ----------- 11008 11019 11039Kueri sebenarnya setara dengan kueri tanpa klausa ORDER BY, di mana urutan presentasi tidak dijamin. Jadi secara teknis pemesanannya tidak deterministik, dan eksekusi yang berbeda secara teoritis dapat menghasilkan urutan yang berbeda, dan karenanya dalam pemilihan 3 baris teratas yang berbeda. Namun, kemungkinannya rendah, dan Anda tidak dapat menganggap solusi ini menghasilkan tiga baris acak dalam setiap eksekusi.
Pengecualian untuk aturan bahwa fungsi nondeterministik dipanggil sekali per referensi dalam kueri adalah fungsi NEWID, yang mengembalikan pengidentifikasi unik global (GUID). Saat digunakan dalam kueri, fungsi ini adalah dipanggil secara terpisah per baris. Kueri berikut menunjukkan hal ini:
PILIH orderid, NEWID() AS mynewid FROM Sales.Orders;Kueri ini menghasilkan keluaran berikut:
orderid mynewid ----------- ---------------------------------- -- 11008 D6417542-C78A-4A2D-9517-7BB0FCF3B932 11019 E2E46BF1-4FA6-4EF2-8328-18B86259AD5D 11039 2917D923-AC60-44F5-92D7-FF84E52250CC 11040 B6287B49-DAE7-4C6C-98A8D7-F84E52250CC 11040 B6287B49-DAE7-4C6C-98A8D7 -0A27D1A0E186 11051 FA0B7B3E-BA41-4D80-8581-782EB88836C0 11054 1E6146BB-FEE7-4FF4-A4A2-3243AA2CBF78 11058 49302EA9-0243-4502-B9D2-46D751E6EFA9 110583B5BB7DCB261-3BD5BB7DCB2013ABD17 -564E1257F93E ...Nilai NEWID sendiri cukup acak. Jika Anda menerapkan fungsi CHECKSUM di atasnya, Anda mendapatkan hasil integer dengan distribusi acak yang lebih baik. Jadi salah satu cara untuk mendapatkan tiga pesanan acak adalah dengan menggunakan kueri TOP dengan pemesanan berdasarkan CHECKSUM(NEWID()), seperti:
SELECT TOP (3) orderid FROM Sales.Orders ORDER BY CHECKSUM(NEWID());Jalankan kueri ini berulang kali dan perhatikan bahwa Anda mendapatkan kumpulan tiga pesanan acak yang berbeda setiap kali. Saya mendapatkan output berikut dalam satu eksekusi:
orderid ----------- 11031 10330 10962Dan output berikut dalam eksekusi lain:
orderid ----------- 10308 10885 10444Selain NEWID, bagaimana jika Anda perlu menggunakan fungsi nondeterministik seperti SYSDATETIME dalam kueri, dan Anda memerlukannya untuk dievaluasi secara terpisah per baris? Salah satu cara untuk mencapai ini adalah dengan menggunakan fungsi yang ditentukan pengguna (UDF) yang memanggil fungsi nondeterministik, seperti:
MEMBUAT ATAU MENGUBAH FUNGSI dbo.MySysDateTime() MENGEMBALIKAN DATETIME2 SEBAGAI AWAL RETURN SYSDATETIME(); AKHIR; PERGIAnda kemudian memanggil UDF dalam kueri seperti itu (sebut saja Kueri 5):
PILIH orderid, dbo.MySysDateTime() AS mydt FROM Sales.Orders;UDF dieksekusi per baris kali ini. Namun, Anda perlu menyadari bahwa ada penalti kinerja yang cukup tajam terkait dengan eksekusi per baris UDF. Selain itu, menjalankan UDF T-SQL skalar adalah penghambat paralelisme.
