Pada artikel sebelumnya kita telah membahas model skema bintang. Skema kepingan salju berada di sebelah skema bintang dalam hal pentingnya dalam pemodelan data warehouse. Ini dikembangkan dari skema bintang, dan menawarkan beberapa keunggulan dibandingkan pendahulunya. Tapi keuntungan ini datang dengan biaya. Dalam artikel ini, kita akan membahas kapan dan bagaimana menggunakan skema kepingan salju.
Skema Kepingan Salju
Nama skema kepingan salju berasal dari fakta bahwa tabel dimensi bercabang dan terlihat seperti kepingan salju. Ketika kita melihat model di atas, kita akan melihat itu adalah tabel fakta yang dikelilingi oleh beberapa tabel dimensi, beberapa di antaranya melakukan percabangan yang disebutkan di atas. Berbeda dengan skema bintang, tabel dimensi dalam skema kepingan salju dapat memiliki kategorinya sendiri.
Ide yang berkuasa di balik skema kepingan salju adalah bahwa tabel dimensi sepenuhnya dinormalisasi. Setiap tabel dimensi dapat dijelaskan oleh satu atau lebih tabel pencarian. Setiap tabel pencarian dapat dijelaskan dengan satu atau beberapa tabel pencarian tambahan. Ini diulang sampai model sepenuhnya dinormalisasi. Proses normalisasi tabel dimensi skema bintang disebut snowflaking.
Anda akan mendengar banyak tentang normalisasi di artikel ini. Apa itu normalisasi? Pada dasarnya, ini mengatur database dengan cara yang meminimalkan redundansi dan melindungi integritas data. Lihat postingan ini untuk mempelajari lebih lanjut tentang normalisasi dan denormalisasi.
Contoh Skema Kepingan Salju:Model Penjualan
Sebelumnya, kami menggunakan skema bintang untuk memodelkan departemen penjualan fiktif – ini akan mirip dengan data mart yang digunakan untuk melacak aktivitas dan hasil penjualan. Model memiliki lima dimensi:produk , waktu , toko , penjualan ketik dan karyawan . Dalam fact_sales meja, harga dan jumlah disimpan dan dikelompokkan berdasarkan nilai dalam tabel dimensi. Untuk penyegaran, lihat model penjualan skema bintang di bawah ini:
Berikut adalah model yang sama yang diatur sebagai skema kepingan salju:
dim_employee dan dim_sales_type tabel dimensi sama persis dengan model skema bintang karena sudah dinormalisasi.
Di sisi lain, kami menerapkan aturan normalisasi ke tabel dimensi lainnya.


dim_product tabel dimensi dari skema bintang dibagi menjadi dua tabel dalam model kepingan salju. dim_product_type tabel telah ditambahkan untuk merujuk pada jenis pencocokan di dim_product meja. Dengan menggunakan ini, kami menghindari beberapa masalah integritas data.
Masuk akal untuk mengasumsikan bahwa kita sudah memiliki semua nama produk dan jenis terkait yang dimasukkan sebagai bagian dari proses ETL, tetapi anggaplah kita perlu menambahkan lebih banyak nama dan jenis produk. Dalam skema bintang, kita bisa salah memasukkan jenis produk yang salah ke dalam tabel. Dalam skema kepingan salju:
- Jika kami menemukan nama jenis produk baru, kami dapat menambahkan jenis produk baru dan kemudian menghubungkan jenis itu ke catatan yang baru ditambahkan. Namun, hal ini dapat mengakibatkan pengguna memasukkan informasi yang salah, seperti pada skema bintang.
- Kami dapat memeriksa apakah nama produk yang ingin kami tambahkan sudah ada. Jika demikian, kita bisa mendapatkan ID-nya; jika tidak, akan muncul peringatan yang menanyakan apakah kami ingin menambahkan produk baru dan jenis terkait.

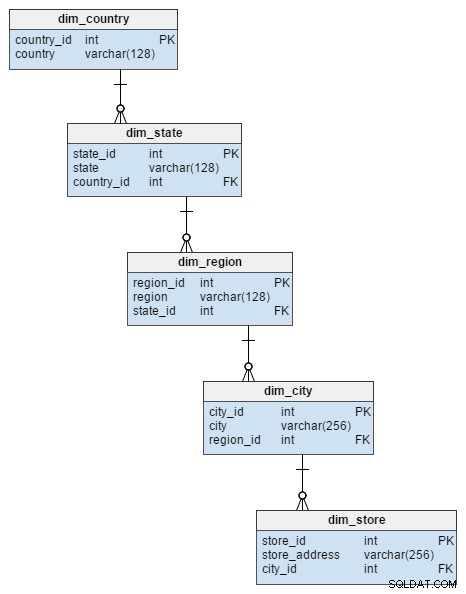
dim_store tabel dimensi dari skema bintang diwakili oleh 5 tabel dalam skema kepingan salju. Ini membagi atribut kota, wilayah, negara bagian, dan negara yang disimpan di dim_store meja. Menormalkan tabel ini tidak hanya menghindari risiko integritas data, tetapi juga menghemat beberapa ruang disk.
