Bucketizing data tanggal dan waktu melibatkan pengorganisasian data dalam kelompok yang mewakili interval waktu tetap untuk tujuan analitis. Seringkali inputnya adalah data deret waktu yang disimpan dalam tabel di mana baris mewakili pengukuran yang dilakukan pada interval waktu reguler. Misalnya, pengukuran dapat berupa pembacaan suhu dan kelembaban yang dilakukan setiap 5 menit, dan Anda ingin mengelompokkan data menggunakan ember per jam dan menghitung agregat seperti rata-rata per jam. Meskipun data deret waktu adalah sumber umum untuk analisis berbasis ember, konsepnya sama relevannya dengan data apa pun yang melibatkan atribut tanggal dan waktu serta ukuran terkait. Misalnya, Anda mungkin ingin mengatur data penjualan dalam keranjang tahun fiskal dan menghitung agregat seperti total nilai penjualan per tahun fiskal. Pada artikel ini, saya membahas dua metode untuk mengelompokkan data tanggal dan waktu. Salah satunya menggunakan fungsi yang disebut DATE_BUCKET, yang pada saat penulisan ini hanya tersedia di Azure SQL Edge. Cara lainnya adalah menggunakan penghitungan kustom yang mengemulasi fungsi DATE_BUCKET, yang dapat Anda gunakan dalam versi, edisi, dan ragam apa pun dari SQL Server dan Azure SQL Database.
Dalam contoh saya, saya akan menggunakan database sampel TSQLV5. Anda dapat menemukan skrip yang membuat dan mengisi TSQLV5 di sini dan diagram ER-nya di sini.
DATE_BUCKET
Seperti yang disebutkan, fungsi DATE_BUCKET saat ini hanya tersedia di Azure SQL Edge. SQL Server Management Studio sudah memiliki dukungan IntelliSense, seperti yang ditunjukkan pada Gambar 1:
 Gambar 1:Dukungan kecerdasan untuk DATE_BUCKET di SSMS
Gambar 1:Dukungan kecerdasan untuk DATE_BUCKET di SSMS
Sintaks fungsinya adalah sebagai berikut:
DATE_BUCKET (Masukan asal mewakili titik jangkar pada panah waktu. Itu bisa dari salah satu tipe data tanggal dan waktu yang didukung. Jika tidak ditentukan, defaultnya adalah 1900, 1 Januari, tengah malam. Anda kemudian dapat membayangkan garis waktu dibagi menjadi interval diskrit yang dimulai dengan titik asal, di mana panjang setiap interval didasarkan pada lebar bucket input dan bagian tanggal . Yang pertama adalah kuantitas dan yang terakhir adalah satuannya. Misalnya, untuk mengatur garis waktu dalam unit 2 bulan, Anda akan menentukan 2 sebagai lebar bucket masukan dan bulan sebagai bagian tanggal masukan.
Masukan stempel waktu adalah titik waktu sewenang-wenang yang perlu dikaitkan dengan ember yang berisi. Tipe datanya harus cocok dengan tipe data input asal . Masukan stempel waktu adalah nilai tanggal dan waktu yang terkait dengan pengukuran yang Anda ambil.
Output dari fungsi tersebut kemudian menjadi titik awal dari bucket yang berisi. Tipe data dari output adalah input timestamp .
Jika belum jelas, biasanya Anda akan menggunakan fungsi DATE_BUCKET sebagai elemen kumpulan pengelompokan dalam klausa GROUP BY kueri dan secara alami mengembalikannya ke daftar SELECT juga, bersama dengan ukuran agregat.
Masih agak bingung dengan fungsi, input, dan outputnya? Mungkin contoh spesifik dengan penggambaran visual dari logika fungsi akan membantu. Saya akan mulai dengan contoh yang menggunakan variabel input dan kemudian dalam artikel ini menunjukkan cara yang lebih umum Anda akan menggunakannya sebagai bagian dari kueri terhadap tabel input.
Perhatikan contoh berikut:
DECLARE @timestamp AS DATETIME2 = '20210510 06:30:00', @bucketwidth AS INT = 2, @origin AS DATETIME2 = '20210115 00:00:00'; SELECT DATE_BUCKET(month, @bucketwidth, @timestamp, @origin);
Anda dapat menemukan penggambaran visual dari logika fungsi pada Gambar 2.