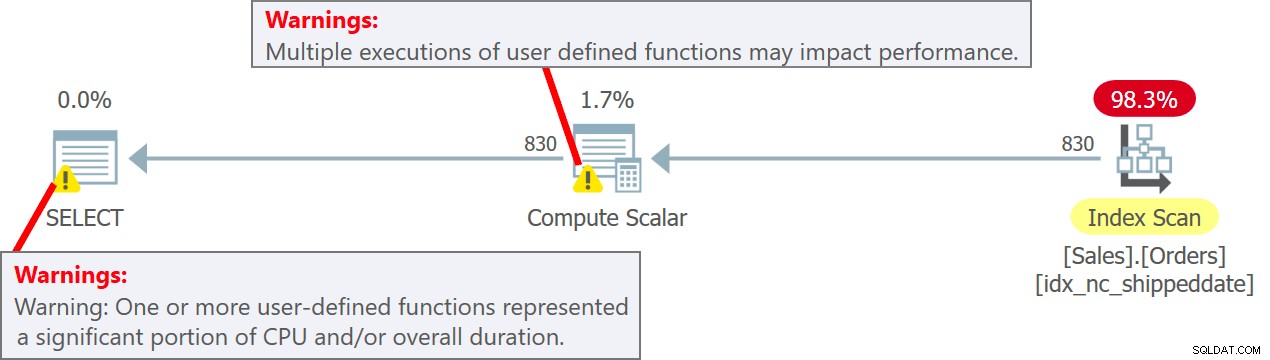
Rencana untuk kueri ini ditunjukkan pada Gambar 5.
Gambar 5:Rencanakan kueri 5Perhatikan dalam rencana bahwa memang UDF dipanggil per baris sumber di operator Hitung Skalar. Perhatikan juga bahwa SentryOne Plan Explorer memperingatkan Anda tentang potensi penalti kinerja yang terkait dengan penggunaan UDF baik di operator Compute Scalar maupun di node root paket.
Saya mendapatkan output berikut dari eksekusi kueri ini:
orderid mydt ----------- --------------------------- 11008 2019-02-04 17 :07:03.7221339 11019 02-04 2019 17:07:03.7221339 11039 02-04-2019 17:07:03.7221339 ... 10251 02-04 17:07:03.7231315 10255 02-2019 17:07:03.7231315 10248 2019-02-04 17:07:03,7231315 ... 10416 02-04 2019 17:07:03.7241304 10420 2019-02-04 17:07:03.7241304 10421 02-2019 17:07:03.7241304 .. .Perhatikan bahwa baris keluaran memiliki beberapa nilai tanggal dan waktu yang berbeda di kolom mydt.
Anda mungkin pernah mendengar bahwa SQL Server 2019 mengatasi masalah kinerja umum yang disebabkan oleh UDF T-SQL skalar dengan menyejajarkan fungsi tersebut. Namun, UDF harus memenuhi daftar persyaratan agar bisa inlineable. Salah satu persyaratannya adalah bahwa UDF tidak memanggil fungsi intrinsik nondeterministik seperti SYSDATETIME. Alasan untuk persyaratan ini adalah bahwa mungkin Anda membuat UDF persis untuk mendapatkan eksekusi per baris. Jika UDF dimasukkan, fungsi nondeterministik yang mendasarinya akan dieksekusi hanya sekali untuk seluruh kueri. Faktanya, paket pada Gambar 5 dibuat di SQL Server 2019, dan Anda dapat dengan jelas melihat bahwa UDF tidak dimasukkan. Itu karena penggunaan fungsi nondeterministik SYSDATETIME. Anda dapat memeriksa apakah UDF inlineable di SQL Server 2019 dengan menanyakan atribut is_inlineable di tampilan sys.sql_modules, seperti:
SELECT is_inlineable FROM sys.sql_modules WHERE object_id =OBJECT_ID(N'dbo.MySysDateTime');Kode ini menghasilkan output berikut yang memberi tahu Anda bahwa UDF MySysDateTime tidak inlineable:
is_inlineable ------------- 0Untuk mendemonstrasikan UDF yang tidak dapat disejajarkan, berikut adalah definisi UDF yang disebut EndOfyear yang menerima tanggal input dan mengembalikan tanggal akhir tahun masing-masing:
MEMBUAT ATAU MENGUBAH FUNGSI dbo.EndOfYear(@dt AS DATE) RETURNS DATE AS BEGIN RETURN DATEADD(year, DATEDIFF(year, '18991231', @dt), '18991231'); AKHIR; PERGITidak ada penggunaan fungsi nondeterministik di sini, dan kode juga memenuhi persyaratan lain untuk inlining. Anda dapat memverifikasi bahwa UDF tidak dapat disejajarkan dengan menggunakan kode berikut:
SELECT is_inlineable FROM sys.sql_modules WHERE object_id =OBJECT_ID(N'dbo.EndOfYear');Kode ini menghasilkan output berikut:
is_inlineable ------------- 1Kueri berikut (sebut saja Kueri 6) menggunakan UDF Akhir Tahun untuk memfilter pesanan yang dilakukan pada tanggal akhir tahun:
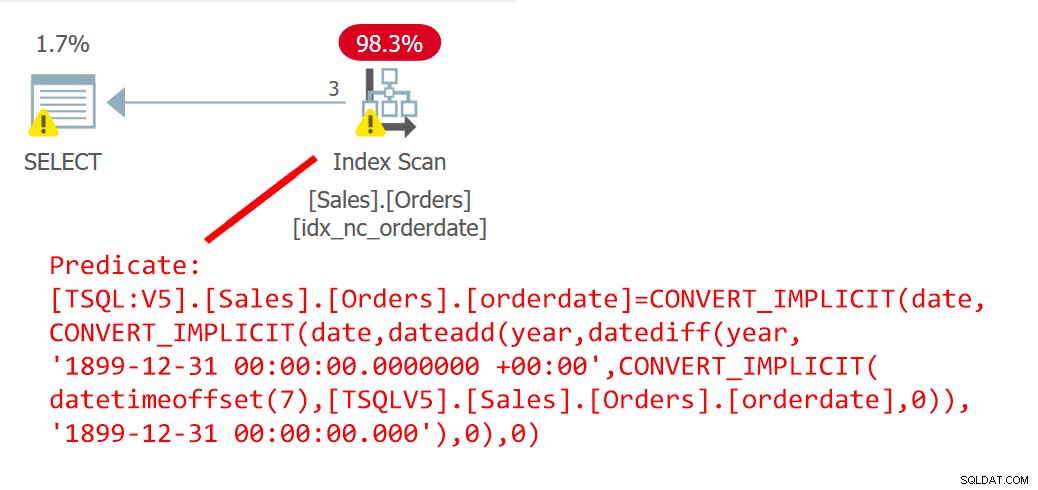
PILIH orderid FROM Sales.Orders WHERE orderdate =dbo.EndOfYear(orderdate);Rencana untuk kueri ini ditunjukkan pada Gambar 6.
Gambar 6:Rencana kueri 6Rencana tersebut dengan jelas menunjukkan bahwa UDF telah digariskan.
Ekspresi tabel, nondeterminisme, dan banyak referensi
Seperti disebutkan, fungsi nondeterministik seperti SYSDATETIME dipanggil sekali per referensi dalam kueri. Tetapi bagaimana jika Anda mereferensikan fungsi seperti itu sekali dalam kueri dalam ekspresi tabel seperti CTE, dan kemudian memiliki kueri luar dengan banyak referensi ke CTE? Banyak orang tidak menyadari bahwa setiap referensi ke ekspresi tabel diperluas secara terpisah, dan kode sebaris menghasilkan banyak referensi ke fungsi nondeterministik yang mendasarinya. Dengan fungsi seperti SYSDATETIME, tergantung pada waktu yang tepat dari setiap eksekusi, Anda bisa mendapatkan hasil yang berbeda untuk masing-masing eksekusi. Beberapa orang menganggap perilaku ini mengejutkan.