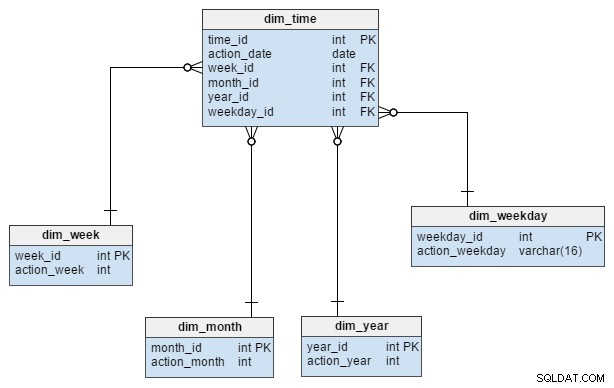
dim_time dimensi diwakili dengan lima tabel. Kita bisa memikirkan dim_week , dim_month , dim_year dan dim_weekday tabel sebagai kamus yang menjelaskan dim_time meja.
dim_week , dim_month , dim_year dan dim_weekday tabel adalah empat hierarki berbeda yang digunakan untuk menggambarkan dimensi waktu kita. Kami dapat menambahkan lebih banyak dimensi seperti perempat atau tabel terkait lainnya jika kami membutuhkannya. Dalam contoh ini, dim_month adalah kamus yang berisi 12 bulan; dari dimensi ini saja, kita tidak memiliki cara untuk mengetahui tahun mana bulan itu berada; itulah fungsi dari dim_year meja.
Contoh Skema Kepingan Salju:Model Pesanan Pasokan
Data mart lain yang kami diskusikan adalah untuk pesanan pasokan. Idenya adalah untuk menyimpan dan menggabungkan semua data pesanan pasokan untuk empat dimensi berikut:produk , waktu , pemasok dan karyawan . Sekali lagi, kita akan melihat skema bintang yang relevan:
Mengubahnya menjadi skema kepingan salju, kita mendapatkan model berikut:
Aturan normalisasi yang sama seperti yang dijelaskan untuk model penjualan digunakan pada dim_product , dim_time dan dim_supplier tabel dimensi.
Keuntungan dan Kerugian Skema Kepingan Salju
Ada dua keuntungan utama ke skema kepingan salju:
- Kualitas data lebih baik (data lebih terstruktur, sehingga masalah integritas data berkurang)
- Lebih sedikit ruang disk yang digunakan dibandingkan dengan model yang didenormalisasi
Kerugian yang paling menonjol untuk model kepingan salju adalah membutuhkan kueri yang lebih kompleks. Kueri ini, dengan peningkatan jumlah gabungan, dapat menurunkan kinerja secara signifikan.
Kami akan menulis ulang kueri yang sama yang digunakan dalam artikel skema bintang untuk model penjualan skema kepingan salju. Berikut kueri yang diperlukan untuk mengembalikan jumlah semua jenis produk tipe ponsel yang dijual di toko Berlin pada tahun 2016:
SELECT dim_store.store_address, SUM(fact_sales.quantity) AS quantity_sold FROM fact_sales INNER JOIN dim_product ON fact_sales.product_id = dim_product.product_id INNER JOIN dim_product_type ON dim_product.product_type_id = dim_product_type.product_type_id INNER JOIN dim_time ON fact_sales.time_id = dim_time.time_id INNER JOIN dim_year ON dim_time.year_id = dim_year.year_id INNER JOIN dim_store ON fact_sales.store_id = dim_store.store_id INNER JOIN dim_city ON dim_store.city_id = dim_city.city_id WHERE dim_year.action_year = 2016 AND dim_city.city = 'Berlin' AND dim_product_type.product_type_name = 'phone' GROUP BY dim_store.store_id, dim_store.store_address
Skema Starflake
Skema starflake adalah kombinasi dari skema kepingan salju dan bintang. Kita dapat melihatnya sebagai skema kepingan salju yang memiliki beberapa tabel dimensi yang didenormalisasi. Ketika digunakan dengan benar, skema starflake dapat memberikan pendekatan terbaik dari kedua dunia. Jelas, bagian kepingan salju dari model harus menghemat ruang disk, sedangkan bagian bintang harus meningkatkan kinerja.
Model di atas pada dasarnya adalah model kepingan salju dengan dim_time meja. Karena skema ini mengurangi jumlah gabungan kueri yang diperlukan, skema ini dapat meningkatkan kinerja. Di sisi lain, kami tidak akan kehilangan banyak ruang disk, karena sebagian besar atribut tabel dan atribut kunci asing berbagi int ketik.
Skema Galaksi
Dalam pergudangan data, skema galaksi adalah ketika dua atau lebih tabel fakta berbagi satu atau lebih tabel dimensi. Salah satu alasan untuk menggunakan skema ini adalah untuk menghemat ruang disk. Kami telah membuat contoh skema galaksi di bawah ini:
Di sini, kami memiliki dua tabel fakta, fact_sales dan fact_supply_order , yang secara langsung berbagi tabel tiga dimensi:dim_product , dim_employee dan dim_time . Perhatikan bahwa bahkan dim_store dan dim_supplier berbagi tabel pencarian yang sama, dim_city .
Kami akan menghemat ruang dengan cara ini, tetapi kami harus memikirkan beberapa hal sebelum menggabungkan dua data mart (dalam hal ini, pesanan penjualan dan pasokan) ke dalam satu skema galaksi:
- Apakah ada logika di balik bergabung dengan mereka? Misalnya Apakah kedua data mart akan digunakan oleh departemen yang sama?
- Apakah kami yakin bahwa kami membutuhkan dimensi dan granulasi yang persis sama untuk kedua data mart?
Skema kepingan salju sering digunakan dalam pemodelan data. Ini mungkin pilihan yang tepat dalam situasi di mana ruang disk lebih penting daripada kinerja. Jika kita menginginkan keseimbangan antara penghematan ruang dan kinerja, kita dapat menggunakan skema starflake. Namun, kecocokan yang tepat untuk masalah spesifik apa pun bergantung pada banyak parameter. Ini adalah salah satu area di TI di mana kita bisa 'bermain' dengan faktor-faktor untuk menghasilkan solusi terbaik.