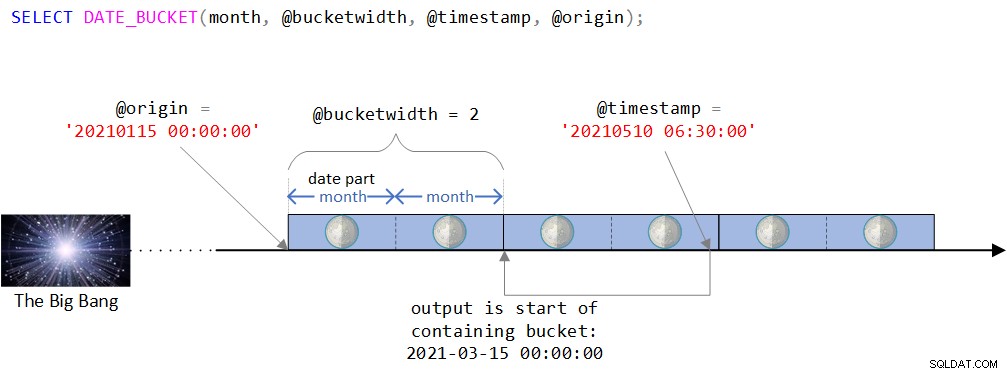 Gambar 2:Penggambaran visual logika fungsi DATE_BUCKET
Gambar 2:Penggambaran visual logika fungsi DATE_BUCKET
Seperti yang Anda lihat pada Gambar 2, titik asal adalah nilai DATETIME2 15 Januari 2021, tengah malam. Jika titik asal ini tampak agak aneh, Anda akan benar dalam merasakan secara intuitif bahwa biasanya Anda akan menggunakan yang lebih alami seperti awal tahun, atau awal suatu hari. Bahkan, Anda sering puas dengan default, yang seingat Anda adalah 1 Januari 1900 di tengah malam. Saya sengaja ingin menggunakan titik asal yang tidak terlalu sepele untuk dapat mendiskusikan kerumitan tertentu yang mungkin tidak relevan saat menggunakan yang lebih alami. Lebih lanjut tentang ini segera.
Garis waktu kemudian dibagi menjadi interval 2 bulan diskrit dimulai dengan titik asal. Stempel waktu masukan adalah nilai DATETIME2 10 Mei 2021, 06.30.
Perhatikan bahwa stempel waktu masukan adalah bagian dari ember yang dimulai pada 15 Maret 2021, tengah malam. Memang, fungsi mengembalikan nilai ini sebagai nilai yang diketik DATETIME2:
--------------------------- 2021-03-15 00:00:00.0000000
Meniru DATE_BUCKET
Kecuali Anda menggunakan Azure SQL Edge, jika Anda ingin mengelompokkan data tanggal dan waktu, untuk saat ini Anda perlu membuat solusi kustom Anda sendiri untuk meniru fungsi DATE_BUCKET. Melakukannya tidak terlalu rumit, tetapi juga tidak terlalu sederhana. Berurusan dengan data tanggal dan waktu sering kali melibatkan logika rumit dan jebakan yang perlu Anda waspadai.
Saya akan membuat perhitungan dalam langkah-langkah dan menggunakan input yang sama yang saya gunakan dengan contoh DATE_BUCKET yang saya tunjukkan sebelumnya:
DECLARE @timestamp AS DATETIME2 = '20210510 06:30:00', @bucketwidth AS INT = 2, @origin AS DATETIME2 = '20210115 00:00:00';
Pastikan Anda menyertakan bagian ini sebelum setiap contoh kode yang akan saya tunjukkan jika Anda benar-benar ingin menjalankan kode.
Pada Langkah 1, Anda menggunakan fungsi DATEDIFF untuk menghitung perbedaan bagian tanggal unit antara asal dan stempel waktu . Saya akan menyebut perbedaan ini sebagai diff1 . Ini dilakukan dengan kode berikut:
SELECT DATEDIFF(month, @origin, @timestamp) AS diff1;
Dengan input sampel kami, ekspresi ini mengembalikan 4.