Hal ini dapat diilustrasikan dengan kode berikut:
MENYATAKAN @i SEBAGAI INT =1, @rc SEBAGAI INT =NULL; SAAT 1 =1 MULAI; DENGAN C1 AS ( SELECT SYSDATETIME() AS dt ), C2 AS ( SELECT dt FROM C1 UNION SELECT dt FROM C1 ) SELECT @rc =COUNT(*) FROM C2; JIKA @rc> 1 BREAK; SET @i +=1; AKHIR; PILIH @rc AS nilai yang berbeda, @i AS iterasi;Jika kedua referensi ke C1 dalam kueri di C2 mewakili hal yang sama, kode ini akan menghasilkan loop tak terbatas. Namun, karena dua referensi diperluas secara terpisah, ketika waktunya sedemikian rupa sehingga setiap pemanggilan dilakukan dalam interval 100 nanodetik yang berbeda (ketepatan nilai hasil), gabungan menghasilkan dua baris, dan kode harus terputus dari lingkaran. Jalankan kode ini dan lihat sendiri. Memang, setelah beberapa iterasi itu rusak. Saya mendapatkan hasil berikut di salah satu eksekusi:
iterasi nilai yang berbeda -------------- ----------- 2 448Praktik terbaik adalah menghindari penggunaan ekspresi tabel seperti CTE dan tampilan, saat kueri dalam menggunakan perhitungan nondeterministik dan kueri luar merujuk ke ekspresi tabel beberapa kali. Itu tentu saja kecuali Anda memahami implikasinya dan Anda setuju dengan mereka. Opsi alternatif dapat berupa mempertahankan hasil kueri dalam, misalnya dalam tabel sementara, lalu mengkueri tabel sementara beberapa kali yang Anda perlukan.
Untuk mendemonstrasikan contoh di mana tidak mengikuti praktik terbaik dapat membuat Anda mendapat masalah, misalkan Anda perlu menulis kueri yang memasangkan karyawan dari tabel HR.Employees secara acak. Anda membuat kueri berikut (sebut saja kueri 7) untuk menangani tugas:
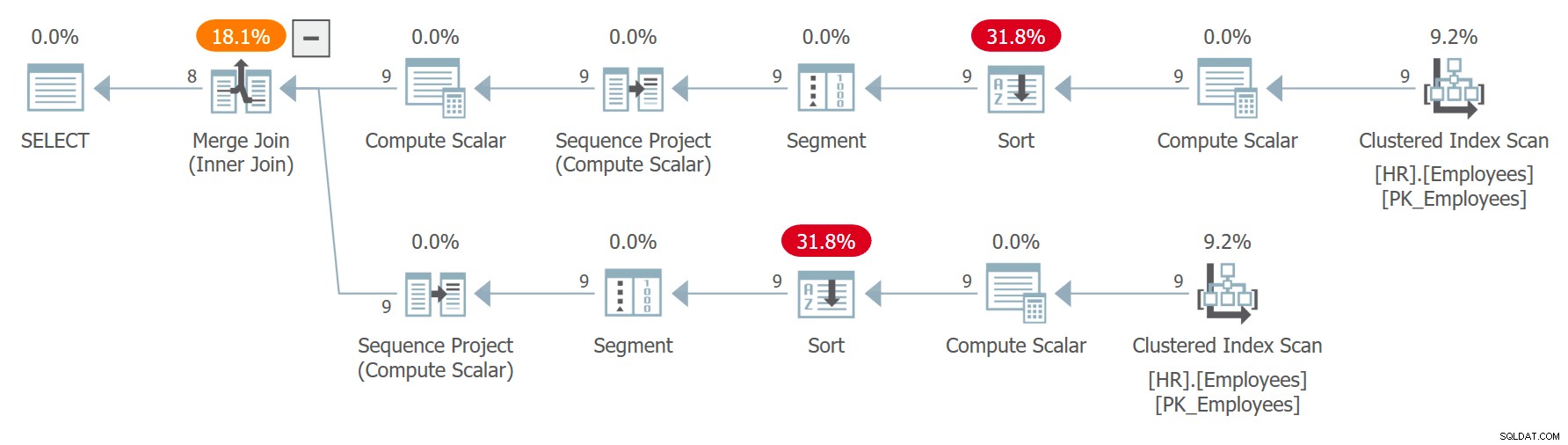
WITH C AS ( SELECT empid, firstname, lastname, ROW_NUMBER() OVER(ORDER BY CHECKSUM(NEWID())) AS n FROM HR.Employees ) SELECT C1.empid AS empid1, C1.firstname AS firstname1, C1. lastname AS lastname1, C2.empid AS empid2, C2.firstname AS firstname2, C2.lastname AS lastname2 DARI C AS C1 INNER GABUNG C AS C2 PADA C1.n =C2.n + 1;Rencana untuk kueri ini ditunjukkan pada Gambar 7.
Gambar 7:Rencana untuk Kueri 7Perhatikan bahwa dua referensi ke C diperluas secara terpisah, dan nomor baris dihitung secara independen untuk setiap referensi yang diurutkan oleh pemanggilan independen dari ekspresi CHECKSUM(NEWID()). Ini berarti bahwa karyawan yang sama tidak dijamin mendapatkan nomor baris yang sama dalam dua referensi yang diperluas. Jika seorang karyawan mendapat nomor baris x di C1 dan nomor baris x – 1 di C2, kueri akan memasangkan karyawan itu dengan dirinya sendiri. Misalnya, saya mendapatkan hasil berikut di salah satu eksekusi:
empid1 nama depan1 nama belakang1 empid2 nama depan2 nama belakang2 ----------- ---------- -------------------- ----------- ---------- -------------------- 3 Judy Lew 6 Paul Suurs 9 Patricia Doyle *** 9 Patricia Doyle *** 5 Sven Mortensen 4 Yael Peled 6 Paul Suurs 8 Maria Cameron 8 Maria Cameron 5 Sven Mortensen 2 Don Funk *** 2 Don Funk *** 4 Yael Peled 3 Judy Lew 7 Russell King ** * 7 Russell King ***Perhatikan bahwa ada tiga kasus di sini dari pasangan-diri. Ini lebih mudah dilihat dengan menambahkan filter ke kueri luar yang secara khusus mencari pasangan mandiri, seperti:
WITH C AS ( SELECT empid, firstname, lastname, ROW_NUMBER() OVER(ORDER BY CHECKSUM(NEWID())) AS n FROM HR.Employees ) SELECT C1.empid AS empid1, C1.firstname AS firstname1, C1. lastname AS lastname1, C2.empid AS empid2, C2.firstname AS firstname2, C2.lastname AS lastname2 DARI C AS C1 INNER GABUNG C AS C2 PADA C1.n =C2.n + 1 WHERE C1.empid =C2.empid;Anda mungkin perlu menjalankan kueri ini beberapa kali untuk melihat masalahnya. Berikut ini contoh hasil yang saya dapatkan di salah satu eksekusi:
empid1 nama depan1 nama belakang1 empid2 nama depan2 nama belakang2 ----------- ---------- -------------------- ----------- ---------- -------------------- 5 Sven Mortensen 5 Sven Mortensen 2 Don Funk 2 Don FunkMengikuti praktik terbaik, salah satu cara untuk memecahkan masalah ini adalah dengan mempertahankan hasil kueri dalam di tabel sementara dan kemudian kueri beberapa contoh tabel sementara sesuai kebutuhan.