Bagian yang sulit di sini adalah Anda perlu menghitung berapa banyak seluruh unit bagian tanggal ada di antara asal dan stempel waktu . Dengan input sampel kami, ada 3 bulan penuh antara keduanya dan bukan 4. Alasan fungsi DATEDIFF melaporkan 4 adalah bahwa, ketika menghitung perbedaan, ia hanya melihat bagian input yang diminta dan bagian yang lebih tinggi tetapi bukan bagian yang lebih rendah . Jadi, ketika Anda menanyakan perbedaan bulan, fungsi tersebut hanya peduli pada bagian tahun dan bulan dari input dan bukan tentang bagian di bawah bulan (hari, jam, menit, detik, dll.). Memang, ada 4 bulan antara Januari 2021 dan Mei 2021, namun hanya 3 bulan penuh antara input penuh.
Tujuan dari Langkah 2 adalah untuk menghitung berapa banyak seluruh unit bagian tanggal ada di antara asal dan stempel waktu . Saya akan menyebut perbedaan ini sebagai diff2 . Untuk mencapai ini, Anda dapat menambahkan diff1 unit bagian tanggal ke asal . Jika hasilnya lebih besar dari stempel waktu , Anda mengurangi 1 dari diff1 untuk menghitung diff2 , jika tidak, kurangi 0 dan gunakan diff1 sebagai diff2 . Ini dapat dilakukan dengan menggunakan ekspresi CASE, seperti:
SELECT
DATEDIFF(month, @origin, @timestamp)
- CASE
WHEN DATEADD(
month,
DATEDIFF(month, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END AS diff2; Ekspresi ini mengembalikan 3, yang merupakan jumlah bulan penuh antara dua input.
Ingatlah bahwa sebelumnya saya menyebutkan bahwa dalam contoh saya, saya sengaja menggunakan titik asal yang tidak alami seperti putaran awal periode sehingga saya dapat mendiskusikan kerumitan tertentu yang kemudian mungkin relevan. Misalnya, jika Anda menggunakan bulan sebagai bagian tanggal, dan awal yang tepat dari beberapa bulan (1 bulan di tengah malam) sebagai asal, Anda dapat dengan aman melewati Langkah 2 dan menggunakan diff1 sebagai diff2 . Itu karena asal + diff1 tidak pernah bisa> stempel waktu dalam kasus seperti itu. Namun, tujuan saya adalah memberikan alternatif yang setara secara logis untuk fungsi DATE_BUCKET yang akan berfungsi dengan benar untuk titik Asal mana pun, umum atau tidak. Jadi, saya akan menyertakan logika untuk Langkah 2 dalam contoh saya, tetapi ingatlah ketika Anda mengidentifikasi kasus di mana langkah ini tidak relevan, Anda dapat dengan aman menghapus bagian di mana Anda mengurangi output dari ekspresi CASE.
Pada Langkah 3 Anda mengidentifikasi berapa banyak unit bagian tanggal ada di seluruh ember yang ada di antara asal dan stempel waktu . Saya akan merujuk nilai ini sebagai diff3 . Ini dapat dilakukan dengan rumus berikut:
diff3 = diff2 / <bucket width> * <bucket width>
Triknya di sini adalah ketika menggunakan operator pembagian / di T-SQL dengan operan integer, Anda mendapatkan pembagian integer. Misalnya, 3 / 2 di T-SQL adalah 1 dan bukan 1,5. Ekspresi diff2 /
SELECT
( DATEDIFF(month, @origin, @timestamp)
- CASE
WHEN DATEADD(
month,
DATEDIFF(month, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth AS diff3; Ekspresi ini mengembalikan 2, yang merupakan jumlah bulan di seluruh bucket 2 bulan yang ada di antara dua input.