Contoh lain mengilustrasikan bug yang dapat dihasilkan dari penggunaan urutan nondeterministik dan banyak referensi ke ekspresi tabel. Misalkan Anda perlu membuat kueri tabel Sales.Orders dan untuk melakukan analisis tren, Anda ingin memasangkan setiap pesanan dengan pesanan berikutnya berdasarkan pemesanan tanggal. Solusi Anda harus kompatibel dengan sistem pra-SQL Server 2012 yang berarti Anda tidak dapat menggunakan fungsi LAG/LEAD yang jelas. Anda memutuskan untuk menggunakan CTE yang menghitung nomor baris untuk memposisikan baris berdasarkan urutan tanggal pesanan, dan kemudian menggabungkan dua contoh CTE, memasangkan pesanan berdasarkan offset 1 di antara nomor baris, seperti ini (sebut ini Kueri 8):
DENGAN C AS ( SELECT *, ROW_NUMBER() OVER(ORDER BY orderdate DESC) AS n FROM Sales.Orders ) PILIH C1.orderid AS orderid1, C1.orderdate AS orderdate1, C1.custid AS custid1, C2.orderid AS orderid2, C2.orderdate AS orderdate2 DARI C SEBAGAI C1 KIRI LUAR GABUNG C SEBAGAI C2 PADA C1.n =C2.n + 1;Rencana untuk kueri ini ditunjukkan pada Gambar 8.
Gambar 8:Rencanakan untuk Kueri 8
Urutan nomor baris tidak deterministik karena tanggal pemesanan tidak unik. Perhatikan bahwa dua referensi ke CTE diperluas secara terpisah. Anehnya, karena kueri mencari subset kolom yang berbeda dari setiap instance, pengoptimal memutuskan untuk menggunakan indeks yang berbeda dalam setiap kasus. Dalam satu kasus, ia menggunakan pemindaian indeks ke belakang yang dipesan pada tanggal pemesanan, secara efektif memindai baris dengan tanggal yang sama berdasarkan urutan urutan menurun. Dalam kasus lain ia memindai indeks berkerumun, memesan salah dan kemudian mengurutkan, tetapi secara efektif di antara baris dengan tanggal yang sama, ia mengakses baris dalam urutan menaik. Itu karena alasan serupa yang saya berikan di bagian tentang urutan nondeterministik sebelumnya. Ini dapat mengakibatkan baris yang sama mendapatkan nomor baris x dalam satu contoh dan nomor baris x – 1 dalam contoh lainnya. Dalam kasus seperti itu, gabungan akan berakhir dengan mencocokkan pesanan dengan dirinya sendiri alih-alih dengan yang berikutnya seperti yang seharusnya.
Saya mendapatkan hasil berikut saat menjalankan kueri ini:
orderid1 orderdate1 custid1 orderid2 orderdate2 ----------- ---------- ----------- ---------- - ---------- 11074 2019-05-06 73 NULL NULL 11075 2019-05-06 68 11077 2019-05-06 11076 2019-05-06 9 11076 2019-05-06 *** 11077 2019-05-06 65 11075 2019-05-06 11070 2019-05-05 44 11074 2019-05-06 11071 2019-05-05 46 11073 2019-05-05 11072 2019-05-05 20 11072 2019-05- 05*** ...Amati kecocokan diri dalam hasilnya. Sekali lagi, masalahnya dapat lebih mudah diidentifikasi dengan menambahkan filter yang mencari kecocokan sendiri, seperti:
DENGAN C AS ( SELECT *, ROW_NUMBER() OVER(ORDER BY orderdate DESC) AS n FROM Sales.Orders ) PILIH C1.orderid AS orderid1, C1.orderdate AS orderdate1, C1.custid AS custid1, C2.orderid AS orderid2, C2.orderdate AS orderdate2 DARI C AS C1 KIRI LUAR GABUNG C AS C2 PADA C1.n =C2.n + 1 WHERE C1.orderid =C2.orderid;Saya mendapat output berikut dari kueri ini:
orderid1 orderdate1 custid1 orderid2 orderdate2 ----------- ---------- ----------- ---------- - ---------- 11076 2019-05-06 9 11076 2019-05-06 11072 2019-05-05 20 11072 2019-05-05 11062 2019-04-30 66 11062 2019-04-30 11052 2019-04-27 34 11052 2019-04-27 11042 2019-04-22 15 11042 2019-04-22 ...Praktik terbaik di sini adalah memastikan bahwa Anda menggunakan urutan unik untuk menjamin determinisme dengan menambahkan tiebreaker seperti orderid ke klausa urutan jendela. Jadi meskipun Anda memiliki banyak referensi ke CTE yang sama, nomor baris akan sama di keduanya. Jika Anda ingin menghindari pengulangan penghitungan, Anda juga dapat mempertimbangkan untuk mempertahankan hasil kueri dalam, tetapi Anda perlu mempertimbangkan biaya tambahan untuk pekerjaan tersebut.
CASE/NULLIF dan fungsi nondeterministik
Saat Anda memiliki beberapa referensi ke fungsi nondeterministik dalam kueri, setiap referensi dievaluasi secara terpisah. Apa yang bisa mengejutkan dan bahkan menghasilkan bug adalah terkadang Anda menulis satu referensi, tetapi secara implisit diubah menjadi beberapa referensi. Begitulah situasi dengan beberapa penggunaan ekspresi CASE dan fungsi IIF.
Perhatikan contoh berikut:
SELECT CASE ABS(CHECKSUM(NEWID())) % 2 WHEN 0 THEN 'Even' WHEN 1 THEN 'GANAL' END;Di sini hasil dari ekspresi yang diuji adalah nilai bilangan bulat nonnegatif, jadi jelas itu harus genap atau ganjil. Itu tidak boleh genap atau ganjil. However, if you run this code enough times, you will sometimes get a NULL indicating that the implied ELSE NULL clause of the CASE expression was activated. The reason for this is that the above expression translates to the following:
SELECT CASE WHEN ABS(CHECKSUM(NEWID())) % 2 =0 THEN 'Even' WHEN ABS(CHECKSUM(NEWID())) % 2 =1 THEN 'Odd' ELSE NULL END;In the converted expression there are two separate references to the tested expression that generates a random nonnegative value, and each gets evaluated separately. One possible path is that the first evaluation produces an odd number, the second produces an even number, and then the ELSE NULL clause is activated.
Here’s a very similar situation with the NULLIF function:
SELECT NULLIF(ABS(CHECKSUM(NEWID())) % 2, 0);This expression generates a random nonnegative value, and is supposed to return 1 when it’s odd, and NULL otherwise. It’s never supposed to return 0 since in such a case the 0 is supposed to be replaced with a NULL. Run it a few times and you will see that in some cases you get a 0. The reason for this is that the above expression internally translates to the following one:
SELECT CASE WHEN ABS(CHECKSUM(NEWID())) % 2 =0 THEN NULL ELSE ABS(CHECKSUM(NEWID())) % 2 END;A possible path is that the first WHEN clause generates a random odd value, so the ELSE clause is activated, and the ELSE clause generates a random even value so the % 2 calculation results in a 0.
In both cases this behavior is standard, so the bug is more in the eyes of the beholder based on your expectations and your choice of how to write the code. The best practice in both cases is to persist the result of the original calculation and then interact with the persisted result. If it’s a single value, store the result in a variable first. If you’re querying tables, first persist the result of the nondeterministic calculation in a column in a temporary table, and then apply the CASE/IIF logic in the query against the temporary table.
Kesimpulan
This article is the first in a series about T-SQL bugs, pitfalls and best practices, and is the result of discussions with fellow Microsoft Data Platform MVPs who shared their experiences. This time I focused on bugs and pitfalls that resulted from using nondeterministic order and nondeterministic calculations. In future articles I’ll continue with other themes. If you have bugs and pitfalls that you often stumble into, or that you find as particularly interesting, please do share!