Pada Langkah 4, yang merupakan langkah terakhir, Anda menambahkan diff3 unit bagian tanggal ke asal untuk menghitung awal ember berisi. Berikut kode untuk mencapai ini:
SELECT DATEADD(
month,
( DATEDIFF(month, @origin, @timestamp)
- CASE
WHEN DATEADD(
month,
DATEDIFF(month, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin); Kode ini menghasilkan output berikut:
--------------------------- 2021-03-15 00:00:00.0000000
Seperti yang Anda ingat, ini adalah output yang sama yang dihasilkan oleh fungsi DATE_BUCKET untuk input yang sama.
Saya sarankan Anda mencoba ekspresi ini dengan berbagai input dan bagian. Saya akan menunjukkan beberapa contoh di sini, tetapi silakan coba sendiri.
Berikut adalah contoh di mana asal hanya sedikit di depan stempel waktu di bulan:
DECLARE
@timestamp AS DATETIME2 = '20210510 06:30:00',
@bucketwidth AS INT = 2,
@origin AS DATETIME2 = '20210110 06:30:01';
-- SELECT DATE_BUCKET(week, @bucketwidth, @timestamp, @origin);
SELECT DATEADD(
month,
( DATEDIFF(month, @origin, @timestamp)
- CASE
WHEN DATEADD(
month,
DATEDIFF(month, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin); Kode ini menghasilkan output berikut:
--------------------------- 2021-03-10 06:30:01.0000000
Perhatikan bahwa awal dari ember berisi adalah pada bulan Maret.
Berikut adalah contoh di mana asal berada pada titik yang sama dalam satu bulan dengan stempel waktu :
DECLARE
@timestamp AS DATETIME2 = '20210510 06:30:00',
@bucketwidth AS INT = 2,
@origin AS DATETIME2 = '20210110 06:30:00';
-- SELECT DATE_BUCKET(week, @bucketwidth, @timestamp, @origin);
SELECT DATEADD(
month,
( DATEDIFF(month, @origin, @timestamp)
- CASE
WHEN DATEADD(
month,
DATEDIFF(month, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin); Kode ini menghasilkan output berikut:
--------------------------- 2021-05-10 06:30:00.0000000
Perhatikan bahwa kali ini ember berisi dimulai pada bulan Mei.
Berikut ini contoh dengan ember 4 minggu:
DECLARE
@timestamp AS DATETIME2 = '20210303 21:22:11',
@bucketwidth AS INT = 4,
@origin AS DATETIME2 = '20210115';
-- SELECT DATE_BUCKET(week, @bucketwidth, @timestamp, @origin);
SELECT DATEADD(
week,
( DATEDIFF(week, @origin, @timestamp)
- CASE
WHEN DATEADD(
week,
DATEDIFF(week, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin); Perhatikan bahwa kode menggunakan minggu bagian kali ini.
Kode ini menghasilkan output berikut:
--------------------------- 2021-02-12 00:00:00.0000000
Berikut ini contoh dengan ember 15 menit:
DECLARE
@timestamp AS DATETIME2 = '20210203 21:22:11',
@bucketwidth AS INT = 15,
@origin AS DATETIME2 = '19000101';
-- SELECT DATE_BUCKET(minute, @bucketwidth, @timestamp);
SELECT DATEADD(
minute,
( DATEDIFF(minute, @origin, @timestamp)
- CASE
WHEN DATEADD(
minute,
DATEDIFF(minute, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin); Kode ini menghasilkan output berikut:
--------------------------- 2021-02-03 21:15:00.0000000
Perhatikan bahwa bagiannya adalah menit . Dalam contoh ini, Anda ingin menggunakan ember 15 menit yang dimulai dari bagian bawah jam, jadi titik asal yang berada di bagian bawah jam mana pun akan berfungsi. Faktanya, titik asal yang memiliki satuan menit 00, 15, 30 atau 45 dengan nol di bagian bawah, dengan tanggal dan jam apa pun akan berfungsi. Jadi default yang digunakan fungsi DATE_BUCKET untuk input Origin akan bekerja. Tentu saja, saat menggunakan ekspresi kustom, Anda harus eksplisit tentang titik asal. Jadi, untuk bersimpati dengan fungsi DATE_BUCKET, Anda dapat menggunakan tanggal dasar di tengah malam seperti yang saya lakukan pada contoh di atas.
Kebetulan, dapatkah Anda melihat mengapa ini akan menjadi contoh yang baik di mana sangat aman untuk melewati Langkah 2 dalam solusi? Jika Anda memang memilih untuk melewati Langkah 2, Anda mendapatkan kode berikut:
DECLARE
@timestamp AS DATETIME2 = '20210203 21:22:11',
@bucketwidth AS INT = 15,
@origin AS DATETIME2 = '19000101';
-- SELECT DATE_BUCKET(minute, @bucketwidth, @timestamp);
SELECT DATEADD(
minute,
( DATEDIFF( minute, @origin, @timestamp ) ) / @bucketwidth * @bucketwidth,
@origin
); Jelas, kode menjadi jauh lebih sederhana ketika Langkah 2 tidak diperlukan.
Mengelompokkan dan menggabungkan data menurut tanggal dan waktu
Ada kasus di mana Anda perlu mengelompokkan data tanggal dan waktu yang tidak memerlukan fungsi canggih atau ekspresi yang berat. Misalnya, Anda ingin membuat kueri tampilan Sales.OrderValues dalam database TSQLV5, mengelompokkan data setiap tahun, dan menghitung jumlah dan nilai pesanan total per tahun. Jelas, cukup menggunakan fungsi YEAR(orderdate) sebagai elemen set pengelompokan, seperti:
USE TSQLV5; SELECT YEAR(orderdate) AS orderyear, COUNT(*) AS numorders, SUM(val) AS totalvalue FROM Sales.OrderValues GROUP BY YEAR(orderdate) ORDER BY orderyear;
Kode ini menghasilkan output berikut:
orderyear numorders totalvalue ----------- ----------- ----------- 2017 152 208083.99 2018 408 617085.30 2019 270 440623.93
Tetapi bagaimana jika Anda ingin mengelompokkan data berdasarkan tahun fiskal organisasi Anda? Beberapa organisasi menggunakan tahun fiskal untuk tujuan akuntansi, anggaran, dan pelaporan keuangan, tidak selaras dengan tahun kalender. Katakanlah, misalnya, bahwa tahun fiskal organisasi Anda beroperasi pada kalender fiskal Oktober hingga September, dan dilambangkan dengan tahun kalender di mana tahun fiskal berakhir. Jadi suatu peristiwa yang terjadi pada tanggal 3 Oktober 2018 termasuk dalam tahun anggaran yang dimulai pada tanggal 1 Oktober 2018, berakhir pada tanggal 30 September 2019, dan dilambangkan dengan tahun 2019.
Ini cukup mudah dicapai dengan fungsi DATE_BUCKET, seperti:
DECLARE @bucketwidth AS INT = 1, @origin AS DATETIME2 = '19001001'; -- this is Oct 1 of some year SELECT YEAR(startofbucket) + 1 AS fiscalyear, COUNT(*) AS numorders, SUM(val) AS totalvalue FROM Sales.OrderValues CROSS APPLY ( VALUES( DATE_BUCKET( year, @bucketwidth, orderdate, @origin ) ) ) AS A(startofbucket) GROUP BY startofbucket ORDER BY startofbucket;
Dan inilah kode yang menggunakan padanan logika khusus dari fungsi DATE_BUCKET:
DECLARE
@bucketwidth AS INT = 1,
@origin AS DATETIME2 = '19001001'; -- this is Oct 1 of some year
SELECT
YEAR(startofbucket) + 1 AS fiscalyear,
COUNT(*) AS numorders,
SUM(val) AS totalvalue
FROM Sales.OrderValues
CROSS APPLY ( VALUES(
DATEADD(
year,
( DATEDIFF(year, @origin, orderdate)
- CASE
WHEN DATEADD(
year,
DATEDIFF(year, @origin, orderdate),
@origin) > orderdate
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin) ) ) AS A(startofbucket)
GROUP BY startofbucket
ORDER BY startofbucket; Kode ini menghasilkan output berikut:
fiscalyear numorders totalvalue ----------- ----------- ----------- 2017 70 79728.58 2018 370 563759.24 2019 390 622305.40
Saya menggunakan variabel di sini untuk lebar bucket dan titik asal untuk membuat kode lebih digeneralisasikan, tetapi Anda dapat menggantinya dengan konstanta jika Anda selalu menggunakan yang sama, lalu menyederhanakan penghitungan yang sesuai.
Sebagai sedikit variasi di atas, misalkan tahun fiskal Anda berjalan dari 15 Juli dari satu tahun kalender hingga 14 Juli tahun kalender berikutnya, dan dilambangkan dengan tahun kalender yang menjadi awal tahun fiskal. Jadi peristiwa yang terjadi pada tanggal 18 Juli 2018 termasuk tahun fiskal 2018. Peristiwa yang terjadi pada tanggal 14 Juli 2018 termasuk tahun fiskal 2017. Dengan menggunakan fungsi DATE_BUCKET, Anda akan mencapai ini seperti ini:
DECLARE @bucketwidth AS INT = 1, @origin AS DATETIME2 = '19000715'; -- July 15 marks start of fiscal year SELECT YEAR(startofbucket) AS fiscalyear, -- no need to add 1 here COUNT(*) AS numorders, SUM(val) AS totalvalue FROM Sales.OrderValues CROSS APPLY ( VALUES( DATE_BUCKET( year, @bucketwidth, orderdate, @origin ) ) ) AS A(startofbucket) GROUP BY startofbucket ORDER BY startofbucket;
Anda dapat melihat perubahan dibandingkan dengan contoh sebelumnya di komentar.
Dan inilah kode yang menggunakan logika khusus yang setara dengan fungsi DATE_BUCKET:
DECLARE
@bucketwidth AS INT = 1,
@origin AS DATETIME2 = '19000715';
SELECT
YEAR(startofbucket) AS fiscalyear,
COUNT(*) AS numorders,
SUM(val) AS totalvalue
FROM Sales.OrderValues
CROSS APPLY ( VALUES(
DATEADD(
year,
( DATEDIFF(year, @origin, orderdate)
- CASE
WHEN DATEADD(
year,
DATEDIFF(year, @origin, orderdate),
@origin) > orderdate
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin) ) ) AS A(startofbucket)
GROUP BY startofbucket
ORDER BY startofbucket; Kode ini menghasilkan output berikut:
fiscalyear numorders totalvalue ----------- ----------- ----------- 2016 8 12599.88 2017 343 495118.14 2018 479 758075.20
Jelas, ada metode alternatif yang dapat Anda gunakan dalam kasus tertentu. Ambil contoh sebelum yang terakhir, di mana tahun fiskal berlangsung dari Oktober hingga September dan dilambangkan dengan tahun kalender di mana tahun fiskal berakhir. Dalam kasus seperti itu, Anda dapat menggunakan ekspresi berikut yang jauh lebih sederhana:
YEAR(orderdate) + CASE WHEN MONTH(orderdate) BETWEEN 10 AND 12 THEN 1 ELSE 0 END
Dan kemudian kueri Anda akan terlihat seperti ini:
SELECT
fiscalyear,
COUNT(*) AS numorders,
SUM(val) AS totalvalue
FROM Sales.OrderValues
CROSS APPLY ( VALUES(
YEAR(orderdate)
+ CASE
WHEN MONTH(orderdate) BETWEEN 10 AND 12 THEN 1
ELSE 0
END ) ) AS A(fiscalyear)
GROUP BY fiscalyear
ORDER BY fiscalyear; Namun, jika Anda menginginkan solusi umum yang akan bekerja dalam lebih banyak kasus, dan Anda dapat membuat parameter, Anda tentu ingin menggunakan bentuk yang lebih umum. Jika Anda memiliki akses ke fungsi DATE_BUCKET, itu bagus. Jika tidak, Anda dapat menggunakan padanan logika khusus.
Kesimpulan
Fungsi DATE_BUCKET adalah fungsi yang cukup berguna yang memungkinkan Anda untuk mengelompokkan data tanggal dan waktu. Ini berguna untuk menangani data deret waktu, tetapi juga untuk mengelompokkan data apa pun yang melibatkan atribut tanggal dan waktu. Dalam artikel ini saya menjelaskan cara kerja fungsi DATE_BUCKET dan menyediakan logika ekuivalen khusus jika platform yang Anda gunakan tidak mendukungnya.